
Dans la Partie 1, nous avons étudié six approches de génération de vidéos longues — TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk et Helios — pour conclure que SVI est la seule solution opérationnelle dès aujourd'hui sans nécessiter le réentraînement d'un modèle 14B. Cet article détaille ce que signifie concrètement construire avec cette solution : comment fonctionne la boucle d'assemblage des clips, pourquoi l'« Error-Recycling » est crucial et les chiffres de production obtenus lors de notre premier déploiement sur TurboWan.
Le choix : SVI (Stable Video Infinity)
La philosophie centrale de SVI est de transformer une génération de longueur infinie en un assemblage d'un nombre fini de clips courts, via un transfert de mémoire soigneusement conçu. Cela semble modeste jusqu'à ce que l'on réalise que cela résout la plupart des problèmes techniques d'un seul coup : aucun réentraînement du modèle de base (un petit LoRA monté sur TurboWan), VRAM constante, composabilité avec la distillation de vitesse existante, et poids LoRA officiels publics.
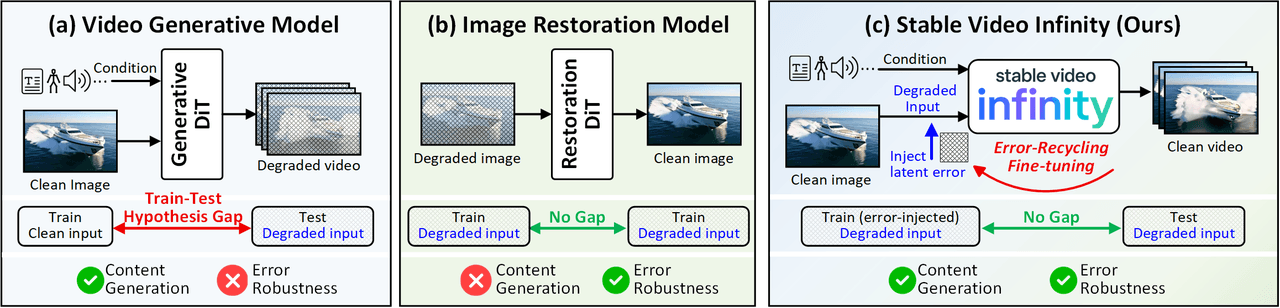
Modèle conceptuel de SVI. (a) Les modèles génératifs vidéo standards souffrent d'un écart entre l'entraînement et le test — ils sont entraînés sur des entrées propres, mais font face à des entrées bruitées et cumulatives en inférence. (b) Les modèles de restauration d'image sont robustes aux erreurs mais ne peuvent pas générer de nouveau contenu. (c) Le réglage fin par « Error-Recycling » de SVI fait le pont entre les deux — en utilisant les erreurs auto-générées comme signaux de supervision pour que le modèle apprenne activement à identifier et corriger ses propres erreurs de génération.
Comment fonctionne l'assemblage des clips
Chaque clip dure 81 images (5s à 16fps). La génération n'est qu'une boucle : conditionner le clip suivant sur une ancre d'identité globale et un pont de mouvement à court terme provenant du clip précédent, puis concaténer.
Clip 1. Entrées : image de référence + mémoire de mouvement vide. Sortie : un clip de 5s. Extraction de la mémoire de mouvement : le latent des 4 dernières images. Clip 2. Entrées : image de référence + mémoire de mouvement du clip 1. Sortie : un clip de 5s. Extraction de la mémoire de mouvement de sa fin. ... Répéter pour N clips, puis concaténer le clip 1 + clip 2 + … + clip N pour former la vidéo longue.
L'avantage est qu'aucune modification de l'attention du DiT n'est nécessaire. Le contexte historique est concaténé au niveau des entrées sous forme de latents, et un petit LoRA apprend au modèle à utiliser réellement ce préfixe.
Ancre latente. Image de référence fournie par l'utilisateur, encodée par le VAE → maintient une cohérence globale du sujet / personnage. Latent de mouvement. Latent des 4/8/12 dernières images du clip précédent → indique au modèle comment le segment précédent s'est terminé. Remplissage (Padding). Aligne la forme de l'entrée pour que le DiT voie une séquence concaténée ordonnée : ancre + mouvement + remplissage.
Réglage fin par « Error-Recycling »
Le détail qui permet à SVI de tenir sur plusieurs clips est la façon dont son LoRA est entraîné. L'inférence standard commence toujours le débruitage à partir d'un bruit gaussien pur — mais dans l'assemblage de vidéos longues, les erreurs des clips précédents contaminent le conditionnement des clips suivants. Si vous ne vous entraînez que sur des entrées de référence propres, vous avez intégré cet écart entraînement-inférence.
Entraînement standard : les entrées de référence de chaque clip sont des vérités terrain propres → le modèle ne voit jamais le type de contexte historique bruité auquel il fait face en inférence, et les discontinuités s'accumulent.
Error-Recycling : pendant l'entraînement, injectez délibérément les erreurs passées du modèle dans les entrées de référence, afin que le LoRA apprenne explicitement à opérer sur un contexte historique bruité. Les discontinuités visuelles aux frontières des clips diminuent considérablement.
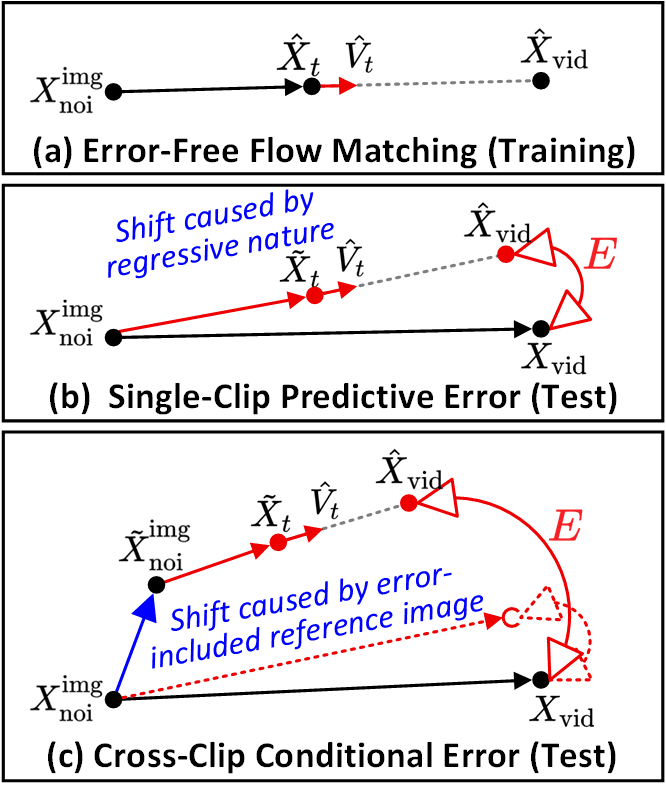
SVI identifie deux types d'erreurs fondamentaux. (a) Le « Error-Free Flow Matching » est la trajectoire lors de l'entraînement. (b) L'erreur prédictive par clip — la dérive entre le chemin de débruitage et la trajectoire idéale. (c) L'erreur conditionnelle inter-clips — les images de référence contaminées par des erreurs provoquent une dérive en cascade à travers les clips. L'Error-Recycling injecte explicitement les deux.
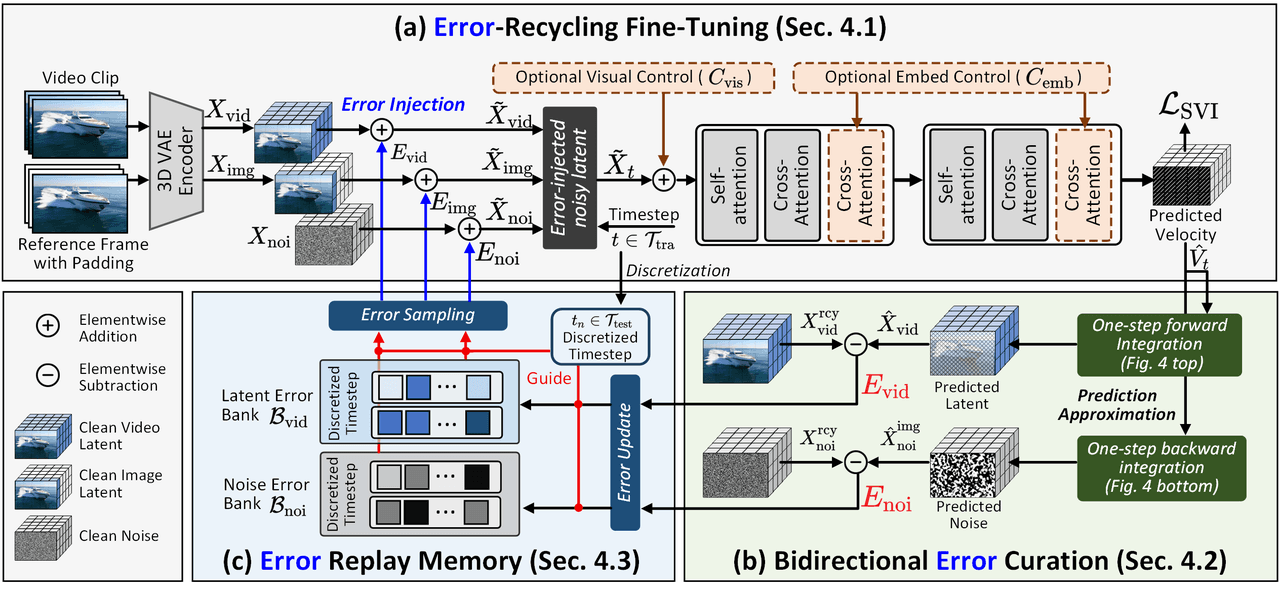
Framework d'entraînement SVI. (a) Injecter les erreurs auto-générées du DiT dans l'espace latent pour briser l'hypothèse d'absence d'erreurs. (b) Calculer efficacement les erreurs bidirectionnelles via une intégration directe/inverse en une étape. (c) Stocker les erreurs dans une mémoire de relecture et les rééchantillonner dynamiquement, formant un cycle de supervision d'erreur en boucle fermée.
SVI distingue deux types d'erreurs. L' Erreur prédictive par clip est la dérive propre à chaque clip entre le chemin de débruitage et la trajectoire idéale. L' Erreur conditionnelle inter-clips est la dérive en cascade causée par des images de référence contaminées transmises au clip suivant. L'Error-Recycling injecte les deux, permettant au LoRA d'apprendre une tolérance explicite aux erreurs.
Variantes de LoRA
SVI propose trois variantes — SVI-Shot pour image statique → clip court, SVI-Dance pour le mouvement humain (il peut également accepter une séquence de poses en entrée), et SVI-Film pour les vidéos longues multi-plans / transitions de scène. Hyperparamètres : 81 images par clip, num_motion_frames ∈ {4, 8, 12}, rang du LoRA généralement entre 16 et 64.
Stack technique sur TurboWan
Nous montons le LoRA de SVI sur TurboWan (une version accélérée de Wan optimisée par Atlas), et nous conservons notre LoRA spécialisé dans la stack pour le contrôle du style. En inférence, plusieurs poids LoRA sont superposés simultanément.
Base. TurboWan LoRA 1. LoRA spécialisé — contrôle du contenu / style. LoRA 2. SVI LoRA — cohérence de la vidéo longue. Combiné. Vitesse TurboWan + continuité vidéo longue SVI + style Spicy, le tout en un seul passage d'inférence.
Le flux d'inférence complet est simple : encoder la référence en un latent d'ancre, le concaténer avec le latent de mouvement du clip précédent et le remplissage, exécuter le débruitage de TurboWan, décoder, ajouter, et mettre à jour le latent de mouvement depuis la fin du clip fraîchement généré. Après N itérations, concaténer le tout en une seule vidéo.
1. Encoder l'image de référence → latent d'ancre. 2. y = concat(latent d'ancre, latent de mouvement, remplissage). 3. Exécuter le débruitage en 5 étapes de TurboWan conditionné par y et l'embedding de texte. 4. Décodage VAE du clip et ajout à la liste de sortie. 5. Définir le latent de mouvement = fin (derniers num_motion_frames) du clip tout juste généré. 6. Répéter pour N clips, puis concaténer le tout.
Quelques chiffres de production
Test standard : une seule image de référence et 3 prompts, générant environ 15s de sortie (3 clips × 5s) :
| Métrique | Valeur |
|---|---|
| Durée générée | 15s (3 clips) |
| Temps d'inférence par clip | ~14s (TurboWan fp8, GPU unique) |
| Temps d'inférence total | ~42s |
| Cohérence du sujet | Bonne |
Un exemple concret : L'aventure du chaton
Pour rendre le comportement inter-clips concret, nous avons réalisé un test de 15 secondes avec une référence et trois plans. Le prompt de style a fixé un rendu type Pixar avec un éclairage chaud ; le personnage était un chaton tigré orange aux grands yeux curieux ; les trois plans l'ont fait passer d'un rebord de fenêtre à un trottoir, puis à la rencontre d'un golden retriever, chacun avec sa propre direction de caméra.

Clip 1 (0–5s) : le chaton orange façon Pixar sur un rebord de fenêtre, avec la caméra reculant lentement d'un gros plan. Le style et le personnage restent stables à travers les images.

Clip 2 (5–10s) à la limite de transition : l'apparence du chaton correspond au Clip 1, puis il tourne et change de posture en sautant. Le latent de mouvement a transporté l'état de mouvement à travers la limite.

Clip 3 (10–15s) : un golden retriever est introduit et la scène transite vers une limite intérieur/extérieur. Le style Pixar du chaton reste stable sur les trois clips.
Métriques agrégées pour ce test :
| Métrique | Valeur |
|---|---|
| Durée totale | 15s (3 clips × 5s) |
| Nombre total d'images | 240 images (16fps) |
| Temps d'inférence total | 33s (TurboWan, GPU unique) |
| Ratio temps/vidéo | 2,2 s/s |
| Cohérence du sujet | Chaton orange Pixar stable tout du long |
| Discontinuité aux limites | Aucune coupure nette évidente |
Cela représente une vidéo de 15 secondes générée en 33 secondes sur un seul GPU, avec une cohérence du sujet entre les clips — bien en deçà de la limite d'attente de 60s que nous nous étions fixée. Sur un jeu de test interne de 14 cas, 9 cas ont été validés sans problème majeur (taux de réussite de 64%).
La conclusion honnête est qu'en génération vidéo, la vitesse, la durée et la qualité sont les trois sommets d'un triangle impossible. Aucune approche actuelle ne domine les trois à la fois. Le travail intéressant consiste à choisir le compromis le plus acceptable, compte tenu du matériel actuel et de votre budget d'entraînement. SVI sacrifie un peu de longueur et un peu de qualité aux transitions — et en échange, nous livrons aujourd'hui de la vidéo longue avec une fidélité de classe Wan2.2, sur un seul GPU.






