GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Explorez les Modèles Leaders
Atlas Cloud vous offre les derniers modèles créatifs de pointe de l'industrie.
Ce Qui Distingue GLM LLM Models
Atlas Cloud vous fournit les derniers modèles créatifs de pointe du secteur.

Advanced Reasoning
Tuned for strong logical reasoning, structured analysis, and multi-step problem solving.

Cost-Efficiency
Optimized architectures keep latency and costs under control.

Safety & Governance
Built-in content filters, auditing tools, and policy controls help teams deploy.

Enterprise Reliability
Production-ready SLAs, monitoring, and governance features help teams confidently ship applications.

Chinese–English Excellence
Native-strength Chinese and fluent English support enable high-quality bilingual chat, search, and generation.

Developer-Friendly Ecosystem
Clean APIs, SDKs, and tooling make it easy to integrate, fine-tune, and operate Z.ai across products and platforms.
Vitesse de pointe
Coût le plus bas
| Model | Description |
|---|---|
| GLM-5 | GLM-5 is Z.ai's flagship LLM featuring a massive 202.75K context window optimized for complex systems and long-horizon agentic tasks. Outperforming elite closed-source models in benchmarks like Humanity’s Last Exam and BrowseComp, it provides robust programming and stable multi-step reasoning at highly competitive baseline pricing. |
| GLM-4.7 | GLM-4.7 is a high-performance LLM with a 202.75K context window specifically engineered for real-world intelligent agents, advanced reasoning, and professional coding. Fast, smart, and reliable, it serves as the ideal engine for building complex websites and automating sophisticated professional workflows with precision. |
| GLM-4.6 | GLM-4.6 is a powerful MoE LLM with a 202.75K context window designed for rapid data analysis and instant, high-fidelity answers. This dependable model excels at high-efficiency tasks like creating professional slides and web content, offering a smart balance of speed and enterprise-grade performance. |
Nouvelles fonctionnalités de GLM LLM Models + Showcase
La combinaison de modèles avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre une vitesse, une évolutivité et un contrôle créatif inégalés pour la génération d'images et de vidéos.
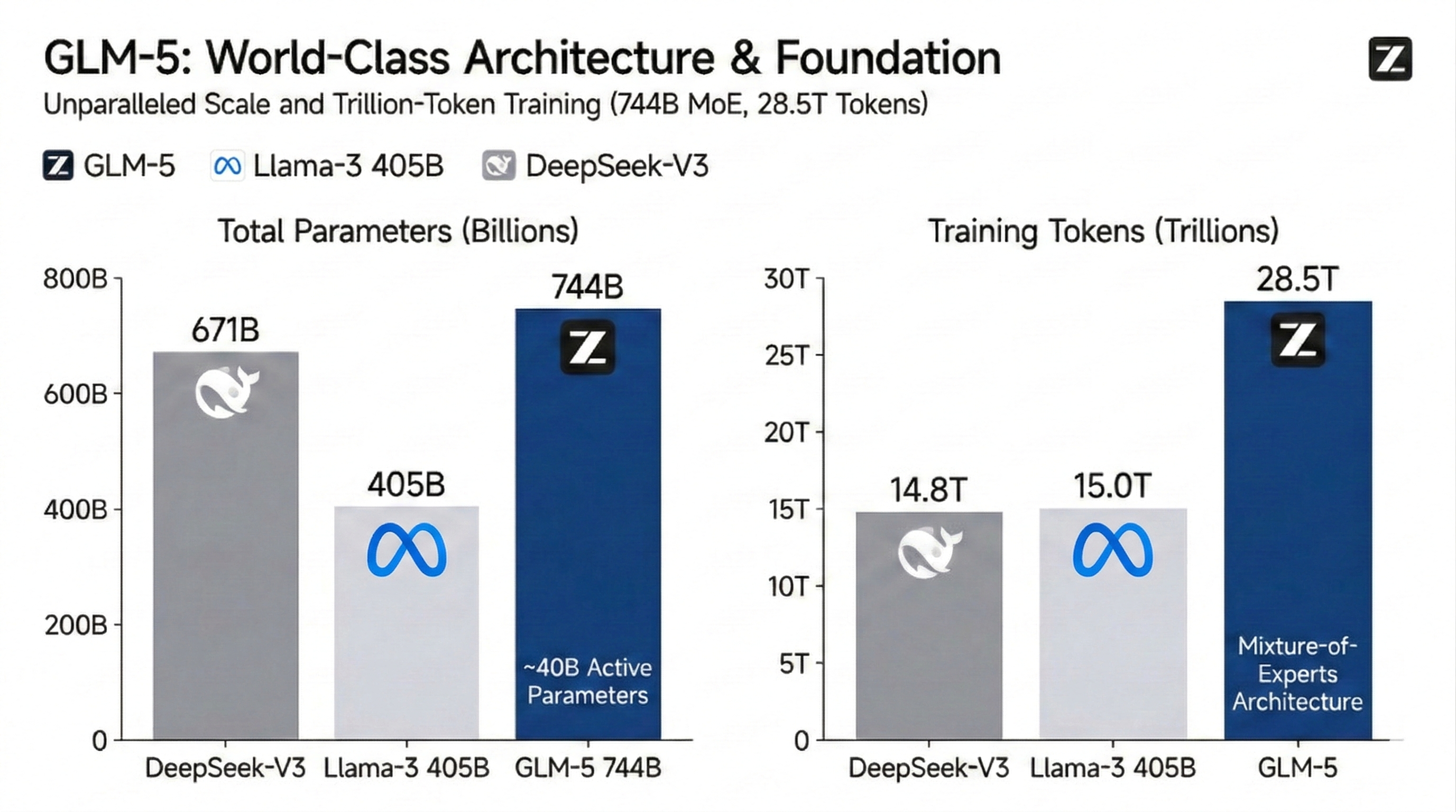
Architecture MoE massive de 744B et base de connaissances universelle
Le modèle GLM-5 s'appuie sur une architecture de mélange d'experts (MoE) de 744 milliards de paramètres entraînée sur un nombre stupéfiant de 28,5 billions de jetons pour redéfinir les plafonds de performance de l'open source. En optimisant 40 milliards de paramètres actifs, il facilite un bond massif dans la densité des connaissances mondiales et la précision de la récupération. Il constitue la base première pour les tâches cognitives à grande échelle et la synthèse de données complexes.
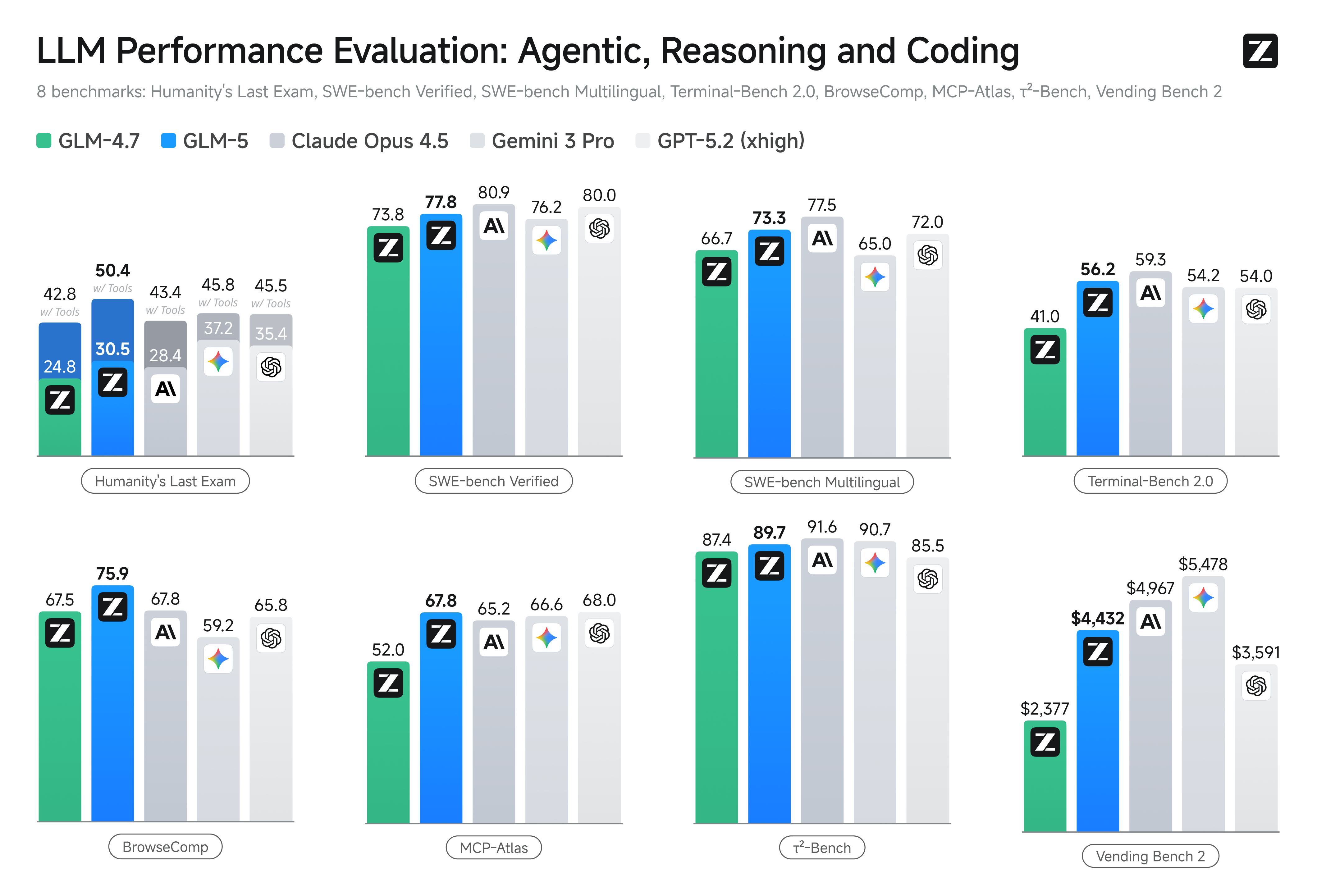
Ingénierie des systèmes agentiques révolutionnaire avec GLM-5
GLM-5 introduit des capacités agentiques avancées conçues pour l'exécution de tâches systémiques à long terme dans des environnements de raisonnement à étapes multiples. En intégrant une logique de planification sophistiquée dans son architecture centrale, le modèle maintient une stabilité exceptionnelle lors du développement logiciel automatisé et de la rédaction juridique professionnelle. Il sert de moteur définitif pour les flux de travail autonomes nécessitant une précision extrême et une cohérence à long terme.
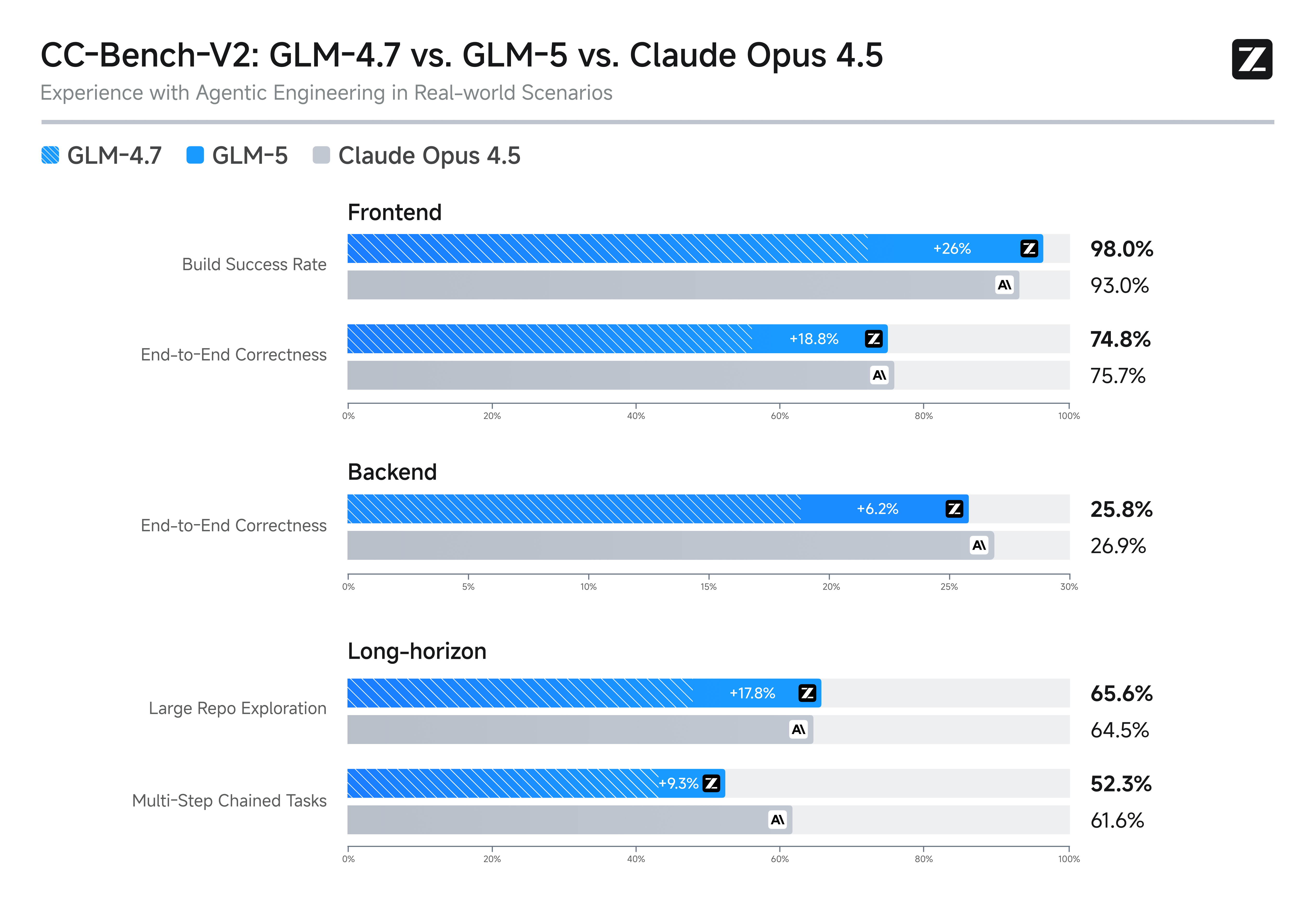
Slime : Apprentissage par renforcement asynchrone et évolution logique
GLM-5 utilise l'infrastructure innovante d'apprentissage par renforcement asynchrone « Slime » pour révolutionner l'efficacité de la post-formation et la rigueur logique. Cette percée améliore considérablement la qualité de la génération de code et le raisonnement algorithmique, surpassant les références précédentes et assurant son rang de modèle open-source de premier plan. C'est la solution ultime pour le développement full-stack et la résolution de problèmes structurels de haut niveau.
Ce Que Vous Pouvez Faire avec GLM LLM Models
Découvrez les cas d'usage pratiques et les workflows que vous pouvez créer avec cette famille de modèles — de la création de contenu et l'automatisation aux applications de niveau production.
Intelligence de dépôt complète avec GLM-5
L'API GLM-5 permet aux développeurs d'ingérer des bases de code entières pour une analyse logique approfondie et une refactorisation structurelle. En cartographiant les graphiques de dépendance et en traçant les flux de données asynchrones complexes, elle identifie les conditions de concurrence dans les cas limites et la dette technique cachée. Parfait pour l'intégration rapide des équipes, les revues de PR automatisées et la maintenance d'architectures de microservices évolutives et performantes.
Prototypage Full-Stack instantané avec GLM-5
Pour le développement axé sur l'intuition (vibe-driven), GLM-5 convertit des maquettes visuelles abstraites et des notes fragmentées en composants React ou Next.js déployables. Il se charge du gros du travail de génération de code standard (boilerplate), du style Tailwind CSS et de la gestion d'état tout en assurant la cohérence entre les pages. Idéal pour les fondateurs solo, les expérimentateurs UX et le lancement de MVP fonctionnels à la vitesse de l'éclair.
Orchestration de flux de travail autonome avec GLM-5
GLM-5 excelle dans la gestion de tâches de recherche à long terme nécessitant un raisonnement en plusieurs étapes et une intégration d'outils en temps réel. Il peut synthétiser de manière indépendante des données de marché provenant de multiples sources, rédiger des résumés juridiques conformes et automatiser une planification complexe interplateforme sans perdre le contexte. Ce cas d'usage convient aux chefs de projet, aux professionnels du droit et à toute personne nécessitant un agent numérique de haute fiabilité pour des opérations systémiques.
Comparaison des Modèles
Découvrez comment les modèles de différents fournisseurs se comparent — performance, tarification et atouts uniques pour une décision éclairée.
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.7 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.6 | 202.75K | 202.75K | Text | Efficient MoE Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use GLM LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Pourquoi Utiliser GLM LLM Models sur Atlas Cloud
Combiner les modèles GLM LLM Models avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre des performances, une évolutivité et une expérience développeur inégalées.
Performance et Flexibilité
Faible Latence :
Inférence optimisée par GPU pour un raisonnement en temps réel.
API Unifiée :
Exécutez GLM LLM Models, GPT, Gemini et DeepSeek avec une seule intégration.
Tarification Transparente :
Facturation prévisible par token avec options serverless.
Entreprise et Échelle
Expérience Développeur :
SDK, analytiques, outils de fine-tuning et modèles.
Fiabilité :
99,99% de disponibilité, RBAC et journalisation conforme.
Sécurité et Conformité :
SOC 2 Type II, alignement HIPAA, souveraineté des données aux États-Unis.
Questions Fréquentes sur GLM LLM Models
Avec 28,5 T tokens de données d'entraînement et des résultats de référence exceptionnels, GLM-5 est largement considéré comme le « plafond de l'open source ». Il rivalise avec les modèles commerciaux mondiaux de premier plan, voire les dépasse, en termes de capacité et de logique, fournissant une base puissante et performante pour l'écosystème mondial des développeurs.
HLE est un benchmark de haute difficulté conçu pour tester si l'IA possède des connaissances et un raisonnement humains de niveau expert. Le fait que GLM-5 obtienne le score le plus élevé signifie que sa maîtrise des sciences de pointe et de la logique complexe a atteint ou dépassé le niveau des principaux modèles propriétaires (closed-source).
BrowseComp est un classement de référence pour les capacités "Agentic", se concentrant sur la planification et l'exécution de tâches complexes dans des environnements web réels. Le score le plus élevé représente la capacité de GLM-5 à naviguer de manière autonome dans les navigateurs et à intégrer des informations inter-pages, le désignant comme le premier moteur de Web Agent.
Cette architecture fournit une "base de connaissances" massive de 744 milliards de paramètres tout en n'activant que ~40 milliards lors de l'inférence. Pour les développeurs, cela se traduit par une densité de connaissances et une profondeur de raisonnement de classe mondiale — surpassant les modèles denses comme Llama-3 405B — à une latence et un coût inférieurs.
Les paramètres totaux représentent la "capacité de connaissances" du modèle, 744B permettant un vaste stockage de faits mondiaux et de logique experte. Les paramètres actifs représentent la "puissance de calcul" utilisée par inférence. Grâce à l'architecture MoE, GLM-5 offre une intelligence de niveau 744B en utilisant seulement 40B de calcul, équilibrant une base de connaissances massive avec des performances rapides et rentables.
Le volume des données de pré-entraînement détermine l'« ampleur de la vision » d'un modèle. 28,5T de tokens constituent l'un des plus grands ensembles de données au monde (environ le double de celui de Llama-3), englobant des langues rares, des articles universitaires spécialisés et un vaste code de haute qualité. Cela garantit que GLM-5 possède une précision et une généralisation supérieures lors du traitement de requêtes complexes de longue traîne, de nuances interculturelles et de programmation système de bas niveau.
Explorer Plus de Familles
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


