
El modelo de generación de imágenes más reciente de OpenAI, GPT-Image-1.5, representa un avance significativo en control, fidelidad visual e integración multimodal. A diferencia de los modelos de difusión independientes anteriores, GPT-Image-1.5 está profundamente integrado en el ecosistema GPT más amplio, lo que permite a los desarrolladores generar, editar e iterar sobre imágenes usando lenguaje natural con mayor precisión y consistencia.
En esta guía, desglosaremos:
- Qué es realmente GPT-Image-1.5
- Qué lo hace diferente de los modelos de imagen anteriores
- Cómo utilizar la API de forma efectiva
- Un flujo de trabajo de producción
¿Qué es GPT-Image-1.5?
OpenAI acaba de lanzar un nuevo modelo de imagen. Se llama GPT‑Image‑1.5. La idea es ofrecerte imágenes de alta calidad y controlables a través de una API. Este modelo está diseñado para el trabajo real, no solo para hacer pruebas.
Además, vive dentro de la infraestructura más amplia de OpenAI. Por lo tanto, funciona perfectamente con sus modelos de texto —útil para generar prompts— y sus modelos de visión para comprender imágenes. También puedes conectarlo a flujos de trabajo automatizados como agentes, pipelines o herramientas SaaS.
Capacidades principales: lo que dice OpenAI
- Generación de texto a imagen con una sólida alineación con el prompt
- Edición basada en instrucciones: modifica imágenes existentes diciéndole al modelo qué hacer
- Flujos de trabajo de refinamiento iterativo: generar, ajustar, generar de nuevo
- Mejor consistencia en múltiples ejecuciones

Qué ha cambiado realmente
1. De la creatividad al control
Los modelos antiguos eran muy creativos pero impredecibles. Nunca sabías qué ibas a obtener. El nuevo produce resultados más estructurados. Sigue mejor los prompts.
2. De una salida única a un flujo de trabajo iterativo
Las versiones anteriores te animaban a generar una imagen "final" y darla por terminada. GPT‑Image‑1.5 está diseñado para un bucle: generar, editar, refinar, escalar.
3. De herramienta de demostración a infraestructura de producción
Esto es importante. El modelo está diseñado para cargas de trabajo reales. Pipelines de imágenes para comercio electrónico. Automatización creativa de marketing. Herramientas de diseño potenciadas por IA. No solo piezas de galería.
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Característica | GPT-Image-1.5 | DALL·E |
| Precisión del prompt | Alta | Media |
| Capacidad de edición | Fuerte | Limitada |
| Consistencia | Alta | Baja |
| Soporte de flujo de trabajo | Listo para producción | Enfocado en demo |
| Integración API | Nativa | Limitada |
Por qué a los desarrolladores realmente les importa
Probablemente ya te hayas enfrentado a estos problemas antes.
Primero, la iteración toma demasiado tiempo.
Generas una imagen. Está casi bien. Pero el color no es correcto. O el fondo es incorrecto. Con modelos anteriores, tenías que regenerar desde cero. Eso desperdicia tiempo y créditos de API. GPT‑Image‑1.5 te permite editar. Cambiar el color. Intercambiar el fondo. Mantener todo lo demás igual. Eso reduce significativamente el tiempo de iteración.
Segundo, los prompts son ignorados.
Escribes una descripción detallada. El modelo hace la mitad. O agrega cosas que nunca pediste. Este modelo presta atención. No perfectamente, pero sí notablemente mejor. Las relaciones de los objetos se mantienen intactas. La composición de la escena coincide con tus instrucciones. Los prompts de estilo realmente funcionan.
Tercero, escalar rompe la consistencia.
Generas diez imágenes del mismo producto. Parecen haber sido hechas por diez fotógrafos diferentes. La iluminación cambia. Los ángulos se desplazan. Los colores varían. Eso acaba con el trabajo de comercio electrónico y branding. GPT‑Image‑1.5 fue entrenado para reducir esa variación. Los resultados en un lote parecen pertenecer juntos.
Cuarto, la integración de la API parece una ocurrencia tardía en muchas herramientas.
Las aplicaciones independientes son geniales para jugar. Pero cuando necesitas conectar la generación de imágenes en un sistema backend, una interfaz web no ayuda. GPT‑Image‑1.5 incluye una API adecuada. Autenticación, endpoints, límites de tasa, webhooks. El tipo de cosas que los desarrolladores realmente necesitan.
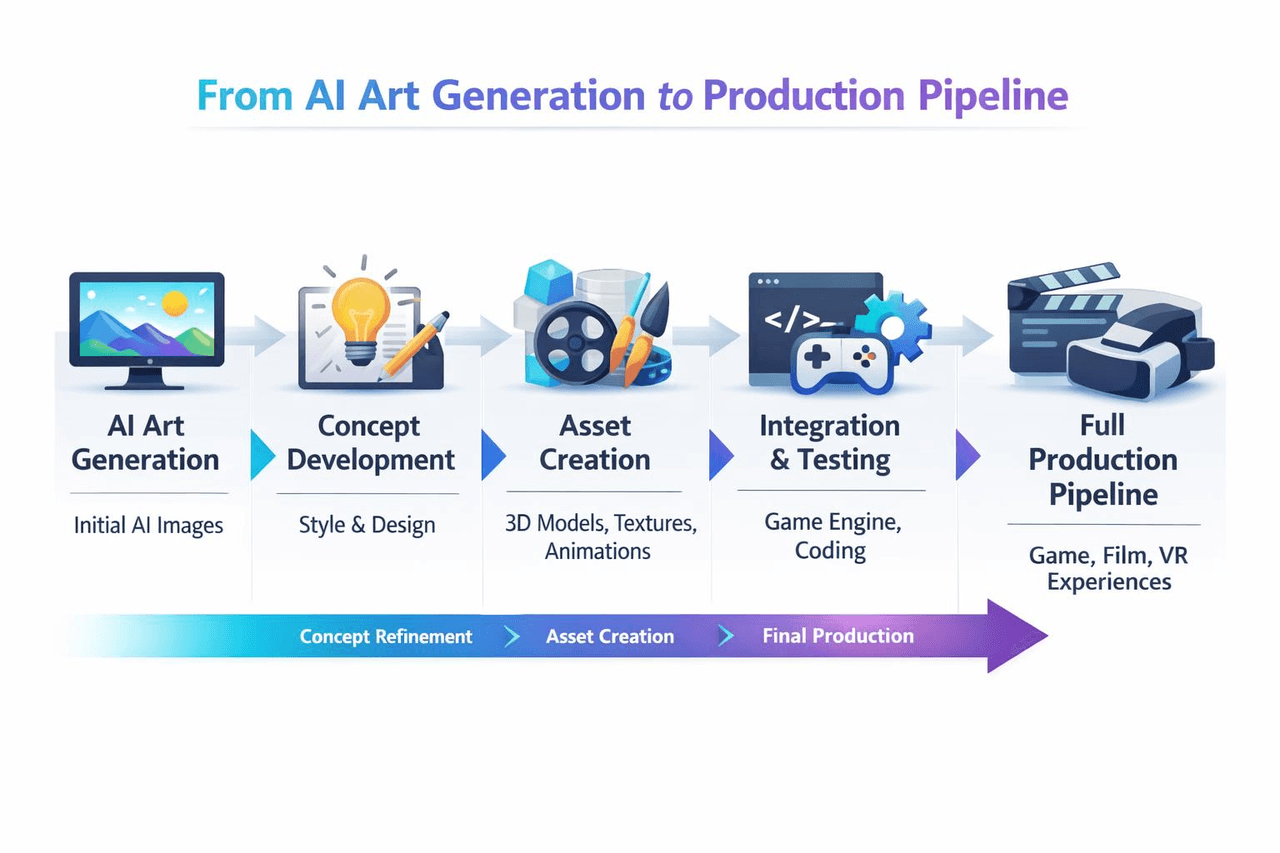
Guía de integración de la API
Atlas Cloud te permite probar múltiples modelos lado a lado. Puedes comenzar en el playground, experimentar, ver qué funciona y luego llamar a todo a través de una única API.
Método 1: Usar directamente en el Atlas Cloud playground
Una de las formas más sencillas de empezar con GPT-Image-1.5 es usarlo directamente en el Atlas Cloud Playground: una interfaz basada en web diseñada para que desarrolladores, diseñadores y especialistas en marketing experimenten con la generación de imágenes por IA sin escribir código.
Método 2: Acceder vía API
Paso 1: Obtén tu clave de API
Crea una clave de API en tu consola y cópiala para usarla más tarde.
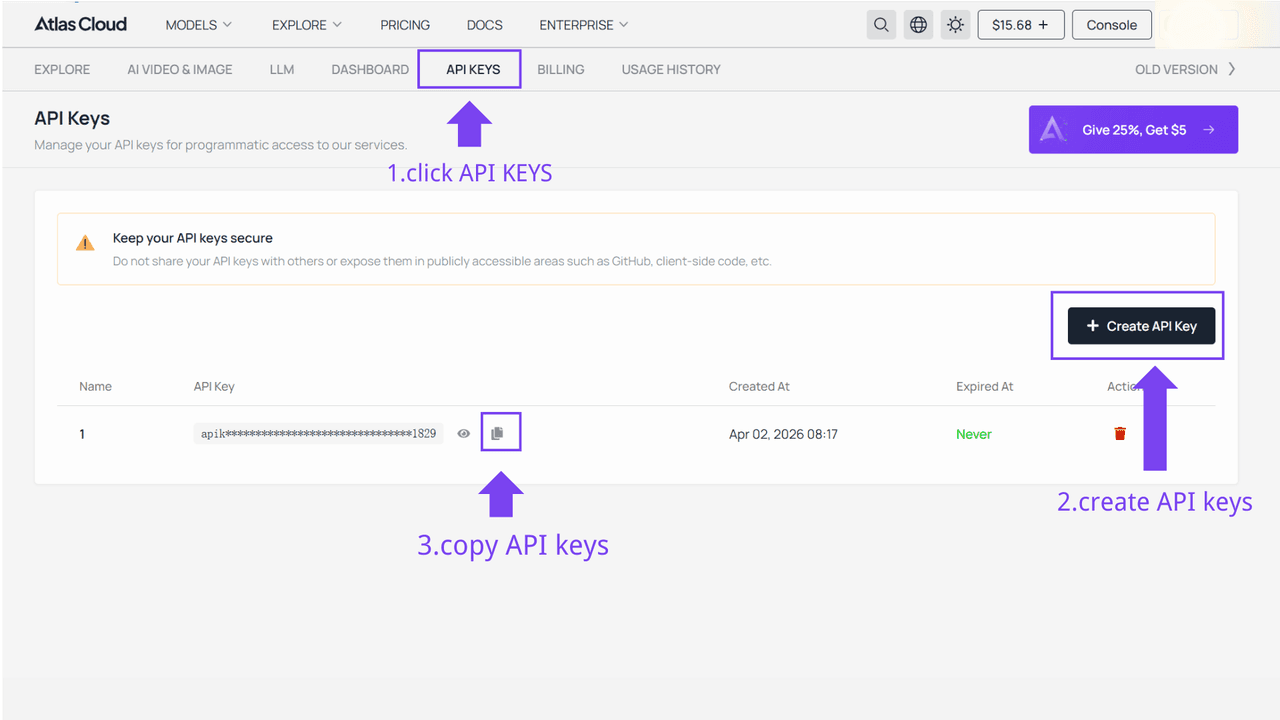
Paso 2: Revisa la documentación de la API
Revisa el endpoint, los parámetros de solicitud y el método de autenticación en nuestra documentación de la API.
Paso 3: Realiza tu primera solicitud (ejemplo en Python)
Aquí tienes un ejemplo sencillo de cómo generar una imagen usando OpenAI GPT-Image-1.5:
plaintext1import requests 2import time 3# Paso 1: Iniciar la generación de imágenes 4generate_url = "https://api.atlascloud.ai/api/v1/model/generateImage" 5headers = { 6 "Content-Type": "application/json", 7 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 8} 9data = { 10 "model": "openai/gpt-image-1.5/text-to-image", # Requerido 11 "enable_base64_output": False, # Si está habilitado, la salida se codificará en una cadena BASE64 en lugar de una URL 12 "enable_sync_mode": False, # Si se establece en true, la función esperará a que el resultado se genere y cargue antes de devolver la respuesta 13 "output_format": "jpeg", # El formato de la imagen de salida. opciones: jpeg | png 14 "prompt": "end-to-end AI image production pipeline, prompt generation, image creation, QA, deployment, SaaS workflow diagram\n\n", # Requerido. El prompt positivo para la generación 15 "quality": "medium", # La calidad de la imagen generada. opciones: low | medium | high 16 "size": "1536x1024", # El tamaño de la media generada en píxeles (ancho*alto). predeterminado: "1024x1024". opciones: 1024x1024 | 1024x1536 | 1536x1024 17} 18generate_response = requests.post(generate_url, headers=headers, json=data) 19generate_result = generate_response.json() 20prediction_id = generate_result["data"]["id"] 21# Paso 2: Consultar el resultado 22poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 23def check_status(): 24 while True: 25 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 26 result = response.json() 27 if result["data"]["status"] == "completed": 28 print("Imagen generada:", result["data"]["outputs"][0]) 29 return result["data"]["outputs"][0] 30 elif result["data"]["status"] == "failed": 31 raise Exception(result["data"]["error"] or "La generación falló") 32 else: 33 # Procesando, esperar 2 segundos 34 time.sleep(2) 35image_url = check_status()
Un flujo de trabajo de producción: integrándolo todo
Los equipos reales que utilizan GPT‑Image‑1.5 siguen un patrón.
- Paso uno: estandarizar prompts. Algunos equipos utilizan modelos de texto GPT para generar prompts estructurados automáticamente.
- Paso dos: llamar a la API. Generar imágenes.
- Paso tres: control de calidad (QA) automatizado. Verificar la consistencia del estilo. Marcar resultados erróneos.
- Paso cuatro: bucle de iteración. Editar imágenes mediante prompts. Generar variaciones.
- Paso cinco: implementación. Almacenar activos. Servirlos a tu frontend o usuarios.
Preguntas frecuentes
1. ¿Cuál es la diferencia entre GPT-Image-1.5 y otros generadores de fotografía de producto con IA?
La mayoría de las llamadas herramientas de fotografía de producto con IA son solo modelos de código abierto envueltos en una plantilla. Subes una imagen con fondo blanco, eliges una escena y une algo. Rápido, claro. Pero no puedes ajustar los detalles. ¿La iluminación se ve rara? Mala suerte. ¿Las sombras caen de forma extraña? Tendrás que lidiar con eso.
GPT‑Image‑1.5 no funciona así. No te da plantillas prefabricadas. Te permite controlar las cosas tú mismo. Puedes decir "luz lateral, sombras cayendo a la derecha, desenfocar un poco el fondo" y lo sigue. ¿La desventaja? Tienes que aprender a escribir prompts correctamente. Pero una vez que lo haces, el mismo prompt funciona en cientos de imágenes. Es por eso que los equipos que crean pipelines de imágenes de producto reales prefieren usar la API de OpenAI para construir su propio sistema, en lugar de depender de esas herramientas de generación de un solo clic.
2. ¿Qué tipos de prompts funcionan mejor para la API de texto a imagen de OpenAI?
No escribas demasiado corto. Tampoco escribas una novela. El mejor formato es desglosarlo: qué hay en la toma, dónde está, cómo está iluminado, qué estilo tiene.
Aquí hay un ejemplo. Escribes "una silla moderna" y el modelo te da una silla cualquiera. Escribes "una silla lounge de madera de nogal, colocada en una sala de estar brillante con ventanas grandes, luz natural suave desde la izquierda, estilo moderno de mediados de siglo, composición limpia" y el resultado es mucho más fiable.
El modelo no puede leer tu mente. Tienes que dividir la escena en piezas y decírselo. Haz eso, ya sea que estés haciendo tomas de producto o cualquier otra cosa, y verás una diferencia real.
3. ¿Cuál es la ventaja de usar un generador de fotografía de producto con IA sobre la fotografía tradicional?
La velocidad es la obvia. Consigue tus prompts correctos y puedes sacar docenas de ángulos de producto en pocos minutos. Una sesión tradicional todavía estaría ajustando luces en ese punto.
La ventaja real es la flexibilidad. Con la fotografía regular, cambiar el fondo significa una sesión completamente nueva. Lo mismo para una iluminación diferente. Con GPT‑Image‑1.5, solo lo escribes. "Cambia el fondo a ladrillo". "Haz la luz más cálida". "Convierte las zapatillas rojas en azules". Una oración convierte una imagen estática en algo que puedes ajustar sobre la marcha.
Luego está la consistencia. En una sesión tradicional, la luz varía. Los colores cambian ligeramente entre tomas. Diez fotos del mismo producto pueden terminar pareciendo como si diez fotógrafos diferentes las hubieran tomado. Con un modelo, mantén el prompt igual y esas diez tomas realmente parecen un set. Para comercio electrónico o branding, eso importa mucho más que una imagen bonita.






