DeepSeek v4: Todo lo que sabemos hasta ahora – Funcionalidades, fecha de lanzamiento y cómo acceder a través de Atlas Cloud
Introducción: ¿Qué es DeepSeek v4?
AtlasCloud amplía su arsenal de IA generativa con la próxima incorporación de DeepSeek v4.
- Qué es: El modelo insignia más reciente del equipo de DeepSeek. Si DeepSeek v3.2 establece el estándar para modelos de programación de código abierto rentables, v4 traspasa los límites de la lógica y la memoria utilizando tecnologías patentadas de Hiperconexiones Restringidas por Variedad (mHC) y Memoria Engrama (Engram Memory).
- Ventaja clave: Más allá de generar fragmentos de código, v4 actúa como un arquitecto senior, comprendiendo estructuras completas de repositorios para el razonamiento entre archivos y la corrección de errores complejos.
- Estado: Lanzamiento próximo (previsto para mediados de febrero de 2026; lee nuestro análisis detallado sobre qué esperar de DeepSeek V4).
¿Por qué estamos seguros de que DeepSeek v4 cambiará las reglas del juego? Porque resuelve el mayor problema de la industria: la IA necesita recordar y comprender la lógica de un proyecto.
📣 Actualización — 24 de abril de 2026: DeepSeek-V4 se ha lanzado oficialmente. Lee nuestra cobertura completa sobre lo que realmente se ha publicado, incluida la nueva arquitectura de atención dispersa, el contexto de 1M de tokens y los resultados en los benchmarks de agentes en Lanzamiento de la vista previa de DeepSeek-V4.
Análisis técnico: Funcionalidades clave
Para desafiar a Claude Opus 4.5, DeepSeek ha reconstruido el modelo desde cero. Los documentos filtrados indican un cambio fundamental en cómo el modelo maneja la memoria y la estabilidad lógica. Analicemos los cuatro pilares de esta actualización.
Arquitectura: Razonamiento lógico superior
-
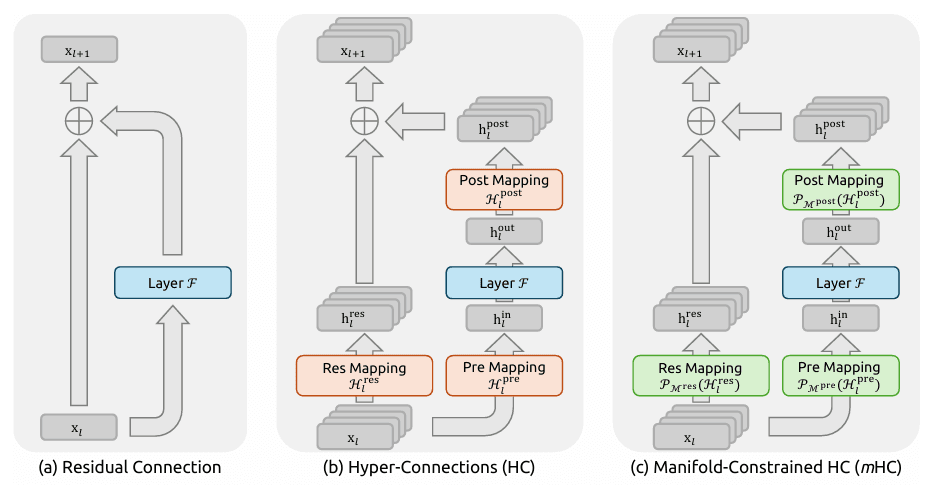
Hiperconexiones Restringidas por Variedad (mHC)
- El concepto: DeepSeek v4 inventa un nuevo método de "cableado neuronal". Las conexiones tradicionales a menudo pierden información en redes profundas, pero mHC actúa como una "superautopista lógica" para el cerebro de la IA.
- El resultado: Al manejar una lógica masiva y compleja (como refactorizar miles de líneas de código), el modelo aprende más rápido y retiene mejor la lógica. Esto elimina las "alucinaciones lógicas" e inconsistencias comunes en la generación de contextos largos.
Eficiencia: Menores costes de inferencia
-
Mixture-of-Experts (MoE) 2.0
- El concepto: Aunque v4 es un gigante en parámetros (cientos de miles de millones), utiliza una arquitectura MoE optimizada para activar solo a los "expertos" más relevantes para cada token.
- El resultado: Logra un equilibrio perfecto entre alta capacidad (base de conocimiento masiva) y escalado eficiente (funcionando tan ligero como un modelo más pequeño).
-
Atención dispersa (Sparse Attention)
- El concepto: Al abandonar el método de fuerza bruta de escanear todo el texto, el modelo ahora se enfoca inteligentemente solo en la información clave. Esto reduce drásticamente los costes de computación y acelera el procesamiento de contextos largos.
Memoria: Gestión inteligente del contexto
-
Memoria Engrama (Almacenamiento y recuperación selectivos)
- El concepto: La IA deja de memorizar mecánicamente y empieza a "comprender". Reconoce estructuras de proyectos, sigue convenciones de nombres (snake_case vs. camelCase) e identifica patrones de programación (imitando los patrones de fábrica específicos de tu equipo).
- El resultado: Programa como un empleado titular.
-
Multi-Head Latent Attention (MLA)
- El concepto: Piénsalo como una "taquigrafía avanzada". Donde otros modelos necesitan 100 tokens para almacenar información, MLA la comprime en 10 símbolos clave.
- El resultado: Cuando se necesita recuperar información, el modelo reconstruye matemáticamente el significado original sin pérdidas. Esto mantiene una retención de detalles increíble con un uso de VRAM significativamente menor.
Aplicación: Ingeniería en el mundo real
- Comprensión a nivel de repositorio y corrección de errores
- El objetivo no es solo escribir una función, sino controlar el código base. En las pruebas de SWE-bench, DeepSeek v4 apunta a resolver más del 80.9% de los problemas complejos del mundo real mediante la comprensión de dependencias entre archivos.
Casos de uso: Reducción de costes y aumento de la eficiencia
DeepSeek v4 está diseñado para la ingeniería avanzada. Así es como se compara con la competencia:
Refactorización de código legado
Para sistemas antiguos, caóticos y sin documentación, la arquitectura mHC es un salvavidas. Rastrea dependencias lógicas de larga distancia para una refactorización segura.
- VS GPT-4o: GPT-4o a menudo sufre de "alucinaciones lógicas" (inventar llamadas a funciones inexistentes) cuando el contexto supera los 10k tokens. DeepSeek v4 mantiene una consistencia lógica del 100% en contextos largos.
- VS Claude 3.5 Sonnet: Aunque Sonnet tiene una gran calidad, es lento y costoso para trabajos de refactorización masivos. La arquitectura MoE de DeepSeek v4 ofrece velocidades de inferencia ~40% más rápidas a un menor coste en Atlas Cloud.
Desarrollo de funciones a nivel de repositorio
Al agregar una nueva API a un proyecto maduro, v4 utiliza la "Memoria Engrama" para comprender el contexto al instante.
- VS Autocompletado tradicional: Las herramientas estándar a menudo ignoran las normas específicas del proyecto, introduciendo inconsistencias de estilo. DeepSeek v4 imita tu código base existente tan bien que parece un copiar y pegar de tu mejor desarrollador.
Seguimiento de errores de extremo a extremo
Apuntar a una tasa de éxito del 80.9% en SWE-bench significa manejar errores que abarcan el frontend, el backend y las bases de datos.
- VS Claude Opus 4.5 (esperado): Opus 4.5 probablemente será potente pero con un precio premium. DeepSeek v4 ofrece un rendimiento casi SOTA a un precio que permite ciclos iterativos de "reflexión y corrección" sin gastar de más.
📉 La conclusión: ROI para equipos
Para startups y equipos de desarrollo, la combinación de DeepSeek v4 + AtlasCloud ofrece un ROI tangible:
- Productividad: Reduce el tiempo de programación para desarrolladores senior entre un 30-50%.
- Coste: Comparado con alquilar servidores duales RTX 4090 o pagar por APIs de código cerrado, la API integrada de AtlasCloud puede ahorrar a los equipos más del 60% en costes totales de computación.
La línea roja del hardware: ¿Alojarlo localmente? Piénsalo dos veces.
A estas alturas, podrías sentir la tentación de ejecutar este "dios de la programación" en tu máquina local. Pero tenemos que darte un toque de realidad: El rendimiento tiene un precio.
- Entrada mínima: Dual RTX 4090
- Traducción: Estás comprando dos de las GPU de consumo más caras del mercado y conectándolas. El coste de las GPU por sí solas equivale aproximadamente a 3x iPhone 17 Pro Max (o un buen coche usado).
- Recomendado: Single RTX 5090 (modelo insignia de 2026)
- Traducción: Este es el "Ferrari" de las GPU. No solo el precio será altísimo debido a la reventa, sino que la disponibilidad será escasa.
Con los precios de las GPU manteniéndose altos, pregúntate: ¿Vale la pena gastar miles de dólares y lidiar con el ruido de los ventiladores, el calor y la configuración del entorno solo para ejecutar un modelo?
La solución inteligente: Acceso desde el día 0 en Atlas Cloud
No necesitas ser rico para usar DeepSeek v4; solo necesitas ser inteligente. En lugar de comprar "ladrillos electrónicos" que se deprecian, elige la nube.
AtlasCloud está listo para el lanzamiento:
-
Nuestra promesa: Disfruta de tus vacaciones. Déjanos el trabajo sucio del despliegue a nosotros. Monitoreamos los canales de lanzamiento oficiales 24/7.
-
Ventajas principales:
- Acceso instantáneo: Tan pronto como se publiquen los pesos de código abierto, nuestra integración de API estará activa.
- Barrera cero: Sin hardware costoso, sin el infierno de las dependencias CUDA. Solo trae tu Prompt.
- Experiencia sin concesiones: Brindamos soporte completo de contexto, asegurando que el mecanismo de memoria "Engrama" funcione al 100% de su capacidad sin pérdida por cuantización.
Cómo usarlo en Atlas Cloud
Atlas Cloud te permite usar modelos lado a lado: primero en un entorno de pruebas (playground) y luego a través de una única API.
Método 1: Usar directamente en el entorno de pruebas de Atlas Cloud
Método 2: Acceso vía API
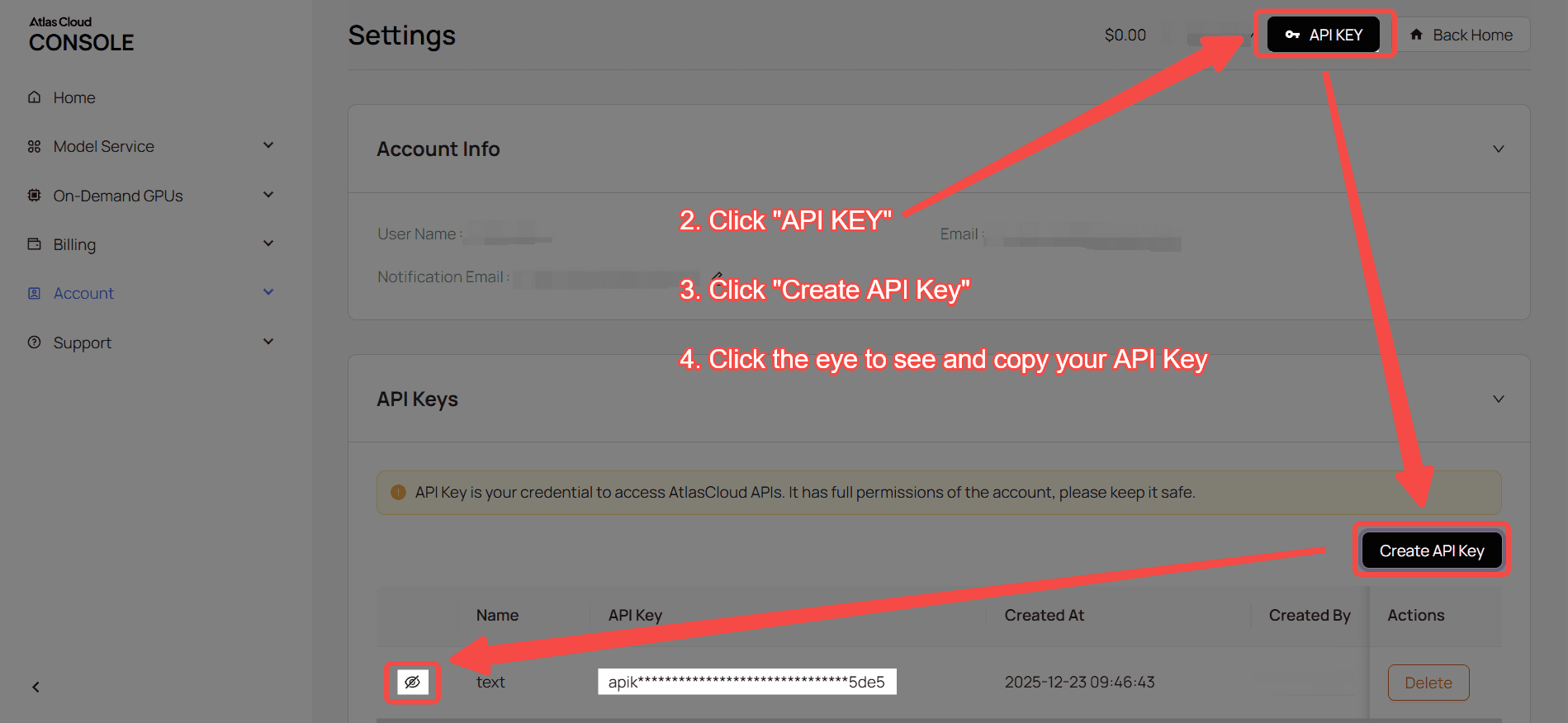
Paso 1: Obtén tu clave API
Crea una clave API en tu consola y cópiala para usarla después.
Paso 2: Consulta la documentación de la API
Revisa el endpoint, los parámetros de solicitud y el método de autenticación en nuestra documentación de API.
Paso 3: Realiza tu primera solicitud (ejemplo en Python)
Ejemplo: generar una respuesta con DeepSeek v3.2:
plaintext1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "cuál es la diferencia entre http y https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






