
Si escribes kernels de GPU, te encuentras en algún punto de un espectro. En un extremo está Triton: rápido de escribir, pero el compilador toma la mayoría de las decisiones sobre el diseño (layout) y la memoria compartida por ti. En el otro extremo está CUTLASS / CuTe: control total, a costa de una gran cantidad de maquinaria de plantillas (templates). TileLang se sitúa en el medio. Escribes Python, pero indicas explícitamente qué reside en la memoria compartida, cómo se organiza el pipeline y cómo los warps dividen el trabajo; el resto lo resuelve una pasada de inferencia de diseño (layout inference).
En esta publicación cubriremos el modelo mental, escribiremos un GEMM y luego pasaremos a un kernel de producción real: el decode de MLA de DeepSeek, donde realmente aparecen las decisiones interesantes. El objetivo no es ser exhaustivos, sino mostrar cómo pensar en mosaicos (tiles) y cómo TileLang se encarga silenciosamente de las partes difíciles. Terminaremos con una historia más típica de producción: un kernel donde la victoria no fue precisamente la velocidad.
El modelo mental
Aquí está la idea completa en tres puntos:
- Un tile es un objeto de primera clase. Un bloque de datos con forma (por ejemplo, block_M × block_K) es propiedad de un thread block, un warp o un hilo, y es operado por estos. Dejas de pensar puramente a nivel de thread block como en Triton, y dejas de gestionar manualmente los hilos individuales como en CUDA.
- Tú colocas los buffers en la jerarquía de memoria. Declaras qué va a la memoria compartida (T.alloc_shared), qué va a los registros (T.alloc_fragment) y qué es local por hilo. Esta es la mayor diferencia con Triton, que oculta la asignación y organización de la memoria compartida dentro del compilador.
- El compilador infiere el mapeo de hilos. Una vez que has definido dónde vive un tile y qué operación se ejecuta en él (copia, gemm, reducción), una pasada de inferencia de diseño lo paraleliza entre hilos y determina los layouts de los registros y de la memoria compartida. Puedes sobrescribirlo cuando lo necesites, pero la mayoría de las veces no es necesario. Esta pasada es la funcionalidad fundamental; cuando lleguemos a MLA verás por qué.
Si vienes de Triton, esta es la equivalencia aproximada:
| Triton | TileLang | |
|---|---|---|
| Granularidad | thread block + vectorización implícita | tile (bloque / warp / hilo) |
| Memoria compartida | gestionada por el compilador | explicit alloc_shared + copy |
| Layout | el compilador decide | inferido, pero puedes anotarlo |
| Pipelining | tl.range + compilador | explícito T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm con política de warp seleccionable |
| Backends | NVIDIA (principalmente) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, más forks de Ascend y MUSA |
En resumen: si deseas un control preciso sobre el bloqueo (blocking), la profundidad del pipeline y la partición de warps sin tener que escribir CUTLASS, TileLang es el punto ideal. Para operaciones elementales simples o fusiones ligeras, Triton sigue siendo más rápido de usar.
Configuración inicial
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # wheel preconstruido, la ruta más fácil
Si vas a modificar las pasadas del compilador, construye desde el código fuente (necesitarás una cadena de herramientas LLVM/CUDA local):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
Escribamos un GEMM
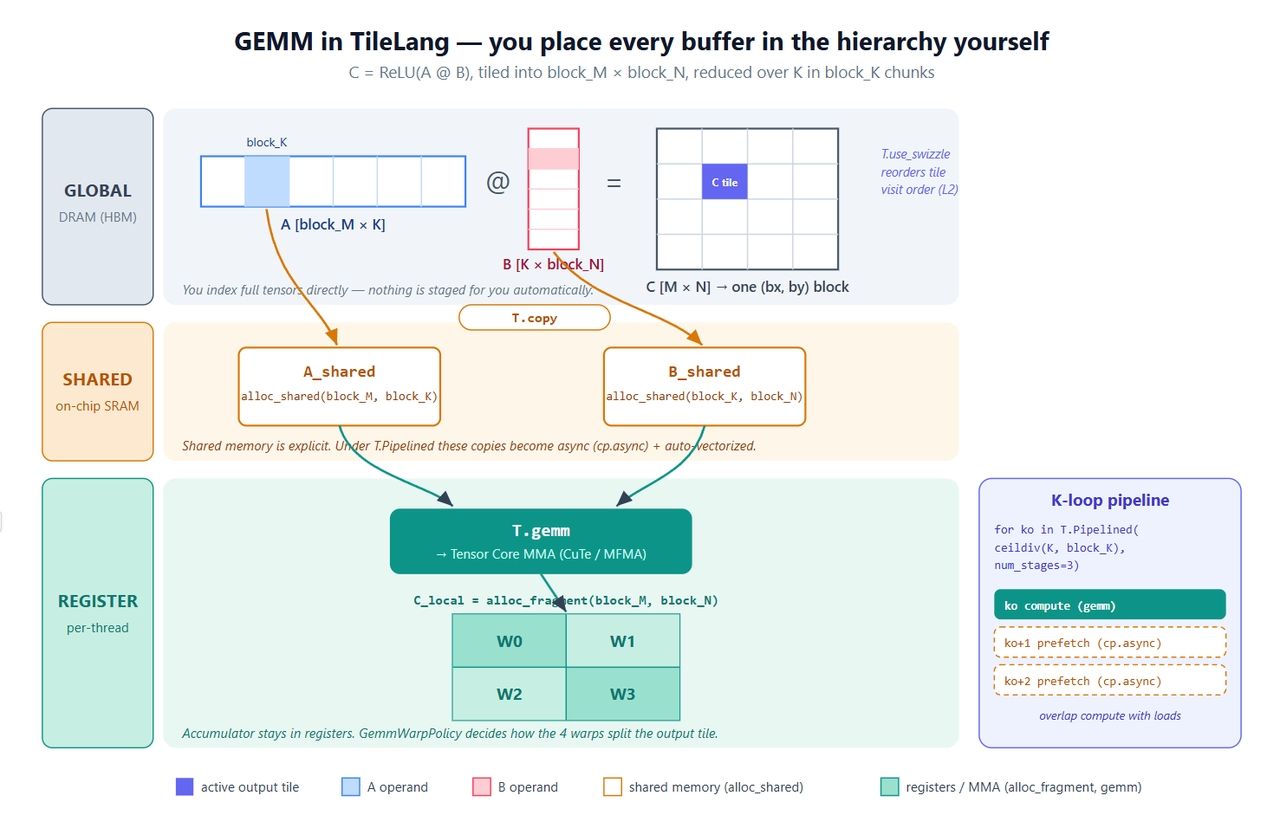
Comenzaremos con el kernel con el que todos empiezan: C = ReLU(A @ B). Es pequeño, pero toca todas las primitivas que importan: buffers explícitos, copia paralela, pipeline de software, llamada a Tensor Core y un swizzle de L2.
python1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # dimensiones de grid: (#bloques a lo largo de N, #bloques a lo largo de M); 128 hilos por bloque 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # Indica explícitamente dónde vive cada tile. 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # memoria compartida 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # acumulador en registros 23 24 T.use_swizzle(panel_size=4, order="col") # opcional: mejor reutilización en L2 25 T.clear(C_local) # limpiar acumulador 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # global -> compartida 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # MMA a nivel de tile 31 32 for i, j in T.Parallel(block_M, block_N): # ReLU fusionado 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # escribir de vuelta 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
Esto es lo que hace cada pieza:
- Tres buffers, tres niveles. A_shared y B_shared residen en memoria compartida; C_local reside en registros. Acumulador en registros, operandos organizados a través de memoria compartida; esa es la receta estándar del GEMM, excepto que aquí tú la escribes. Esa es toda la diferencia con Triton en una línea.
- T.copy es azúcar sintáctico para una copia paralela. Se expande a un movimiento estilo T.Parallel, y el compilador deriva una transferencia global→compartida vectorizada y coalescente a partir de ella. Cuando la copia se encuentra dentro de T.Pipelined, automáticamente se convierte en cp.async.
- T.Pipelined(extent, num_stages=N) es un pipeline de software. num_stages=3 significa triple buffering: mientras calculas el tile-K ko, las cargas para ko+1 y ko+2 ya están en vuelo. En Triton, esto es un flag de compilación; aquí es solo el bucle, lo cual es más fácil de razonar.
- T.gemm(A, B, C) es el matmul a nivel de tile. Se reduce a CuTe/MMA en NVIDIA y a lo equivalente en AMD. También acepta transpose_A / transpose_B y una política=T.GemmWarpPolicy.* que controla cómo los warps dividen el tile de salida. Guarda ese argumento de política: es todo el núcleo del asunto cuando lleguemos a MLA.
- T.use_swizzle reordena cómo se programan los thread blocks para que los bloques adyacentes en L2 se ejecuten cerca en el tiempo. Suele suponer un pequeño porcentaje de ancho de banda gratuito.
La figura a continuación mapea todo esto en el hardware. Vale la pena leerla junto con el código, ya que los puntos etiquetados son exactamente donde TileLang te otorga un control que Triton se reserva para sí mismo.
Algunas primitivas que utilizarás con frecuencia
Puedes escribir la mayoría de los kernels con un vocabulario pequeño:
- Asignar: T.alloc_shared, T.alloc_fragment (registros), T.alloc_local.
- Mover e inicializar: T.copy(src, dst) entre cualquier nivel; T.clear, T.fill.
- Calcular: T.gemm(...); T.Parallel(d0, d1, ...) para bucles de elementos (este es el punto de entrada para la inferencia de diseño); T.reduce_max / T.reduce_sum; matemáticas escalares como T.exp, T.exp2, T.max, T.infinity.
- Programar: T.Pipelined(extent, num_stages=), T.use_swizzle(...), T.annotate_layout(...) cuando necesitas un diseño específico (evitar conflictos de banco, swizzle personalizado).
- Forma dinámica: M = T.dynamic("m") para no recompilar por cada forma (en algunas versiones se llama T.symbolic).
Comprobando tu trabajo
Dos cosas que querrás hacer a menudo. Para ver qué emitió realmente el compilador:
plaintext1print(kernel.get_kernel_source()) # CUDA / HIP generado
Y para medir el tiempo:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latencia: {profiler.do_bench()} ms")
T.print(buf) imprime un tile desde dentro del kernel, y examples/plot_layout del repositorio dibuja el diseño de memoria, lo cual es útil cuando persigues un conflicto de banco o compruebas un swizzle.
Ahora uno real: MLA decode
El GEMM muestra la mecánica. Este siguiente ejemplo muestra por qué son importantes. Analizaremos el kernel de decode de MLA (Multi-Head Latent Attention) de DeepSeek, porque es el ejemplo más claro de por qué TileLang vale la pena. La referencia de TileLang alcanza aproximadamente el rendimiento en H100 de FlashMLA (benchmarked en batch 64/128 en fp16, superando cómodamente a Triton y FlashInfer) en unas 80 líneas de Python. La pregunta interesante es cómo, porque la parte difícil de MLA no es la matemática, sino la presión sobre los registros.
Revisemos el bucle que todos conocen. Cada kernel de la familia FlashAttention tiene la misma forma. Por cada bloque de consulta (query), haces streaming sobre bloques de claves/valores (key/value) y mantienes un máximo y un denominador acumulados, de modo que la matriz de puntuación completa nunca aterriza en la memoria:
plaintext1# acc_s : [block_M, block_N] puntuaciones para este bloque KV 2# acc_o : [block_M, dim] acumulador de salida 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # reescalar salida previa 9 acc_s = exp(acc_s - scores_max) # probabilidades 10 acc_o += acc_s @ V[i]
Tanto acc_s como acc_o quieren permanecer en registros. Para MHA o GQA, eso está bien. Para MLA, no lo está.
Aquí es donde se pone difícil. Las dimensiones de las cabezas (head dimensions) de MLA son grandes: la consulta y la clave tienen 576 de ancho (una parte "nope" de 512 de ancho sin codificación posicional, más una parte "rope" de 64), y el valor es 512. Por lo tanto, acc_o = [block_M, 512], y tiene que permanecer residente en registros durante todo el bucle KV.
Ahora introduzcamos el hardware. En Hopper, la ruta rápida es wgmma.mma_async, que vincula 4 warps (128 hilos) en un grupo de warps (warpgroup) y requiere un M mínimo de 64. Por lo tanto, el M más pequeño que un warpgroup puede poseer es 64, lo que significa que un warpgroup contendría un acumulador de 64 × 512. Eso es demasiado grande para el archivo de registros de un solo warpgroup. Se produce un derrame (spill) y el rendimiento cae en picado.
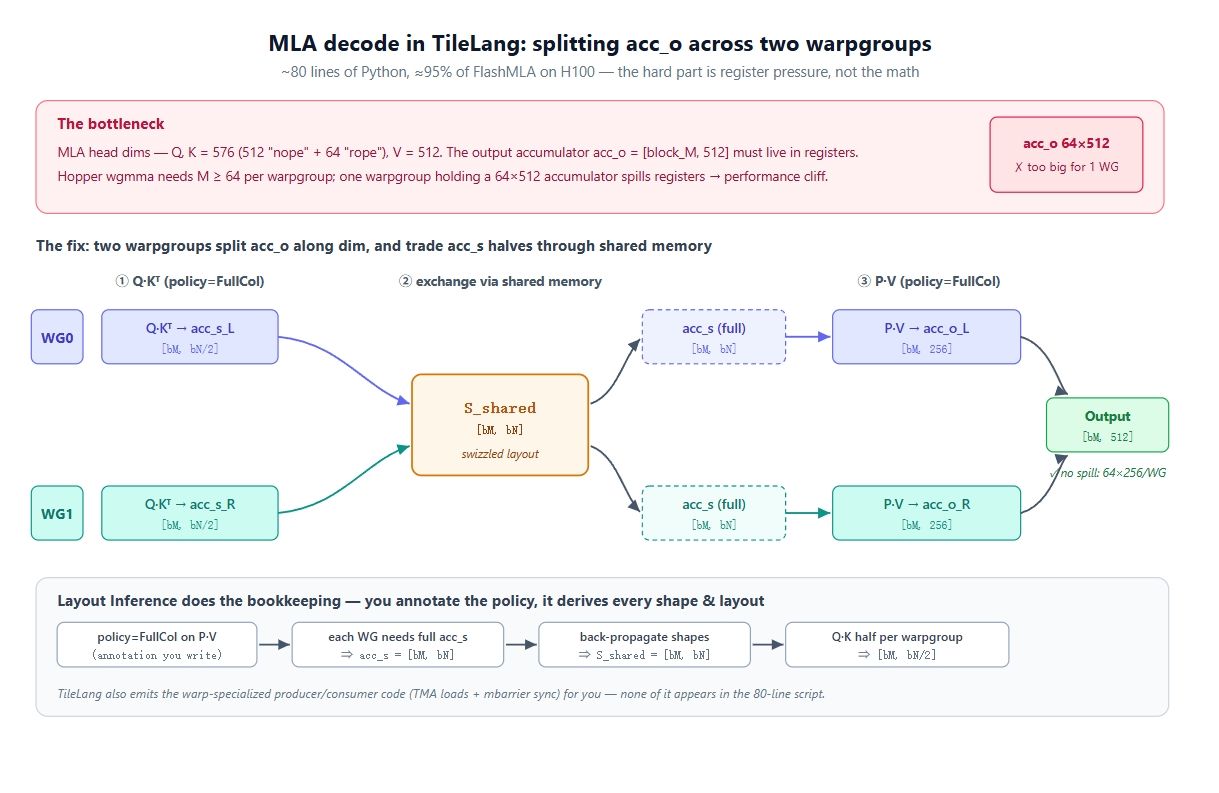
La solución es dividir la salida entre dos warpgroups. No puedes reducir M por debajo de 64, por lo que el único eje que queda es la dimensión (dim). Usa dos warpgroups: WG0 posee acc_o[:, :256], WG1 posee acc_o[:, 256:]. Ahora cada uno tiene un acumulador de 64 × 256, que cabe. Sin embargo, eso crea un segundo problema: el paso P @ V (con policy=FullCol, donde cada warpgroup produce una losa de columna de la salida) necesita la acc_s completa, pero en Q @ K cada warpgroup solo calculó naturalmente la mitad. La resolución es un intercambio en memoria compartida. Durante Q @ K, cada warpgroup escribe su mitad de acc_s en memoria compartida y lee la mitad del otro warpgroup, de modo que después ambos tienen la acc_s completa y pueden calcular su losa de acc_o. El diagrama de arriba es exactamente eso: dividir las puntuaciones, intercambiar a través de S_shared, dividir la salida.
En CuTe tendrías que escribir a mano los diseños, los swizzles, la alineación con Tensor Core y la sincronización productor/consumidor para lograr esto. La razón por la que aquí se reduce a ~80 líneas es la inferencia de diseño.
Analicemos qué hace la inferencia de diseño. Anotas la intención en las llamadas a T.gemm, y esta propaga las restricciones a través del programa por ti:
- policy=FullCol en P @ V significa que cada warpgroup necesita la acc_s completa, por lo que acc_s = [block_M, block_N].
- Eso se propaga hacia atrás al buffer de organización (staging buffer), por lo que S_shared en T.copy(S_shared, acc_s) también es [block_M, block_N].
- Y hacia adelante en Q @ K: con FullCol, la losa de puntuación de cada warpgroup es [block_M, block_N/2].
La idea clave es que nunca escribes ninguna de esas formas. Eliges la política de warp y escribes las matemáticas; las formas, los diseños swizzled y el código productor/consumidor especializado para warps surgen de la inferencia.
El esqueleto del kernel. En el decode de MLA, la consulta se divide en una parte "nope" (Q, dim 512) y una parte "rope" (Q_pe, dim 64), y el latente comprimido sirve tanto como K como V. Así que la puntuación es una suma de dos GEMMs, y la salida es uno más. El bucle interno se ve así (un esqueleto representativo, no exacto línea por línea; consulta example_mla_decode.py):
python1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# softmax en línea 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, reescalar acc_o por scores_scale, reduce_sum en logsum ... 12 13# acc_o += P @ V (V es el mismo KV latente) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
El intercambio de S_shared entre los dos warpgroups es la parte que la inferencia inserta por ti, una vez que las políticas FullCol obligan a que acc_s sea completa por warpgroup.
La parte buena: las optimizaciones son de una sola línea cada una. Aquí es donde TileLang compensa: todo el kit de herramientas de rendimiento son líneas únicas, y la reducción (lowering) complicada se maneja por ti.
- Swizzling de threadblock para reutilización en L2: T.use_swizzle(panel_size, order="row").
- Swizzling de memoria compartida para conflictos de banco: T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)}) — remapeo de direcciones estilo XOR para que los accesos concurrentes se distribuyan entre los bancos en lugar de serializarse.
- Especialización de warp: escribes un script sencillo y se reduce a un warpgroup productor (cargas TMA) más warpgroups consumidores, con toda la sincronización mbarrier generada. Nada de esto aparece en tu código.
- Pipelining: T.Pipelined(range, num_stages) solapa cargas con cálculo; más etapas, más solapamiento, pero más memoria compartida, por lo que es un ajuste.
- Split-KV (estilo FlashDecoding): cuando el batch es pequeño y los SMs están ociosos, divide el contexto KV entre SMs y fusiona. Es un parámetro num_split más un kernel de combinación.
Entonces, el razonamiento verdaderamente difícil —presupuesto de registros frente al suelo de M≥64, quién posee qué a través de warpgroups, el intercambio en memoria compartida— lo expresas eligiendo una política y escribiendo las matemáticas. Todo lo que serían cientos de líneas frágiles en CuTe es inferencia y generación de código. Ese es el argumento de venta, y MLA es donde resulta más convincente.
Uno propio: un RMSNorm de reemplazo directo en AtlasCloud
El último ejemplo es uno de nuestros propios kernels de producción en AtlasCloud, del VAE de generación de video Wan en H100/H200. Es una gran ilustración de la otra cosa en la que TileLang es excelente: cubrir una configuración que un kernel ajustado a mano no puede alcanzar, con un reemplazo limpio.
La configuración. Ya distribuimos un kernel fusionado de RMSNorm + SiLU ajustado a mano. Es rápido y está compilado para las dimensiones ocultas D ∈ {96, 192, 384} que usa una configuración de modelo. Una configuración más nueva necesita anchos de canal como {160, 256, 320, 512, 640, 1024}, así que en esa configuración la ruta rápida ajustada a mano no puede ejecutarse. Escribimos un reemplazo con TileLang para cubrir exactamente ese vacío.
El kernel de TileLang. Un reemplazo directo con la misma interfaz (entrada/salida BTHWC, mismas matemáticas, mismo eps) que soporta cualquier C que sea múltiplo de 32. Dos pasadas, totalmente coalescente, acumulador FP32:
python1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W filas 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # suma de cuadrados en FP32 8 # pasada 1: bucle sobre C en bloques BLOCK_C, acumular suma de cuadrados en FP32 9 # rinv = rsqrt(ss / C + 1e-5) 10 # pasada 2: recargar X, y = silu(x * gamma * rinv), escribir de vuelta
BLOCK_C es 128/64/32 dependiendo de C, para respetar el límite de boxDim ≤ 256 de TMA, y el acumulador FP32 evita que la suma de cuadrados se desborde en FP16. El dispatch mantiene la ruta ajustada a mano donde funciona y solo recurre a esto cuando es necesario:
python1_ATLAS_SUPPORTED_D = (96, 192, 384) 2 3def rms_silu_dispatch(x, gamma, out): 4 if x.shape[-1] in _ATLAS_SUPPORTED_D: 5 atlas_rms_norm_silu(x, gamma, out=out) # mantener la ruta ajustada a mano 6 else: 7 tilelang_rms_silu_bthwc(x, gamma, out=out) # cubrir el vacío
Lo que ganamos. Todo son ventajas, y es un verdadero reemplazo: misma interfaz, mismas matemáticas, mismo eps, por lo que se inserta detrás del dispatch existente sin cambios en el sitio de llamada.
| Qué | Ganancia |
|---|---|
| Configuración no soportada anteriormente | 0 → 1 — ahora funciona (la mejora principal) |
| RMSNorm del bloque de atención vs el norm de PyTorch eager que reemplazó | 42 μs → 20 μs (~2× más rápido) |
| VAE de extremo a extremo a resolución de producción (720×1280, 21 frames) | ~1.79× codificación, ~1.78× decodificación |
La primera fila es el punto real: TileLang nos permitió servir una configuración de modelo que antes no tenía ninguna ruta rápida, sin tocar el kernel ajustado a mano que ya funciona para la otra configuración. Un reemplazo, escrito en Python, y una ruta completa del modelo pasó de "fallar" a "funcionar".
Dónde brilla TileLang
- Control preciso sobre el bloqueo, etapas de pipeline y partición de warps, sin escribir CUTLASS/CuTe.
- Kernels estructuralmente complejos y sensibles al diseño: variantes de GEMM, familia FlashAttention, MLA, atención lineal, GEMM con dequantización fusionada, enrutamiento MoE.
- Cubrir una operación o configuración que tus kernels ajustados a mano no alcanzan (una dimensión oculta fuera del conjunto instanciado, un diseño inusual) — y superando a un fallback eager mientras estás en ello.
- Un cuerpo de kernel único a través de backends (NVIDIA / AMD / forks de proveedores).
- Todo el kit de herramientas de optimización es una llamada a la vez — T.use_swizzle, T.annotate_layout, T.Pipelined, especialización de warp, split-KV — con la reducción manejada por ti.
Conclusión
Lo genial de TileLang es que el razonamiento difícil permanece en tu cabeza, no en el código repetitivo (boilerplate). Tú decides cómo dividir el trabajo entre warps, dónde viven los buffers y qué tan profundo llega el pipeline; luego, la inferencia de diseño y la especialización de warps lo convierten en los diseños de registro, los swizzles y la danza productor/consumidor que de otro modo serían cientos de líneas de CuTe. Eliges una política y escribes las matemáticas. Ese es todo el argumento, y es la razón por la que un kernel de MLA de 80 líneas puede estar junto a uno de CUTLASS ajustado a mano.






