DeepSeek v4: Tudo o que sabemos até agora – Recursos, Data de Lançamento e Como Acessar no Atlas Cloud
Introdução: O que é o DeepSeek v4?
O Atlas Cloud está expandindo seu arsenal de IA generativa com a chegada do DeepSeek v4.
- O que é: O mais recente modelo carro-chefe da equipe do DeepSeek. Se o DeepSeek v3.2 estabelece o padrão para modelos de codificação open-source de excelente custo-benefício, o v4 amplia os limites da lógica e da memória utilizando tecnologias proprietárias de Manifold-Constrained Hyper-Connections (mHC) e Engram Memory.
- Principal Benefício: Além de apenas gerar trechos de código, o v4 atua como um arquiteto sênior, compreendendo estruturas completas de repositórios para raciocínio entre arquivos e correção de bugs complexos.
- Status: Lançamento próximo (Esperado para meados de fevereiro de 2026 — leia nossa análise detalhada sobre o que esperar do DeepSeek V4).
Por que estamos confiantes de que o DeepSeek v4 é o próximo divisor de águas? Porque ele resolve o maior problema da indústria: a IA precisa lembrar e compreender a lógica de um projeto.
📣 Atualização — 24 de abril de 2026: O DeepSeek-V4 foi lançado oficialmente. Leia nossa cobertura completa sobre o que foi disponibilizado, incluindo a nova arquitetura de atenção esparsa, contexto de 1M de tokens e resultados de benchmarks de agentes — em Lançamento do Preview do DeepSeek-V4.
Análise Técnica Profunda: Principais recursos
Para desafiar o Claude Opus 4.5, o DeepSeek reconstruiu o modelo do zero. Documentos vazados indicam uma mudança fundamental na forma como o modelo lida com memória e estabilidade lógica. Vamos detalhar os quatro pilares desta atualização.
Arquitetura: Raciocínio Lógico Superior
-
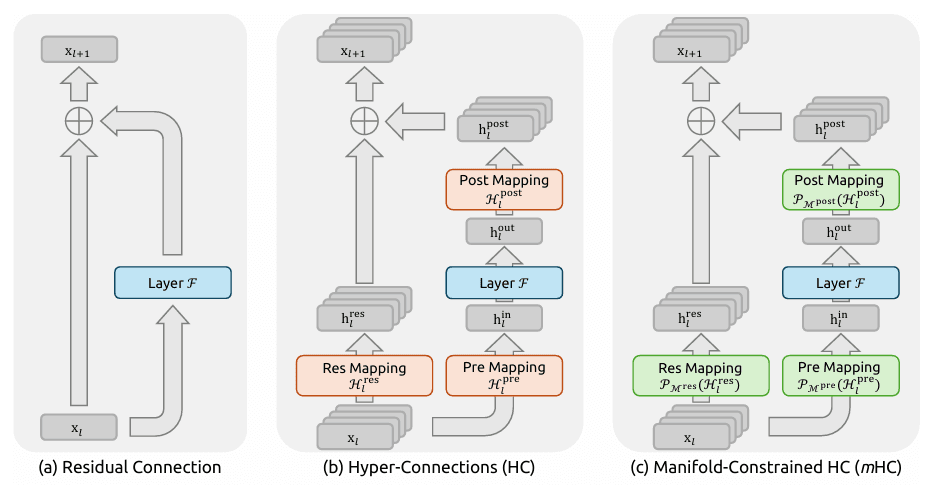
Manifold-Constrained Hyper-Connections (mHC)
- O Conceito: O DeepSeek v4 inventa um novo método de "conexão neural". As conexões tradicionais geralmente perdem informações em redes profundas, mas o mHC atua como uma "superestrada lógica" para o cérebro da IA.
- O Resultado: Ao lidar com lógica massiva e complexa (como refatorar milhares de linhas de código), o modelo aprende mais rápido e retém melhor a lógica. Isso elimina as "alucinações lógicas" e inconsistências comuns na geração de contextos longos.
Eficiência: Menores Custos de Inferência
-
Mixture-of-Experts (MoE) 2.0
- O Conceito: Embora o v4 seja um gigante em parâmetros (centenas de bilhões), ele utiliza uma arquitetura MoE otimizada para ativar apenas os "especialistas" mais relevantes para cada token.
- O Resultado: Ele atinge um equilíbrio perfeito entre Alta Capacidade (base de conhecimento massiva) e Escalabilidade Eficiente (execução leve como a de um modelo menor).
-
Atenção Esparsa (Sparse Attention)
- O Conceito: Abandonando o método de força bruta de escanear todo o texto, o modelo agora foca de forma inteligente apenas nas informações chave. Isso reduz drasticamente os custos computacionais e acelera o processamento de contextos longos.
Memória: Gestão Inteligente de Contexto
-
Engram Memory (Armazenamento e Recuperação Seletiva)
- O Conceito: A IA para de memorizar por repetição e começa a "compreender". Ela reconhece estruturas de projetos, segue convenções de nomenclatura (snake_case vs. camelCase) e identifica padrões de codificação (imitando os padrões de fábrica específicos da sua equipe).
- O Resultado: Ela codifica como um funcionário sênior.
-
Multi-Head Latent Attention (MLA)
- O Conceito: Pense nisso como uma "super taquigrafia". Onde outros modelos precisam de 100 tokens para armazenar informações, o MLA comprime isso em 10 símbolos-chave.
- O Resultado: Quando a recuperação é necessária, o modelo reconstrói matematicamente o significado original sem perdas. Isso mantém uma retenção de detalhes incrível com um uso de VRAM significativamente menor.
Aplicação: Engenharia do Mundo Real
- Compreensão em Nível de Repositório & Correção de Bugs
- O objetivo não é apenas escrever uma função, mas controlar a base de código. Em testes no SWE-bench, o DeepSeek v4 visa resolver mais de 80,9% dos problemas complexos do mundo real ao compreender dependências entre arquivos.
Casos de Uso: Reduzindo Custos e Aumentando a Eficiência
O DeepSeek v4 foi criado para engenharia pesada. Veja como ele se compara à concorrência:
Refatoração de Código Legado
Para sistemas legados caóticos e sem documentação, a arquitetura mHC é uma salvação. Ela rastreia dependências lógicas de longa distância para uma refatoração segura.
- VS GPT-4o: O GPT-4o frequentemente sofre de "alucinações lógicas" (inventando chamadas de função inexistentes) quando o contexto excede 10 mil tokens. O DeepSeek v4 mantém 100% de consistência lógica em contextos longos.
- VS Claude 3.5 Sonnet: Embora o Sonnet seja de alta qualidade, ele é lento e caro para tarefas massivas de refatoração. A arquitetura MoE do DeepSeek v4 oferece velocidades de inferência ~40% mais rápidas a um custo menor no Atlas Cloud.
Desenvolvimento de Funcionalidades em Nível de Repositório
Ao adicionar uma nova API a um projeto maduro, o v4 usa a "Engram Memory" para entender o contexto instantaneamente.
- VS Autocomplete Tradicional: Ferramentas padrão frequentemente ignoram normas específicas do projeto, introduzindo inconsistências de estilo. O DeepSeek v4 imita sua base de código existente tão bem que parece um "copiar e colar" do seu melhor desenvolvedor.
Rastreamento de Bugs de Ponta a Ponta
Visar uma taxa de sucesso de 80,9% no SWE-bench significa lidar com bugs que abrangem frontend, backend e bancos de dados.
- VS Claude Opus 4.5 (Esperado): O Opus 4.5 provavelmente será poderoso, mas com um preço premium. O DeepSeek v4 oferece um desempenho próximo ao estado da arte a um preço que permite loops de "reflexão e correção" sem comprometer o orçamento.
📉 O Veredito: ROI para Equipes
Para startups e equipes de desenvolvimento, a combinação de DeepSeek v4 + Atlas Cloud entrega um ROI tangível:
- Produtividade: Reduza o tempo de codificação para desenvolvedores sêniores em 30-50%.
- Custo: Comparado ao aluguel de servidores com dual RTX 4090 ou ao pagamento de APIs de código fechado, a API integrada do Atlas Cloud pode economizar para as equipes mais de 60% em custos computacionais abrangentes.
A Linha Vermelha do Hardware: Hospedar Localmente? Pense Duas Vezes.
A esta altura, você pode estar tentado a executar este "Deus da Codificação" em sua máquina local. Mas precisamos lhe dar um choque de realidade: desempenho tem um preço.
- Entrada Mínima: Dual RTX 4090s
- Tradução: Você está comprando duas das GPUs de consumo mais caras do mercado e interconectando-as. O custo apenas das GPUs é aproximadamente equivalente a 3x iPhone 17 Pro Max (ou um carro usado decente).
- Recomendado: Uma única RTX 5090 (Flagship de 2026)
- Tradução: Esta é a "Ferrari" das GPUs. O preço será altíssimo devido a revendedores e a disponibilidade será escassa.
Com os preços das GPUs permanecendo altos, pergunte a si mesmo: vale a pena gastar milhares de dólares e lidar com ruído de ventoinhas, calor e configuração de ambiente apenas para rodar um modelo?
A Solução Inteligente: Acesso no Dia 0 pelo Atlas Cloud
Você não precisa ser rico para usar o DeepSeek v4; você só precisa ser inteligente. Em vez de comprar "tijolos eletrônicos" que se desvalorizam, escolha a nuvem.
O Atlas Cloud está pronto para o lançamento:
-
Nossa Promessa: Aproveite suas férias. Deixe o trabalho sujo de implementação conosco. Estamos monitorando os canais oficiais de lançamento 24/7.
-
Vantagens Principais:
- Acesso Instantâneo: Assim que os pesos open-source forem liberados, nossa integração de API entra no ar.
- Barreira Zero: Sem hardware caro, sem o inferno de dependências do CUDA. Apenas traga seu prompt.
- Experiência Sem Compromissos: Oferecemos suporte total a contexto, garantindo que o mecanismo de memória "Engram" funcione com 100% de capacidade sem perda por quantização.
Como usar no Atlas Cloud
O Atlas Cloud permite que você use modelos lado a lado — primeiro em um playground e, depois, via uma única API.
Método 1: Usar diretamente no playground do Atlas Cloud
Método 2: Acessar via API
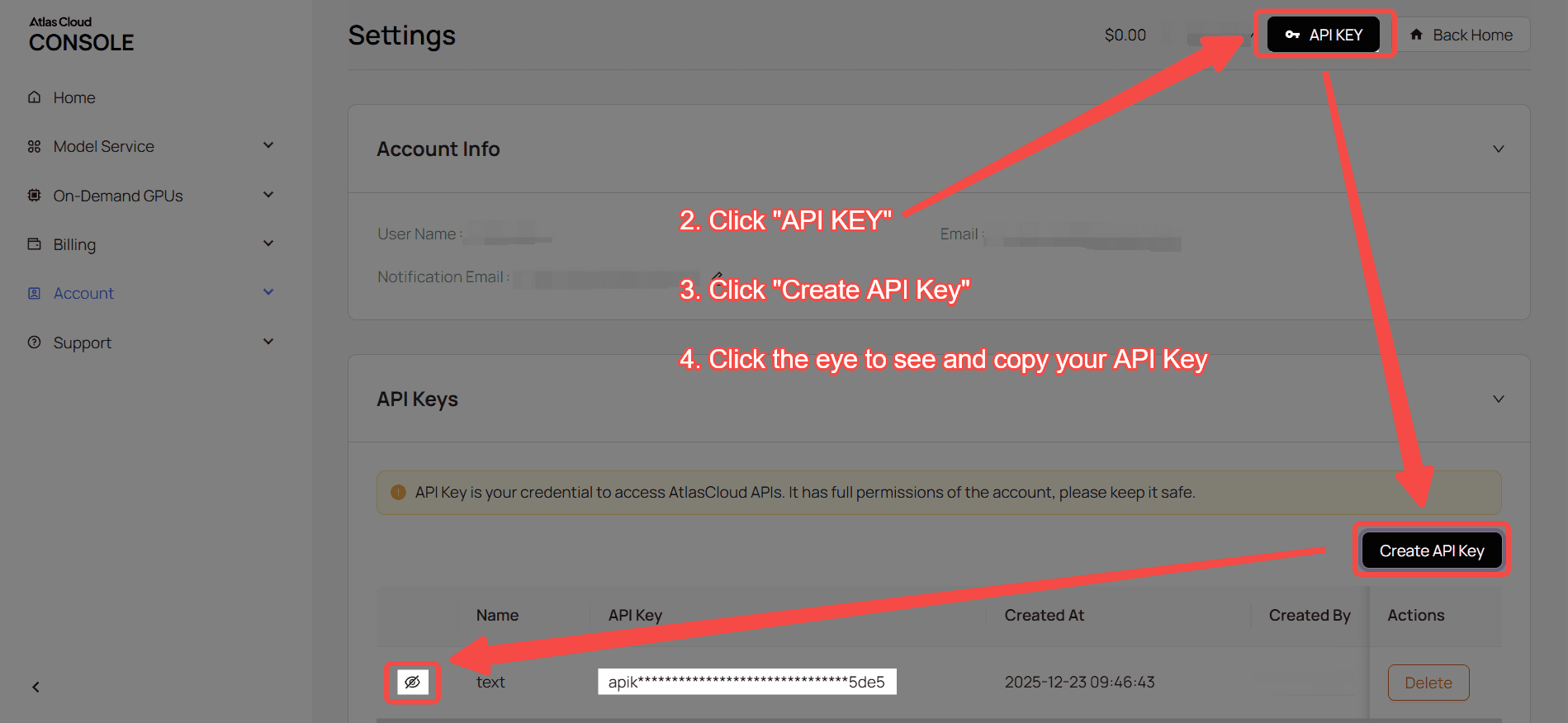
Passo 1: Obtenha sua chave de API
Crie uma chave de API em seu console e copie-a para uso posterior.
Passo 2: Verifique a documentação da API
Revise o endpoint, parâmetros de solicitação e método de autenticação em nossa documentação da API.
Passo 3: Faça sua primeira solicitação (Exemplo em Python)
Exemplo: gerar uma resposta com o DeepSeek v3.2:
python1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "qual a diferença entre http e https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






