Google Gemini Omniは、2026年5月19日のGoogle I/Oで発表された、Google DeepMindによるオールインワンAIモデルです。最大の画期的な点はネイティブ・マルチモーダルであることです。これは、異なるツールを連携させるのではなく、単一のシステム内でテキスト、画像、音声、動画を処理・生成できることを意味します。アプリを切り替えることなく、簡単な会話を通じて動画を作成・編集したいクリエイター、開発者、企業向けに設計されています。
Gemini Omniの機能概要の根底にあるのは、「あらゆる入力から何でも作成する」という考え方です。従来の単独のテキスト・トゥ・ビデオ(text-to-video)AIツールとは異なり、OmniはGeminiの推論能力と高度なメディアレンダリングを1回のプロセスで組み合わせます。
主な機能一覧
| 機能 | 詳細 |
|---|---|
| 入力形式 | テキスト、画像、音声、動画 |
| 主要な出力 | 動画(画像・音声は近日対応予定) |
| 編集スタイル | 会話型、マルチターン・プロンプト |
| 初代モデル | Gemini Omni Flash |
| 利用対象 | Google AI Plus、Pro、Ultraのサブスクリプション登録者 |
アクセス方法
- Geminiアプリ — AI Plus/Pro/Ultraサブスクリプション登録者(全世界)
- Google Flow — 短編映画制作ワークフロー全体
- YouTube Shorts / YouTube Create — ショート動画制作
- Developer API — 数週間以内に公開予定
Google Gemini Omniとは何か、その仕組みは?
Google Gemini Omniは飛躍的な進化を遂げたモデルです。Google DeepMindが提供する主要なオールインワン型クリエイティブAIモデルであり、2026年のGoogle I/Oで発表されました。このシステムはテキスト、画像、音声、動画を同時に受け取り、高品質な動画コンテンツを生成します。Geminiエコシステムにおいて、公式にVeoの後継モデルとなります。
中核エンジン:ネイティブ・マルチモーダルの仕組み
従来のAI動画ツールの多くは、「入力をテキスト記述に変換し、それを別の動画レンダラーに渡す」という逐次的なパイプラインを踏んでいました。Gemini Omniは異なります。ネイティブ・マルチモーダルモデルに基づいて構築されており、メディアタイプを個別のステップでルーティングするのではなく、単一の中核エンジン内で同時に処理します。
これが重要な理由は、変換レイヤーをスキップすることでモデルがよりリッチなコンテキストを保持できるからです。テキストプロンプトと一緒に参照用写真を渡すと、Omniは両方を同時に推論するため、テキスト変換ステップで失われがちな視覚的詳細を維持できます。
実践におけるGemini Omniのマルチモーダル入力
Gemini Omniのマルチモーダル入力は、単一のプロンプトで以下の組み合わせをサポートします。
| 入力タイプ | 利用例 |
|---|---|
| テキストのみ | シーンをゼロから記述 |
| 画像 + テキスト | 静止画をテキスト指示でアニメーション化 |
| 動画 + テキスト | 既存のクリップを会話形式で編集 |
| 音声 + テキスト | 視覚的なプロンプトに合わせたトーンのガイド |
| 混合(4種すべて) | 参照クリップ、スタイル画像、ナレーションの組み合わせ |
リアルタイム処理と会話による制御
推論が単一モデル内で行われるため、編集指示のリアルタイム処理が現実的となります。「背景を入れ替える」「照明を調整する」「ショットを安定させる」といった変更を単に記述するだけで、マルチターン形式の会話を通じて出力が洗練されます。最初からやり直す必要はありません。
Google DeepMindのNicole Brichtova氏は、これを「Veoの単なるアップデートではなく、Geminiの推論能力とメディアレンダリングが融合した一貫性のあるシステム」と表現しました。
会話型動画編集AI:Gemini Omniによる高度なアセット修正
アーキテクチャの理解も大切ですが、実際に動かすことは別問題です。ここでGemini Omniの会話型動画編集AI機能が、従来のツールと一線を画します。
従来の動画エディターは、タイムライン、レイヤー、手動でのキーフレーム設定を必要としました。Gemini Omniはそのワークフローを完全に置き換えます。フッテージをアップロードし、変更したい内容を入力または音声で話すだけで、モデルがクリップを再レンダリングします。プラグインや外部ソフトウェアは不要です。
Gemini Omniは複雑なAI動画要素の差し替えに対応しているか?
はい、これこそが実用面で最も便利な機能の一つです。Googleの公式ドキュメントによると、サポートされている動画アセット修正タスクには以下が含まれます。
- 背景の入れ替え — キャラクターを維持したまま、被写体背後の環境を置換
- 服装とスタイルの変更 — 服装の変更や、クリップ全体へのビジュアルスタイルの転送
- オブジェクトの差し替え — ショットの途中でシーン内の特定のアイテムを交換
- 照明の調整 — 単一の指示でシーンの照明の雰囲気や強度を変更
- 動画の手ブレ補正 — 自然言語プロンプトによる映像の安定化
- キャラクターの差し替え — 参照画像を使用して別の被写体に入れ替え
マルチターン会話を通じたインタラクティブ動画編集
これが単発の生成ではなくインタラクティブな動画編集である理由は、マルチターン(複数回)のループ構造にあります。各編集指示は前の指示の上に構築されるため、背景、照明のロジック、キャラクターの同一性といったシーンの一貫性が、繰り返しの調整過程でも維持されます。
例えば、クリエイターが「背景を街の通りにして」と指示し、続いて「照明をもっと暖かくして」、最後に「ショットを安定させて」と指示すれば、生成を最初からやり直すことなく反映されます。
AI動画要素の差し替え:現時点での期待値
現行のGemini Omni FlashモデルにおけるAI動画要素の差し替えは、10秒のクリップを対象としています。より長いフォーマットにおける複雑な動画アセット修正や、独立した画像・音声といった追加の出力タイプは、今後のリリースで予定されています。
マルチターン・ループをマスターする:Gemini Omniプロンプトガイド
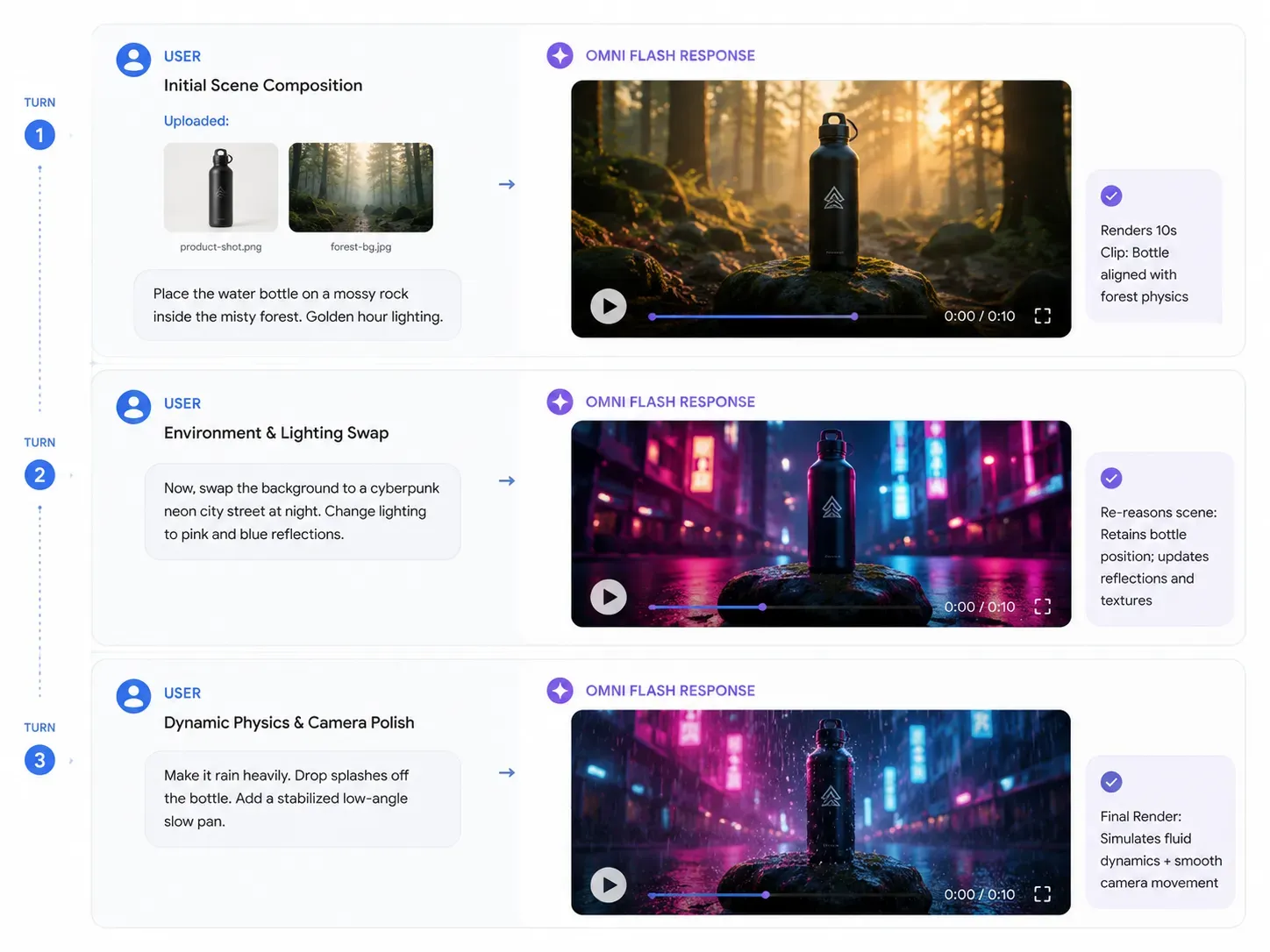
Gemini Omniのネイティブ・マルチモーダルを最大限に引き出すには、プロンプト戦略を「1回限りの生成」から「継続的な会話」へとシフトさせる必要があります。世界モデルの物理エンジンが環境のロジックを保持しているため、ステップバイステップで指示を重ねることができます。
以下は、一般的な商業クリエイター向けワークフローの完成された構成案です。
ターン1:初期の参照入力
入力アセット: brand-product-shot.png(金属製のウォーターボトル)と background-reference.jpg(霧深い森)。
プロンプト:「10秒間のシネマティックな商品紹介動画を生成して。製品写真の金属製ウォーターボトルを、霧深い森の中の苔むした岩の上に配置して。照明は早朝のゴールデンアワーに設定して。」
期待されるAI出力: Omniが両方の画像を同時に推論し、正確な物理ベースの重量感と初期の影の描写を伴って、岩の上にボトルをリアルに配置します。
ターン2:動的なアセット修正
入力コンテキスト: 同じセッション内の継続的なチャット(再アップロード不要)。
プロンプト:「背景を入れ替えて。霧深い森を、夜の洗練されたミニマルなサイバーパンク風のネオン街にして。照明を冷たい青と熱いピンクのネオン反射に変更し、ボトルの金属面にそれが当たるようにして。」
期待されるAI出力: 背景環境が即座に変更されます。重要なのは、岩の上のボトルの位置が維持される一方で、表面の反射が新しいネオン光源を反映して動的に変化することです。
ターン3:物理的な磨き上げ
| プロンプト操作 | 対象コマンド |
|---|---|
| 環境物理の追加 | 「シーン内で激しく雨が降り始めるようにして。雨粒がボトルの上部からリアルに跳ね返り、地面に波紋が広がるように。」 |
| カメラコントロールの適用 | 「カメラをローアングルから上にゆっくりパンし、自然言語で動画の手ブレ補正を適用してスムーズなトランジションにして。」 |
Google Flow内でのマルチターン・ループをマスターすることでプロンプトパイプラインは最適化されますが、マルチモデルワークフローを拡大する開発者は、より広範な柔軟性を必要とすることがあります。統合されたマルチモーダルAI APIを実装することで、Atlas Cloudのようなプラットフォームは、単一のオーケストレーション層の下で、高度な動画、画像、LLM推論エンジンを含む300以上のモデルを提供できます。
現実のシミュレーション:Gemini Omni世界モデル物理エンジンの力
会話型の編集は、モデルが「なぜそのシーンがそう見えるのか」を理解している場合にのみ優れた結果を生み出します。ここでGemini Omniの世界モデル(world model)物理レイヤーが極めて重要になります。
2026年のGoogle I/Oで、Google DeepMindのCEOであるDemis Hassabis氏は、Gemini Omniを単なる動画生成機ではなく、世界モデルであると説明しました。これは、現実を内部的に理解し、与えられたシーン内で次に何が起こるべきかを推論するシステムです。
「世界モデル」の実践的な意味

従来の動画AIツールの多くは、ピクセルを大規模にパターンマッチングすることで次のフレームを予測していました。それらは「現実に見える」映像は生成できても、「一貫した振る舞い」はできませんでした。キャラクターはカット間で変形し、影は光源を無視し、流体は物質ではなくテクスチャのように動いていました。
Gemini Omniは異なるトレーニングを受けています。Googleによれば、このモデルは物理、運動、空間認識AIに関する現実世界の理解を取り入れており、出力結果を現実世界の仕組みに基づいて接地させています。
Gemini Omniがシミュレートするように学習した物理プロパティ
DeepMindのゲーム世界シミュレーションプラットフォームであるGenieを基盤として、モデルは以下の物理特性を直感的に把握しているとGoogleは述べています。
| 物理プロパティ | 動画における実際の影響 |
|---|---|
| 重力 | 物体が正確な重さで落下し着地する |
| 運動エネルギー | 衝突間で勢いが保持される |
| 流体力学 | 水、煙、液体が自然に振る舞う |
| 照明の一貫性 | シーン編集時に影が正しく変化する |
| 空間的解剖学 | カット間でキャラクターの比率が維持される |
これが一貫した動画生成になぜ重要なのか
I/O 2026の基調講演では、このレイヤーを検証するために、タンパク質の折り畳みに関する非常に正確なクレイアニメーションが作成されました。これにより、モデルが単なるピクセルマッチングを超え、科学的・空間的な現実を理解していることが証明されました。
この世界モデルの基盤こそが、マルチターン編集全体で一貫した動画生成を可能にします。ユーザーが会話を通じて背景を変更したり照明を調整したりする際、モデルは単にレイヤーを合成するのではなく、被写体、新しい環境、光源の物理的な関係を再推論します。その結果、ピクセルをつなぎ合わせるのではなく、シーンレベルで物理的な現実をシミュレートできるのです。
パラダイムシフト:ピクセルマッチング vs 世界シミュレーション
| 従来の動画AIツール(旧時代) | Google Gemini Omni(世界モデル) |
| ❌ 中核ロジックを欠き、ピクセル群の統計的確率を予測するのみ。 | 🧠 物体の質量、運動量、流体エネルギーの保存を理解。 |
| ❌ カメラアングルが変わると影が歪み、テクスチャが破綻する。 | 🧠 グローバルイルミネーションをシミュレートし、光線や反射が自然に屈折する。 |
| ❌ 3〜5秒経過するとキャラクターの解剖学的構造や背景が崩れる。 | 🧠 マルチターン編集全体で一貫した環境、照明ロジック、アイデンティティを維持。 |
カスタム・デジタルアバター:Gemini Omniはクリエイター用のAIアバターを作成できるか?
前述の世界モデル物理は生成された映像をリアルに見せます。そしてアバター機能は、それを「あなた自身」に見せます。
Gemini OmniはAIアバターを作成できるか? はい。Gemini Omni Flashには専用のアバターツールが含まれており、クリエイターは自身の外見と声を使ったデジタルな分身を作成し、参照素材を毎回アップロードし直すことなく、生成された動画内に直接配置できます。
![]()
アバター登録(オンボーディング)の仕組み
不正利用を防ぐため、Googleはアバター作成前に構造化された検証ステップを追加しました。TechCrunchによると、ユーザーは録画を行い、一連の数字を読み上げるという専用の登録プロセスを完了する必要があります。登録された外見は保存され、将来のセッションで再利用されます。
既存のサードパーティ製クリップの完全な音声編集については、Googleが責任あるデプロイメントの準備を進めている間、審査が継続されます。すべてのカスタム・デジタルアバターと生成動画には、GoogleのSynthIDデジタル透かしが適用され、これはGeminiアプリ、Chrome上のGemini、Google検索を通じて検証可能です。
Gemini OmniはどのようにYouTube ShortsやGoogle Flowと統合されるか?
下表はプラットフォーム別の現在のアクセス状況を示しています。
| プラットフォーム | アクセスレベル | 備考 |
|---|---|---|
| Geminiアプリ | AI Plus, Pro, Ultraサブスクリプション登録者 | アバターを含むOmni Flashの全機能 |
| Google Flowプラットフォーム | AIサブスクリプション登録者 | Flowエージェント、バッチ編集、Flow Musicを含む |
| YouTube Shortsクリエイターツール | 無料、サブスクリプション不要 | 2026年Google I/O週から順次展開 |
| YouTube Createアプリ | 無料 | Shortsと同じスケジュールで展開 |
| Developer API | 数週間以内に公開 | エンタープライズおよびGoogle AI Studioアクセス |
Google FlowプラットフォームはOmni Flashと並行して機能追加が行われました。ブレインストーミングやバッチ生成用のFlowエージェント、共有可能なノーコードワークフロー用のカスタムツール機能、そしてミュージックビデオ制作やスタイル変換をサポートするFlow Music機能です。
コンテンツのセキュリティと出自:Google SynthID動画透かしがメディアを守る仕組み
強力なアバター作成ツールや動画編集ツールは、「誤解を招くコンテンツの作成に使われないか?」という当然の疑問を呼び起こします。Googleの答えは、Gemini Omniが生成するすべてのクリップに組み込まれた、不可避かつ不可視の透かし(ウォーターマーク)です。
Google SynthID動画透かしとは何か?
Google SynthID動画透かしは、目に見えるロゴや削除可能なメタデータタグではありません。生成の瞬間に動画のピクセルに直接埋め込まれる信号であり、人間の目には見えませんが、Googleの検出ツールで読み取り可能です。2026年のI/O基調講演によると、SynthIDはローンチ以来、すでに1000億件以上のAI生成画像や動画をマークしています。
重要なのは、表面的なマーカーを消去しうる一般的な後処理操作に対して、信号が耐性を持つよう設計されている点です。
- 圧縮と再エンコード
- リサイズとトリミング
- フォーマット変換
Gemini Omniに関して言えば、SynthIDはデフォルトでオンになっており、無効にすることはできません。
AIメディアの来歴(プロバナンス)検証の仕組み
AIメディアの来歴は、Geminiアプリ、Chrome上のGemini、Google検索という3つのGoogleプラットフォームで確認できます。ユーザーがクリップをアップロードすると、検出機能が透かし信号が検出された特定のタイムスタンプを強調表示します。これにより、単純な「はい/いいえ」ではなく、文脈に応じた検証結果を提供します。
ディープフェイク対策戦略としてのSynthID
| セキュリティレイヤー | 役割 |
|---|---|
| ピクセルレベルの透かし | 圧縮、トリミング、再エンコードに耐性を持つ |
| 不可避な埋め込み | ユーザーによるオフ設定不可 |
| クロスプラットフォーム対応 | OpenAIやElevenLabsがC2PA標準を採用 |
| アバター登録のゲート | 外見を保存する前に音声検証を要求 |
| 音声編集機能の制限 | 責任あるデプロイメントが整うまで完全な音声編集を保留 |
Sundar Pichai氏はI/O 2026でその背景を簡潔に説明しました。調査によると、質の高いディープフェイク動画を正しく識別できる人は全体の約4分の1に過ぎません。SynthIDは、制限された音声編集機能とともに、Gemini Omniの多層的なディープフェイク対策およびコンテンツセキュリティ機能を構成しています。
Gemini Omni Flash vs Pro:サブスクリプション料金、トークン価格、APIアクセス
機能セットが明確になったところで、次の実務的な疑問は「利用にはいくらかかるか?どのプランが自分のワークフローに合うか?」ということです。
今すぐGemini Omni Flashを利用するには?

Gemini Omni Flashは2026年5月19日より順次展開されています。利用方法は用途によって異なります。
| プラン | 月額料金 | クラウドストレージ | Geminiアプリとコア機能 |
|---|---|---|---|
| Google AI Plus | 7.99 USD / 月 | 200 GB | 利用制限:AIプランなしの場合の2倍。Flash Thinkingモデルへのアクセス |
| Google AI Pro | 19.99 USD / 月 | 5 TB | 利用制限:AIプランなしの場合の4倍。Proモデル、Deep Researchなどへのアクセス |
| Google AI Ultra | 99.99 USD / 月 | 20 TB | 利用制限:Proより5倍高い制限。Deep Thinkなどの最先端機能へのアクセス |
Google Flow内でのGemini Omniへのアクセスは、プランに応じたGoogle Flow Omniクレジットによって決まります。AI Plusのエントリーレベルから、AI Proの高度なマルチターン映画制作パイプライン、そしてAI Ultraの高上限スタジオコンピュート境界へとスケールします。
標準的なアプリケーション開発については、GoogleのVertex AIのトークン課金モデルが予測可能性を維持します。しかし、厳格なAPIレート制限に抵触するプロダクションレベルのレンダリングパイプラインにおいては、オンデマンドGPU価格モデルに切り替えることで、最低契約期間なしで生ハードウェアの制御を可能にする、より費用対効果の高いプランを選択できます。
Gemini Omni Flash vs Pro:何が違うのか?
Gemini Omni Flash vs Proの比較において、一方(Flash)は確認済みであり、もう一方(Pro)はまだ利用できません。Flashは10秒のクリップを生成します。これはモデルの制限ではなく、ローンチ時の計算需要を管理するための意図的な制限であると、Google DeepMindのNicole Brichtova氏は述べています。
Omni Proは発表済みですが、リリース日は未定です。チームが「Flashを超える段階的な変化」を確認した時点でリリースされる予定です。それまでは、Flashが唯一公開されているOmniモデルです。
Gemini Omni vs Google Veo:何が変わったか?
Gemini Omni vs Google Veoはバージョンアップではなく、アーキテクチャの転換です。Veo 3.1は現在もライブ稼働しており、テキスト・トゥ・ビデオ生成用のGA APIアクセスも継続しています。Omniはそこに「推論レイヤー」を追加し、4種類の入力を同時に受け入れ、マルチターン会話型編集を導入しました。これらはVeoではサポートされていない機能です。
プロダクション動画生成のための単一統合API
GoogleがGeminiアプリやGoogle Flow内でGemini Omni Flashを展開する一方で、同じマルチモーダル動画エンジンを自社のワークフローに組み込みたい開発者やプロダクトチームには、安定的で予測可能なAPI層が必要です。
Atlas Cloudは、OpenAI互換APIを通じてGemini Omni Flashを提供しています。300以上の他の画像・動画・LLMモデルと併せて利用できるため、ベンダーご






