
Las rígidas etiquetas de género ID3 están acabando con tu colección de música local. Al combinar el análisis sónico avanzado de AudioMuse-AI con la API escalable de AtlasCloud, puedes transformar un directorio estático de archivos multimedia en un motor de descubrimiento semántico profundamente intuitivo que envía listas de reproducción basadas en emociones directamente a tu servidor autohospedado.
![]()
Recuperando la calidez de la música: construye una biblioteca local realmente intuitiva mediante AudioMuse-AI
Estás sentado en tu escritorio a altas horas de la noche. No quieres escuchar una lista de reproducción electrónica de alta energía, ni estás de humor para música clásica pura y estéril. Lo que realmente quieres es un ambiente muy específico: “Indie folk tranquilo y atmosférico con sutiles matices acústicos de día lluvioso para ayudarme a relajarme”.
Si abres tu instancia autohospedada de Navidrome o Jellyfin y escribes esa frase exacta en la barra de búsqueda, obtendrás exactamente cero resultados.
Durante décadas, los coleccionistas de música digital hemos pasado incontables horas organizando meticulosamente etiquetas ID3, limpiando portadas de álbumes y forzando formas de arte fluidas en cubetas de género rígidas como "Rock", "Jazz" o "Pop". Pero seamos honestos: las etiquetas de género son una reliquia del marketing de las tiendas de discos del siglo XX. No entienden cómo se siente la música en realidad.
El futuro de la gestión de una colección de música privada no pertenece a los metadatos estáticos. Pertenece al análisis de audio semántico. Los modelos de lenguaje grandes (LLM) son mucho más que simples interfaces de chat; son la clave definitiva para decodificar el peso emocional incuantificable de tu música. Al desplegar el software de código abierto AudioMuse-AI junto a un router de LLM inteligente como AtlasCloud, puedes devolverle la vida a tus archivos locales y generar listas de reproducción basadas en la vibra pura, la textura sónica y el significado de las letras.
¿Qué es AudioMuse-AI?
AudioMuse-AI es un motor de inteligencia de audio de código abierto y autohospedado, diseñado para integrarse directamente con tu configuración multimedia existente. Actúa como un cerebro impulsado por IA que se conecta directamente a plataformas de música populares autohospedadas como Jellyfin, Navidrome, LMS/Lyrion y Emby.
En lugar de analizar etiquetas de texto, AudioMuse-AI procesa archivos de audio sin procesar. Ejecuta modelos de redes neuronales localizados para extraer vectores acústicos matemáticos complejos (usando CLAP - Contrastive Language-Audio Pretraining) y mapea temas líricos en 72 idiomas admitidos.
Una vez que se completa el escaneo inicial, desbloqueas funciones que hacen que los algoritmos de streaming corporativos parezcan superficiales:
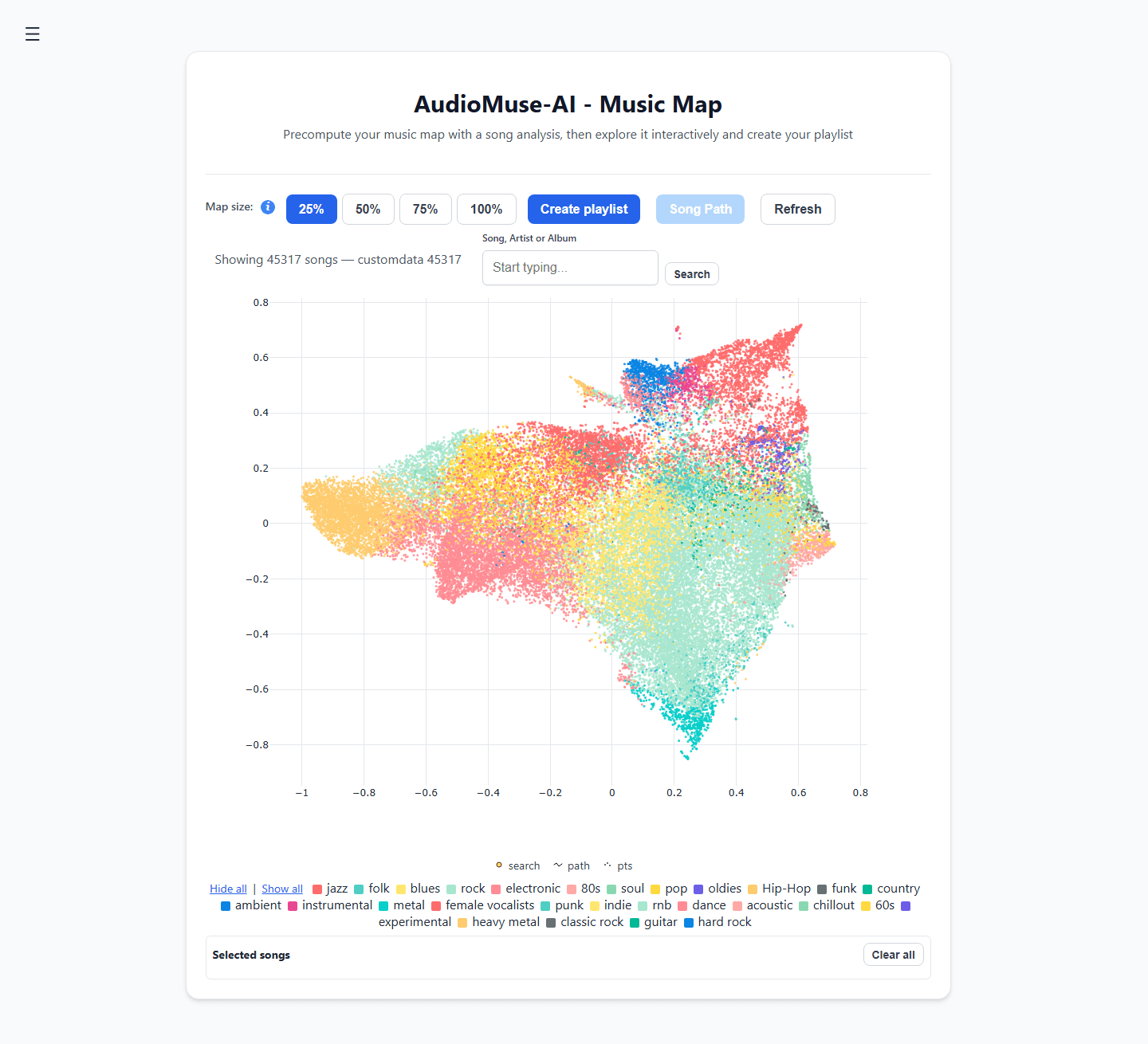
- Agrupación acústica: Traza automáticamente tu biblioteca musical en un "Mapa de música" interactivo en 2D, agrupando pistas según sus ondas de sonido reales en lugar de géneros arbitrarios.
- Rutas de canciones: Elige una pista de funk animada como punto de partida y una pieza ambiental melancólica como destino. El motor calculará automáticamente el puente sónico entre ellas, generando una lista de reproducción que cambia de estado de ánimo de forma gradual e impecable.
- Búsqueda semántica de letras: Busca en tu biblioteca por tema narrativo o conceptos emocionales (por ejemplo, "canciones sobre crecer en un pueblo pequeño"), en lugar de buscar solo coincidencias exactas de letras.
Guía paso a paso: Construyendo tu motor de descubrimiento musical semántico
Veamos cómo configurar un pipeline completo de listas de reproducción semánticas sin metadatos.
Paso 1: Preparación del entorno y despliegue
AudioMuse-AI se puede ejecutar de forma nativa en macOS, Linux y Windows, pero para una configuración de servidor doméstico o NAS, Docker Compose es la ruta más limpia.
Crea un directorio en tu servidor, obtén el archivo docker-compose.yaml oficial de la documentación de despliegue y asegúrate de que tu archivo de entorno esté configurado.
YAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ Nota sobre el hardware: Los modelos de IA subyacentes dependen en gran medida de los conjuntos de instrucciones de CPU modernos. Si ejecutas esto dentro de un entorno virtualizado como Proxmox, asegúrate de que tu tipo de CPU esté configurado en "Host" para habilitar el soporte AVX2. Si lo ejecutas en una CPU virtual QEMU genérica, el contenedor fallará inmediatamente al arrancar.
Inícialo ejecutando:
Bash
plaintext1docker compose up -d
Paso 2: Ejecutar el escaneo del framework de audio
Abre tu navegador y navega a http://TU-IP-DE-SERVIDOR:8000. Te recibirá el asistente de configuración inicial. Vincula tu servidor multimedia (por ejemplo, ingresando tu URL de Navidrome y tu token de API personal).
Una vez vinculado, ve al panel de Análisis y Agrupación y haz clic en "Iniciar análisis".
El motor comenzará a calcular huellas dactilares acústicas. Dependiendo del tamaño de tu biblioteca y de si estás ejecutando el sistema en un mini PC Intel i5 o una Raspberry Pi 5, esta fase de análisis inicial puede tardar desde unos minutos hasta varias horas mientras procesa las formas de onda sin procesar.
Paso 3: Potenciar el cerebro de la IA mediante AtlasCloud
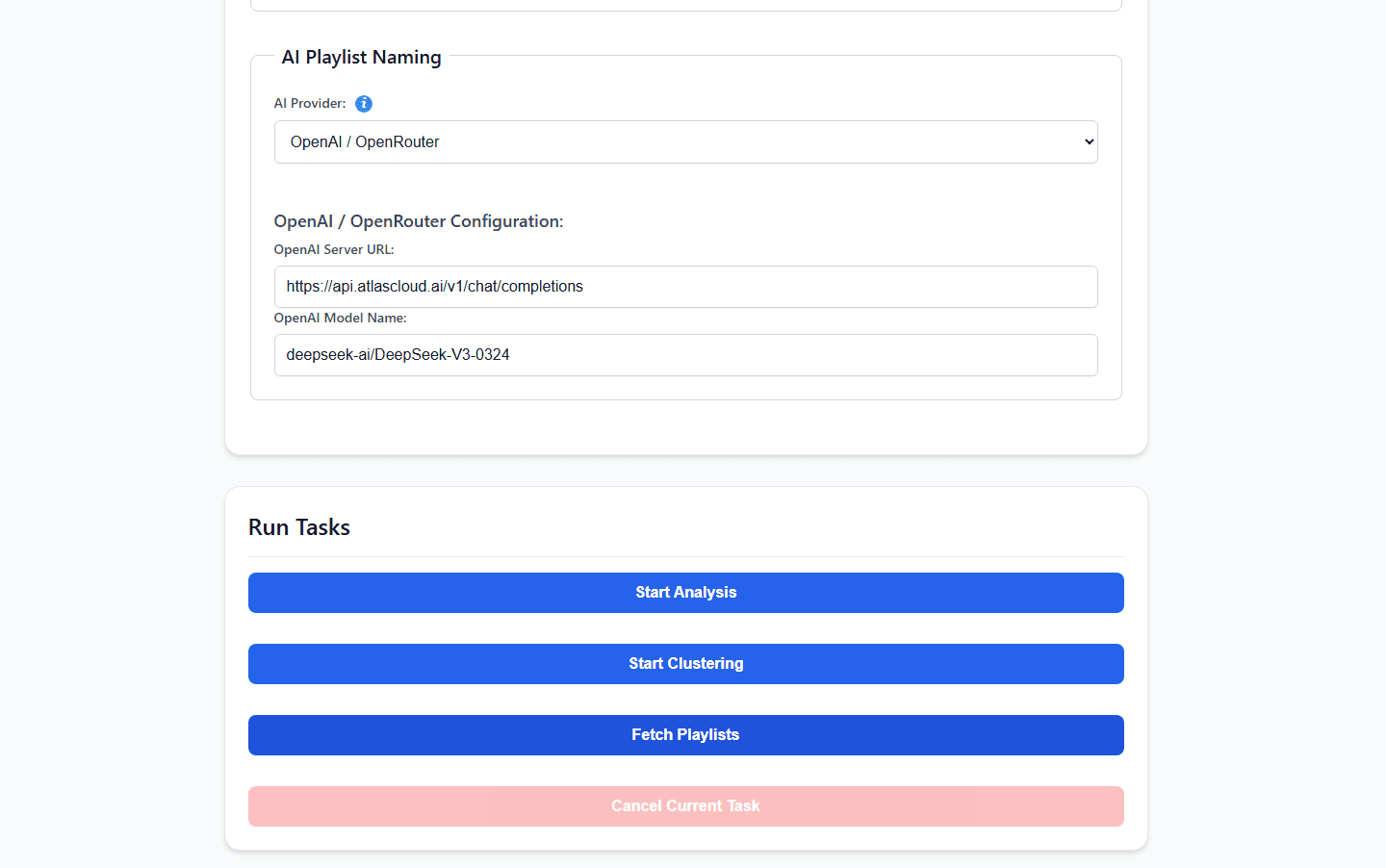
Aquí es donde nos encontramos con un cuello de botella clásico del autohospedaje. AudioMuse-AI cuenta con una interfaz de chat interactiva para listas de reproducción (app_chat.py) y un motor de incrustación de letras profundo. Ejecutar modelos de lenguaje masivos y complejos localmente para manejar estas consultas semánticas puede poner fácilmente la CPU de tu NAS al 100%, causando tiempos de espera de API dolorosos y una generación de listas de reproducción lenta.
Para mantener tu hardware local ligero, fresco y silencioso, podemos descargar el razonamiento semántico pesado a una API externa. Como se documenta oficialmente en la Guía de proveedores de IA compatibles con OpenAI del proyecto, puedes enrutar tus solicitudes a través de AtlasCloud sin problemas utilizando el proveedor central de OPENAI nativo.
Simplemente añade estas variables a la configuración del entorno de despliegue de tu servidor:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
Al aprovechar AtlasCloud, evitas la necesidad de gestionar modelos masivos de varios gigabytes en tu disco duro local. Una sola clave le da a AudioMuse-AI acceso instantáneo a modelos de razonamiento de alto rendimiento para desglosar tus indicaciones de lenguaje natural sobre la marcha, con latencias de procesamiento inferiores a un segundo.
Paso 4: Genera tu primera lista de reproducción basada en "vibra"
Con AtlasCloud manejando el mapeo semántico, navega a la pestaña de Listas de reproducción instantáneas. Probemos la capacidad del sistema para cruzar fronteras tradicionales. Escribe una instrucción altamente abstracta:
"Dame una vibra de conducción nocturna bajo la lluvia. Comienza acústico y lento, pero haz la transición hacia algo con un pulso electrónico conductor hacia el final."
AtlasCloud procesa la intención emocional central de tu solicitud, pasa el plano estructural de vuelta al índice vectorial local de AudioMuse-AI y devuelve instantáneamente una selección bellamente curada. Haz clic en "Exportar al servidor multimedia" y la lista de reproducción personalizada se enviará instantáneamente a la aplicación de música de tu teléfono a través de Jellyfin o Navidrome.
Comparativa técnica: IA de audio local vs. La competencia
| Característica | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
| Privacidad y control | Propiedad completa. Los datos permanecen locales; consultas de LLM proxy segura. | Semiprivado. Requiere cuenta propietaria y Plex Pass activo. | Privacidad cero. Tus registros de escucha se monetizan para seguimiento publicitario. |
| Dependencia de metadatos | Ninguna. Analiza formas de onda de audio y temas líricos directamente. | Alta. Depende en gran medida de etiquetas precisas antes del análisis. | Absoluta. Depende totalmente de etiquetas de discográficas y IDs de bases de datos. |
| Rendimiento inicial | Perfecto. Puede analizar una pista indie local oscura al instante. | Pobre. Falla al contextualizar pistas si no coinciden en la base de datos de Plex. | Terrible. Si una canción carece de millones de reproducciones, el algoritmo la ignora. |
| Búsqueda semántica | Avanzada. Entiende instrucciones en lenguaje natural complejo vía LLM. | Inexistente. Limitado a filtros básicos (año, género, etiquetas de estado de ánimo). | Moderada. Buena en análisis de texto, pero estrictamente limitada al catálogo. |
Advertencias técnicas y resolución de problemas de producción
- El error de reanálisis de letras VNNI: Si actualizaste recientemente tu stack de contenedores a las últimas versiones de AudioMuse-AI, presta mucha atención a la arquitectura de tu CPU. Las revisiones anteriores del modelo de incrustación multilingüe GTE podían producir mapeos vectoriales degradados en CPUs antiguas que carecían de conjuntos de instrucciones VNNI (hardware anterior a 2019). Si ejecutas en tu host Linux y no obtienes resultados, deberías eliminar tus tablas de base de datos heredadas usando la CLI de PostgreSQL y volver a activar un escaneo de letras fresco para obtener resultados de búsqueda semántica limpios y precisos.text
1grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo - Ajustes de tiempo de espera del servidor multimedia: Al sincronizar listas de reproducción vastas que contienen más de 500 pistas de vuelta a Navidrome, los apretones de manos (handshakes) de sincronización inicial podrían exceder los límites predeterminados del proxy. Si ves caídas en los registros, consulta la guía de parámetros oficiales para ajustar los indicadores de tiempo de espera de tu servidor.
Preguntas frecuentes
¿Por qué falla mi prueba de conexión a Jellyfin durante la configuración?
Esto suele deberse a un formato incorrecto de la URL base o a un token de API no válido. Asegúrate de estar utilizando la dirección HTTP/HTTPS completa, incluido el puerto (por ejemplo,
1http://192.168.1.50:8096¿Puedo ejecutar AudioMuse-AI en un servidor antiguo sin conjuntos de instrucciones AVX2?
Sí, pero no puedes usar las imágenes estándar de Docker. Deberás extraer explícitamente la imagen especial de Docker etiquetada con el sufijo
1-noavx21neptunehub/audiomuse-ai:latest-noavx2¿Cómo mejora la API de AtlasCloud la velocidad de respuesta de app_chat.py?
Cuando interactúas con el asistente de listas de reproducción conversacional, el sistema debe transformar tus comentarios en esquemas JSON estructurados. Procesar este texto en la CPU de un servidor local puede llevar entre 10 y 30 segundos por mensaje. Enrutar estas solicitudes específicas a través de un socio en la nube optimizado como AtlasCloud entrega respuestas en milisegundos, asegurando que la memoria de tu servidor local permanezca libre para transmitir archivos FLAC de alta tasa de bits sin interrupciones.






