Googleは2026年のI/Oで、タイムラインやキーフレームではなく、日常的な会話を通じてビデオを編集するマルチモーダルモデル「Gemini Omni」を発表しました。バイラルとなったデモ(バブルスカルプチャー、リキッドミラー、バイオリニスト)が証明している真の変化は、単なるテキストからビデオへの生成ではなく、「既に手元にあるビデオをテキストで編集できる」という点です。これはビデオ制作における「iPhoneのカメラ」モーメントとも言える瞬間です。音声、オーディオ編集、そしてProティアが意図的に省かれている点も注目すべきポイントです。
深夜1時。30秒のクリップを編集して4時間が経過しました。プロジェクトファイルは47レイヤーに達し、キーフレームをドラッグしすぎて手首は悲鳴を上げています。クライアントからのメッセージは「照明をもう少し暖かみのある感じにできますか?」……プロであるあなたは、また一からやり直そうとしています。
それが、これまでの仕事でした。これまでの「仕事」だったのです。
2026年5月19日、Googleはその時代を静かに終わらせました。
GoogleはI/O 2026において、ビデオ編集を多くの人が10年先のことだと思っていた領域へと変えるマルチモーダルモデルGemini Omniを発表しました。それは**「ごく自然な会話」**です。
核となる約束:ビデオを「操作」するな、「対話」せよ
この発表を一行で言えば、ビデオを「操作」するのではなく、どうしたいかを伝えるだけでいいということです。
Googleの公式発表では、回りくどい表現は使われていません。「各指示は前回の内容に基づきます。キャラクターの一貫性は保たれ、物理法則は維持され、シーンは以前の状態を記憶しています」。
これは単なるVeoのアップデートではありません。Google DeepMindのプロダクトページは、より分かりやすくこう解説しています。「Gemini Omniは、ビデオ版のNano Bananaと考えてください」。昨年、Nano Bananaはテキスト入力だけで写真編集を可能にしました。今度はOmniが、それを動画で行うのです。
このファミリーの最初のモデルである「Gemini Omni Flash」は、すでにGeminiアプリ、Google Flow、YouTubeショートで利用可能です。
そして、このカテゴリー全体を捉え直す上で重要な一言があります。TechCrunchのDeepMindチームへのインタビューの中で、リサーチエンジニアのGabe Barth-Maron氏は、人々がOmniで作成しているものを「パーソナライズされたミーム」と表現しました。
これが本質です。ビデオ制作は「職人技」から「表現」へと移行しました。かつてiPhoneが登場し、デジタル一眼レフの牙城を崩した写真の世界と同じ現象です。
Twitter(現X)を沸かせているデモ
マーケティング資料を読み込むよりも、この発表の凄さはデモを見れば一目瞭然です。今、以下の3つのデモがSNSを席巻しています。
- バブルスカルプチャー: 石の彫刻のクリップを入力し、「彫刻をシャボン玉にして」と指示すると、構図や照明、影はそのままに、彫刻が周囲の光を反射する半透明の石鹸膜へと変化します。
- リキッドミラー: 手が鏡に触れるシーンで「鏡が液体のように波打つようにして、腕が鏡面素材に変わるように」と指示します。Windows Reportが報じたように、波紋は物理的に外側へ広がり、腕のクローム素材には実際の部屋が反射します。
- 連続編集: バイオリニストのデモでは、ステージから移動先、そして肩越しのカメラアングルまで、3段階の編集を見せています。編集は3回。被写体は同一。顔、姿勢、楽器の持ち方まで、すべてが維持されています。

これは単なる「テキストからビデオ」への生成ではありません。「既にあるビデオをテキストで編集する」こと。この違いはわずかに見えて、すべてを根底から変えます。
なぜクリエイターは熱狂しているのか
この発表が他のモデルリリースよりも強力な理由はシンプルです。Omniは、生成ビデオにおける最悪のループを断ち切ったからです。
従来のループ: 生成 → 気に入らない → プロンプトを書き直す → 90秒待つ → まだダメ → 繰り返し。
新しいループ: 生成 → 「照明をゴールデンアワーに変えて」 → 完了 → 「カメラの押し出しを遅くして」 → 完了。
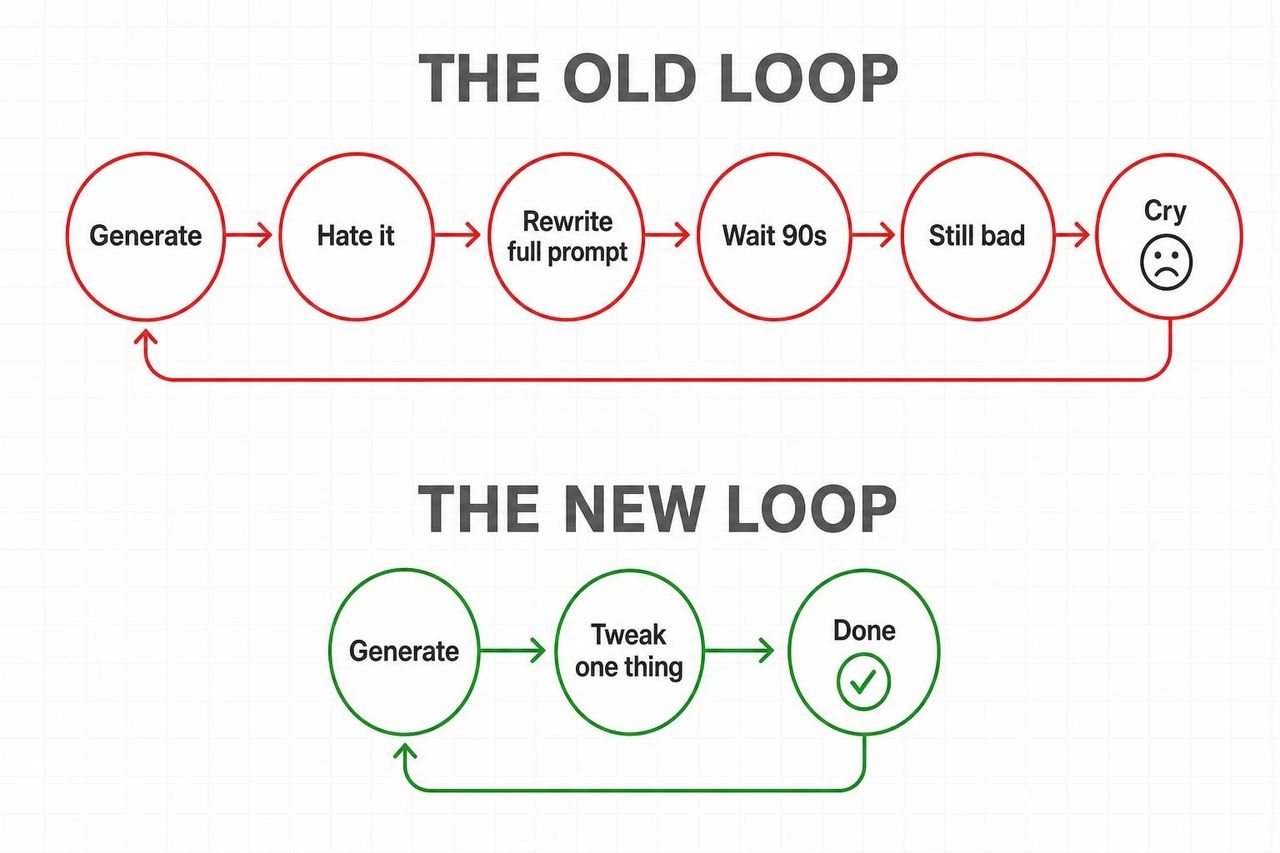
Android Centralは容赦なくこう評価しました:「Gemini Omniの登場で、従来のビデオ編集アプリは古臭いものに感じられるだろう」。TechRadarも同様の視点で、プロンプトごとにリセットされるのではなく、動きが一貫して維持される点を評価しています。
開発者たちもすでに動き出しています。中国の掲示板V2EXでは、リリース当日にテストした開発者が「動画内のオブジェクトをチャットベースで修正できる――このインタラクションこそが明らかに未来の方向性だ。速度と一貫性は期待を超えていた」と投稿しました。Xでは、免疫学者でAIコメンテーターのDerya Unutmaz博士も「ワオ!Google DeepMindが『Gemini Omni』という素晴らしいマルチモーダルAIをリリースした。映像は非常に美しい!すぐに試すべきだ!」と投稿しています。
AI界の識者や開発者コミュニティが数時間のうちに同じ評価を下すということは、これが確実な変曲点であることを意味します。
Googleが慎重な姿勢を見せている部分
もちろん、すべてが完璧というわけではありません。注意すべき点もあります。

Engadgetは重要な懸念を指摘しています。「Veo 3.1や他の生成ビデオアプリの最大の問題は、映像の『不気味の谷』現象であり、ユーザーから嫌われることも多い。この出力品質が、Googleの主張通りになるかは見ものだ」。
また、DataCampの検証では、投石機が弾薬を後ろに発射するという物理演算上のバグも確認されました。独立したベンチマークスコアもまだ公開されておらず、検証には今後数週間かかる見込みです。
さらに、意図的な制限もあります。既存ビデオ内での音声やオーディオの編集機能です。Google自身が認めているように、同社は「この機能を責任を持ってユーザーに提供する方法を慎重に検討している」段階です。言い換えれば、ディープフェイクのリスクは深刻であり、最も危険な機能はまだ公開を控えているのです。
すべてのOmniクリップには、Googleの目に見えないSynthIDウォーターマークとC2PAコンテンツクレデンシャルが付与されます。これはオプションではなく、現在の標準的な必須事項です。
ワークフローへの本当の影響
誇大広告を抜きにすれば、真に新しい価値が見えてきます:
- ツールは「会話」そのもの。 タイムラインも、レイヤーも、キーフレームも不要。言葉だけで完結します。
- フィードバックループが崩壊。 90秒かかっていた再生成が、10秒の調整に短縮されます。
- 専門家の優位性が縮小。 センスさえあればSlackメッセージを返すのと同じ速度でビデオを改良できるようになれば、ボトルネックは「技術力」から「アイデア」へと移行します。
マーケティングチーム、インディー系クリエイター、教育関係者など、「ちょっとした10秒のクリップ」を必要とするすべての人にとって、これは大きな変曲点です。モデルが完璧だからではなく、インタラクションのパターンがついに正解にたどり着いたからです。
未来のビデオ編集にソフトウェアは不要。必要なのはボキャブラリーだけです。
本番用ビデオ生成のための統合API
GoogleはGeminiアプリやGoogle Flowを通じてGemini Omni Flashをエンドユーザーに提供していますが、自身のワークフローに同じマルチモーダルビデオエンジンを組み込みたい開発者やプロダクトチームには、安定的で予測可能なAPI層が必要です。
Atlas Cloudは、Gemini Omni FlashをOpenAI互換の統合APIを通じて提供しています。300以上の画像、ビデオ、LLMモデルと並んで提供されるため、ベンダーごとの個別契約や支払いポータル、SDKの管理に頭を悩ませることなく、Googleのネイティブなマルチモーダルモデルを統合できます。
Gemini Omni FlashのバリエーションはAtlas Cloudで利用可能です:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| バリエーション | 最適用途 | 入力 | 解像度 | 長さ | 開始価格 |
|---|---|---|---|---|---|
| Gemini Omni Flash テキストからビデオ | プロンプトによるシネマティック生成 | テキスト (最大20,000文字) | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash 画像からビデオ | 参照画像に基づいたキャラクター一貫性のある動画 | テキスト + 参照画像最大7枚 | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
クイックスタート — Gemini Omni Flashで5行のコードでビデオ生成:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
APIは直ちに予測IDを返します。/api/v1/model/prediction/{id} をポーリングして、レンダリングされたMP4 URLを取得してください。詳細なスキーマ、7つの言語でのコードサンプル、ノーコードのプレイグラウンドは、上記のリンク先で公開されています。
最後に — 構築に取り組むすべての人へ
今回のようなモデルが登場するたびに突きつけられる残酷な現実があります。それは、次の四半期にはまた「世界最高」を謳うモデルが3つも登場するということです。それぞれ異なるSDK、異なる認証フロー、異なるレート制限、異なる価格体系。あなたのチームは、そのたびに導入のための1週間を費やし、前のモデルの廃止にも1週間を費やすことになるでしょう。
それこそが、まさにAtlas Cloudが解決する課題です。
私たちは、300以上の主要モデルへアクセスできる単一のエンドポイントを開発者に提供します。あらゆる主要な基盤モデル、主要なオープンソースモデル、そして画像、ビデオ、推論に特化した専門モデルを網羅しています。コード一行でモデルを切り替え、SDKを再統合することなくサイドバイサイドでベンチマークを実行できます。今日ホットなモデルを実装し、来月にはまた別のモデルに乗り換える――何も書き直す必要はありません。
今、AI業界で唯一確実なのは「毎週火曜日にはリーダーボードが塗り替わる」という事実だけです。それに備えた開発をしましょう。






