
Il y a quelques mois, nous nous sommes fixé un objectif faussement simple : produire une vidéo cohérente de haute qualité, d'une durée supérieure à 15 secondes, sur un seul GPU et en moins d'une minute de temps réel. Les modèles de diffusion vidéo actuels comme Wan2.2 excellent sur des clips de 3 à 5 secondes. C’est lorsqu’on cherche à atteindre 10, 30 ou 60 secondes que les choses deviennent intéressantes.
Cet article documente le chemin que nous avons réellement suivi. Nous avons étudié six approches issues de publications et rapports techniques récents — TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk et Helios — nous avons mesuré les compromis, et nous avons finalement opté pour SVI (Stable Video Infinity), intégré à TurboWan au sein de notre DiffSynth Engine. Nous passerons en revue chacune de ces pistes, puis le fonctionnement de SVI, et enfin les chiffres de production.
Pourquoi la vidéo longue est un défi
Trois facteurs bloquent dès que l'on dépasse environ cinq secondes.
Le mur de la VRAM
Wan2.2 utilise une attention complète (Full Attention) avec un coût en O(n²) lié au nombre de jetons latents. Le calcul est sans appel :
5s (81 images) : ~32,7k jetons, matrice d'attention ~10 Go.
10s (165 images) : ~65,5k jetons, matrice d'attention ~40 Go — cela dépasse déjà la capacité d'un seul GPU.
30s (~500 images) : ~200k jetons, irréalisable.
En pratique, le Self Forcing seul sature la majeure partie des 129 Go d'un H200 à 165 images rien que pour le cache KV.
La dérive temporelle (Temporal drift)
Même quand la mémoire suffit, trois modes de dérive apparaissent, identifiés dans le rapport Helios : le décalage de position (les sujets errent dans le cadre), le décalage de couleur (dérive progressive de la teinte et de la luminosité) et le décalage de restauration (le modèle surcorrige, créant des discontinuités visibles).
La cohérence causale
La diffusion vidéo standard utilise une attention bidirectionnelle complète — chaque image interagit avec toutes les autres. Cela empêche toute lecture en streaming : impossible d'afficher la première image tant que la dernière n'est pas traitée.
Notre objectif concret était modeste : vidéo ≥ 15 secondes, continuité visuelle fluide, stabilité des sujets sur tout le clip, temps d'attente total inférieur à 60 secondes, entraînement minimal et une nette préférence pour la réutilisation des poids déjà existants.
L'étude
Nous avons examiné six familles. Les noms correspondent principalement aux titres des publications ; les catégories seront importantes par la suite.
Route 1 · TTT (Test-Time Training)
Publication : One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, avr. 2025).
L'idée est d'ajuster finement (fine-tune) le modèle pendant l'inférence afin qu'il mémorise ce qu'il a déjà généré. Une petite couche TTT (un MLP à 2 couches, une porte et une attention locale) est insérée après l'attention dans chaque bloc Transformer, et le modèle est entraîné sur un curriculum qui progresse de clips courts vers une minute complète.
Insertion par bloc : après l'attention standard, on insère une porte (Gate), une couche TTT et une attention locale, suivies d'une LayerNorm.
Curriculum : entraînement sur des fenêtres de plus en plus longues — 3s → 9s → 18s → 30s → 60s.
Coût : 256 H100 pendant ~50 heures.
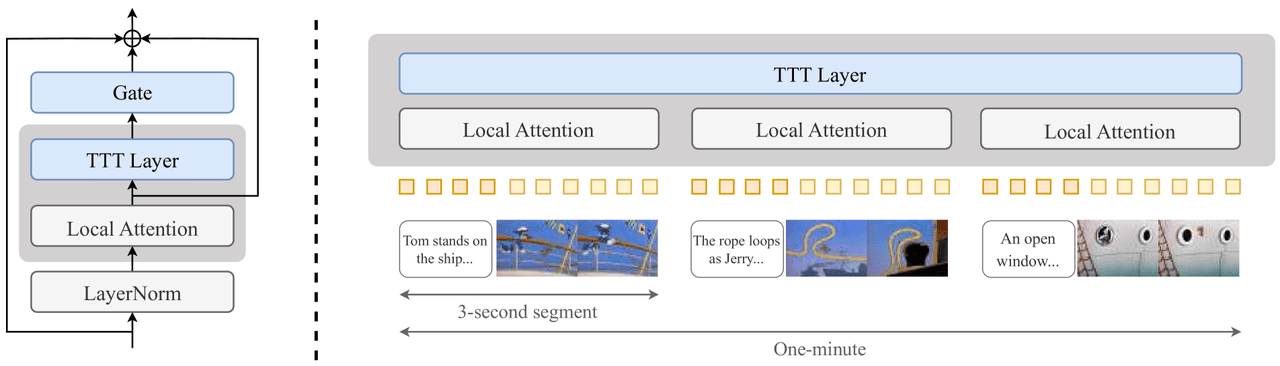
TTT — à gauche : point d'insertion (Porte + Couche TTT + Attention locale + LayerNorm, attachée après l'attention standard via résiduel). À droite : vidéo segmentée en clips de 3 secondes, chacun géré en interne par l'attention locale, la couche TTT assurant la mémoire globale entre les segments.
Cela fonctionne — l'article atteint la génération d'une minute. Mais le coût d'entraînement est énorme, les expériences ne couvrent que CogVideoX 5B (le transfert vers Wan2.2 14B n'est pas prouvé), et les couches TTT insérées entrent en conflit avec les optimisations de noyau sur lesquelles nous nous appuyons déjà. Verdict : non retenu.
Route 2 · LoL (Longer than Longer)
Publication : LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, janv. 2026).
LoL cible un mode d'échec spécifique de la vidéo longue autorégressive — le sink-collapse, où l'attention multi-têtes converge vers l'image d'ancrage et la vidéo revient périodiquement à son état initial. La solution est le Multi-Head RoPE Jitter : des perturbations de phase aléatoires par tête qui brisent l'homogénéité entre les têtes. Sans entraînement, prêt à l'emploi.
Mode d'échec : sink-collapse — sous RoPE autorégressif, les phases positionnelles des images distantes se réalignent périodiquement avec l'ancrage, l'attention se concentre et le contenu revient brusquement à l'image initiale.
Solution : donner à chaque tête d'attention son propre petit décalage de phase aléatoire. Les têtes ne peuvent plus s'effondrer sur la même colonne. Aucun réentraînement requis, s'intègre aux modèles existants.
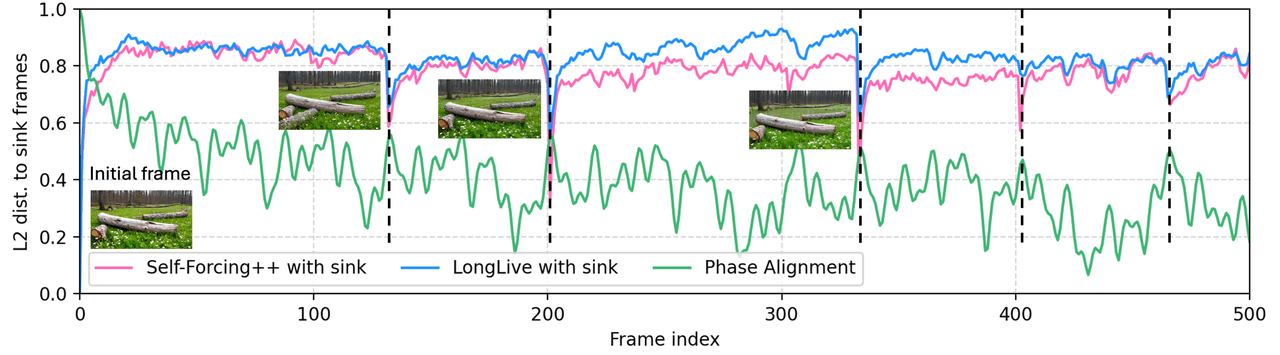
Distance L2 par rapport à l'ancrage vs index d'image. Self-Forcing++ (rouge) et LongLive (bleu), tous deux avec sink, reviennent régulièrement à l'ancrage à des positions précises — ce sont des événements de sink-collapse. L'alignement de phase de LoL (vert) élimine ce phénomène.
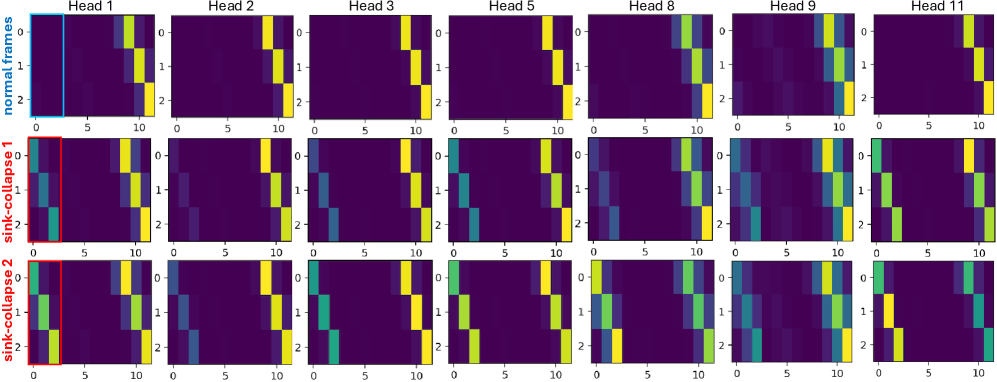
Cartes d'attention par tête. Rangée supérieure : images normales — les têtes ont des motifs visiblement différents. Rangées inférieures : pendant le sink-collapse — chaque tête semble identique, toutes effondrées sur la colonne de l'image d'ancrage. Le RoPE Jitter restaure la diversité par tête.
LoL atteint 12 heures de vidéo sur CogVideoX/HunyuanVideo avec peu de perte de qualité. Le piège est que toutes les démonstrations concernent des scènes plutôt statiques ; nous ne savons pas comment cela survit à la danse, au sport ou à tout mouvement intense. De plus, nous devrions modifier l'attention de Wan2.2. Verdict : coût d'adaptation trop élevé pour des gains incertains sur le contenu en mouvement. Non retenu.
Route 3 · Self Forcing (Causal Wan2.2)
Publication : Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight).
Self Forcing remplace l'attention bidirectionnelle de Wan2.2 par une attention causale : chaque image n'interagit qu'avec les images précédentes. Ce simple changement permet la génération en streaming — une fois le premier segment terminé, on le décode et on l'envoie.
Bidirectionnelle : chaque image interagit avec toutes les autres → il faut terminer les 40 étapes de débruitage avant de montrer une seule image. Causale : une image ne voit que son passé → le premier segment peut être diffusé dès qu'il est prêt.
L'astuce d'entraînement donne son nom à l'article. Au lieu d'entraîner sur un contexte de vérité terrain propre (Teacher Forcing) ou avec des masques d'attention personnalisés (Diffusion Forcing), Self Forcing reproduit le chemin réel d'inférence avec un cache KV glissant, afin que les distributions d'entraînement et d'inférence correspondent.
Boucle de génération : débruiter le prochain petit segment d'images en utilisant le programme d'étapes compressé de DMD, conditionné par un cache KV glissant construit à partir des images déjà générées.
Stream : dès qu'un segment est fini, on le décode via VAE et on l'émet.
Carry-over : pousser les latents du nouveau segment dans le cache KV pour que le prochain segment puisse s'y référer.
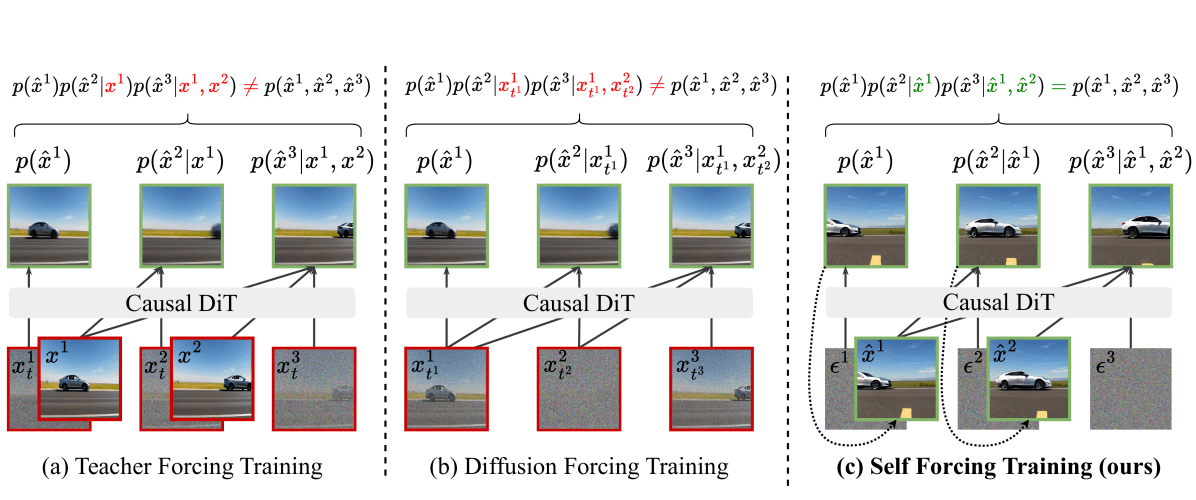
Comparaison des trois paradigmes d'entraînement : (a) Teacher Forcing entraîne sur des images propres — à l'inférence, les images bruitées provoquent une dérive ; (b) Diffusion Forcing utilise des masques d'attention personnalisés mais présente toujours une inadéquation entraînement-inférence ; (c) Self Forcing rejoue le processus d'inférence réel avec un cache KV glissant, alignant totalement les deux phases.
Nous avons mesuré cela sur le framework FastVideo, avec un seul H200 :
| Durée | Images | Temps | VRAM |
|---|---|---|---|
| 5s | 81 images | 70s | — |
| 10s | 165 images | 168s | 129 Go (presque saturé) |
| 20s | 321 images | 287s | 129 Go (cache KV limité à 42 images) |
C'est architecturalement la réponse la plus propre, et nous l'apprécions réellement. Mais 10s saturent déjà la VRAM d'un H200, la qualité baisse à 165 images, le modèle original nécessite un fine-tuning de l'attention causale, et le vrai streaming nécessite également un Conv3D causal dans le VAE.
Verdict : attendons que la communauté résolve les problèmes de VRAM et de qualité. Non adopté pour le moment.
Route 4 · Self Forcing++
Publication : Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, oct. 2025).
S'appuie sur Self Forcing avec trois ajouts : Backward Noise Initialization (chaque nouveau segment commence à partir d'un bruit intégré à rebours depuis les images déjà générées, éliminant les discontinuités aux frontières des segments) ; alignement DMD étendu (découpage de fenêtres de 5s sur un long déploiement et alignement contre la sortie à fenêtre courte d'un professeur) ; et une phase GRPO avec récompense de flux optique pour favoriser des mouvements plus dynamiques.
Étape 1. Autodéploiement de l'élève sur bien plus de 5 secondes, accumulant un brouillon long avec un cache KV glissant. Étape 2. Découpage de fenêtres aléatoires de 5s, passage via DMD étendu contre la distribution à fenêtre courte du professeur pour aligner. Étape 3. Raffinement avec GRPO en utilisant l'amplitude du flux optique comme récompense, poussant le modèle vers plus de dynamisme. Astuce. Chaque nouveau segment commence à partir d'un bruit intégré depuis le segment précédent, pas d'un bruit gaussien pur — donc plus de sauts aux frontières.
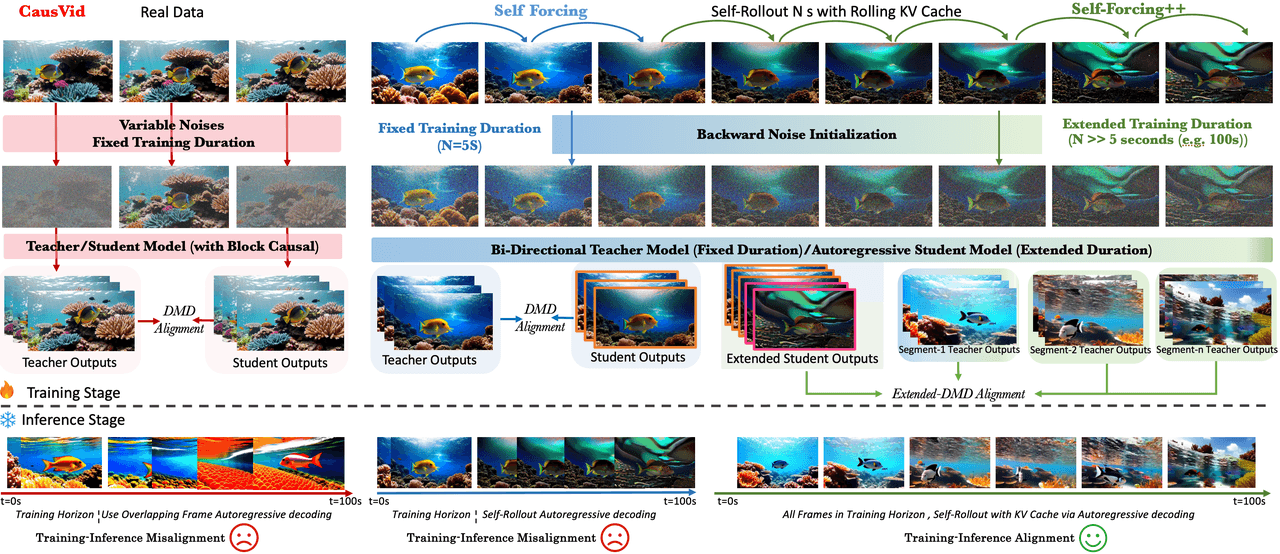
De gauche à droite : CausVid → Self Forcing → Self-Forcing++. Les rangées du bas montrent la correspondance entre les étapes d'entraînement et d'inférence.
Résultat : vidéo à l'échelle de la minute sur un Wan2.1 1.3B. Très bon article. Pour la production, nous avons rencontré deux murs : le contenu est majoritairement statique, le modèle de base est un 1.3B (bien en dessous de Wan2.2 14B), et aucun code ou poids n'est publié. Verdict : non retenu pour le moment.
Route 5 · Infinite Talk (A2V)
Un problème d'une nature différente — Audio-to-Video, où l'audio pilote la génération continue de têtes parlantes.
Bundle d'entrée par segment : les latents bruités du nouveau segment, les caractéristiques audio pour cette fenêtre temporelle, l'image de référence fournie, la dernière image du segment précédent et un poids de conditionnement flexible. Identité de référence : l'image de référence maintient la stabilité de l'apparence sur le long terme. Contrainte adaptative : le poids flexible ajuste la référence selon la dérive de similarité. Pont de mouvement : la dernière image du segment précédent assure la transition du mouvement.
C'est excellent dans son domaine — les têtes parlantes, indéfiniment. Mais l'architecture diffère trop de Wan2.2, nécessitant un entraînement dédié, et ne se généralise pas aux scènes classiques. Verdict : utile dans un couloir étroit, pas une solution générale pour la vidéo longue.
Route 6 · Helios
Publication : Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, mars 2026).
À l'heure où nous écrivons, Helios est l'état de l'art pour la vidéo longue — 14B de paramètres, 19,5 FPS en temps réel sur un seul H100. L'astuce est de compresser les images historiques dans une pyramide à trois niveaux et de les injecter dans le débruitage de l'image actuelle, pour que le budget de jetons reste constant quelle que soit la longueur.
Mémoire multi-termes. Historique à court terme (3 dernières images) en pleine résolution ; moyen terme (20 dernières images) avec compression modérée ; long terme (tout le reste) avec compression forte. Budget total de jetons constant. Attention de guidage. Dans chaque bloc DiT, les KV historiques propres et les QKV actuels bruités sont traités séparément pour que le bruit historique ne contamine pas le débruitage actuel. Échantillonnage pyramidal. Échantillonner d'abord en basse résolution pour définir la structure, puis raffiner en haute résolution pour les détails — environ 2,3× moins de jetons au total.
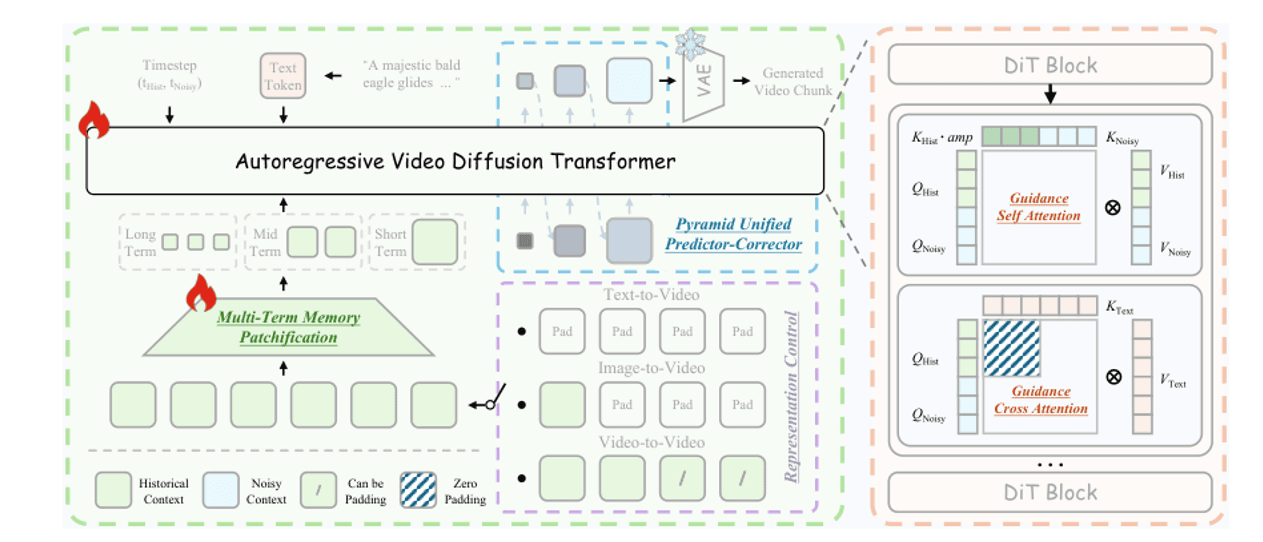
Architecture Helios. Gauche : Injection d'historique unifiée. Droite : Prédicteur-Correcteur pyramidal unifié — faible nombre de jetons pour définir la structure, puis haute résolution pour les détails, réduisant le calcul de ~2,3×.

L'article Helios définit systématiquement trois types de dérive : (a) décalage de position, (b) décalage de couleur, (c) décalage de restauration (bruit), (d) décalage de restauration (flou). L'Attention de Guidage est spécifiquement conçue pour traiter ces trois points.
Le débit mesuré d'Helios sur H200 est frappant — pratiquement constant avec la longueur :
| Durée | Temps | Débit |
|---|---|---|
| 240 images (10s) | 24s | ~10 FPS |
| 480 images (20s) | 42s | ~11.4 FPS |
| 960 images (40s) | 82s | ~11.7 FPS |
| H100 GPU unique (Helios-Distilled) | — | 19.5 FPS |
Le piège est que le patchification de la mémoire multi-termes nécessite un réentraînement complet d'un modèle 14B. Il n'y a pas de poids publiés — seulement un rapport technique — nous ne pouvons donc pas simplement y ajouter un LoRA. Verdict : une direction à moyen-long terme ; non déployable aujourd'hui.
Résumé de la comparaison des routes
Toutes les routes côte à côte, avec l'ajout de SVI comme ligne que nous avons finalement choisie :
| Approche | Durée max | Qualité | Entraînement | Difficulté ingénierie | Généralité | Rec. |
|---|---|---|---|---|---|---|
| TTT | 1 minute | Haute | Entraînement lourd | Haute | Moyenne | ★★☆ |
| LoL | Échelle heure | Moyenne (statique) | Entraînement nécessaire | Moyenne | Moyenne | ★★☆ |
| Self Forcing | Théoriquement illimité | Moyenne (baisse > 10s) | Modèle existant | Haute (VRAM) | Haute | ★★★ |
| Self Forcing++ | Échelle minute | Basse (très statique) | Entraînement nécessaire | Très haute (pas de code) | Haute | ★☆☆ |
| Infinite Talk | Illimité | Haute (tête parlante) | Entraînement nécessaire | Haute | Faible (A2V seulement) | ★★☆ |
| Helios | Théoriquement illimité | Haute (SOTA) | Réentraînement complet | Très haute (pas de poids) | Haute | ★★★☆ |
| SVI | Illimité | Moyenne-Haute | LoRA open-source | Moyenne | Haute | ★★★★ |
Une taxonomie issue de l'étude
En y regardant de plus près, chaque approche se classe dans l'une des trois catégories suivantes :
Type A — étendre la portée de l'attention elle-même (Self Forcing, LoL, TTT). Le modèle traite directement des séquences plus longues. Qualité théorique la plus élevée. La VRAM croît de façon quadratique, donc l'ingénierie se heurte à un mur autour de 10s.
Type B — compression hiérarchique de l'historique (Helios). Compresser les images passées et les injecter en tant que conditionnement. Contourne la limite de VRAM. Coûte un réentraînement complet d'un modèle 14B.
Type C — génération glissante avec état (SVI, Infinite Talk). Décomposer la vidéo longue en clips courts avec état chevauchant. VRAM constante, durée illimitée, entraînement uniquement par LoRA. Le compromis réside dans de possibles discontinuités aux frontières des clips et une dérive à long terme gérable mais inévitable.
Pour ce trimestre, le Type C est ce que nous lançons. Pour l'année prochaine, le Type B est là où nous suivons la littérature.
Dans le prochain article, nous détaillerons la mise en production — les six approches pour la génération vidéo ≥ 15 secondes, pourquoi nous avons choisi SVI et à quoi ressemblent les chiffres de production. Lire la partie 2 →






