Votre invite a heurté un mur de refus. Non pas parce qu'elle était dangereuse, mais parce qu'un mot-clé a déclenché un filtre.
Les développeurs de la communauté Ollama décrivent cela comme des « vecteurs de refus » : des blocages déclenchés par des mots-clés qui n'ont rien à voir avec un danger réel. Rétro-ingénierie de logiciels malveillants pour la recherche en sécurité, documentation d'études de cas médicaux, création de contenu pour adultes, écriture de fiction sombre. L'IA grand public bloque tout cela. Cette liste classe les meilleurs modèles d'IA non censurés de 2026 selon des données réelles de la communauté, et non des textes marketing. Elle couvre trois catégories : modèles LLM non censurés pour le texte et le code, les meilleurs modèles d'IA locaux non censurés de 2026 pour un déploiement sur matériel privé, et modèles d'IA non censurés de 2026 pour la génération d'images et de vidéos via API. Chaque chiffre est sourcé et horodaté à mai 2026.
Pour une introduction au paysage plus large des outils, les lecteurs novices dans ce domaine trouveront le guide des générateurs d'images IA non censurés comme point de départ utile avant de choisir un modèle spécifique.
Comment nous avons classé les meilleurs modèles d'IA non censurés 2026
En 2026, les nombres de téléchargements de la communauté Ollama fournissent un signal de classement plus fiable que les scores de référence (benchmarks), qui peuvent être sélectionnés pour des communiqués de presse plutôt que pour une performance en situation réelle (Ollama, recherche de modèles non censurés, 2026). Des millions de téléchargements représentent des milliers de configurations matérielles et de types d'invites. C'est plus difficile à manipuler qu'un ensemble d'évaluation organisé.
Trois signaux de classement sont utilisés tout au long de cet article. Pour les modèles non censurés Ollama, le signal principal est le nombre de téléchargements depuis ollama.com, récupéré en mai 2026. Pour les modèles OpenRouter, le classement se base sur le nombre de paramètres et la fenêtre de contexte, car les nombres de téléchargements ne sont pas accessibles publiquement sur cette plateforme. Pour les modèles d'images et de vidéos, le classement se fait par prix par sortie, les coûts les plus bas étant listés en premier au sein de chaque groupe.
La plupart des modèles d'IA non censurés de 2026 tombent dans deux catégories techniques : fine-tunés (ajustés) et abliterés. Les modèles fine-tunés comme la série Dolphin sont entraînés sur des jeux de données qui ne renforcent pas les comportements de refus. Les modèles abliterés ont leurs poids de refus supprimés chirurgicalement. La communauté constate systématiquement que les modèles fine-tunés sont plus stables sur divers types d'invites.
En pratique, les nombres de téléchargements sont également corrélés à la stabilité du modèle. Un modèle qui atteint plus d'un million de téléchargements a été testé sur une large gamme de configurations matérielles, faisant ressortir des bugs et une instabilité que des groupes de test plus restreints manquent totalement.
Quels sont les 5 modèles Ollama non censurés les plus téléchargés ?
En 2026, les cinq modèles ollama non censurés les plus téléchargés totalisent plus de 9,2 millions de téléchargements, llama2-uncensored étant en tête avec 2,6 millions (Ollama, recherche de modèles non censurés, 2026). Ce sont les meilleurs modèles Ollama non censurés de 2026 par validation communautaire, et non par un quelconque benchmark. Le matériel est le principal filtre que la plupart des utilisateurs appliquent en premier : les besoins en VRAM vont de moins de 4 Go à 40 Go dans ce groupe.
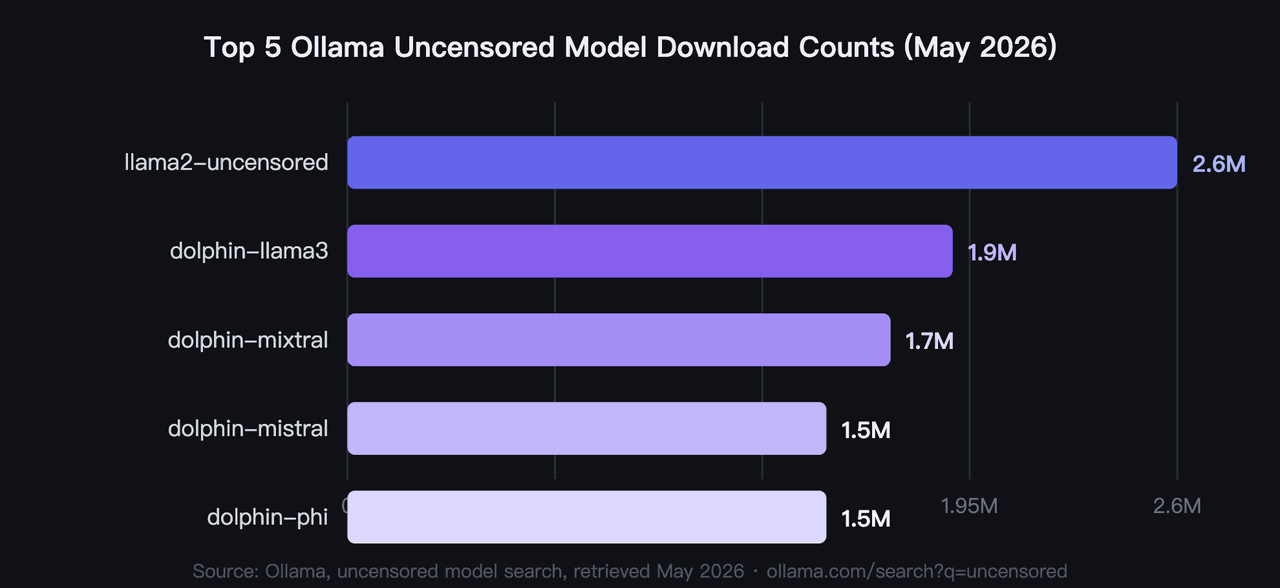
1. llama2-uncensored : Modèle d'IA non censuré le plus téléchargé sur Ollama
La référence communautaire originale pour l'IA locale non censurée. George Sung et Jarrad Hope ont publié cet ajustement pour supprimer le comportement de refus de Llama 2 sans dégrader les capacités générales. C'est le modèle avec lequel la plupart des développeurs commencent, et son nombre de 2,6 millions de téléchargements reflète plus de deux ans d'utilisation réelle. Aucun autre LLM non censuré n'a égalé ce volume de téléchargement.
- Paramètres : 7B ou 70B
- VRAM : ~6 Go (7B) ; ~40 Go (70B)
- Idéal pour : Chat à usage général sans restriction et génération de contenu
- Plateforme : Ollama
2. dolphin-llama3 : Meilleur LLM non censuré Llama 3 pour les flux de travail agentiques
Le Dolphin d'Eric Hartford basé sur Llama 3 est le modèle non censuré le plus téléchargé construit sur une architecture moderne, avec 1,9 million de téléchargements (Ollama, page du modèle dolphin-llama3, 2026). Il prend en charge l'appel de fonctions (function calling) et une fenêtre de contexte qui s'étend de 8K à 256K jetons selon la configuration. La version 8B pèse 4,7 Go, s'adaptant à la plupart des GPU grand public de milieu de gamme.
- Paramètres : 8B ou 70B
- VRAM : ~5 Go (8B) ; ~40 Go (70B)
- Idéal pour : Codage, flux de travail agentiques et appel de fonctions
- Plateforme : Ollama
3. dolphin-mixtral 8x7B : Modèle d'IA MoE non censuré pour le raisonnement complexe
Une architecture de mélange d'experts (MoE) achemine chaque jeton à travers un sous-ensemble de ses 8 couches d'experts. Cela produit une qualité de raisonnement proche du 70B à un coût d'inférence inférieur à celui d'un modèle dense de nombre total de paramètres équivalent. L'ajustement non censuré d'Eric Hartford conserve une forte emphase sur le codage.
- Paramètres : 8x7B (les paramètres actifs par passe d'inférence sont bien inférieurs au total)
- VRAM : ~12-16 Go avec quantification
- Idéal pour : Tâches de codage complexes, raisonnement technique et chaînes d'instructions plus longues
- Plateforme : Ollama
4. dolphin-mistral : Modèle d'IA local 7B non censuré pour des réponses rapides
Plus léger et plus rapide que dolphin-mixtral sur du matériel limité par le CPU. Il cumule 1,5 million de téléchargements de la part de développeurs qui souhaitent un modèle local réactif pour la complétion de code sans avoir besoin d'un GPU haut de gamme. L'architecture de base Mistral lui confère un solide rapport performance-taille pour un modèle 7B.
- Paramètres : 7B
- VRAM : ~5-6 Go
- Idéal pour : Assistance au codage légère et réponses rapides en chat
- Plateforme : Ollama
5. dolphin-phi 2.7B : Modèle d'IA local non censuré le plus léger
L'architecture de base Phi de Microsoft intègre un raisonnement capable dans un nombre de 2,7 milliards de paramètres. L'ajustement non censuré d'Eric Hartford préserve cette efficacité. Avec moins de 4 Go de VRAM, il fonctionne sur la plupart des ordinateurs portables grand public équipés d'un GPU dédié, ce qui en fait le point d'entrée accessible pour les meilleurs modèles d'IA locaux non censurés de 2026.
- Paramètres : 2,7B
- VRAM : Moins de 4 Go
- Idéal pour : Déploiement sur ordinateur portable, tests rapides et environnements limités par le matériel
- Plateforme : Ollama
Meilleurs modèles LLM non censurés 6-10 : Codage, jeu de rôle et contexte étendu
En 2026, la série Dolphin occupe 5 des 10 premières places du catalogue non censuré d'Ollama en nombre de téléchargements, une concentration qui reflète la méthodologie d'ajustement cohérente d'Eric Hartford appliquée à travers différentes architectures de base (Ollama, page du modèle hermes3, 2026). Les modèles 6 à 10 couvrent le jeu de rôle, la conversation générale, les outils de développement, le suivi d'instructions et le contexte étendu : les cas d'utilisation où les refus de l'IA grand public sont les plus perturbateurs.
6. hermes3 : Modèle d'IA non censuré pour le jeu de rôle et les tâches agentiques
Nous Research a construit hermes3 pour la profondeur du jeu de rôle et l'utilisation structurée d'outils. Il est disponible en quatre tailles, de 3B à 405B, la plus large gamme de tailles de tous les modèles de cette liste. Avec 1,3 million de téléchargements, la variante 8B se situe à un niveau pratique pour l'écriture créative et les flux de travail de planification agentique (Ollama, page du modèle hermes3, 2026).
- Paramètres : 3B, 8B, 70B ou 405B
- VRAM : ~2 Go (3B) ; ~5 Go (8B) ; ~40 Go (70B)
- Idéal pour : Jeu de rôle, fiction créative et planification de tâches agentiques
- Plateforme : Ollama
7. wizard-vicuna-uncensored : Modèle d'IA multi-tailles non censuré pour un usage général
Un modèle plus ancien mais éprouvé construit sur Llama 2, disponible en trois tailles jusqu'à 30B. Ses 1,2 million de téléchargements proviennent d'utilisateurs qui souhaitent une option non censurée fiable avec une gamme de paramètres plus large. Il n'égale pas les capacités de fenêtre de contexte de dolphin-llama3, mais gère la conversation générale et le contenu créatif de manière cohérente.
- Paramètres : 7B, 13B ou 30B
- VRAM : ~5 Go (7B) ; ~9 Go (13B) ; ~20 Go (30B)
- Idéal pour : Conversation à usage général et contenu créatif avec plusieurs options de taille
- Plateforme : Ollama
8. dolphincoder : Modèle de codage IA non censuré sur base StarCoder2
StarCoder2 comme base fait de dolphincoder un véritable spécialiste. Là où les autres modèles Dolphin sont des généralistes avec un ajustement non censuré, celui-ci cible spécifiquement le développement logiciel. Ses 943 000 téléchargements proviennent presque entièrement de développeurs, et non d'utilisateurs créatifs. La variante 15B gère des bases de code plus importantes que ce que le 7B peut gérer.
- Paramètres : 7B ou 15B
- VRAM : ~5 Go (7B) ; ~10 Go (15B)
- Idéal pour : Génération de code, débogage et documentation technique
- Plateforme : Ollama
9. wizardlm-uncensored : LLM de suivi d'instructions non censuré pour les flux de travail de recherche
Un modèle de suivi d'instructions 13B avec 610 000 téléchargements. Sa force est de suivre des instructions complexes en plusieurs étapes sans émettre de réserves ou refuser des sous-tâches. Dans les flux de travail de recherche où un seul refus brise une longue chaîne, cette fiabilité a une valeur de productivité directe. Il n'a pas l'architecture de base moderne de dolphin-llama3, mais il fait le travail d'instruction de manière cohérente.
- Paramètres : 13B
- VRAM : ~9 Go
- Idéal pour : Chaînes d'instructions complexes en plusieurs étapes et flux de travail de recherche
- Plateforme : Ollama
10. everythinglm : LLM non censuré avec fenêtre de contexte 16K
La caractéristique marquante ici est la fenêtre de contexte de 16K sur une base Llama 2. La plupart des modèles 7B plafonnent à 4K ou 8K jetons. Ce contexte supplémentaire permet à everythinglm de traiter des bases de code complètes, de longs documents ou des historiques de conversation étendus sans troncature. Ses 536 000 téléchargements sont modestes selon les standards de cette liste, mais il comble une lacune qu'aucun autre modèle ici ne couvre à cette taille.
- Paramètres : 13B
- VRAM : ~9 Go
- Idéal pour : Analyse de longs documents, chat à contexte étendu et révision complète de bases de code
- Plateforme : Ollama
La domination de la série Dolphin dans les nombres de téléchargements Ollama reflète un schéma que la communauté a documenté : les modèles non censurés fine-tunés par un auteur unique avec une méthodologie cohérente surpassent les tentatives d'abliteration ponctuelles. L'abliteration supprime les poids de refus d'un modèle unique. Le fine-tuning construit un comportement non censuré stable à travers divers types d'invites. C'est pour cette cohérence que 5 des 10 premières places appartiennent au travail d'Eric Hartford, et non à une quelconque architecture de base.
Comment configurer les modèles Ollama non censurés localement ?
En 2026, trois commandes installent n'importe quel modèle Ollama sur Mac, Linux ou Windows : installez Ollama depuis ollama.com, exécutez ollama pull [nom-du-modèle], puis ollama run [nom-du-modèle] (Documentation Ollama, 2026). Aucune clé API n'est requise. Aucune modération de contenu externe ne s'applique. Votre invite ne quitte jamais votre matériel.
Pour dolphin-llama3 comme exemple concret : ollama pull dolphin-llama3 télécharge le fichier 8B de 4,7 Go. ollama run dolphin-llama3 ouvre une invite interactive. L'ensemble du processus d'inférence s'exécute sur votre GPU ou CPU local.
LM Studio fournit une interface graphique de bureau pour les utilisateurs qui préfèrent ne pas travailler dans le terminal. Il utilise les mêmes fichiers de modèle GGUF qu'Ollama, avec une interface visuelle pour la sélection du modèle et l'ajustement des paramètres. llama.cpp est le moteur d'inférence sous-jacent derrière les deux outils, et il prend en charge l'utilisation directe en ligne de commande lorsque vous avez besoin de plus de contrôle sur les niveaux de quantification et les paramètres de longueur de contexte.
Les développeurs qui souhaitent des configurations matérielles spécifiques et des paramètres de quantification pour exécuter les meilleurs modèles d'IA locaux non censurés de 2026 sur des GPU grand public trouveront que le guide de configuration locale complet couvre en détail les configurations VRAM minimales et les erreurs de configuration courantes.
Quels modèles OpenRouter non censurés sont disponibles sans GPU local ?
En 2026, OpenRouter héberge des LLM non censurés via API, éliminant totalement l'exigence de GPU. Le modèle venice/uncensored est disponible en tant que modèle de niveau gratuit à 0 $ par million de jetons d'entrée et de sortie (OpenRouter, page du modèle venice/uncensored, 2026). Cela fait des modèles non censurés OpenRouter le point d'entrée pratique pour les utilisateurs sans matériel dédié.
Le compromis est simple : OpenRouter achemine votre invite via leur infrastructure, donc la conversation n'est pas privée comme le serait un modèle local. Les modèles Ollama locaux gardent tout sur votre appareil. Aucune approche n'est universellement meilleure. Le bon choix dépend de votre modèle de menace et de la disponibilité du matériel.
11. venice/uncensored : Modèle OpenRouter non censuré gratuit
Le modèle Venice Uncensored sur le niveau gratuit d'OpenRouter. Une base Mistral-Small 24B, ajustée pour une sortie non censurée par Cognitive Computations en collaboration avec Venice.ai. Fenêtre de contexte 32K, 0 $ par million de jetons. Le niveau gratuit d'OpenRouter applique une limite à l'échelle de la plateforme de 200 requêtes par jour pour l'ensemble des modèles gratuits.
- Paramètres : 24B
- VRAM : Aucune requise (hébergé dans le cloud)
- Idéal pour : Tester des LLM non censurés sans matériel local ; gratuit dans les limites de débit de la plateforme
- Plateforme : OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B : Grand modèle non censuré via OpenRouter
Modèle de jeu de rôle créatif et de suivi d'instructions 70B de Sao10k, ajusté pour une sortie non censurée. Basé sur Llama 3.3 70B avec 131K de contexte. Activement maintenu avec une utilisation réelle sur OpenRouter, et consultable par nom dans la recherche globale de la plateforme.
- Paramètres : 70B
- VRAM : Aucune requise (hébergé dans le cloud)
- Idéal pour : Écriture créative complexe, jeu de rôle et longues chaînes d'instructions sans matériel local
- Plateforme : OpenRouter
13. Sao10K: Llama 3 8B Lunaris : Modèle non censuré léger via OpenRouter
Lunaris 8B est un modèle généraliste et de jeu de rôle polyvalent de Sao10k, basé sur Llama 3 8B. Il s'agit d'une fusion stratégique de plusieurs modèles conçus pour équilibrer la créativité avec une logique et des connaissances générales améliorées, offrant une expérience améliorée par rapport à Stheno v3.2 avec plus de créativité et de raisonnement. L'option non censurée la moins chère sur OpenRouter à 0,04 $ / 0,05 $ par million de jetons, avec plus de 6 milliards de jetons d'utilisation réelle sur la plateforme.
- Paramètres : 8B
- VRAM : Aucune requise (hébergé dans le cloud)
- Idéal pour : Conversation légère non censurée et écriture créative à coût minimal
- Plateforme : OpenRouter
14. TheDrummer: Cydonia 24B V4.1 : Modèle d'écriture créative non censuré via OpenRouter
Cydonia 24B V4.1 est un modèle d'écriture créative non censuré de TheDrummer, basé sur Mistral Small 3.2 24B, avec une bonne mémorisation, un bon respect des invites et de l'intelligence. Fenêtre de contexte 131K. Activement maintenu et directement consultable par nom dans la recherche globale d'OpenRouter.
- Paramètres : 24B
- VRAM : Aucune requise (hébergé dans le cloud)
- Idéal pour : Écriture créative non censurée et jeu de rôle sans matériel local
- Plateforme : OpenRouter
Comment accéder aux modèles d'images et de vidéos non censurés via Atlas Cloud
En 2026, la plupart des modèles d'images et de vidéos non censurés nécessitent soit un matériel GPU local, soit une plateforme API dédiée, car les fournisseurs de cloud grand public appliquent des filtres de contenu qui bloquent les sorties NSFW au niveau de l'inférence. Atlas Cloud est une plateforme API de modèles construite spécifiquement pour supprimer cette contrainte, couvrant plus de 300 modèles organisés à travers le texte, l'image, la vidéo et l'audio.
Démarrer prend trois étapes :
- Créez un compte sur atlascloud.ai
- Générez une clé API depuis le tableau de bord
- Appelez le point de terminaison du modèle en utilisant la clé — les modèles d'image et de vidéo utilisent leur propre format REST ; les points de terminaison LLM suivent le format OpenAI Chat Completions
Ce qui rend Atlas Cloud pertinent pour les cas d'utilisation non censurés spécifiquement :
- La politique de confidentialité de la plateforme stipule : « Votre contenu généré n'est jamais utilisé pour l'entraînement et n'est jamais examiné par personne. » Il s'agit d'un engagement publié et explicite, pas d'une hypothèse par défaut.
- Aucun plafond de génération quotidien ne s'applique à aucun modèle du catalogue.
- Le catalogue d'images non censuré couvre 33 modèles texte-vers-image à partir de 0,003 $ par image.
- Le catalogue vidéo non censuré couvre plus de 10 modèles vidéo NSFW à partir de 0,01 $/s.
Le catalogue complet des modèles non censurés est consultable sur Uncensored AI. Les modèles #15 à #20 de cette liste sont tous accessibles via une seule clé API Atlas Cloud.
Quels sont les meilleurs modèles d'images IA non censurés pour la génération de contenu NSFW et adulte ?
En 2026, l'architecture FLUX propulse la majorité de la génération d'images non censurées de haute qualité, disponible via l'API Atlas Cloud à travers des niveaux de prix et de qualité (Atlas Cloud, liste des modèles texte-vers-image, 2026). Le catalogue d'Atlas Cloud couvre 33 modèles texte-vers-image au total. Les cas d'utilisation incluent les beaux-arts, la conception de personnages, les modèles de lingerie non censurés et la génération de portraits adultes, la création d'actifs de jeu et l'illustration en lot en volume.
La page d'accueil d'Atlas Cloud indique « plus de 300 modèles organisés à travers le texte, l'image, la vidéo et l'audio », et la politique de confidentialité de la plateforme pour son catalogue non censuré se lit comme suit : « Votre contenu généré n'est jamais utilisé pour l'entraînement et n'est jamais examiné par personne. »
Pour une répartition complète des outils d'image non censurés basés sur navigateur et API, le guide des meilleurs générateurs d'images IA NSFW non censurés couvre les deux catégories avec des comparaisons de capacités. Les développeurs concentrés spécifiquement sur l'architecture FLUX peuvent lire le guide des générateurs d'images FLUX non censurés pour des détails sur l'ajustement et le flux de travail.
Pour les flux de travail qui partent d'une image existante plutôt que d'une invite texte, le guide de l'IA image-vers-image non censuré et le guide des meilleurs éditeurs d'images IA non censurés couvrent respectivement les pipelines de transformation et d'édition. Les équipes concentrées sur la sortie de personnages de style anime ou illustrés trouveront des options spécialisées dans le guide des générateurs d'images IA anime non censurés.
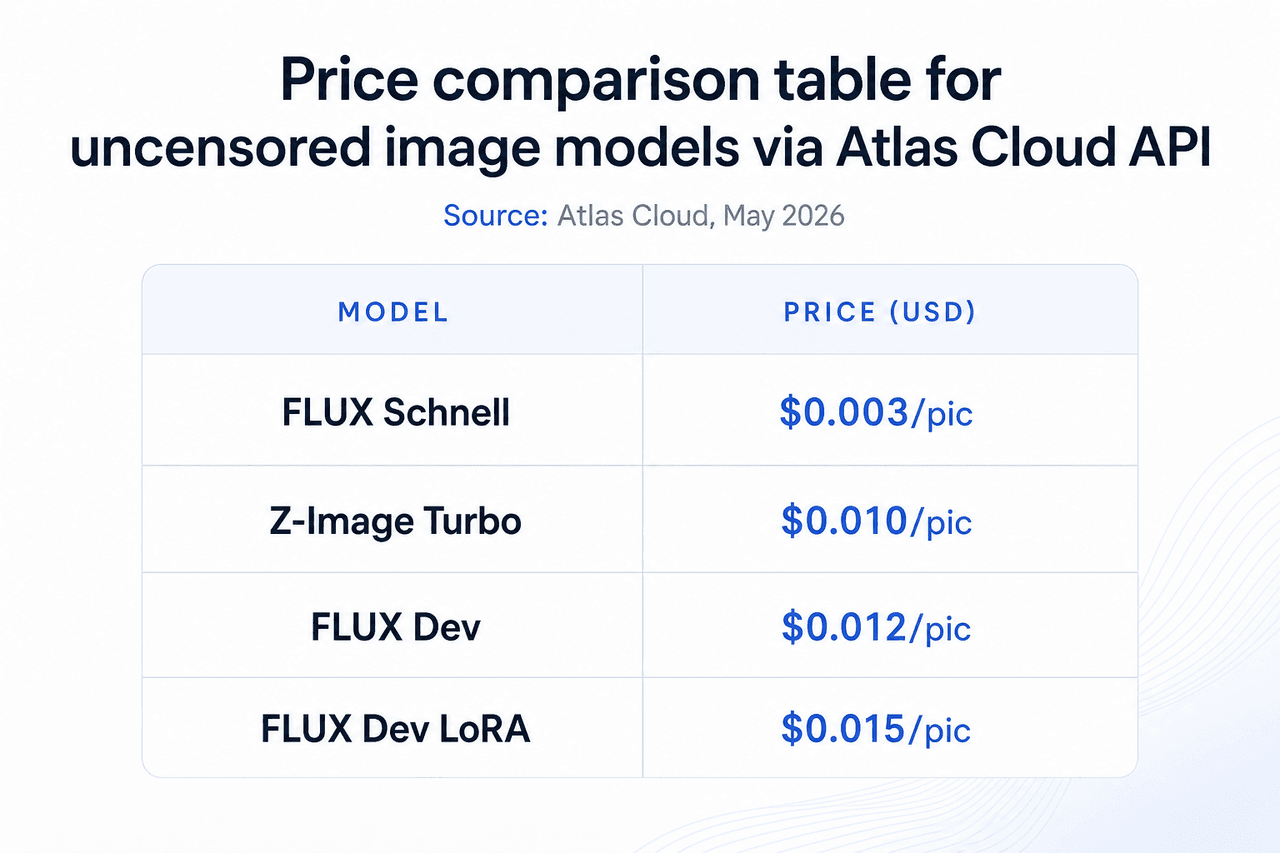
15. FLUX Schnell : Modèle d'image IA non censuré le plus rapide pour la génération en lot
L'option la moins chère du catalogue d'images Atlas Cloud. À 0,003 $ par image, c'est l'outil approprié pour les flux de travail de génération en lot où la vitesse et le volume comptent plus que les détails fins. Aucun plafond quotidien ne s'applique, et aucun contenu n'est stocké pour l'entraînement.
- Prix : 0,003 $/image
- VRAM : Aucune requise (accès API)
- Idéal pour : Génération d'images en lot, prototypage rapide et sortie non censurée à haut volume
- Plateforme : API Atlas Cloud
À 0,003 $ par image, un budget de 3,00 $ produit 1 000 images. Ce coût par sortie est inférieur aux frais de stockage cloud pour les fichiers résultants chez la plupart des fournisseurs. Cela change l'économie pour les studios qui faisaient fonctionner auparavant des installations GPU locales coûteuses pendant la nuit pour la génération en lot : l'approche API est désormais à la fois moins chère et plus rapide pour le travail en volume.
16. FLUX Dev : Modèle d'image IA non censuré de plus haute qualité pour la production finale
Quatre fois le coût de FLUX Schnell, avec une anatomie, un éclairage et des détails de texture sensiblement meilleurs. Pour une sortie de qualité finale où les images individuelles comptent, le point de prix de 0,012 $ est une étape pratique. Il convient aux pièces de portfolio, au contenu adulte commercial et aux actifs de production où la qualité est la contrainte principale.
- Prix : 0,012 $/image
- VRAM : Aucune requise (accès API)
- Idéal pour : Images uniques de haute qualité, pièces de portfolio et actifs de production finale
- Plateforme : API Atlas Cloud
17. FLUX Dev LoRA : Modèle d'image non censuré avec entraînement de style personnalisé
L'ajustement LoRA injecte un style personnalisé, une apparence de personnage ou un sujet dans la base FLUX Dev. C'est le modèle à utiliser lorsque vous avez besoin d'une apparence de personnage cohérente sur un lot ou que vous souhaitez qu'un style maison soit appliqué à chaque image d'un ensemble. Atlas Cloud gère le chargement LoRA côté serveur.
- Prix : 0,015 $/image
- VRAM : Aucune requise (accès API)
- Idéal pour : Cohérence des personnages, entraînement de style personnalisé et série d'images de marque
- Plateforme : API Atlas Cloud
18. Z-Image Turbo : Modèle d'image IA non censuré économique avec une qualité de milieu de gamme
Positionné entre FLUX Schnell et FLUX Dev sur la courbe prix-qualité. À 0,01 $ par image, Z-Image Turbo offre une architecture différente optimisée pour la vitesse sans la simplification d'image que fait Schnell à son prix inférieur. Le choix pratique lorsque la qualité de Schnell n'est pas suffisante et que le coût de FLUX Dev est trop élevé pour le volume nécessaire.
- Prix : 0,01 $/image
- VRAM : Aucune requise (accès API)
- Idéal pour : Génération à volume modéré où la qualité et le coût doivent s'équilibrer
- Plateforme : API Atlas Cloud
Quels sont les meilleurs modèles de vidéo IA non censurés pour l'animation NSFW en 2026 ?
En 2026, la génération de vidéo non censurée nécessite un pipeline distinct de la génération d'images car les plateformes vidéo grand public appliquent des filtres de contenu identiques et refusent d'animer du contenu NSFW même lorsque l'image source a été générée ailleurs (Atlas Cloud, catalogue de modèles non censurés, 2026). La page vidéo non censurée d'Atlas Cloud porte le titre « Liberté créative sans restriction. Aucun filtre. Aucune limite. » et couvre plus de 10 modèles vidéo NSFW, le catalogue complet incluant également les variantes Wan 2.6, Wan 2.5 et Van.
19. Wan 2.2 Turbo Spicy Infinite I2V : Modèle vidéo non censuré le moins coûteux
L'option d'entrée de gamme pour l'animation NSFW à partir d'une image fixe. À 0,01 $/s, c'est le moyen le plus rentable d'animer une image statique en contenu vidéo NSFW. La résolution atteint 1080p avec une durée de clip variable, ce qui en fait le bon point de départ pour les pipelines de production soucieux de leur budget.
- Prix : 0,01 $/s
- Résolution : 1080p
- Durée : Variable
- Idéal pour : Animation NSFW rentable et prévisualisation de concepts de mouvement
- Plateforme : API Atlas Cloud
20. Seedance v1.5 Spicy : Modèle vidéo non censuré de plus haute qualité pour la sortie finale
L'option de qualité cinématographique du catalogue. À 0,049 $/s, il coûte environ 2,5 fois plus que Wan 2.2 Turbo Spicy Infinite, mais produit un mouvement plus fluide, une meilleure cohérence du sujet à travers les cadres et des transitions plus naturelles. Pour une sortie vidéo NSFW de qualité finale où la fidélité visuelle est la préoccupation principale, c'est l'option supérieure dans la gamme vidéo non censurée d'Atlas Cloud.
- Prix : 0,049 $/s
- Résolution : 720p
- Durée : 5s
- Idéal pour : Vidéo NSFW de qualité finale, contenu adulte professionnel et sortie prête à la livraison
- Plateforme : API Atlas Cloud
Le guide des meilleurs générateurs d'image-vers-vidéo IA non censurés couvre le catalogue complet des variantes de la série Wan 2.7 et Wan 2.2 Spicy avec toutes les options de durée et de résolution.
Guide de sélection rapide des modèles d'IA non censurés
| Besoin | Recommandé |
|---|---|
| Meilleur LLM non censuré global | llama2-uncensored ou dolphin-llama3 |
| Tâches de codage | dolphin-mixtral 8x7B ou dolphincoder |
| Jeu de rôle et écriture créative | hermes3 |
| Moins de 4 Go de VRAM | dolphin-phi 2.7B |
| Génération d'images non censurée | FLUX Schnell via Atlas Cloud (0,003 $/image) |
| Vidéo NSFW à partir d'image | Wan 2.2 Turbo Spicy Infinite via Atlas Cloud (0,01 $/s) |
FAQ sur les modèles d'IA non censurés
Quel est le modèle d'IA le plus non censuré en 2026 ?
Par nombre de téléchargements Ollama, llama2-uncensored est en tête avec 2,6 millions de téléchargements, ce qui en fait l'option la plus validée par la communauté parmi les modèles d'IA non censurés de 2026 (Ollama, recherche de modèles non censurés, 2026). En termes de capacité brute, dolphin-llama3 offre plus : appel de fonctions, jusqu'à 256K de contexte et une architecture de base Llama 3. La réponse dépend de si la stabilité éprouvée ou la capacité moderne compte le plus pour votre cas d'utilisation.
Quels modèles non censurés fonctionnent sur Ollama ?
Dix modèles de cette liste fonctionnent comme des modèles Ollama non censurés : llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored et everythinglm. Le modèle communautaire jaahas/qwen3.5-uncensored fonctionne également sur Ollama pour une utilisation multilingue. Tous s'installent avec ollama pull [nom-du-modèle].
Quels modèles non censurés sont disponibles sur OpenRouter ?
En 2026, OpenRouter héberge des LLM non censurés via API, éliminant totalement l'exigence de GPU. Les options incluent le modèle venice/uncensored du niveau gratuit à 0 $ par million de jetons (200 requêtes par jour), ainsi que des modèles payants incluant Sao10K Euryale 70B, Lunaris 8B et TheDrummer Cydonia 24B (OpenRouter, page du modèle venice/uncensored, 2026). Ces modèles non censurés OpenRouter ne nécessitent aucun GPU local et aucun investissement matériel pour démarrer.
Quelle est la différence entre un modèle non censuré abliteré et un modèle ajusté (fine-tuné) ?
L'abliteration supprime les poids de refus d'un modèle chirurgicalement au niveau des poids. Les modèles non censurés ajustés comme la série Dolphin sont entraînés sur des jeux de données qui ne renforcent pas le comportement de refus en premier lieu. La communauté constate systématiquement que les modèles ajustés sont plus stables : l'abliteration peut introduire une sortie incohérente à travers divers types d'invites, tandis que l'ajustement produit des résultats fiables, ce qui explique pourquoi les modèles Dolphin dominent les nombres de téléchargements non censurés d'Ollama.
Puis-je exécuter des modèles d'IA non censurés localement sur un ordinateur portable ?
Oui. dolphin-phi 2.7B fonctionne avec moins de 4 Go de VRAM, ce qui en fait le point d'entrée pour le déploiement sur ordinateur portable avec un GPU dédié. Avec 6-8 Go de VRAM, vous pouvez exécuter n'importe quel modèle 7B de cette liste. Les graphiques intégrés ne fonctionneront pas. Le guide de configuration locale pour les modèles d'IA non censurés couvre en détail les configurations matérielles minimales et les paramètres de quantification.
Conclusion
Le meilleur modèle d'IA non censuré en 2026 dépend entièrement de votre cas d'utilisation. Pour le travail LLM général, dolphin-llama3 est l'option Ollama la plus capable. Pour les ordinateurs portables, dolphin-phi couvre l'exigence de moins de 4 Go de VRAM. Pour l'accès LLM cloud sans matériel, venice/uncensored sur le niveau gratuit d'OpenRouter est le point de départ pratique à 0 $ par million de jetons. Pour la génération d'images non censurée à grande échelle, FLUX Schnell via l'API Atlas Cloud produit une sortie à 0,003 $ par image sans plafond quotidien. Pour la vidéo NSFW, le catalogue Atlas Cloud commence à 0,01 $/s avec une politique vérifiée de non-entraînement et de non-examen.
Les lecteurs à la recherche d'un aperçu complet des outils d'IA non censurés à travers les images, la vidéo et les éditeurs trouveront que le guide des générateurs d'images IA non censurés couvre tout le paysage.






