ほとんどの人は、今でも「言葉を磨けば、より良い画像が生成できる」と考えています。それは2年前なら正解でしたが、今は違います。
2026年の今、モデル同士の差よりも、ユーザー間の差こそが重要です。片方のグループは「シネマティックなライティング、4K、超精細」と入力し、もう片方のグループはシーンを「構築」します。光の向き、奥行きの層、カメラのアングルを細かく組み立てるのです。
もし生成された画像がのっぺりしているなら、その原因はモデルではなく、モデルに指示できていない情報にあります。
なぜあなたのプロンプトでは不十分なのか(2026年版)
ありきたりなプロンプトは、もはや通用しません。「最高品質」「高精細」といったフレーズは、モデルにとって何百万回も学習済みの言葉であり、もはや結果をほとんど左右しません。
本当に重要なのは「構造化された入力」です。光はどこから差し込んでいるか?手前と奥には何があるか?どのレンズを使っているか?現代のモデルは、こうした変数に反応するように設計されています。意味のない修飾語は無視されるのです。
よくある失敗例を見てみましょう。「ソフトな照明で美しいポートレート」と入力しても、モデルが出力するのはのっぺりとした画像です。なぜなら、光の方向も、奥行きの分離も、カメラのアングルも指定されていないからです。モデルは推測するしかなく、推測の結果は「平均的なもの」にしかなりません。
必要なシフトは単純です。結果を「描写」するのをやめて、シーンを「構築」してください。
上級者向け7つのヒント
-
光の方向を指定する
「ソフトな照明」という言葉は曖昧です。サイドライト、バックライト、トップライトなど、具体的な方向を指定すれば、モデルは明確な答えを出せます。光の方向は影を作り、影は奥行きを生み、奥行きはリアリティを生みます。
「ソフトなポートレート照明」と書く代わりに、こう試してみてください:
女性のポートレート、左側からのサイドライト、顔の右側にソフトな影、背景からの控えめな環境光

結果は一目瞭然です。モデルは光の位置を正確に把握しています。
-
本物のライティング設定を使う
「3点照明」「リムライト」「レンブラントライト」などは、単なる専門用語ではありません。これらはモデルが学習中に何度も目にしてきたライティングパターンです。これらを使うことで、出力の安定性が劇的に向上します。
例:
スニーカーの製品ショット、3点照明設定、強いキーライト、ソフトなフィルライト、製品と暗い背景を分離する繊細なリムライト

「ドラマチックな照明」と言うよりも、確実に良い結果が得られます。
-
層を重ねて奥行きを作る
平坦に見える画像は、すべての要素が同じ平面にあることが原因です。前景、中景、背景を明示的に指定して修正しましょう。
例:
木製テーブルの上のコーヒーカップ(前景)、ノートPCで作業する人物(中景)、暖かな照明が灯る、わずかにぼやけたカフェの室内(背景)

こうすることで、モデルは空間的な関係性を考慮できるようになります。
-
スタイル名ではなく「カメラ用語」を使う
「サイバーパンク風」は曖昧ですが、「35mmレンズ、ローアングル、ワイドショット」は精密です。カメラ設定は、画像の生成方法と直接的に結びつきます。
以下の基本設定を使いこなしましょう:
- 35mm:自然で日常的な見た目
- 85mm:圧縮効果のあるポートレート
- 広角:ドラマチックで壮大なスケール
- ローアングル、アイレベル、トップダウン:視点のコントロール
例:
クローズアップポートレート、85mmレンズ、浅い被写界深度、アイレベル、背景のソフトなボケ

これだけで、「美しいポートレート」という指示よりも遥かに明確な結果が得られます。
-
コントラストで視線を誘導する
すべてを細かく描画することが目的ではありません。重要なのは「コントラスト」です。光と影、暖色と寒色、シャープな被写体とぼやけた背景を使い分けます。
効果的な3種類のコントラスト:
- 明暗のコントラスト:暗い背景に浮かび上がる明るい被写体
- 色のコントラスト:寒色系の背景に当たる暖色のスポットライト
- ディテールのコントラスト:シャープな被写体と、ぼやけた環境
例:
暗く冷たい色調の背景に対し、暖色のスポットライトに照らされた被写体、高コントラストなライティング、被写体を強調したフォーカス
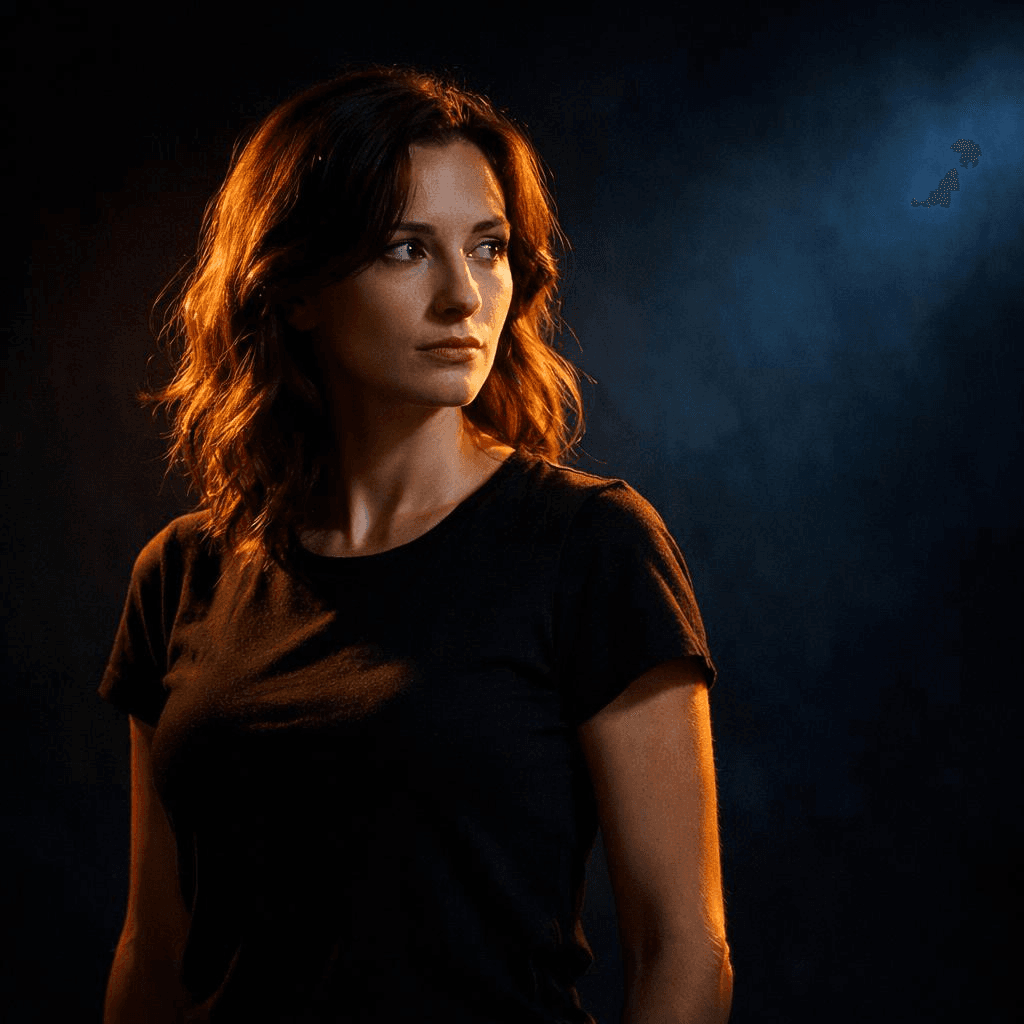
これによって、見る人の視線をコントロールできます。
-
制約を加えて混沌を整理する
プロンプトが長すぎると混乱を招きます。情報を付け加えるのではなく、「制限」を加えましょう。不要なものを指定するのです。余計な装飾、歪み、余計なオブジェクトを省くよう指示します。
例:
ミニマルな製品ショット、中央配置、クリーンな白背景、装飾なし、テキストなし、歪みなし

制約を加えることは、説明文を増やすことよりも効果的な場合があります。
-
ギャンブラーではなく「監督」のように反復する
最初から完璧な画像を作れる人はいません。プロは生成し、調整し、再生成します。
単純なワークフロー:
- ステップ1:基本的な構図、被写体、環境を決定
- ステップ2:方向性のあるライティングとコントラストを追加
- ステップ3:細部を洗練させ、ノイズを取り除く
このプロセスを繰り返すことで、運任せではない「一貫性」が生まれます。
まとめ:プロフェッショナルなプロンプトフレームワーク
プロンプトを長文で書くのはやめて、モジュール型のシステムとして構築しましょう。
推奨される構造:
plaintext1[被写体] + [環境] + [ライティング] + [カメラ] + [構図] + [カラー] + [制約]
基礎的なプロンプトと、構造化されたプロンプトの違いを見てください。
例:基礎的なプロンプトからプロレベルへの変換
基礎的なプロンプト(一般的なユーザー):
白いサマードレスを着た女性モデル、クリーンな背景、スタジオ照明、高精細、eコマーススタイル

プロフェッショナルなプロンプト(構造化):
白いサマードレスを着た女性モデル(被写体)、ベージュの質感のある背景を持つミニマルなスタジオ(環境)、右側からのサイドライトにより身体の左側にソフトな影、シルエットを背景から分離する繊細なリムライト(ライティング)、85mmレンズで撮影、アイレベル(カメラ)、被写体をわずかに中央から外し、浅い被写界深度、手前のソフトなボケで奥行きを追加(構図)、自然で暖かな色調、ソフトなコントラスト(カラー)、クリーンな構図、装飾なし、歪みなし、余計なオブジェクトなし(制約)

結論:プロンプトからディレクションへ
単発で優れた画像を作ることは簡単です。しかし、実際のプロジェクトには、一貫性のある高品質なビジュアルが何百枚も必要です。手動のプロンプト入力では、スケールしません。
遅延、コスト、バッチ間の一貫性の維持など、現実的な問題に直面します。これらはプロンプトデザイン単体では解決できません。システムが必要です。
そこで不可欠なのが、APIベースの画像生成です。毎回プレイグラウンドに入力するのではなく、生成プロセスをワークフローに統合するのです。構造化されたプロンプトを再利用し、自動化し、時間をかけて最適化する。
Atlas Cloudのようなプラットフォームは、このための統合API層を提供します。
以下のような方には最適です: • 簡単で安価なAI利用を求める開発者 • 複数のプロジェクトでAIを活用するチーム • 信頼性の高いAIビジュアルを必要とするビジネス • ComfyUIやn8nのようなツールを利用している方
AtlasCloudを使えば、単なる実験から本番制作へと移行できます。インフラを一から作り直す必要はありません。
未来は、プロンプトを孤立して書くことではなく、制御可能で、再現性のある、プロダクションレベルのビジュアルシステムを構築することにかかっています。
よくある質問
なぜAI生成画像がのっぺりしてしまうのか?
平坦に見えるのは、奥行きのヒントが不足しているからです。写真の原理を考えてみてください。奥行きは「影」「重なり」「焦点の差」から生まれます。プロンプトでこれらを明確に指定する必要があります。
単純なプロンプト「デスクに座る人物」では、奥行きに関する情報はほぼゼロです。代わりに「デスクに座る人物(中景)、窓の外にぼやけた街の明かり(背景)、シャープな焦点が当たったコーヒーカップ(前景)」と指定しましょう。こうすることで、モデルはレイヤーを意識できます。
照明も重要です。「環境光」だけでは平坦になります。サイドライト、バックライト、リムライトといった、方向性のある光源を最低一つは指定してください。モデルが影を生成し始めれば、画像に立体感が生まれます。
また、画面の隅々まで情報を詰め込もうとしないこと。余白とボケは重要な要素です。詳細が少ないほうが、かえって奥行きを感じさせることもあります。
AIは製品撮影を代替できるか?
多くの場合でイエスです。ただし、向き不向きはあります。
高級時計の宣伝写真のように、金属への反射一つひとつや、レザーストラップの質感が厳密に求められる場合は、依然として伝統的な写真が勝ります。その点において、本物のスタジオに勝るものはありません。
しかし、それ以外のほとんどのケース(カタログ画像、ライフスタイル写真、季節ごとのバリエーション、A/Bテスト用素材など)では、AIの方が圧倒的に速く安価です。クリーンな白背景の製品写真を数秒で生成し、それを砂浜や冬の小屋、モダンなキッチンといったシーンに合成することも可能です。
スタジオのレンタルも、照明のセットアップも、レタッチも不要。1枚あたりのコストはわずかです。
小規模ブランドやD2Cスタートアップにとって、これはゲームチェンジャーです。2年前には不可能だった規模のビジュアル制作が、今では可能になっています。
OpenAIの画像生成モデルは以前のバージョンとどう違うのか?
新しいモデルであるGPT‑image‑1.5は、内部アーキテクチャが刷新され、「Diffusion Transformer」を採用しています。これは、空間的な関係性をより正確に処理できることを意味します。
旧バージョンでは、複雑なシーンを別々に解釈して違和感が残ることがありました(例:手がカップを持っているのではなく、近くに浮いている)。新バージョンでは、これらが統合され、手はカップを掴み、影は適切な方向に落ちます。
テキスト描画能力も大幅に向上しました。以前は解読不能な文字でしたが、GPT‑image‑1.5は多言語を正確に生成します。英語と中国語を混在させることも可能です。
また、アップスケーリングなしで最大2Kの解像度をネイティブサポートしており、アーティファクト(ノイズ)が少なく、細部まで鮮明です。
ただし、曖昧なプロンプトには厳しくなりました。「素敵なポートレート」だけで魔法のような結果を期待することはできません。しかし、光の方向や奥行き、カメラ設定といった構造化された指示を与えれば、これまでの世代をはるかに凌駕する品質が得られます。






