DeepSeek-V4 プレビュー版発表:100万トークンのコンテキスト、エージェント機能の強化、そしてオープンソースでの重み公開
本日(4月24日)、DeepSeekは最新モデルシリーズであるDeepSeek-V4のプレビュー版を正式に発表し、オープンソース化しました。
DeepSeek-V4は最大100万トークンのコンテキストをサポートし、エージェント機能、一般知識、推論能力において、国内およびオープンソースモデルの中でトップクラスの性能を達成しています。本シリーズには2つのサイズが用意されています。
- DeepSeek-V4-Pro — フラッグシップモデル。総パラメータ数1.6兆を誇る巨大なMoE(Mixture of Experts)モデルですが、推論1回あたりのアクティブパラメータ数はわずか490億に抑えられており、これが効率性の鍵となっています。
- DeepSeek-V4-Flash — より高速でコスト効率に優れたモデル。Proと同様のMoE設計をより小規模(総パラメータ数2840億 / アクティブ130億)にスケールダウンしており、より高速かつ安価な推論が可能です。
- 両モデルとも100万トークンのコンテキストウィンドウを共有し、API経由で完全にオープンソースとして利用可能です。
| モデル | パラメータ数 | アクティブ数 | 事前学習データ | コンテキスト長 | オープンソース | APIサービス | Web/Appアクセス |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | Expert Mode |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | Fast Mode |
本日より、chat.deepseek.com または公式アプリにてDeepSeek-V4をご利用いただけます。APIも公開されており、model_nameを deepseek-v4-pro または deepseek-v4-flash に設定するだけで利用を開始できます。
以前公開した推論およびリリース前の分析(DeepSeek V4 予想ガイド および 詳細な技術解説)の内容が、公式発表によって裏付けられました。以下では、実際にリリースされた機能や新要素、そして開発・評価に携わる方にとっての意味を解説します。
DeepSeek-V4-Pro:クローズドソースのトップモデルに匹敵
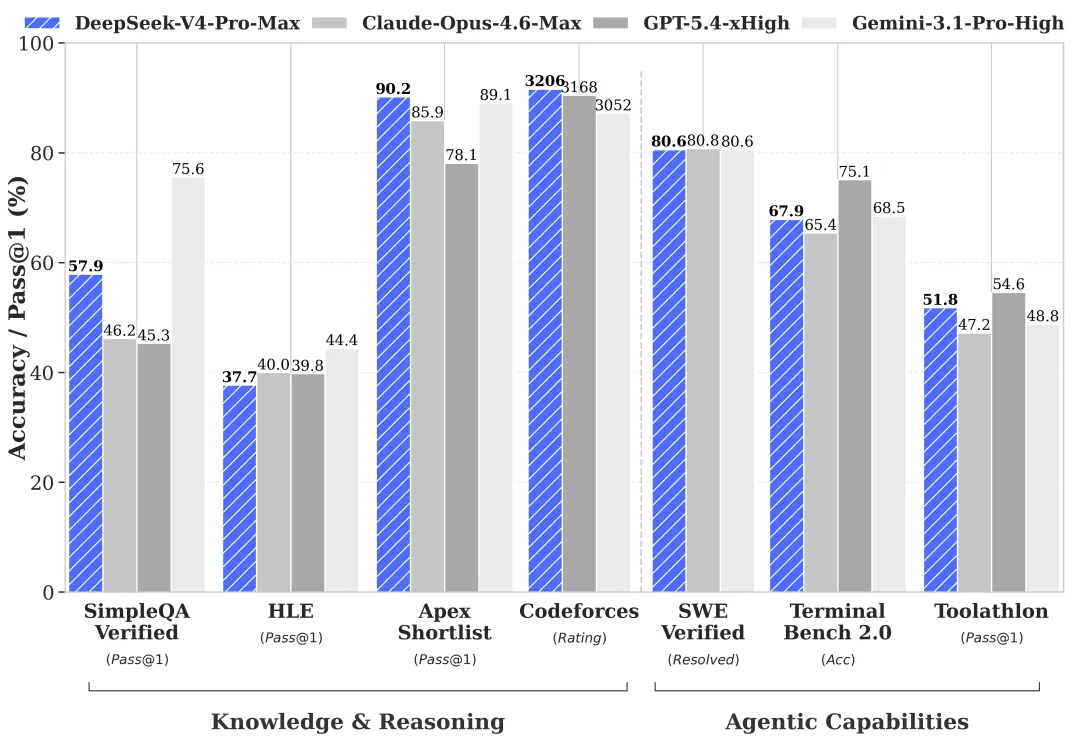
大幅に強化されたエージェント機能。 前世代と比較して、DeepSeek-V4-Proはエージェントタスクにおいて劇的な改善を見せています。「Agentic Coding」ベンチマークにおいて、V4-Proはすべてのオープンソースモデルの中でトップに立ちました。DeepSeek社内でもコーディング用エージェントとして導入されており、従業員のフィードバックによると、その体験はClaude Sonnet 4.5を上回り、非思考(non-thinking)モードではClaude Opus 4.6に近い品質に達しています(ただし、Opus 4.6の思考モードにはまだ及びません)。
豊富な一般知識。 DeepSeek-V4-Proは、一般知識のベンチマークにおいて他のオープンソースモデルを大きく引き離し、クローズドソースのトップモデルであるGemini Pro 3.1にわずかに迫る性能を示しています。
世界最高水準の推論能力。 数学、STEM、競技プログラミングの評価において、DeepSeek-V4-Proはこれまでベンチマークされたすべてのオープンソースモデルを凌駕し、世界トップクラスのクローズドソースモデルに匹敵するパフォーマンスを発揮します。
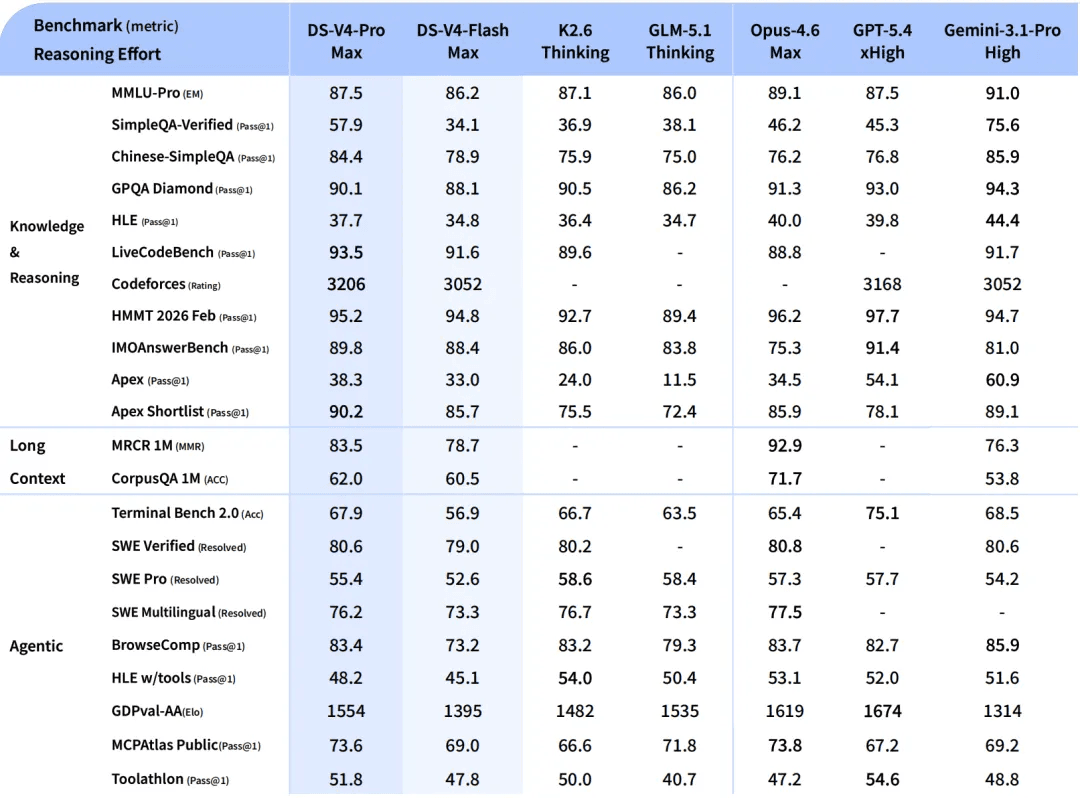
DeepSeek-V4-Flash:高速かつ手頃な選択肢
V4-Proと比較すると、DeepSeek-V4-Flashは一般知識では若干劣りますが、推論能力は同等です。パラメータ数が少なくアクティブ数も低いため、V4-Flashはより高速な応答速度と経済的なAPI価格を提供します。
エージェントベンチマークにおいては、単純なタスクではV4-Proに匹敵し、より複雑なタスクでは依然として差があるものの、非常に優秀な結果を示しています。
アーキテクチャの革新と究極のコンテキスト効率
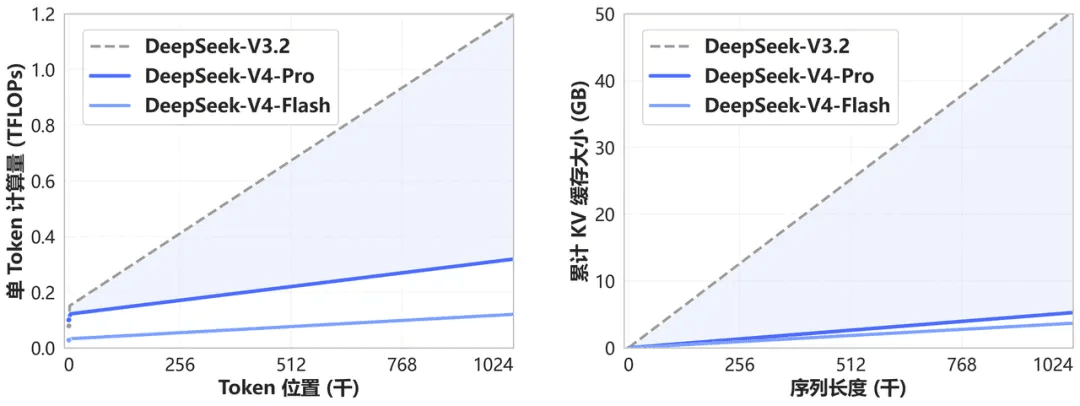
DeepSeek-V4は、トークン次元に沿って圧縮を行う斬新なアテンションメカニズムを導入しています。**DSA(DeepSeek Sparse Attention)**との組み合わせにより、従来の手法と比較して計算量とメモリ要件を劇的に削減しながら、世界最高水準の長大なコンテキスト処理性能を実現しました。
今後、1M(100万)トークンのコンテキストは、すべての公式DeepSeekサービスにおける標準となります。
エージェント利用向けに特化した最適化
DeepSeek-V4は、Claude Code、OpenClaw、OpenCode、CodeBuddyなど、人気のエージェント製品向けに微調整と最適化が行われています。コード生成、ドキュメント作成、およびその他のエージェント主導のタスクにおいてパフォーマンスが向上しています。
このようなフレームワーク固有のチューニングは、単なる数値以上の意味を持ちます。独立した環境で優れた性能を発揮しても、構造化されたエージェントのループ内での挙動が不安定なモデルは、実用的なデプロイが困難だからです。主要なエージェントフレームワークを最適化の第一優先ターゲットとする判断は、AIのプロダクション利用がどのように進化しているかを反映しています。
DeepSeek-V4 APIアクセス
V4-ProとV4-Flashは、両方ともDeepSeek API経由で利用可能です。OpenAI ChatCompletionsインターフェースとAnthropicインターフェースの両方をサポートしているため、既存のインテグレーションを最小限のコード変更でV4モデルに切り替えることができます。ベースURLに変更はなく、modelパラメータを deepseek-v4-pro または deepseek-v4-flash に更新するだけです。
両モデルとも最大1Mトークンのコンテキスト長をサポートし、**non-thinking(非思考)モードとthinking(思考)**モードの両方を提供します。思考モードでは、reasoning_effortパラメータを「high」または「max」に設定可能です。複雑なエージェントワークフローには、max設定での思考モードを推奨します。APIアクセスのドキュメントはこちら:https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ 廃止のお知らせ: 旧モデル名である
deepseek-chatおよびdeepseek-reasonerは、**3か月後(2026年7月24日)**に廃止されます。移行期間中、これらはそれぞれdeepseek-v4-flashの非思考モードおよび思考モードにマッピングされます。プロダクション環境でこれらの名前を使用している場合は、早急に移行計画を立ててください。
オープンソースの重みとローカルデプロイ
- モデルの重み:Hugging Face | ModelScope
- 技術レポート:DeepSeek-V4 PDF
ローカルまたはオンプレミス環境へのデプロイを検討しているチームにとって、このパラメータ規模のモデル(特に総パラメータ数1.6TのV4-Pro)はハードウェアに多大な負荷をかける点に注意が必要です。オープンソースであることは、企業のコンプライアンスやカスタマイズにおいては大きな利点ですが、多くのチームにとってはクラウドAPI経由での利用がより現実的な出発点となるでしょう。
DeepSeek-V4のローンチが意味するもの
今回のリリースから、3つの重要なポイントが見えてきます。
第一に、1Mコンテキストの標準化は予想以上に重要な意味を持ちます。DeepSeekはこれをプレミアムオプションとして提供するのではなく、公式サービスすべてにおけるベースラインとしています。これはオープンソースのフロンティアがどこに向かっているかを示すシグナルであり、他のすべてのプロバイダーに対する静かな圧力となるでしょう。
第二に、エージェント優先の最適化(特にClaude CodeやOpenCode等への適応)は、DeepSeekがデプロイについていかに成熟した考えを持っているかを反映しています。ベンチマーク性能はあくまで入り口であり、プロダクション環境で重要なのは、開発者が日常的に使用するツールの中での挙動だからです。
第三に、Claude Opus 4.6との誠実な競争評価です。全面的に優れていると主張するのではなく、Sonnet 4.5より良く、Opus 4.6の非思考モードに近づき、思考モードにはまだ及ばないという層別化された評価を示しています。こうした具体性が、主張の信頼性を高めています。
エージェントワークフロー、長文処理、複雑な推論タスクのためにモデルを評価している開発者にとって、DeepSeek-V4-Proは現在最も有力なオープンソースの候補です。また、コスト重視や低レイテンシが求められるパイプラインにおいては、V4-Flashが極めて強力な軽量代替案となります。
Atlas CloudでDeepSeek-V4を試す
Atlas Cloud は、インフラの運用を管理することなく、信頼性が高く費用対効果の高い方法で世界最先端のAIモデルにアクセスしたい開発者やチームのために設計された、プロダクショングレードのAIプラットフォームです。統合されたAPI、透明性の高い料金体系、エンタープライズレベルのコンプライアンス(SOC 2準拠、HIPAA対応)により、Atlas Cloudは運用ではなく構築に集中できるようにします。
Atlas CloudでのDeepSeek: 私たちはすでにDeepSeekモデルファミリーをサポートしており、DeepSeek V3.2, V3.2 Fast, V3.2 Speciale, V3.2 Exp が単一のAPIエンドポイント経由で利用可能です。Atlas Cloud上のDeepSeekモデルは、長文コンテキストワークロードやエージェントパイプライン向けに最適化されており、コンテキストウィンドウのフルサポートと量子化による劣化ゼロを実現しています。DeepSeek以外にも、 Atlas CloudではLLM全体で300以上のモデルにアクセス可能です。
DeepSeek-V4がAtlas Cloudに登場予定です。 現在、DeepSeek-V4-ProおよびV4-Flashの統合作業を精力的に進めています。発表をお待ちください。それまでの間、現在利用可能なすべての機能をご確認ください。






