
その感覚、分かりますよね。
深夜、ブランドキャンペーンの改修に4回も追われている状況です。AIがヒーローショットの完璧なライティングを生成したのに、モデルの顔が今夜3度目の微妙な変化を遂げてしまいました。衣装は同じ。でも、別人です。これでは納品できません。修正も不可能です。やり直しです。
深夜0時を回る頃には、あなたはもう動画を編集しているのではなく、ロシアンルーレットをしているような気分でしょう。
ストーリーの一貫性を構築しようとする人にとって、複数のショットで同じモデルを使う製品デモ、複数のシーンで同じ講師が登場するチュートリアル、カットが変わっても同じ歌手が登場するミュージックビデオなど、キャラクターの「ドリフト(変容)」は、あらゆるAI動画ツールの隠れた最大の欠陥でした。AI動画がこれまで実用化されず、「面白いデモ」の域を出られなかったのはこのためです。

2026年5月19日、Google I/O 2026において、Googleの Gemini Omni は、この時代が終わりを迎えることを示しました。
その核心は、Google DeepMindの製品ページにある一行に集約されています。「編集を行うたびに前回の内容が引き継がれ、一貫性のあるコヒーレント(整合性のある)なシーンが維持される」というものです。
歴史を変えた3段階のバイオリニストデモ
I/Oの発表で最も重要な瞬間は、転がるビー玉でも、泡の彫刻でもなく、一人のバイオリニストでした。
Googleがステージとブログで示したプロセスは以下の通りです:
- ステップ1: ステージで曲を演奏するバイオリニストのベースライン動画。
- ステップ2: プロンプト — 「バイオリニストを画像内の環境へ転送して」。結果:背景は変わったが、奏者の顔、姿勢、弓の持ち方、手首の角度まで完全に同一。
- ステップ3: 次のプロンプト — 「カメラアングルをバイオリニストの肩越しに変更して」。結果:新しいフレーミング。同じバイオリニスト。同じアイデンティティ。同じパフォーマンス。
3回のターン。一人の被写体。ドリフトはゼロ。
現在のAI動画ツールを使い込んでいる人なら、これが「ずる」のように見えるはずです。しかし、そうではありません。これは、映像作家や広告主、教育者が待ち望んでいた「マルチターン・リファインメント(複数回にわたる洗練)」というワークフローが、技術的に現実のものとなり、出荷可能であることを示す初の公式な証拠なのです。
なぜ「マルチターンの整合性」がAI動画の弱点だったのか
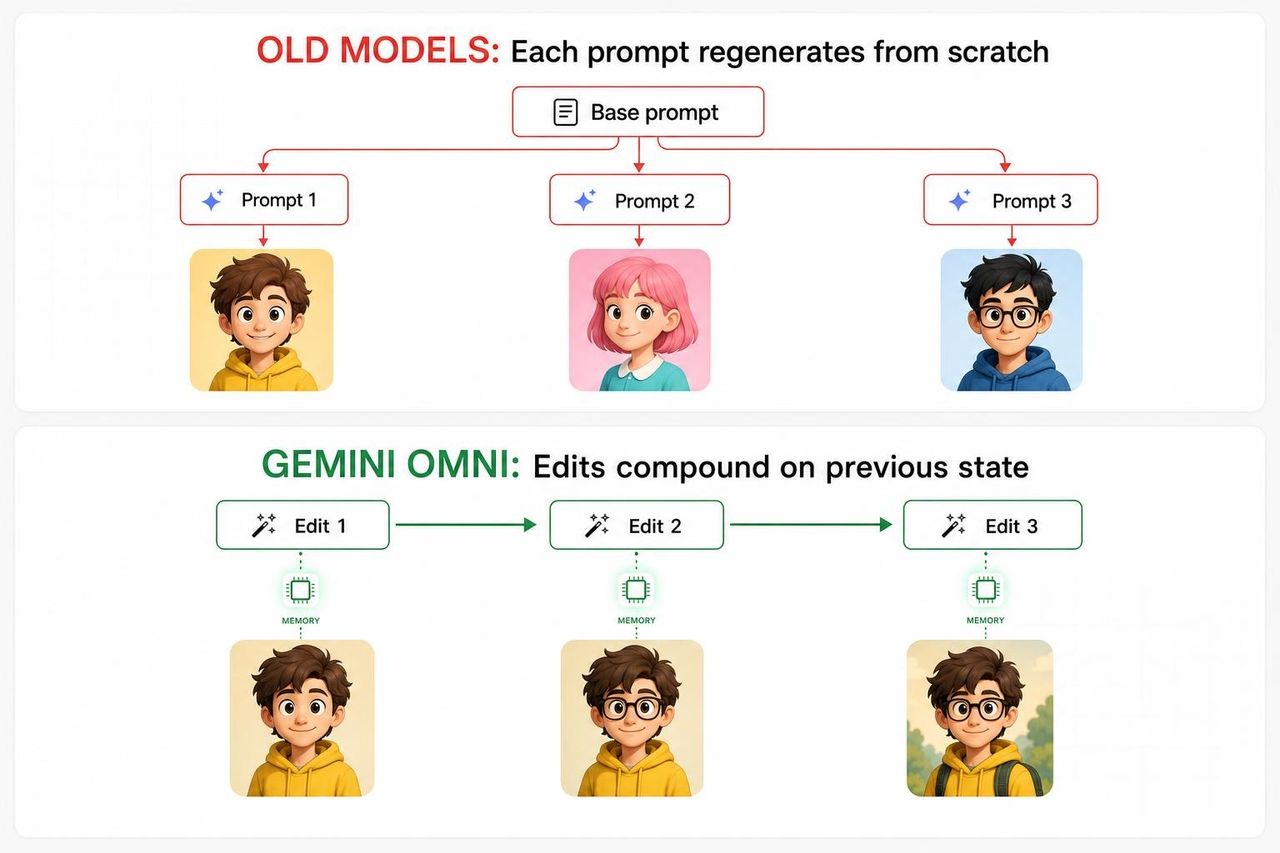
なぜこのバイオリニストのデモが重要なのかを理解するには、他のAI動画モデルがこれまで何に失敗してきたのかを知る必要があります。
従来の生成AI動画パイプラインでは、新しいプロンプトを入力すると、元のプロンプトと新しいプロンプトを組み合わせて、実質的にシーンをゼロから再生成していました。モデルには、ターン間で内部的な連続性がほとんどなかったのです。顔は変わり、背景の小道具は消え、ライティングも変わってしまう。3ターン目には、元のビジョンとはかけ離れた結果になり、クリエイターは諦めてやり直すしかなかったのです。
根本的な原因はアーキテクチャにあります。ほとんどの動画モデルは、マルチターンのエージェントではなく、一度きりの生成器として学習されてきました。プロンプトから一度の最良の結果を出すことに最適化されており、前回何を生成したかを記憶し、そこから洗練させることには向いていなかったのです。「編集」を求めても、それは実質的に「追加のコンテキスト付きでやり直す」ことと同義であり、その計算プロセスがさらなるドリフトを生んでいたのです。
Omniのアプローチは異なります。これは「ステートフル(状態保持型)エディタ」として構築されています。つまり、各ターンがシーンの持続的な表現を更新するため、ゼロから再生成する必要がないのです。
「シーンが記憶する」ということの意味
英語圏のテックメディアも、同じ事実にたどり着いています。
Decryptは、この画期的な進歩を最も分かりやすく説明しています:「Googleによると、Omniはユーザーが動画に変更を加えても、同じキャラクター、背景、動きを一貫して維持できる。これは多くのAI動画モデルが苦戦していた点だ」
Android Centralは、重要な技術的詳細を指摘しています:「同社は、モデルが複数ステップの修正中に過去のコマンドを記憶しているとしており、これにより反復的な編集作業の混乱が大幅に軽減される可能性がある」
TechRadarは映画的な視点で報じました:「キャラクターは認識可能なままであり、シーンは連続性を維持する。プロンプトが変わるたびに動きがリセットされることなく、一貫した動作を保つ」
そして Phandroid は、その全機能を5語で要約しました:「シーンは以前の状態を覚えている(The scene remembers what came before)」
これが結論です。シーンが記憶する。 この単一の特性こそが、AI動画を「おもちゃ」から「ツール」へと変える決定的な差なのです。
一貫性におけるSora、Veo、Seedanceとの比較
2026年5月時点での、主要なAI動画モデルのマルチターン整合性に関する比較です:
| モデル | マルチターン編集 | 会話型リファインメント | キャラクター整合性 | 現状 |
|---|---|---|---|---|
| Gemini Omni Flash | ステートフル、マルチターン | ネイティブなチャットベース | (3/5) | 2026年5月19日リリース |
| Sora 2 (OpenAI) | ワンショット生成 | 限定的 | - | サービス終了 |
| Veo 3.1 (Google) | 部分的 | テキスト+画像のみ | Omniより低い | 提供中(Omniへ移行) |
| Seedance 2.0 (ByteDance) | リファレンスベース | 限定的 | (4/5) | 提供中 |
正直な見解:Omniは、真の意味で「ステートフル」なマルチターン編集ができる唯一のモデルです。Seedanceは生成ごとに最大9枚の参照画像を活用することでキャラクター整合性において高い評価を得ていますが、それを「編集セッション全体を通して」維持することはできません。Soraは一般向けから撤退し、Veoは統合されつつあります。
「リロール(再生成)」から「リファイン(洗練)」へ — このワークフローが解き放つもの

ここでの真の価値はデモにあるのではなく、ワークフローの変革にあります。
Blockchain.newsは、この商業的な影響を次のように表現しました:「バッチ編集により、複数の動画セグメントに対して同時に修正が可能になり、AI生成コンテンツの品質基準を維持しつつ、制作を加速できる。映画、広告、教育コンテンツのクリエイターは、コスト削減と物語の信頼性向上という大きなメリットを得る」
この最後のフレーズ「物語の信頼性(narrative reliability)」こそ、コンテンツ制作に関わる誰もが注目すべき点です。
これまで、AI動画は1つの良いクリップを提供することはできても、「キャンペーン」――つまり同じ主人公、同じブランドアセット、同じ視覚言語を複数の納品物全体で共有する一連の映像を作ることはできませんでした。すべての編集がコイン投げのような運任せだったのです。しかし今は、編集が積み重なっていきます。
TechTimesは、公に示された機能セットを次のように要約しました:ユーザー撮影素材の編集、リアルな外観とアニメーションの外観とのスタイル変換、マルチターン・リファインメント、解説動画風の生成。
また DataCampの実践レビュー でも、マルチターンの挙動が実戦に耐えうるものであると確認されました:「Omniはマルチターン編集をサポートしているため、シーンの一貫性を保ちながら、詳細、環境、カメラアングルを段階的に洗練させることができる」
ワークフローのシフトは理論上は小さく見えますが、実際には巨大です。「生成 → 再生成 → 再生成 → 諦める」が、「生成 → 洗練 → 洗練 → 納品」へと変わるのです。
開発者たちも気づいています。中国の開発者フォーラムV2EXで、リリース初日にOmniをテストしたエンジニア はこう書いています:「生成速度と一貫性は期待以上だった」
AIエンジニアと最前線のクリエイターがリリースから数時間で同じ観察結果に至るというのは、マーケティング用語ではなく、実際の能力シフトが起きている証拠です。
正直な懐疑論 — Omniはまだ完璧ではない
整合性の問題が解決したと宣言する前に、冷徹な意見も伝えておきます。
MediumのAI Analytics Diariesのレビュアー は、OmniとByteDanceのSeedance 2.0を比較し、Omniのキャラクター整合性に「5段階中3」という評価を下しました。
すべてのAI動画プロダクトマネージャーのモニターに貼り付けておくべき一言があります:「両モデルとも、複数のカットにわたるキャラクター整合性には苦戦している。これは依然としてAI動画の開いた傷口(解消されていない課題)である」
つまり、Omniは「単一の編集セッション内での」マルチターン・リファインメントにおいては他のどの公開モデルよりも優れていますが、カテゴリ全体として問題が完全に解決したわけではないのです。
まだ残されている課題とは:
- 単一シーンでのマルチターン整合性は極めて良好(バイオリニストのデモ)
- クロスカット(同じキャラクターで、異なるシーン、異なるライティング設定、異なるフレーミング)の整合性は依然として不完全
- 微細な特徴(顔の詳細、手の表現、特定の衣服の質感など)は、何度も編集を重ねるとドリフトする可能性がある
- Omni Flashの現在の10秒クリップ制限により、長編ストーリー制作におけるマルチターン整合性はまだ公にストレステストされていない
ユースケースの80%(単一シーンの洗練、SNS用動画、マーケティング用素材)については、Omniはすでに十分納品可能な品質です。残りの20%(30カットのシーケンス全体でキャラクターの一貫性が求められる映画品質の作業)には、まだ編集による修正作業が必要です。
業界ごとに何が変わるのか
マルチターン整合性が解決(またはセッション内ではほぼ解決)された今、何が可能になるのでしょうか。
ブランド広告: キャンペーンの継続性。ファッションブランドは、再撮影も、新しいモデルの採用も、手作業での修正もなしに、同じモデルを10の異なる環境で展開できるようになります。SNSファーストのクリエイティブ制作の収支は劇的に変わるでしょう。
教育・チュートリアル制作: シリーズの一貫性。AI生成された一人の講師が、視聴者に合成であることを気づかせることなく、全12回のコースを担当できます。「コンテンツ全体で顔が一貫しない」という問題は、2年間もAI教育の足を引っ張ってきましたが、それが今、解決されました。
映像作家: 大規模なプリビジュアライゼーション。同じ俳優を使い、複数のシーン案、ライティング、カメラアングルを単一セッションで生成し、反復的に洗練させることができます。「アイデアがある」から「監督に見せられる」までのギャップが、数日から数分へと短縮されます。
ECチーム: リストのバリエーション間で一貫性のある製品ヒーローショット。同じモデル、6つの衣装、ライフスタイルショット、スタジオショット、環境内ショットを、すべて一貫した状態で同じマルチターンセッションから生成できます。
ゲーム開発: カットシーン間でも同一人物に見えるNPC。ゲーム内AIシネマの弱点は、主人公がシーン間で微妙に変化してしまうことでしたが、Omniのステートフル編集により、キャラクター固定が商業的に実現可能になります。
プロビナンス(起源)の緊張感 — 一貫性のある「フェイク」は見抜くのが難しくなる
この進歩には、直接指摘すべき暗い側面もあります。
マルチターン整合性が向上するということは、フェイクを見抜くのが難しくなることを意味します。顔がカットごとに変化したり、手の形が変わったり、髪の色がドリフトしたりといったAI特有の「兆候」が、一貫性によって修正されてしまうからです。Omniとその継承モデルが内部的な連続性を高めるほど、「明らかに合成」と「実写と見分けがつかない」の境界線は急速に狭まります。
これこそが、すべてのOmni生成クリップにGoogleの不可視のSynthID透かしとC2PAコンテンツ認証情報が生成時に組み込まれている理由です。Geminiアプリ、Chrome、検索内で検証可能であり、これはオプションではなく、オフにすることはできません。
また、Googleが動画内の音声や会話の編集機能を意図的に制限したのもこのためです:「私たちは、この機能を責任を持ってユーザーに提供する方法を模索している」。つまり、一貫性のある顔と修正された声を組み合わせたディープフェイクのリスクは、安全策なしに出荷するには大きすぎるということです。
ブランドやクリエイターにとって、計算式は変化しています。「フェイク」コンテンツを人の目で検出することが信頼できなくなるにつれ、暗号化されたプロビナンスがコンテンツの真実性の新しい基準となります。 整合性の向上には、プロビナンスの義務がセットで付いてくるのです。
新たなボトルネックは品質ではなく「モデルの乱立」
AI動画プロダクトを構築するすべての人にとって、戦略的に意味することは以下の通りです。
主要モデル間の性能差は急速に縮まっており、同時に断片化も進んでいます。2026年半ば現在:
- Gemini Omni は、マルチターン整合性と会話型編集でリード
- Seedance 2.0 は、シネマティックな動きとスタイライズされたアニメーション、強力なリファレンスベースのキャラクター整合性でリード
- その他の専門モデルは、長尺生成、きめ細かいキャラクター制御、音声同期、低コストのバッチ処理などでリード
今四半期に整合性が最強のモデルが、次の四半期もシネマティックな動きで最強とは限りません。今日最も物理演算が強力なモデルが、半年後に音声同期で一番とも限らないのです。そして、すべてのモデルが独自のSDK、認証フロー、価格体系、レート制限、契約条項を持っています。チームは、統合のたびにエンジニアリングスプリントを浪費し、非推奨になるたびにさらにスプリントを費やすことになるでしょう。
これこそが、Atlas Cloud が解決するために構築された断片化問題です。私たちは開発者に、300以上のモデル(主要な基盤モデル、主要なオープンソースリリース、画像・動画・音声・推論にわたる最新の専門モデル)にアクセスできる単一の統合エンドポイントを提供します。Gemini Omniへのアクセスは今後数週間以内にAtlas Cloudに追加されますので、テストのためにスタックを切り替える準備ができ次第、統合はすでに完了していることになります。
チームにとっての実践的な意味は以下の通りです:
- コードを1行変更するだけでモデルを切り替え可能 — SOTA(最先端)モデルが出るたびにSDKの統合を書き直す必要はありません
- 同一プロンプトで比較評価を実行 — 予算を投じる前に、特定のユースケースでどのモデルが実際に優れているかを見極められます
- 能力ごとに最強のモデルを出荷 — 今日は整合性のリーダー、明日はシネマティックな動きのリーダー、次の四半期はコスト効率のリーダーを活用
- 請求、オブザーバビリティ、レート制限を一つのダッシュボードで管理 — 12個の個別アカウントを管理する必要はありません
2026年にAI動画プロダクトを出荷する構築者にとって、賢明なアーキテクチャの選択肢は「Omniに賭ける」ことではありません。「次に勝つものなら何にでも切り替えられる抽象化レイヤーの上で構築する」ことです。Gemini OmniがAtlas Cloudに搭載されれば、Seedanceや、その次の画期的なモデル、あるいはその後に来る何かに対して、統合コードを1行も変えずにテストできるようになります。
整合性、物理演算、シネマティックな動き、音質のそれぞれが異なるモデルによってリードされる市場において、特定の1つに固執することは、技術的負債を抱える最悪の選択です。 Atlas Cloudは、その断片化という足かせを追い風に変える抽象化レイヤーなのです。
動画生成制作のための単一統合API
GoogleがGeminiアプリ内でGemini Omni Flashを展開する一方で、独自のワークフローにマルチモーダル動画エンジンを組み込みたい開発者やチームには、安定した予測可能なAPIレイヤーが必要です。
Atlas Cloudは、OpenAI互換の統合APIを通じてGemini Omni Flashを提供します。300以上の他の画像・動画・LLMモデルと併用できるため、個別のベンダーアカウントやSDKをやりくりすることなく、Googleのネイティブなマルチモーダルモデルを統合できます。
Gemini Omni Flashの両バリアントは Atlas Cloud で利用可能です:
| バリアント | 最適な用途 | 入力 | 解像度 | 尺 | 開始価格 |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video | プロンプト主導のシネマティック生成 | テキスト (最大20,000文字) | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash Image-to-Video | 実写ベースのキャラ一貫性動画 | テキスト + 参照画像(最大7枚) | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
クイックスタート — 5行でGemini Omni Flash動画を生成:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
APIは即座にprediction IDを返します。/api/v1/model/prediction/{id} をポーリングして、レンダリングされたMP4のURLを取得してください。完全なスキーマ、7言語でのコードサンプル、ノーコードのPlaygroundは、上記のモデルリンク先で利用可能です。
核心的インサイト
マルチターン整合性が重要な理由は、デモ自体にあるのではなく、それが何を解き放つかにあります。
5年間、「AI動画がいつ商業化されるか」というすべての会話は、「モデルが編集を通じてキャラクターの一貫性を保てるようになった瞬間」という同じ壁にぶつかってきました。その壁が、今動いたのです。
バイオリニストのデモはスタントではありません。主要な研究所が、実働するマルチターン編集ワークフローをステージ上で提示した初めての事例です。次にマーケティングチームがAI動画ツールに「6つのシナリオで同じ製品のヒーローショットを6つ作って」と依頼するとき、彼らは6つの無関係な顔ではなく、6つの使用可能な成果物を期待できるはずです。






