Seedance 1.5 Pro が Atlas Cloud で利用可能に:生成ビデオのための同期と制御の強化
ByteDance の革新的な AI 動画生成モデル Seedance 1.5 Pro が、開発者向けの強力な API と共に Atlas Cloud プラットフォームで正式にローンチされました。
Seedance 1.5 Pro 価格スナップショット:
| モデル | 価格 |
|---|---|
| Seedance 1.5 Pro テキストから動画へ | $0.0867/秒 |
| Seedance 1.5 Pro 画像から動画へ | $0.0867/秒 |
Seedance 1.5 Pro の紹介
Seedance 1.0 からの大幅な進化を遂げた ByteDance の Seedance 1.5 Pro は、プロフェッショナルな動画制作の効率を最大化するために設計された、シームレスで同期されたオーディオビジュアル出力を実現する V2A ネイティブ生成を導入しています。
Seedance 1.5 Pro のコア機能と能力
オーディオビジュアル同期
このアップデートでは、音声入力と視覚出力の間の整合性を最優先し、動画の全期間にわたって技術的な一貫性を確保しています。
- 正確なリップシンク: モデルはミリ秒単位のタイミングを使用して、口の動きと言語パターンをマッピングします。これにより、生成された動画でしばしば見られる、リップフラップが発話された音素と一致しない「吹き替え効果」が軽減されます。
- 統合されたサウンドスケープ: 生成プロセスには、視覚ストリームと並行して、環境音、アクションベースの音声キュー、BGM、ボーカルが含まれます。
- 時間的感情の一致: モデルは入力音声のトーンとリズムを分析し、キャラクターの視覚的な感情表現を調整して、セリフのデリバリーと顔の表情が一致するようにします。
比較分析: 現在の多くの動画生成モデルでは、音声は別々に生成されるか、緩やかに連携されるため、長尺のクリップではずれが生じます。Seedance 1.5 Pro はこれらのモダリティを統合し、ポストプロダクションでの手動での再タイミングや ADR(自動音声置換)の必要性を効果的に削減します。
マルチスピーカーナレーションと多言語サポート
Seedance 1.5 Pro は、複雑なインタラクションシナリオと多様な言語要件をサポートするように生成機能を拡張しています。
- マルチキャラクターインタラクション: システムは複数のスピーカーが登場するシーンをサポートし、個別のアイデンティティとキャラクター間のスムーズなターンテーキングを維持します。
- グローバル言語カバレッジ: モデルは、英語、日本語、韓国語、スペイン語、インドネシア語、ポルトガル語、北京語で一貫したパフォーマンスを発揮します。また、これらの言語内の地域方言も考慮します。
- 自然な音声合成: 音声エンジンは、自然なスピーチパターンに準拠した音声を生成し、異なる言語間でのキャラクターの一貫性を維持します。
実用的な文脈: 多国籍企業にとって、この機能はローカライズされたトレーニング資料やマーケティングアセットの作成を容易にします。単一の動画コンセプトを、各地域で正しいリップシンクで複数の言語で生成でき、ターゲット市場ごとに個別の声優を雇う必要がなくなります。
ディレクションコントロールとプロンプト遵守
このバージョンでは、確率的またはランダムな生成から脱却し、テキストプロンプトを通じて特定の視覚的結果を指示するユーザーの能力が向上しています。
- カメラワークコントロール: ユーザーは、パン、ズーム、トラッキングショット、およびさまざまなモーション速度などのシネマティックテクニックを、予測可能な結果と共に指定できます。
- アクション忠実度: モデルは、特定のキャラクターのアクション、動き、またはオブジェクトとのインタラクションを説明するプロンプトに厳密に従います。
- シーン構成: ユーザーは、ショットのレイアウト、タイミング、ペースを制御できます。システムは、生成プロセス内での統合ビジュアルエフェクトもサポートします。
比較分析: 標準的な生成モデルは、複雑な指示セットを無視して「幻覚」のようなカメラアングルや間違ったアクションを生じさせることがよくあります。Seedance 1.5 Pro は、ストーリーボードアーティストやディレクターが物理的な制作前にシーンを正確に計画できる、信頼性の高い視覚化ツールとして機能します。
ビジュアル忠実度と安定性
Seedance 1.5 Pro のレンダリングエンジンは、プロフェッショナルな表示に適した高解像度と構造的整合性を維持することに重点を置いています。
- テクスチャとディテール: 出力は、クリーンなテクスチャを維持し、デジタルアーティファクトを削減することで、ライブアクション映像を模倣します。
- ライティングと構成: モデルは、プロフェッショナルグレードのカラー処理と安定したライティング物理学を適用し、非論理的な影の配置を防ぎます。
- 時間的整合性: 動画の品質は、異なるシーンや長時間の再生にわたって一定に保たれ、拡張された生成クリップでしばしば見られる劣化やモーフィングを回避します。
実用的な文脈: AI 動画の以前のイテレーションでは、背景のちらつきやオブジェクトの歪みがしばしば発生していました。ここで提供される安定性により、映像は、視覚的なエラーが容易に認識される商業放送や高解像度プレゼンテーションで使用できます。
Seedance 1.5 Pro の応用
企業ローカライゼーション
- シナリオ: グローバルソフトウェア企業が、製品アップデート動画を7言語で同時にリリースする必要がある。
- 応用: 多言語サポートとリップシンク機能を活用し、チームは単一のアバタープレゼンテーションを生成します。スペイン語、北京語、英語でスクリプトを入力します。モデルは、アバターの口の動きが各言語に完全に一致する個別の動画ファイルを生成し、すべての地域でネイティブな視聴体験を保証します。
多言語能力をテストするためのケースはこちらです。動画をご覧ください。
映画プリビジュアライゼーション(プリビズ)
- シナリオ: 監督が、動く車両内で口論する2人の俳優が登場する複雑なトラッキングショットを視覚化したいと考えている。
- 応用: カメラコントロールと感情一致機能を利用し、制作チームはスクリプトとカメラモーションプロンプトを入力します。Seedance 1.5 Pro はシーンのラフカットを生成し、撮影クルーがセットに到着する前に AI 生成されたリファレンスに基づいてライティングとレンズの選択を計画できるようにします。
自動ニュース放送
- シナリオ: メディアアウトレットが、速報記事の迅速な動画要約を必要としている。
- 応用: アウトレットは、テキストフィードを Atlas Cloud 上の Seedance 1.5 Pro API に接続します。モデルは、ニュースアンカーが中立的でプロフェッショナルなトーンでテキストを読み上げ、適切な背景ビジュアルと共に自動的に動画を生成し、テキストが確定してから数分以内に公開準備完了の動画を提供します。
結論
Seedance 1.5 Pro は、実験的な出力から制御可能で制作準備の整ったアセットへと、生成ビデオにおける構造的な進歩を提供します。同期、制御、およびビジュアルの安定性に対処することで、精度と効率を必要とするクリエイターにとって機能的なツールを提供します。
👇今すぐ Atlas Cloud で Seedance 1.5 Pro を体験しましょう。👇
Atlas Cloud では、まずプレイグラウンドで Seedance 1.5 Pro を使用し、その後単一の API 経由でアクセスできます。
方法 1:Atlas Cloud プレイグラウンドで直接使用
プレイグラウンド で Seedance 1.5 Pro を試してみてください。
方法 2:API 経由でアクセス
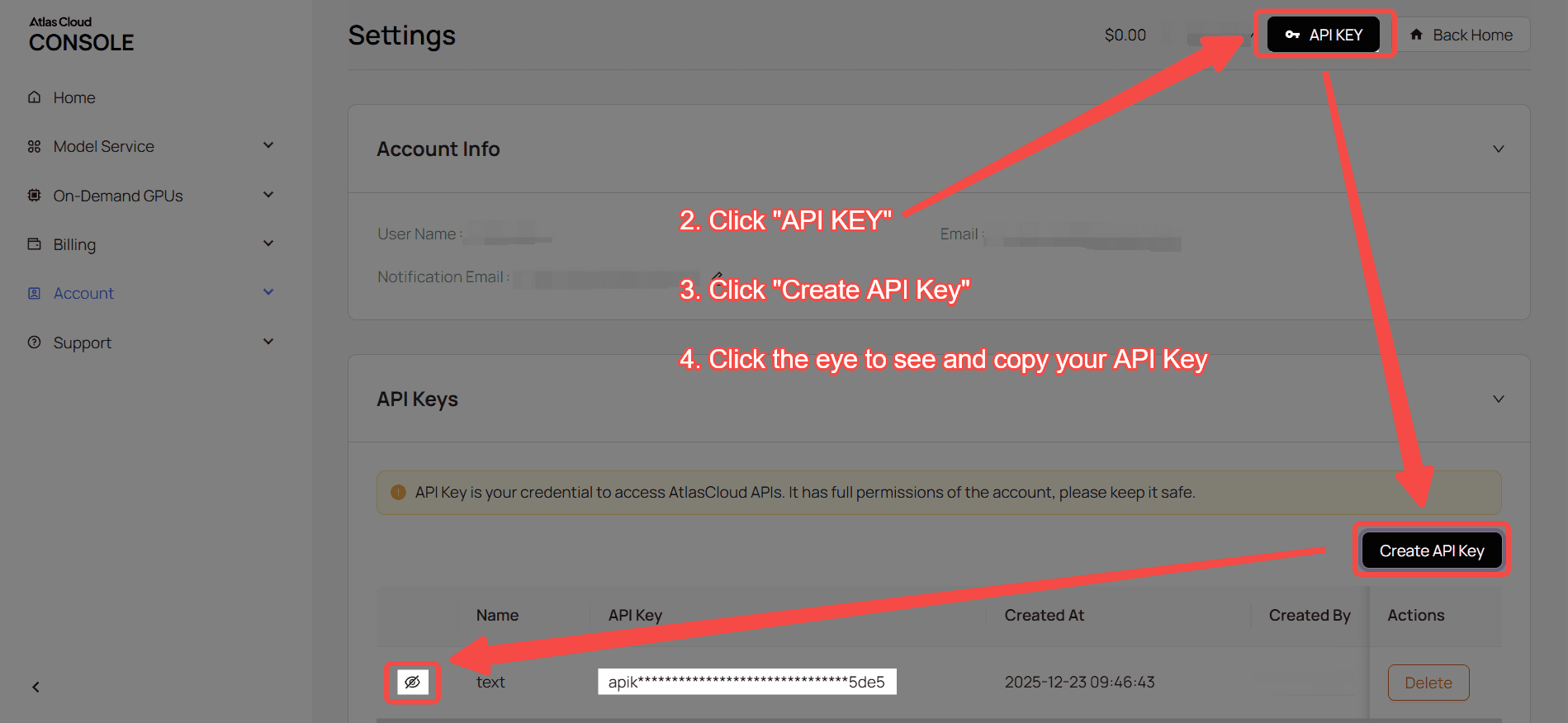
ステップ 1:API キーを取得
コンソール で API キーを作成し、後で使用するためにコピーします。
ステップ 2:API ドキュメントを確認
エンドポイント、リクエストパラメータ、認証方法については、API ドキュメント を参照してください。
ステップ 3:最初の要求を行う(Python 例)
例として seedance 1.5 pro テキストから動画への変換を示します。
plaintext1import requests 2import time 3 4# Step 1: Start video generation 5generate_url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6headers = { 7 "Content-Type": "application/json", 8 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 9} 10data = { 11 "model": "bytedance/seedance-v1.5-pro/text-to-video", 12 "aspect_ratio": "16:9", 13 "camera_fixed": False, 14 "duration": 5, 15 "generate_audio": True, 16 "prompt": "Shot 1 (establishing): Wide aerial of a quiet coastal cliff at sunrise, low fog rolling over the ocean, golden light breaking through thin clouds. A lone runner appears as a small silhouette on the winding path. Camera: smooth drone-like glide forward, slow and steady, cinematic pacing. Shot 2 (character): Medium tracking shot at ground level beside the runner, shoes crunching gravel, breath visible in the cool air, wind tugging at a lightweight jacket. Camera: gimbal-stable side-tracking, shallow depth of field, keep the runner's face and jacket details consistent. Shot 3 (emotion): Close-up on the runner's face—focused eyes, subtle micro-expressions, a quick swallow, determination building. Camera: gentle push-in, soft background bokeh, natural handheld micro-shake kept minimal. Shot 4 (end beat): The runner reaches the cliff overlook and slows to a stop; fog parts to reveal a vast sunlit ocean. The runner exhales and smiles slightly. Camera: slow tilt up from the runner to the horizon, hold for a calm finish. Style: photoreal live-action, natural sunrise lighting, filmic color grading, realistic wind and fabric motion, crisp facial detail. Continuity: same runner, same outfit, consistent sunrise direction and color temperature across shots; avoid warping, duplicate limbs, flicker, jump cuts, text overlays, logos.", 17 "resolution": "720p", 18 "seed": -1 19} 20 21generate_response = requests.post(generate_url, headers=headers, json=data) 22generate_result = generate_response.json() 23prediction_id = generate_result["data"]["id"] 24 25# Step 2: Poll for result 26poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 27 28def check_status(): 29 while True: 30 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 31 result = response.json() 32 33 if result["data"]["status"] in ["completed", "succeeded"]: 34 print("Generated video:", result["data"]["outputs"][0]) 35 return result["data"]["outputs"][0] 36 elif result["data"]["status"] == "failed": 37 raise Exception(result["data"]["error"] or "Generation failed") 38 else: 39 # Still processing, wait 2 seconds 40 time.sleep(2) 41 42video_url = check_status()
FAQ
Q: モデルはどの言語と音声形式をサポートしていますか?
A: Seedance 1.5 Pro は ネイティブなオーディオビジュアル統合生成を提供します。
- 言語サポート: 7つの主要言語(英語、北京語、日本語、韓国語、スペイン語、インドネシア語、ポルトガル語)を地域方言の精度でカバーしています。
- 利点: 音声と映像の合成を統合することで、単一のワークフローで ElevenLabs のような TTS ツールを個別に組み合わせるだけでは達成できない、自然なリップシンクとマルチスピーカーの流動性を実現します。
Q: カメラワークやシーンディレクションにおいて、ユーザーはどの程度の制御ができますか?
A: Seedance 1.5 Pro は、パン、ズーム、トラッキングを含む、きめ細やかなシネマティックコントロールを提供します。
- 精度: キャラクターのアクションやレイアウトに関するユーザープロンプトに厳密に従い、ストーリーボード計画に最適です。
- 差別化: 重要なのは、これらの視覚的な動きを音声のリズムに合わせることで、標準的な動画生成モデルではしばしば欠けているディレクションの一貫性を提供することです。
Q: ビジュアル出力は、商業放送や大画面に適していますか?
A: はい。Seedance 1.5 Pro は、OpenAI の Sora や Kling AI に匹敵するフォトリアリスティックな品質を提供します。
- ビジュアル忠実度: クリーンなテクスチャとプロフェッショナルなライティングを生成し、Stable Video Diffusion (SVD) のような以前のアーキテクチャで一般的な「ちらつき」や時間的な不整合を最小限に抑えます。
- 商業利用: 長尺コンテンツ全体でスタイルの一貫性を維持する能力は、プレミアムブランドのストーリーテリングや重要なプレゼンテーションに実行可能なソリューションとなります。



