
MiniMax just teased a 15.6× decode speedup at 1M tokens. If that number holds, the cost of running million-token context drops by close to an order of magnitude — and the generation gets faster, not slower, while doing it.
For anyone building on these models, that resets what's affordable. Workloads that don't pencil out today start to: handing a coding agent your entire codebase instead of fragments, multi-hour agent runs that pile up enormous histories, retrieval over whole document sets rather than chopped-up snippets. The question every team fights — how much can I stuff in the context window before the bill or the latency kills the product? — gets a much higher ceiling.
The mechanism is sparse attention, and MiniMax isn't alone. DeepSeek shipped it across three model lines, Qwen has its own version, and now MiniMax. The direction is settled. What's changing is the consequence: when every frontier model can run long context cheaply, the model stops being the moat — and that is the part worth your attention, which we'll come back to at the end.
Two honest caveats first, because they matter to anyone who'd actually deploy this:
- These are MiniMax's own figures, from a single teaser diagram of an unreleased model, on their setup. A strong signal of direction — not a third-party benchmark. Treat them as "what MiniMax claims," and re-test on your own workload when the weights land.
- M3 isn't public yet. We expect to bring it to Atlas Cloud with day-zero access when it opens — more at the end.
So how is MiniMax pulling this off? On May 26, MiniMax R&D lead Skyler Miao posted one diagram on X — restrained palette, a lot packed in — titled MiniMax Sparse Attention, with two curves carrying the numbers everyone latched onto: 9.7× faster prefill, 15.6× faster decode at 1M tokens. The community read it near-unanimously as the M3 teaser. We took it apart to understand the architecture behind those numbers.
A bit of grounding before the teardown. Three terms carry the whole story:
- Prefill is the pass where a model reads your input in one shot.
- Decode is the slower, token-by-token phase where it writes the output — and at long context, decode is the one that hurts, because every new token looks back over everything before it.
- Sparse attention is the fix: instead of having every token attend to every other token (the default, whose cost grows with the square of the sequence length), the model attends to a carefully chosen subset — keeping most of the quality for a fraction of the compute. How you choose that subset is where every lab differs.
And the reason this teaser carries weight: back in October, MiniMax published a post titled Why Did M2 End Up as a Full Attention Model? — unusually direct, explaining that M2 skipped M1's efficient "Lightning Attention" because efficient attention wasn't production-ready yet. Six months later, M3 surfaces with sparse attention front and center. The subtext is one sentence: this time it is.
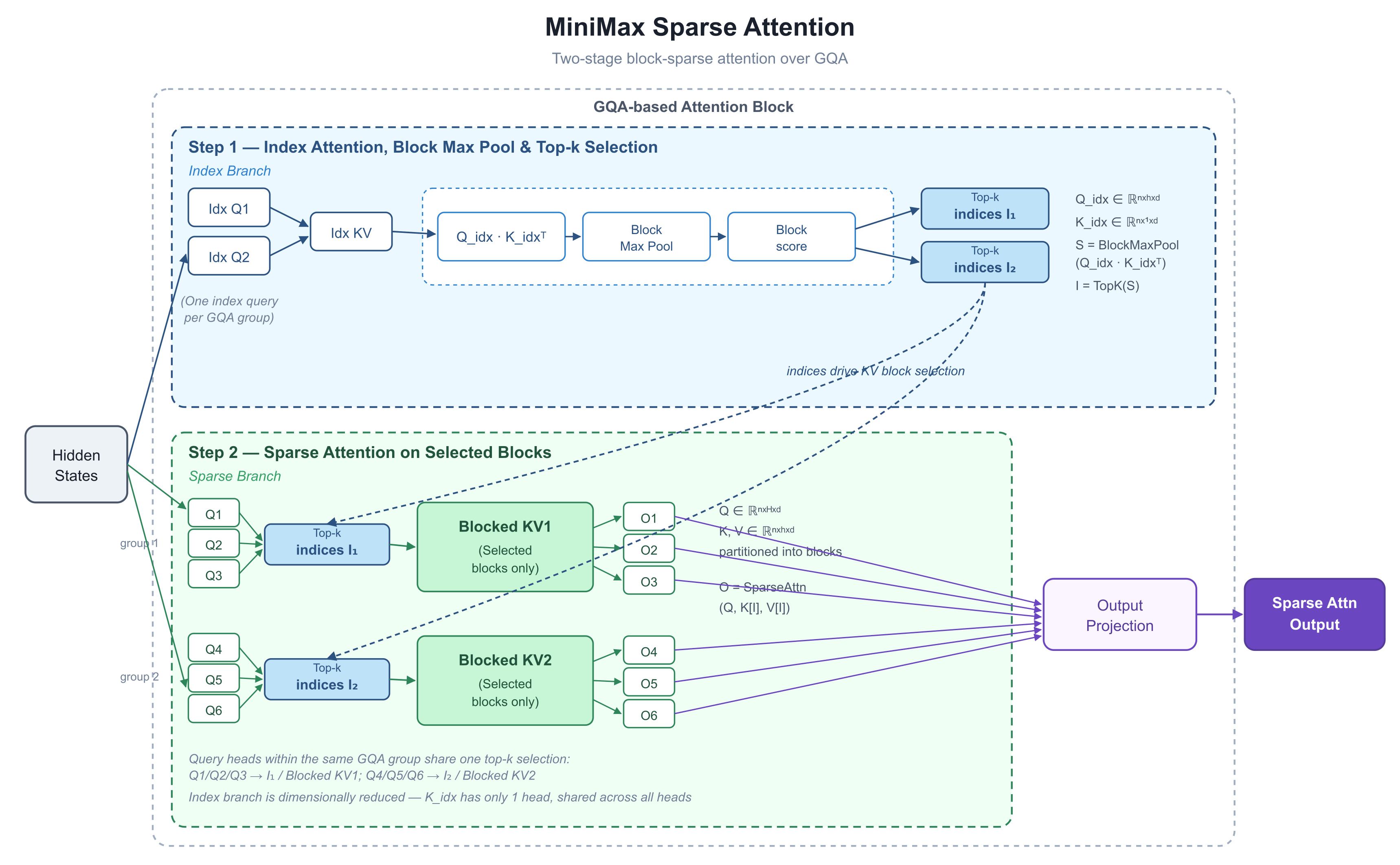
1. What the diagram shows: two stages — pick before you compute
The diagram is the internal unfolding of a single attention block. Its key move is to split "which tokens to look at" from "how to compute attention over them" into two clearly separated steps.
A note on the substrate, since it recurs throughout: M3 is built on GQA — Grouped-Query Attention. In a standard attention layer, every "query head" carries its own set of keys and values, which is expressive but bloats the KV cache (the key/value cache — the stored keys and values from all prior tokens, kept around so they don't have to be recomputed every step). GQA splits query heads into groups, and each group shares one set of keys and values. It's the mainstream memory-saving layout used across most production models today. Hold onto that — it's the foundation of the whole design.
Step 1: Index Branch — score everything cheaply
The top half is the index branch. It runs off to the side of the main path with one job: tell the rest of the block which blocks of tokens are worth looking at.
Each GQA group shares one index query (the diagram shows six real heads paired with two index queries, "Idx Q" — one per group). The key side of this branch is deliberately stripped down:

Note that K_idx has only one head — every head shares the same index key. That makes the scoring step (Q_idx · K_idxᵀ) cost almost nothing.
Block Max Pool then compresses those token-level scores into block-level scores (it slices the sequence into fixed-size blocks and keeps the top score in each):

Finally, TopK — "keep the k highest-scoring items" — decides which KV blocks survive for this layer and this group. The output is a short list of indices: I₁, I₂.
Step 2: Sparse Branch — where attention actually runs
The bottom half is the real computation. The queries, keys, and values are still in standard GQA form. Using I₁ and I₂ from Step 1, the block pulls only the selected subsets out of the full keys and values, and runs attention over just those:

The most important design choice: every query head in a group shares a single top-k selection. In the diagram, Q1/Q2/Q3 all use I₁; Q4/Q5/Q6 all use I₂. This is the hardware-alignment principle DeepSeek's NSA paper hammers on — one group of queries loads one set of KV blocks, that set fits into SRAM (the GPU's small, extremely fast on-chip memory) in a single pass, and standard FlashAttention-style kernels (the dominant optimized attention implementation) can be reused unchanged.
-
Three deliberate subtractions relative to the DeepSeek family
The community immediately lined this up against DeepSeek's three sparse-attention designs:
- NSA — Native Sparse Attention. "Native" means the sparsity is trained in from the start of pretraining, not bolted on after. Three parallel branches (compress + select + sliding window) plus a learned gate.
- DSA — DeepSeek Sparse Attention. The variant shipped in DeepSeek V3.2; token-level selection with a very light indexer.
- CSA — community shorthand for the block-level direction associated with DeepSeek V4. (This label is less standardized than NSA/DSA, so treat it as a working name rather than an official term.)
The one-line community read: M3 uses GQA rather than MLA, block-level selection in the spirit of CSA, but it computes attention on the real keys and values.
Expanded into a table:
| Dimension | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (inferred) |
|---|---|---|---|---|
| KV substrate | MLA (latent) | GQA | MLA | GQA |
| Selection granularity | token-level | block-level | block-level | block-level |
| Parallel branches | 1 (indexer + select) | 3 (compress + select + sliding) | 1 | 1 (select only) |
| Where attention runs | real K/V | three-way fusion | compressed KV | real K/V |
| Indexer cost | Lightning indexer | compression branch | block summaries | single-head K + Block Max Pool |
| Gating | none | learned gate | none | none |
That table hides one more acronym worth defining: MLA — Multi-head Latent Attention, DeepSeek's signature trick. Instead of caching full keys and values, MLA compresses them into a small shared "latent" vector, caches that, and decompresses on the fly. The KV cache shrinks dramatically — but the math no longer matches standard attention, so it needs custom kernels. That contrast drives the first of M3's three trade-offs.
First subtraction: GQA as the substrate, not MLA. Because M3 stays on plain GQA, the standard serving stack — vLLM and SGLang (the two widely used open-source inference servers) plus FlashAttention — works with little to no modification. None of the engineering required to work around MLA's latent KV. For a lab targeting "production-ready," it's the lowest-risk path. This is the most business-legible idea in the whole design: MiniMax optimized for what runs immediately on the hardware and software everyone already has.
Second subtraction: block-level selection, but attention runs on the real keys and values. Unlike CSA, which computes attention over compressed KV, M3 keeps the full expressive power of standard softmax attention. The cost: the KV cache doesn't shrink along with the sparsification — but trading some memory for preserved quality is a sensible bargain.
Third subtraction: NSA's other two branches are gone. NSA runs three parallel paths (compress + select + sliding window) plus a learned gate. M3 keeps only selection. One community summary called it streamlined, simplified NSA. In a phrase: engineering first. Of the two cut branches, the sliding window is most likely replaced by RoPE (Rotary Position Embedding — the standard way models encode token position) plus an attention sink, or simply by dense attention as a per-layer fallback, the way Gemma 3 and Qwen3-Next do. The compression branch is absorbed into that minimal "single-head K + Block Max Pool."
3. How to read the numbers
| Stage | Speedup @ 1M | What it means |
|---|---|---|
| Prefill | 9.7× | Process 1M tokens of input in one pass |
| Decode | 15.6× | Generate token by token |
Decode outrunning prefill makes sense. During prefill, the index branch still has to scan the full input length, so the saving lands only on the main attention. During decode, each new token interacts only with its selected KV blocks, and the memory-bandwidth pressure on the KV cache drops by roughly an order of magnitude — which is exactly where decode-time cost lives.
Backing out the selection ratio: assume a block size of 64 tokens, so 1M tokens is ~16,000 blocks. A 15.6× decode speedup implies each query actually touches only about 6–7% of the blocks — an effective receptive field around 60k–70k tokens. That ratio sits almost exactly on the sparsity rate the NSA paper reports (6–10%). Not a coincidence — it's the sweet spot for this kind of design at the 1M scale.
4. Inferring the rest of M3
Extrapolating from this one attention block to the full model — clearly labeled as inference, since a diagram only shows so much:
- The MoE backbone likely stays. MoE — Mixture of Experts — is the model's backbone (separate from attention): instead of routing every token through one giant network, a router sends each token to a few specialized "expert" sub-networks, so you get a large model's quality at a small model's active compute. M2 shipped as 230B total parameters / ~10B active / Top-2 routing; M2.7 already pushed expert count to 256. No reason for M3 to abandon this — the likely change is deeper and wider.
- The full-attention stack gets replaced with block-sparse GQA. M1's Lightning Attention is unlikely to return. M3 isn't re-betting on linear attention; it's taking the "softmax expressiveness + top-k block selection" route — sub-quadratic cost while preserving quality.
- Most likely natively trained sparsity. This is the central lesson of the NSA paper: the sparse pattern has to enter the gradients during pretraining, or the model's retrieval behavior gets scrambled. MiniMax has its own research line on retrieval heads, so they shouldn't fall into that trap.
- The battleground is 1M+ context. M1 was trained at 1M and extrapolated to 4M at inference. M3 looks set to lock that in while slashing inference cost — a very natural product cadence.
5. Placing M3 in the 2026 design space
Across 2025–2026, sparse-attention designs have diverged quickly:
- DeepSeek V3.2 DSA: MLA + token-level top-k, very light indexer; most stable quality, but heavy kernel engineering.
- DeepSeek NSA: GQA, three branches + gate; highest quality ceiling, most complex to implement.
- Qwen3-Next: layer-wise mix of dense and linear attention; robust but relatively conservative.
- MiniMax M3: GQA + single-branch block selection; minimal, riding the hardware tailwind.
The subtext of M3's design is unambiguous: don't chase the theoretically optimal attention — chase the one that runs immediately, runs fast, and lets existing kernels be reused. It's of a piece with the decision to fall back to full attention in M2: stabilize quality with mainstream methods first, then replace cleanly once the technology is genuinely mature.
6.What this means if you're building the next wave of AI apps
Step back from the architecture and there's a bigger pattern. Every serious lab is now shipping a version of trained-in sparse attention — DeepSeek across three lines, Qwen with its layer-wise mix, now MiniMax. The direction is settled, and the consequence is straightforward: when every frontier model can run long context cheaply, the model itself stops being the moat. Raw inference cost compresses toward commodity. Differentiation moves up a layer — to which model you run for which workload, how you route between them, and how fast you adopt the next one when it lands six weeks later.
That's a harder problem than "find the cheapest endpoint." A team running a production app is balancing four things at once — quality, latency, cost, and the business outcome the feature actually drives — and the right answer differs per workload and shifts every release cycle. M2 was full-attention in October; M3 is block-sparse by May. Whatever you wired to last quarter is already a step behind.
Picking the cheapest model is no longer a winning strategy for builders. Instead, it'll be builders who built on a layer that lets them choose, route, and swap models without re-integrating every time the frontier moves — and who spend their engineering budget on their own product instead of chasing release notes every few weeks.
That's the layer Atlas Cloud operates at: one API across 300+ models spanning LLM, video, image, and audio, with intelligent routing and day-zero access to new launches. The same lens we used to take apart this diagram is the one we use to decide what to onboard and how to route it. M3 isn't public yet — when it opens, we expect to bring it to Atlas with day-zero access, so the teams already building on us can put it in front of their own users the day it ships, not the quarter after.
Closing thoughts
Plenty can't be confirmed from a single diagram: whether the sparse pattern is mixed layer by layer, whether there's a dense fallback, whether the index branch shares embeddings with the main network, whether training-time top-k is hard or soft, how the index branch's loss is formulated. All of that waits for the official paper or the weights.
But one thing is already settled: following DeepSeek, another major lab has assembled sparse attention + long context + open weights into a working stack. In the second half of 2026, 1M context in open source is likely to shift from a selling point to a baseline — and that, on its own, matters more than any single benchmark.
References
- Skyler Miao (MiniMax R&D lead), original post on X: Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- Community roundup: MiniMax details its M3 sparse attention architecture — https://digg.com/ai/78gnmbpg
- MiniMax blog: Why Did M2 End Up as a Full Attention Model? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- DeepSeek NSA paper: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- DeepSeek V3.2 DSA write-up: Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka: A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- MiniMax-01 tech report: Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






