Claude Code cuesta alrededor de USD13 por desarrollador por día activo, y la automatización intensa puede elevar esa factura a entre USD500 y USD2,000 por ingeniero cada mes (CloudZero, 2026). Para un equipo de 50 personas, esto representa un gasto de cinco cifras que aparece de la nada. Si su factura de programación con IA se disparó el último trimestre y nadie puede explicar por qué, no está solo, y la solución rara vez es "usar menos la IA".
El verdadero problema es que las herramientas de programación basadas en agentes consumen tokens de una forma fundamentalmente distinta a una ventana de chat, y la mayoría de los equipos pagan el precio completo por tokens que podrían obtener a una fracción del costo. Esta guía recorre siete tácticas concretas para reducir el costo de tokens en la programación con IA, con las cifras que respaldan cada una y los cambios de configuración exactos para hacerlas funcionar.
Conclusiones clave
- Las herramientas de programación con agentes consumen de 10 a 100 veces más tokens que el chat, porque el contexto completo se vuelve a enviar en cada llamada a la herramienta (LeanOps, 2026).
- El almacenamiento en caché de prompts (prompt caching) es el cambio de mayor impacto: las lecturas de caché cuestan aproximadamente el 10% de los tokens de entrada estándar, y un equipo redujo su gasto total en LLM en un 59% solo con esto.
- Cambiar la programación diaria a modelos de pesos abiertos como GLM, Kimi y DeepSeek puede reducir el costo por token en un 80% o más en comparación con los modelos de frontera, con una brecha de calidad menor de lo que muchos esperan.
- Enrutar todas sus herramientas a través de una única pasarela permite mantener un presupuesto único, una API key y precios consistentes, en lugar de pagar precios minoristas a cinco proveedores distintos.
Por qué el costo de tokens de programación con IA se sale de control
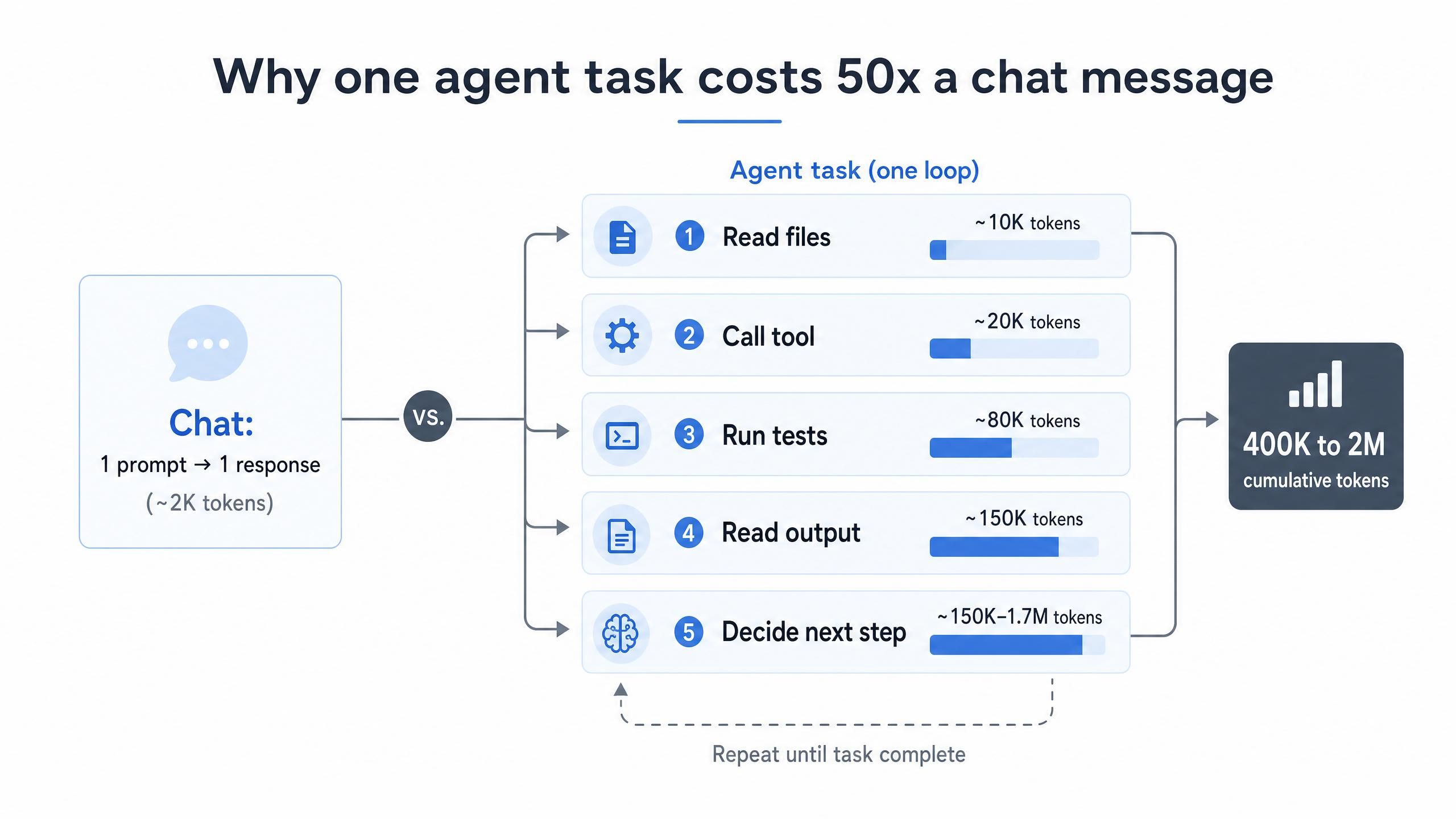
La razón principal por la que el costo de tokens de programación con IA es tan alto es estructural, no de comportamiento. Un intercambio de chat envía un prompt y recibe una respuesta. Un agente hace algo muy diferente: lee archivos, llama a herramientas, ejecuta pruebas, lee el resultado y decide la siguiente acción. Cada uno de esos pasos de razonamiento reenvía el contexto acumulado, por lo que el uso de tokens aumenta con cada bucle. Por esta razón, los agentes de IA consumen tokens de 10 a 100 veces más rápido que los chatbots (LeanOps, 2026).
Las cifras crecen rápidamente. Una sola tarea de agente no trivial puede procesar de 400,000 a 2,000,000 de tokens de entrada acumulados a través de la API a medida que la ventana de contexto se llena y se rellena (Morph, 2026). Multiplique eso por decenas de tareas al día en todo un equipo, y la factura mensual deja de ser un error de redondeo.
Esta no es una preocupación hipotética para grandes organizaciones. Según un informe cubierto por The Next Web, Microsoft retiró la mayoría de sus licencias internas de Claude Code en parte debido al costo, con facturas por ingeniero que ascendían a un rango de USD500 a USD2,000 (The Next Web, 2026). Cuando una de las organizaciones de ingeniería con más recursos del mundo se estremece ante la factura, vale la pena entender a dónde van realmente los tokens antes de intentar reducirlos.
Cómo reducir el costo de tokens de programación con IA sin perder velocidad
La buena noticia es que casi ninguna de estas tácticas requiere escribir menos código o supervisar al agente. Funcionan eliminando el desperdicio, reajustando el precio del mismo trabajo y asignando cada tarea al modelo más barato capaz de realizarla. Aquí están las siete que más influyen, aproximadamente en orden de esfuerzo frente a beneficio.
Táctica 1: Utilice el almacenamiento en caché de prompts para reducir el costo
El almacenamiento en caché de prompts es el cambio único de mayor impacto. Cuando un agente reenvía el mismo prompt del sistema, definiciones de herramientas y contexto de archivos en cada paso, el caché permite que el modelo lea ese contenido repetido desde la memoria en lugar de reprocesarlo. Las lecturas de caché tienen un precio de aproximadamente 0.10 veces la tasa de entrada estándar, un descuento del 90% en la parte repetida de cada solicitud (Finout, 2026).
El detalle que vale la pena conocer: las escrituras en caché cuestan ligeramente más que un token de entrada normal, alrededor de 1.25 veces la estándar por una ventana de cinco minutos. Por lo tanto, el almacenamiento en caché vale la pena cuando el contexto se reutiliza dentro de la ventana de tiempo de vida, que es exactamente el patrón que produce un agente. El impacto en el mundo real no es teórico. El equipo de ProjectDiscovery documentó una reducción del 59% en el costo total de LLM después de implementar el almacenamiento en caché de prompts en su canalización (ProjectDiscovery, 2026).
Si utiliza Claude Code o un agente compatible, confirme que el almacenamiento en caché esté habilitado y que el prompt del sistema y los contextos de archivos grandes se encuentren en bloques almacenables en caché. Este cambio suele ofrecer la mayor caída porcentual en la factura.
Táctica 2: Ajuste el modelo a la tarea para reducir el costo
La mayoría de los equipos enrutan cada solicitud a su modelo más capaz, lo cual es como usar un camión de carga para comprar comestibles. El patrón más inteligente es reservar el modelo de frontera costoso para el trabajo que realmente lo necesita, y enviar todo lo demás a uno más barato.
Una división práctica se ve así:
- Razonamiento, arquitectura, depuración compleja: un modelo de primer nivel donde la calidad justifica el precio.
- Generación y edición de código cotidiana: un modelo abierto de nivel medio sólido.
- Tareas de fondo de alto volumen, clasificación, código repetitivo (boilerplate): el modelo capaz más barato.
Los ahorros son dramáticos porque la diferencia de precio es enorme. En el extremo económico, DeepSeek V4 Flash cuesta alrededor de USD0.14 por millón de tokens de entrada, mientras que los modelos de frontera cuestan muchas veces más (Codersera, 2026). Destinar el 80% de su volumen de tokens a un modelo que cuesta una fracción, manteniendo el modelo premium para el 20% que lo necesita, puede reducir el gasto total en más de la mitad sin una caída notable en la calidad del resultado.
Táctica 3: Mantenga la ventana de contexto reducida
Debido a que cada token en el contexto se reenvía en cada paso del agente, una ventana de contexto inflada es un impuesto que se paga repetidamente. Dos hábitos ayudan. Primero, defina el alcance de cada tarea para que el agente solo cargue los archivos que necesita en lugar de todo el repositorio. Segundo, inicie una sesión nueva al cambiar de tarea en lugar de dejar que una conversación acumule cientos de miles de tokens obsoletos.
Un modelo mental útil: si no pegaría un archivo en un chat para responder a una pregunta, no lo deje en el contexto del agente. Recortar una ventana de contexto de 200,000 tokens a 40,000 tokens no solo ahorra una vez. Ahorra en cada llamada a la herramienta durante el resto de esa tarea, que es donde la capitalización funciona a su favor.
Táctica 4: Cambie a modelos de pesos abiertos para reducir costos
Esta es la táctica con los ahorros más grandes y las suposiciones más obsoletas. Los modelos de programación de pesos abiertos lanzados en 2026 son genuinamente buenos. En SWE-Bench Pro, un modelo de frontera líder obtiene alrededor de 91, mientras que Kimi K2.6 alcanza 76.8 y DeepSeek V4 Pro se sitúa cerca de 77 (Codersera, 2026). Existe una brecha real en el benchmark más difícil, pero para el trabajo rutinario de funciones, refactorizaciones y escritura de pruebas, la diferencia es mucho menor que la diferencia de precio.
Y la diferencia de precio es el punto clave. Los modelos de pesos abiertos como GLM, MiniMax, Kimi y DeepSeek cuestan una pequeña fracción de los precios de frontera por token. Para la mayoría de la programación diaria, un modelo abierto maneja el trabajo a una fracción del costo. La fricción ha sido históricamente el acceso: hacer malabarismos con cuentas separadas, claves separadas y precios inconsistentes entre proveedores.
Aquí es donde una pasarela (gateway) de programación unificada cambia los números. Una plataforma como Atlas Cloud agrega los principales modelos de pesos abiertos detrás de una única API y un saldo de crédito común, por lo que puede apuntar Claude Code, Codex o OpenClaw a GLM-5.1 hoy y a Kimi K2.6 mañana sin reconfigurar nada. Atlas Cloud publica multiplicadores de crédito por modelo que se traducen en ahorros de aproximadamente 45% a 55% frente a los precios oficiales de API de los modelos, y la empresa posiciona su tasa de crédito como más económica que OpenRouter para los mismos modelos.
Aquí hay una muestra de cómo sus multiplicadores de crédito se traducen en modelos de programación populares:
| Modelo | Contexto | Multiplicador Entrada | Multiplicador Salida | Ahorro aprox. vs oficial |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
Fuente: Reglas de crédito del Plan de Programación de Atlas Cloud. Costo de crédito = tokens de entrada × multiplicador de entrada + tokens de salida × multiplicador de salida.
Táctica 5: Procesamiento por lotes de tareas de fondo para reducir el costo
No todos los tokens necesitan gastarse a precios interactivos en tiempo real. Las evaluaciones nocturnas, los trabajos de clasificación grandes, los procesos de documentación y las refactorizaciones masivas no necesitan a un humano esperando, lo que significa que pueden ejecutarse a través de canales de procesamiento por lotes (batch) más baratos o en el modelo de menor costo disponible. Trasladar este volumen no urgente fuera de su modelo interactivo premium es dinero encontrado, porque es trabajo por el que ya estaba pagando el precio minorista completo sin beneficio de calidad del precio más alto.
El principio es simple: separe los tokens de "estoy esperando esto" de los tokens de "esto puede terminar durante la noche", y asígneles precios diferentes. Para la mayoría de los equipos, una parte sorprendente del volumen total de tokens resulta ser del tipo nocturno.
Táctica 6: Enrute todas las herramientas a través de una sola pasarela
La proliferación de herramientas infla silenciosamente el costo de tokens de IA. Un desarrollador típico podría usar Claude Code en la terminal, Codex para algunas tareas, Cursor en el editor y un par de agentes adicionales, cada uno con su propia suscripción, su propia clave y su propia facturación opaca. Se pierde la capacidad de ver el gasto total y se paga el precio minorista en todas partes.
Consolidar todo en un endpoint compatible con OpenAI resuelve ambos problemas. Debido a que Atlas Cloud expone una URL base y un fondo de crédito que funciona en Codex, Claude Code, OpenClaw, OpenCode, Cursor y llamadas directas a la API, obtiene una sola factura, un presupuesto y un lugar para cambiar de modelo. Sus planes van desde un nivel inicial de USD10 al mes hasta niveles superiores para equipos más pesados, y los paquetes de pago por uso tienen un descuento del 41%, por lo que puede ajustar el compromiso al uso real en lugar de adivinar.
Apuntar Claude Code a la pasarela es cuestión de un solo archivo de configuración. En macOS o Linux, edite
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Para los usuarios de Codex, el equivalente vive en
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.jsonTáctica 7: Establezca presupuestos y monitoree el costo
No puede reducir lo que no puede ver. Los equipos que fueron sorprendidos por facturas enormes casi siempre compartían un rasgo: falta de controles de gasto y falta de visibilidad por desarrollador. La solución es poner un límite al consumo antes de que comience el mes, no después de que llegue la factura.
Un plan basado en créditos con una cuota diaria hace esto de forma estructural. En lugar de un medidor abierto, una suscripción mensual que refresca una asignación fija de créditos cada día a medianoche limita el radio de explosión de un bucle de agente desbocado, mientras que los paquetes de pago por uso absorben picos ocasionales una vez que se agota la asignación diaria. Cuando necesita escalar, las actualizaciones prorrateadas significan que solo paga la diferencia. El flujo de actualización de Atlas Cloud, por ejemplo, carga el valor restante contra el nuevo nivel, por lo que un movimiento a mitad de ciclo puede costar solo unos pocos dólares en lugar de un plan nuevo completo.
Una comparación de costos real: El costo de tokens de IA entre modelos
Para hacer concretos los ahorros, considere un desarrollador que procesa aproximadamente 1.5 millones de tokens de entrada y 300,000 de salida a través de su agente en un día ocupado, una cifra realista dado que las tareas individuales pueden alcanzar siete dígitos de entrada acumulada. En un modelo de frontera con un precio cercano a USD5 por millón de entrada y USD25 por millón de salida, eso es aproximadamente USD7.50 en entrada más USD7.50 en salida, o alrededor de USD15 por día de desarrollador, lo que se alinea con la cifra de USD13 por día activo citada ampliamente (CloudZero, 2026).
Ejecute el mismo volumen a través de un modelo de pesos abiertos como GLM o Kimi a través de una pasarela con descuento, y la parte de entrada por sí sola cae un 70% o más, con la salida siguiendo de cerca. Agregue el almacenamiento en caché de prompts y el contexto repetido que domina las cargas de trabajo de los agentes se factura a una décima parte de la tarifa. Si combina las tres tácticas (caché + modelo más barato + contexto reducido), un día de desarrollador de USD15 puede aterrizar de forma realista cerca de USD3 a USD5 sin cambiar la forma en que nadie escribe código.

Las cifras exactas variarán según su carga de trabajo, pero la tendencia se mantiene: la mayor parte del costo de tokens de programación con IA es contexto repetido ejecutándose a través de un modelo sobrevalorado, y ambos aspectos son solucionables.
Poniéndolo todo junto: una configuración que mantiene bajo el costo
Si desea una configuración inicial que capture la mayoría de los ahorros con un esfuerzo mínimo, se ve así: use un modelo de pesos abiertos como GLM-5.1 o Kimi K2.6 como su modelo de programación predeterminado, mantenga un modelo de frontera disponible para razonamiento difícil, habilite el almacenamiento en caché de prompts en todas partes, defina tareas de alcance estrecho para mantener el contexto reducido y enrute cada herramienta a través de un único endpoint compatible con OpenAI con un presupuesto diario fijo.
Esa combinación aborda cada factor de costo a la vez: reajusta el precio de los tokens, deja de pagar por contexto repetido y limita el riesgo. Los equipos que deseen esto consolidado bajo una sola clave y un solo presupuesto pueden activarlo a través de la consola del Plan de Programación de Atlas Cloud, que admite los principales modelos de pesos abiertos y las herramientas de programación comunes desde el primer momento. La configuración toma unos minutos; los ahorros se repiten cada día.
Preguntas frecuentes sobre el costo de tokens de programación con IA
¿Por qué mi costo de tokens de programación con IA es mucho más alto que el de mi uso de chat?
Porque los agentes reenvían el contexto completo acumulado en cada paso de razonamiento, mientras que el chat envía cada prompt una vez. Esa diferencia estructural significa que los agentes consumen de 10 a 100 veces más tokens que el chat para un trabajo comparable (LeanOps, 2026), por lo que unas pocas docenas de tareas de agente pueden empequeñecer un mes de uso casual de chat.
¿Cuál es la forma más rápida de reducir el costo de tokens de programación con IA?
Habilite el almacenamiento en caché de prompts. El contexto repetido en las cargas de trabajo de agentes se factura aproximadamente al 10% de la tarifa de entrada estándar una vez almacenado en caché (Finout, 2026), y al menos un equipo de ingeniería reportó una caída del 59% en el costo total de LLM solo gracias al caché. No requiere ningún cambio en su forma de trabajar, lo que lo convierte en el mayor beneficio con el menor esfuerzo.
¿Son los modelos de pesos abiertos más baratos lo suficientemente buenos para el trabajo de programación real?
Para la mayoría de las tareas cotidianas, sí. En el benchmark más difícil, SWE-Bench Pro, los mejores modelos abiertos obtienen puntuaciones en el rango alto de los 70 frente a alrededor de 91 para los modelos de frontera (Codersera, 2026), pero el trabajo de funciones rutinarias, refactorizaciones y pruebas rara vez estresa esa brecha. Mantenga un modelo de frontera en espera para razonamientos genuinamente difíciles y envíe el resto a un modelo abierto.
¿Cuánto puedo ahorrar realmente en el costo de tokens de programación con IA?
Combinar las tácticas principales (caché de prompts, un modelo predeterminado más barato y un contexto reducido) suele reducir el día de desarrollador de alrededor de USD15 al rango de USD3 a USD5 según las tarifas publicadas por token. Los ahorros se acumulan en todo un equipo, razón por la cual una factura mensual de cinco cifras suele estar a una reducción porcentual de dos dígitos de ser razonable.
¿Tengo que cambiar de herramientas para reducir mi costo de tokens?
No. La mayoría de los ahorros provienen de cómo se fijan los precios y se reutilizan los tokens, no de qué cliente utilice. Apuntar sus herramientas existentes, ya sea Claude Code, Codex o OpenClaw, a un endpoint compatible con OpenAI con descuento es un cambio de configuración, no una migración, por lo que su flujo de trabajo permanece igual mientras la factura disminuye.
Conclusión
El costo de tokens de programación con IA parece un misterio hasta que ve el mecanismo: los agentes reenvían el mismo contexto una y otra vez, y la mayoría de los equipos pagan precios de modelo de frontera por todo ello. Corrija esas dos cosas con almacenamiento en caché de prompts, enrutamiento de modelos más inteligente, contexto reducido y una única pasarela con descuento, y la factura se reducirá a la mitad o más sin que nadie escriba una línea de código de manera diferente. Comience con el caché esta semana, audite qué tareas realmente necesitan su modelo más caro y consolide sus herramientas en un solo presupuesto. La configuración toma una tarde; los ahorros son permanentes.






