
Durante años, los creadores tuvieron un trabajo realmente aburrido: debían crear videos mudos primero y luego pasar horas intentando añadirles sonidos. Esto solía causar grandes problemas con la sincronización. La boca de una persona se movía, pero las palabras llegaban un segundo después. Se sentía extraño y falso, lo que dificultaba que la gente mantuviera su atención en el video.
Vidu Q3 soluciona estos viejos problemas creando videos con IA con sonido integrado. A diferencia de otras herramientas, crea clips de 16 segundos con el audio y el video al mismo tiempo. Este método inteligente asegura que cada palabra coincida perfectamente con el movimiento de labios de la persona. También significa que cada estruendo o clic en el sonido ocurre exactamente al mismo tiempo que la acción en pantalla.
Los estándares de sincronización labial por IA en 2026 ahora priorizan la generación "One-Pass" (de una sola pasada) para reducir la latencia y mejorar el realismo. Al integrar el diálogo y la música de fondo directamente en el proceso de generación, Vidu Q3 elimina el "valle inquietante" del habla desalineada, aumentando significativamente la retención de la audiencia para contenido de redes sociales y marketing.
¿Qué hace que el "Audio Nativo" de Vidu Q3 sea diferente?
A diferencia de los modelos tradicionales que generan imágenes primero y "superponen" el sonido después, Vidu Q3 utiliza una arquitectura de generación de una sola pasada. Esto significa que el modelo sintetiza:
- SFX (Efectos de sonido): Sonidos ambientales como pasos o crujido de hojas.
- BGM (Música de fondo): Música de fondo adaptada al arco emocional de la escena.
- Diálogo: Patrones de habla con sincronización precisa.
Al generar estos elementos simultáneamente, la sincronización entre una acción física y su sonido queda bloqueada matemáticamente, eliminando el efecto de "valle inquietante" del audio tardío.
El hito de los 16 segundos
Vidu Q3 ahora admite clips de video de hasta 16 segundos de duración. Esta duración es un punto medio ideal por varias razones principales:
- Anuncios en redes sociales: Te da tiempo suficiente para captar la atención, explicar el valor y añadir una llamada a la acción (CTA).
- Flujo narrativo: Esta longitud permite pausas naturales en la sincronización labial de la IA, haciendo que los proyectos de video de 2026 luzcan fluidos en lugar de entrecortados.
Comparativa de rendimiento
Para entender cómo se posiciona Vidu Q3 frente a sus competidores, observamos la latencia audiovisual: el retraso entre una acción visual y su sonido correspondiente.
| Característica | Vidu Q3 (Opción principal) | Kling 2.6 | Veo 3.1 |
| Arquitectura de sincronización | Nativa One-Pass (Unificada) | Nativa One-Pass | Nativa One-Pass |
| Duración máxima | 16 segundos (Líder del sector) | 10 segundos | 8 segundos |
| Alineación de guiones largos | Excepcional (100+ caracteres) | Moderada (propenso a derivas) | Alta (enfocado en visuales) |
| Fidelidad de SFX físicos | Alta (basada en materiales) | Equilibrada | Atmosférica |
| Continuidad entre tomas | Cambio de audio fluido | Básica | Avanzada |
| Latencia / Deriva de audio | < 30ms | < 15ms | ~10ms |
Aunque los competidores puedan ofrecer una latencia ligeramente menor, Vidu es el único modelo que ofrece un creativo completo de 16 segundos. Su capacidad para generar entornos sincronizados lo convierte en la opción principal para creadores que exigen realismo cinematográfico sin el dolor de cabeza técnico de la alineación manual.
La fórmula del "Prompt del Director" para un audio perfecto
Lograr los estándares de sincronización labial por IA en 2026 de alta fidelidad requiere ir más allá de las descripciones simples. Para aprovechar al máximo el video con IA de audio nativo, los creadores deben cerrar la brecha entre la acción visual y la reacción auditiva dentro de un solo prompt.
Maestría del puente Sujeto-Audio en la generación One-Pass
En Vidu Q3, el "Puente Sujeto-Audio" es la técnica de anclar sonidos específicos a señales visuales. Debido a que el modelo utiliza la generación "One-Pass", busca vínculos semánticos: alinea los datos del video con IA de audio nativo dentro de tu prompt. Por ejemplo, si describes "un cristal rompiéndose", el puente activa un flujo de trabajo específico:
- Precisión temporal: La IA identifica el fotograma exacto del impacto.
- Mapeo acústico: Prepara un pico de audio de alta frecuencia (el "tintineo" o "choque") para que ocupe esa marca de tiempo específica.
- Contexto ambiental: Ajusta la reverberación según si la escena visual es una habitación pequeña o un gran salón.
Este enfoque integrado resulta en una deriva significativamente menor en comparación con los sistemas de IA modulares.
La receta del prompt: Un enfoque de tres capas
Para asegurar que el modelo capture cada capa de la escena, sigue esta jerarquía estructural:
[Descripción visual] + [Movimiento de cámara] + [Capa de audio: Diálogo/SFX/BGM]
Desglose de los componentes del prompt
| Componente | Función | Ejemplo |
| Descripción visual | Define sujetos, texturas y acciones | Un herrero golpeando una espada de hierro al rojo vivo |
| Movimiento de cámara | Establece perspectiva y profundidad | Primer plano extremo, chispas volando hacia el lente |
| Capa de audio | Especifica tipos de sonido e intensidad | SFX: Anillos metálicos agudos, vapor sibilante |
Caso de estudio: Ejecución de alta sincronización
Analicemos un prompt diseñado para la máxima sincronización:
Esta es mi imagen de referencia:

Este es mi prompt de video:

A continuación, veamos los resultados de la generación de video:
Información del video: 1080p, H264, Flash
- El hecho de que la sincronización labial basada en fonemas se mantenga así de precisa en modo Flash es notable. Por lo general, los modelos "rápidos" o "lite" sacrifican microexpresiones para ahorrar tiempo de cómputo. Sin embargo, la alineación en palabras como "Loved" y "Real" se mantiene estable, lo que demuestra que la arquitectura de Audio Nativo de Vidu Q3 es robusta incluso sin muestreo iterativo de alta gama.
- H.264 es un formato con pérdida que suele fallar al capturar detalles pequeños como la lluvia o el grano de la película. A menudo deja "macrobloques" o cajas pixeladas feas en zonas oscuras y granuladas. A pesar de estos límites, la iluminación tipo "Claroscuro" luce excelente. Las sombras se mantienen nítidas en lugar de convertirse en un desenfoque borroso, mostrando qué tan bien maneja el modelo la gradación de color.
- Las texturas húmedas y la lluvia nítida de fondo son donde notarás más desenfoque por compresión. Estos detalles lucen mucho más claros si usas una salida Pro o de alta resolución, como ProRes o un bitrate más alto.
El plan gratuito es perfecto si tienes proyectos sencillos o solo quieres experimentar. Pero si buscas un aspecto de cine real —superando el "Valle Inquietante" con altos bitrates y calidad nítida— deberías trasladar tu trabajo a Atlas Cloud.
Al utilizar Vidu Q3 Turbo en Atlas Cloud, puedes evitar los cuellos de botella de cómputo local y generar contenido de alta fidelidad sin marca de agua que preserva cada microdetalle.
Secretos profesionales para una sincronización labial impecable: Sección de "Maestría"

Lograr el realismo cinematográfico en los estándares de sincronización labial por IA en 2026 requiere algo más que un buen prompt; requiere una comprensión técnica de cómo el motor interpreta el habla humana. Al optimizar tus guiones y el entorno visual, puedes maximizar la precisión de la generación de video con IA de audio nativo.
Guiones basados en fonemas
El secreto para "bloquear" el motor de seguimiento de Vidu Q3 reside en los fonemas. Específicamente, comenzar tus frases con "oclusivas": sonidos creados al detener el flujo de aire, como M, B y P. Estos sonidos requieren un cierre labial visible y distintivo. Cuando el modelo detecta una oclusiva al inicio de una secuencia, establece un punto de anclaje de alta confianza para la geometría de la boca, reduciendo significativamente la posibilidad de un "murmullo" inicial o fotogramas desalineados.
La regla de las 5-9 palabras
Para mantener la consistencia, los creadores profesionales siguen la Regla de las 5-9 palabras. Aunque Vidu Q3 admite duraciones más largas, la "deriva de la IA" —donde los movimientos de la boca pierden gradualmente la sincronización con el audio— tiende a aumentar durante largas cadenas de diálogo ininterrumpidas. Dividir el habla en segmentos de 5 a 9 palabras permite que el modelo "reinicie" sus parámetros de seguimiento en cada pausa natural.
| Característica | Longitud del segmento | Resultado |
| Ideal | 5-9 palabras | Alineación perfecta por fotograma y ritmo natural. |
| Subóptimo | 15+ palabras | Mayor riesgo de "deriva" o bordes labiales borrosos. |
Claridad visual e iluminación
El motor de sincronización labial requiere una vista clara y sin obstrucciones de la parte inferior del rostro para mapear los fonemas a los píxeles. Para garantizar un seguimiento de alta fidelidad:
- Evita obstrucciones: Asegúrate de que las manos, micrófonos o cabellos sueltos no crucen el área de la boca, ya que estos elementos de "ruido visual" pueden confundir el mapeo del espacio latente.
- Iluminación de alto contraste: Asegúrate de que la barbilla y los labios estén bien definidos. La iluminación plana puede hacer que a la IA le cueste determinar la profundidad del interior de la boca.
Ritmos multilingües: Inglés vs. Mandarín
Vidu Q3 utiliza una lógica diferente para varios ritmos de habla. El inglés sigue un ritmo basado en el énfasis, por lo que el motor se enfoca en formas vocálicas amplias. El mandarín es silábico y tonal, lo que requiere movimientos labiales más rápidos y precisos. Para obtener un habla natural en mandarín, utiliza prompts que mantengan la "posición de la cabeza estable". Esto ayuda al motor a concentrarse mejor en esos ajustes pequeños y rápidos de la boca.
Seguir estas reglas visuales y de diseño mantiene tu video y audio estables durante todo el clip de 16 segundos.
Historias de varias tomas y diseño de audio
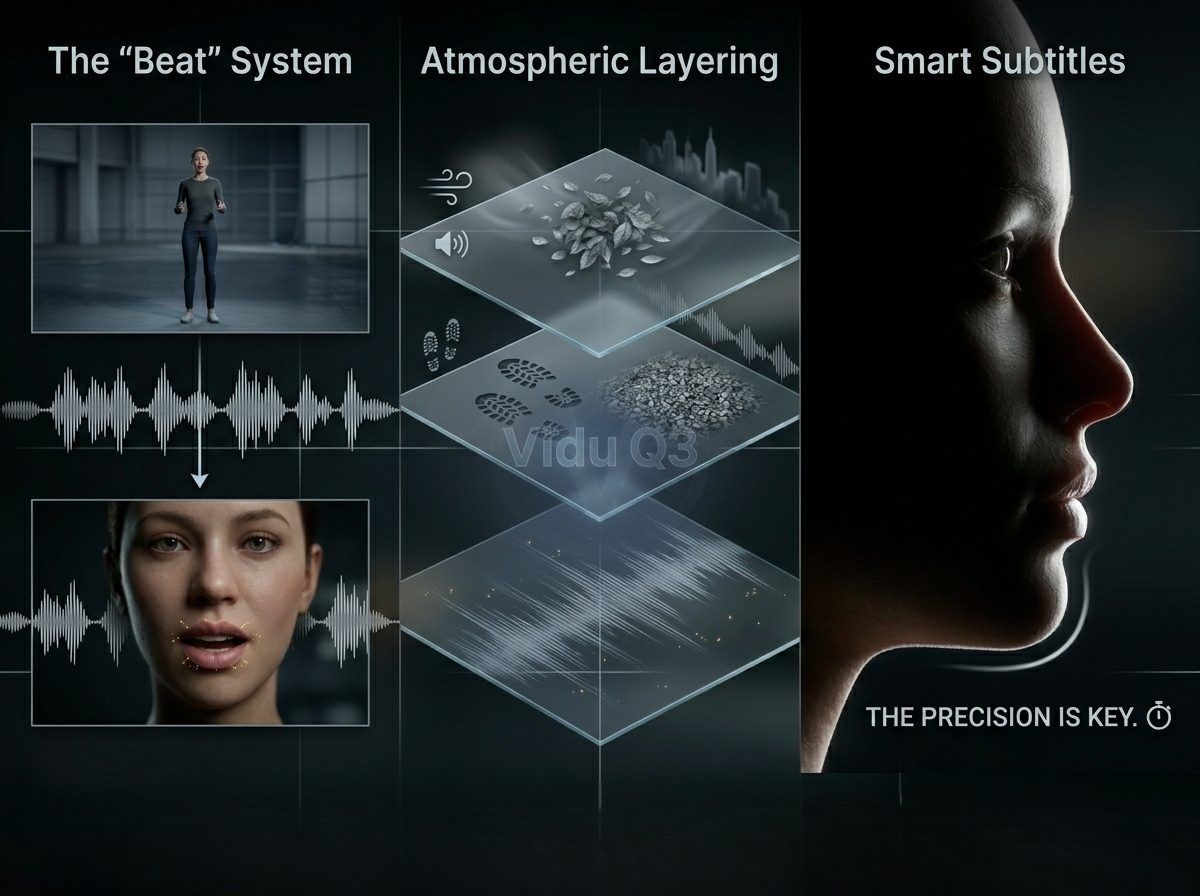
Mantener una historia en movimiento a través de varios ángulos es lo que hace que un creador parezca un profesional. Vidu Q3 facilita esto con herramientas inteligentes de múltiples tomas. Estas funciones mantienen tu video e audio de IA perfectamente sincronizados incluso cuando cambia la vista de la cámara.
El sistema "Beat": Orquestando la continuidad del audio
Vidu Q3 introduce el sistema "Beat", que permite a los usuarios definir transiciones de cámara específicas sin interrumpir el flujo de audio. Al escribir "beats" (tiempos), puedes ordenar una transición de un plano general a un primer plano cerrado mientras el diálogo o la música de fondo (BGM) continúan sin problemas. Esta continuidad evita los molestos "reinicios de audio" comunes en herramientas de IA modulares.
Gestión de transiciones de varias tomas:
| Tipo de toma | Propósito | Comportamiento del audio |
| Plano general | Establece el entorno | Alta reverberación, énfasis ambiental |
| Plano medio | Se enfoca en la acción | Diálogo y SFX equilibrados |
| Primer plano | Mejora la emoción | Audio seco, prioridad en sincronización labial |
Capas atmosféricas: Anclando las imágenes
Para que las imágenes generadas por IA se sientan arraigadas en la realidad, los creadores deben mirar más allá del diálogo e incorporar "textura". Las capas atmosféricas implican solicitar sonidos secundarios y terciarios que interactúen con el entorno.
- Textura ambiental: Especifica el silbido del viento a través de los árboles o el murmullo de una ciudad lejana.
- Textura física: Incluye el "crujido de la seda" o el "crujir de la grava" bajo los pasos.
- Profundidad acústica: La generación de una sola pasada de Vidu Q3 calcula la distancia del sujeto respecto a la cámara, ajustando automáticamente el volumen y el "aire" alrededor de estos sonidos para que coincidan con la profundidad visual.
Subtítulos inteligentes: Sincronización de texto precisa
Un gran problema en la creación automática de videos es cuando los subtítulos no coinciden con el habla. Vidu Q3 soluciona esto activando su motor interno de renderizado de texto directamente desde las pistas de diálogo generadas. Debido a que el texto se renderiza en la misma pasada que el video con IA de audio nativo, la sincronización es precisa al fotograma. Esto asegura que el ojo y el oído del espectador reciban la misma información en el mismo milisegundo, un requisito para los estándares de alta accesibilidad en la sincronización labial por IA en 2026.
Utilizar estas funciones integradas reduce el tiempo de postproducción en aproximadamente un 60%, permitiendo un flujo de trabajo "directo a redes sociales" que mantiene una calidad cinematográfica.
Problemas comunes y cómo solucionarlos
Los creadores suelen encontrar fricción técnica cuando utilizan Vidu Q3 por primera vez. Lograr un video con IA de audio nativo impecable requiere solucionar las interacciones sutiles entre los prompts de texto y la salida acústica.
Problema: La boca se mueve, pero es un galimatías
Este es un obstáculo frecuente donde la sincronización labial visual parece activa pero la vocalización es ininteligible.
- La solución: Higiene del guion. El motor de Vidu Q3 es altamente sensible al formato del bloque de diálogo. Asegúrate de que tu transcripción esté libre de muletillas no verbales (como "eh" o "mmm") a menos que estén específicamente destinadas a un rasgo de carácter "naturalista". Usa puntuación estándar para señalar a la IA cuándo hacer una pausa para respirar, lo que reinicia la alineación del seguimiento labial.
Problema: El sonido es demasiado fuerte o distorsionado
Los chasquidos y la distorsión ocurren cuando la energía del video no se ajusta a los niveles de volumen establecidos.
-
La solución: Ajustar palabras clave de emoción. En lugar de simplemente aumentar el "volumen" en un prompt —que la IA puede interpretar como un aumento de ganancia—, utiliza estilos vocales descriptivos.
- Baja intensidad: Usa "susurro" o "tono murmurado" para reducir los niveles máximos.
- Alta intensidad: Usa "grito proyectado" o "anuncio estruendoso" para asegurar que la IA equilibre el rango dinámico del audio.
Problema: La música no coincide con el estado de ánimo
Dado que Vidu Q3 genera la música de fondo en la misma pasada que el video, los prompts genéricos como "música alegre" a menudo resultan en desconexiones tonales.
- La solución: Anclas de BPM y género específico. Trata a la IA como a un compositor. Proporcionar un tempo específico o un subgénero ayuda al modelo a anclar la música de fondo a la frecuencia de fotogramas visuales.
Tabla de referencia rápida para solución de problemas
| Síntoma | Causa principal | Ajuste recomendado |
| Habla distorsionada | Guion sucio/jerga | Usa cadenas de texto limpias y puntuadas |
| Recorte de audio | Desajuste tonal | Usa descriptores de "susurro" o "grito" |
| Deriva del estado de ánimo | Prompt de BGM vago | Añade BPM (ej. 120 BPM) o género (ej. Lofi) |
Estos ajustes cambian la forma en que el modelo mapea el sonido. Mantienen tus niveles de audio seguros para la transmisión profesional. Cuando dominas estas soluciones, dejas de jugar simplemente con la IA; empiezas a crear contenido que se ve y suena profesional.
Conclusión: El futuro del contenido con IA es "Full-Stack"
Dominar Vidu Q3 significa convertirse en un creador "Full-Stack": alguien que entiende que un video con IA de audio nativo verdaderamente inmersivo se construye sobre la sinergia de píxeles sincronizados y ondas sonoras.
Los creadores que priorizan la arquitectura del audio obtienen una ventaja significativa en un mercado digital saturado. Al utilizar la generación "One-Pass", te beneficias de:
- Reducción del tiempo de producción: Eliminando la necesidad de herramientas de doblaje externas.
- Mayor retención: La sincronización labial precisa y las texturas ambientales impulsan una mayor interacción de los espectadores.
- Versatilidad de plataforma: El contenido está listo para transmisión de alta fidelidad sin necesidad de masterización adicional.
¿Listo para liderar la revolución del cine sonoro? Comparte tu primera creación con Vidu Q3 en los comentarios, o mantente atento a nuestro próximo análisis profundo sobre técnicas avanzadas de edición de video a video en Vidu.
Preguntas frecuentes (FAQ)
¿En qué se diferencia la generación "One-Pass" de los flujos de trabajo tradicionales de video con IA?
En los flujos de trabajo tradicionales, los creadores generaban imágenes mudas y utilizaban herramientas de terceros como ElevenLabs o SyncLabs para el doblaje en postproducción. La generación One-Pass, utilizada por modelos como Vidu Q3 y Veo 3.1, sintetiza audio y video en un solo ciclo de inferencia. Este enfoque multimodal asegura que los sonidos ambientales y los patrones de habla estén bloqueados matemáticamente a los fotogramas visuales, reduciendo el tiempo de "costura" manual en aproximadamente un 60% según los puntos de referencia de la industria de 2026.
¿Qué modelos de video con IA lideran actualmente la sincronización de audio nativo?
Para mediados de 2026, el mercado se dividió en dos caminos. Algunos modelos se centran en visuales de alta gama, mientras que otros trabajan en funciones de "cine sonoro" realista.
| Modelo | Duración máxima | Integración de audio | Ideal para |
| Vidu Q3 | 16 segundos | Nativa (One-Pass) | Narrativa y anuncios sociales |
| Kling 3.0 | 15 segundos | Nativa (Bilingüe) | Narrativa cinematográfica |
| Veo 3.1 | 8-10 segundos | Nativa (Alta fidelidad) | Contenido de marca comercial |
¿Qué factores técnicos causan la "deriva de sincronización labial" en la IA?
La "deriva" ocurre cuando el mapeo del espacio latente para la geometría de la boca pierde la alineación con la señal de audio a lo largo del tiempo. Los factores clave incluyen:
- Longitud del clip: Si un personaje habla durante más de 10 segundos sin pausa, los movimientos de la boca comienzan a perder la pista.
- Luz y sombra: Cuando la iluminación es demasiado plana en la barbilla y los labios, el sistema no puede ver las formas de la boca claramente.
- Detalle de la pantalla: Los videos hechos a 720p a menudo pierden movimientos faciales diminutos que verías en un video nítido de 1080p.
¿Puede la IA crear efectos de sonido naturales sin prompts?
Aunque los modelos modernos como Vidu Q3 utilizan Mapeo del Entorno Acústico para generar automáticamente sonidos ambientales (ej. lluvia o pasos), los resultados profesionales aún requieren "Prompts de anclaje". Al definir explícitamente la [Capa de audio] en tu prompt —especificando la intensidad de la BGM o la textura del SFX— guías la capa de "Mapeo Acústico" del modelo para evitar que el audio se sienta desconectado o genérico.






