O seu prompt atingiu um bloqueio. Não por ser prejudicial, mas porque uma palavra-chave acionou um filtro.
Desenvolvedores na comunidade Ollama descrevem isso como "vetores de recusa": bloqueios acionados por palavras-chave que não têm relação com danos reais. Engenharia reversa de malware para pesquisa de segurança, documentação de estudos de caso médicos, criação de conteúdo adulto, escrita de ficção sombria. As IAs convencionais bloqueiam tudo isso. Esta lista classifica os melhores modelos de IA sem censura em 2026 com base em dados reais da comunidade, e não em textos de marketing. Ela abrange três categorias: modelos LLM sem censura para texto e código, os melhores modelos locais de IA sem censura de 2026 para implementação em hardware privado, e modelos de IA sem censura de 2026 para geração de imagem e vídeo via API. Todos os números foram obtidos de fontes com data de maio de 2026.
Para uma introdução ao panorama geral de ferramentas, leitores iniciantes nesta área encontrarão o guia de geradores de imagem de IA sem censura como um ponto de partida útil antes de selecionar um modelo específico.
Como classificamos os melhores modelos de IA sem censura de 2026
Em 2026, as contagens de download da comunidade no Ollama fornecem um sinal de classificação mais confiável do que pontuações de benchmark, que podem ser selecionadas para comunicados de imprensa em vez de desempenho real (Ollama, pesquisa de modelos sem censura, 2026). Milhões de pulls representam milhares de configurações de hardware e tipos de prompt. Isso é mais difícil de manipular do que um conjunto de avaliação curado.
Três sinais de classificação são usados ao longo deste artigo. Para modelos Ollama sem censura, o sinal principal é a contagem de pulls de ollama.com, obtida em maio de 2026. Para modelos no OpenRouter, a classificação é baseada na contagem de parâmetros e na janela de contexto, já que as contagens de pulls não estão disponíveis publicamente nessa plataforma. Para modelos de imagem e vídeo, a classificação é baseada no preço por saída, com os custos mais baixos listados primeiro em cada grupo.
A maioria dos modelos de IA sem censura de 2026 se encaixa em duas categorias técnicas: ajustados (fine-tuned) e abliterados. Modelos ajustados como a série Dolphin são treinados em conjuntos de dados que não reforçam comportamentos de recusa. Modelos abliterados tiveram seus pesos de recusa removidos cirurgicamente. A comunidade considera consistentemente que modelos ajustados são mais estáveis em diversos tipos de prompt.
Na prática, as contagens de download também se correlacionam com a estabilidade do modelo. Um modelo que atinge mais de 1 milhão de pulls foi testado em uma ampla gama de configurações de hardware, revelando bugs e instabilidades que grupos de teste menores ignoram totalmente.
Quais são os 5 modelos Ollama sem censura mais baixados?
Em 2026, os cinco modelos Ollama sem censura mais baixados totalizam mais de 9,2 milhões de pulls, com o llama2-uncensored liderando com 2,6 milhões (Ollama, pesquisa de modelos sem censura, 2026). Estes são os melhores modelos Ollama sem censura de 2026 por validação da comunidade, não por qualquer benchmark. O hardware é o filtro primário que a maioria dos usuários aplica primeiro: os requisitos de VRAM variam de menos de 4 GB a 40 GB neste grupo.
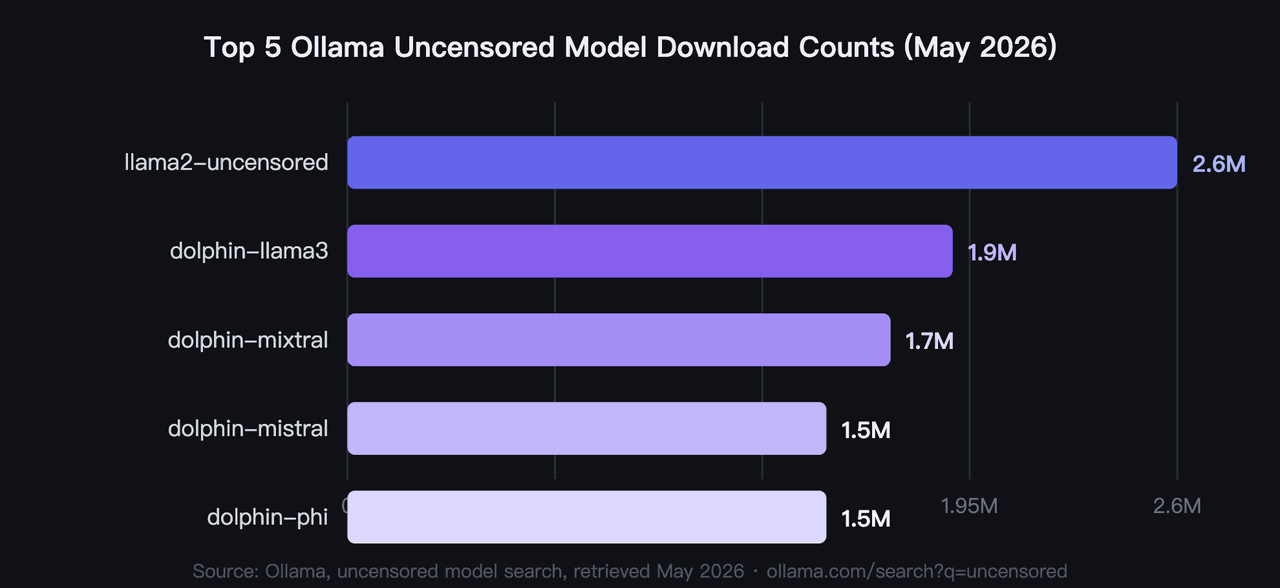
1. llama2-uncensored: Modelo de IA sem censura mais baixado no Ollama
O benchmark comunitário original para IA local sem censura. George Sung e Jarrad Hope lançaram este ajuste para remover o comportamento de recusa do Llama 2 sem degradar a capacidade geral. É o modelo com o qual a maioria dos desenvolvedores começa, e sua contagem de 2,6 milhões de pulls reflete mais de dois anos de uso no mundo real. Nenhum outro LLM sem censura igualou esse volume de downloads.
- Parâmetros: 7B ou 70B
- VRAM: ~6 GB (7B); ~40 GB (70B)
- Ideal para: Chat irrestrito de uso geral e geração de conteúdo
- Plataforma: Ollama
2. dolphin-llama3: Melhor modelo LLM Llama 3 sem censura para fluxos de trabalho agenticos
O Dolphin de Eric Hartford na base Llama 3 é o modelo sem censura mais baixado construído sobre uma arquitetura moderna, com 1,9 milhão de pulls (Ollama, página do modelo dolphin-llama3, 2026). Ele suporta chamada de função (function calling) e uma janela de contexto que se estende de 8K a 256K tokens, dependendo da configuração. A versão 8B pesa 4,7 GB, cabendo na maioria das GPUs de consumo intermediárias.
- Parâmetros: 8B ou 70B
- VRAM: ~5 GB (8B); ~40 GB (70B)
- Ideal para: Programação, fluxos de trabalho agenticos e chamadas de função
- Plataforma: Ollama
3. dolphin-mixtral 8x7B: Modelo de IA MoE sem censura para raciocínio complexo
Uma arquitetura de mistura de especialistas (MoE) roteia cada token através de um subconjunto de suas 8 camadas de especialistas. Isso produz uma qualidade de raciocínio próxima a 70B com menor custo de inferência do que um modelo denso com contagem total de parâmetros equivalente. O ajuste sem censura de Eric Hartford mantém uma forte ênfase em programação.
- Parâmetros: 8x7B (os parâmetros ativos por passe de inferência são muito menores que o total)
- VRAM: ~12-16 GB com quantização
- Ideal para: Tarefas complexas de programação, raciocínio técnico e cadeias de instruções longas
- Plataforma: Ollama
4. dolphin-mistral: Modelo de IA local sem censura 7B para respostas rápidas
Mais leve e mais rápido que o dolphin-mixtral em hardware com limitação de CPU. Ele acumula 1,5 milhão de pulls de desenvolvedores que desejam um modelo local responsivo para completação de código sem a necessidade de uma GPU de alto nível. A arquitetura base Mistral oferece uma forte relação desempenho-tamanho para um modelo 7B.
- Parâmetros: 7B
- VRAM: ~5-6 GB
- Ideal para: Assistência leve de programação e respostas rápidas de chat
- Plataforma: Ollama
5. dolphin-phi 2.7B: Modelo de IA local sem censura mais leve
A arquitetura base Phi da Microsoft compacta um raciocínio capaz em uma contagem de 2,7 bilhões de parâmetros. O ajuste sem censura de Eric Hartford preserva essa eficiência. Com menos de 4 GB de VRAM, ele roda na maioria dos laptops de consumo com GPU dedicada, tornando-o o ponto de entrada acessível para os melhores modelos locais de IA sem censura de 2026.
- Parâmetros: 2.7B
- VRAM: Abaixo de 4 GB
- Ideal para: Implementação em laptop, testes rápidos e ambientes com restrição de hardware
- Plataforma: Ollama
Melhores modelos LLM sem censura de 6 a 10: Programação, Roleplay e contexto longo
Em 2026, a série Dolphin ocupa 5 das 10 primeiras posições no catálogo sem censura do Ollama por contagem de downloads, uma concentração que reflete a metodologia de ajuste consistente de Eric Hartford aplicada em diferentes arquiteturas base (Ollama, página do modelo hermes3, 2026). Os modelos de 6 a 10 cobrem roleplay, conversação geral, ferramentas de desenvolvedor, seguimento de instruções e contexto estendido: os casos de uso onde as recusas das IAs convencionais são mais prejudiciais.
6. hermes3: Modelo de IA sem censura para roleplay e tarefas agenticas
A Nous Research construiu o hermes3 para profundidade de roleplay e uso estruturado de ferramentas. Ele está disponível em quatro tamanhos, de 3B a 405B, a maior variedade de tamanhos de qualquer modelo nesta lista. Com 1,3 milhão de pulls, a variante 8B ocupa um lugar prático para escrita criativa e fluxos de trabalho de planejamento agentico (Ollama, página do modelo hermes3, 2026).
- Parâmetros: 3B, 8B, 70B ou 405B
- VRAM: ~2 GB (3B); ~5 GB (8B); ~40 GB (70B)
- Ideal para: Roleplay, ficção criativa e planejamento de tarefas agenticas
- Plataforma: Ollama
7. wizard-vicuna-uncensored: Modelo de IA sem censura multitarefa para uso geral
Um modelo mais antigo, porém comprovado, construído sobre o Llama 2, disponível em três tamanhos até 30B. Seus 1,2 milhão de pulls vêm de usuários que desejam uma opção sem censura confiável com uma faixa maior de parâmetros. Ele não iguala as capacidades da janela de contexto do dolphin-llama3, mas lida com conversação geral e conteúdo criativo de forma consistente.
- Parâmetros: 7B, 13B ou 30B
- VRAM: ~5 GB (7B); ~9 GB (13B); ~20 GB (30B)
- Ideal para: Conversação de uso geral e conteúdo criativo com múltiplas opções de tamanho
- Plataforma: Ollama
8. dolphincoder: Modelo de IA sem censura para programação na base StarCoder2
O StarCoder2 como base torna o dolphincoder um especialista genuíno. Enquanto outros modelos Dolphin são generalistas com ajuste sem censura, este foca especificamente no desenvolvimento de software. Seus 943 mil pulls vêm quase inteiramente de desenvolvedores, não de usuários criativos. A variante 15B lida com bases de código maiores do que a 7B pode gerenciar.
- Parâmetros: 7B ou 15B
- VRAM: ~5 GB (7B); ~10 GB (15B)
- Ideal para: Geração de código, depuração e documentação técnica
- Plataforma: Ollama
9. wizardlm-uncensored: LLM sem censura de seguimento de instruções para fluxos de pesquisa
Um modelo de seguimento de instruções 13B com 610 mil pulls. Sua força é seguir instruções complexas de várias etapas sem hesitar ou recusar subtarefas. Em fluxos de trabalho de pesquisa, onde uma recusa quebra uma longa cadeia, essa confiabilidade tem valor direto na produtividade. Ele não possui a arquitetura base moderna do dolphin-llama3, mas faz o trabalho de instrução de forma consistente.
- Parâmetros: 13B
- VRAM: ~9 GB
- Ideal para: Cadeias complexas de instruções de várias etapas e fluxos de pesquisa
- Plataforma: Ollama
10. everythinglm: LLM sem censura com janela de contexto de 16K
O recurso de destaque aqui é a janela de contexto de 16K em uma base Llama 2. A maioria dos modelos 7B chega ao máximo em 4K ou 8K tokens. Esse contexto extra permite que o everythinglm processe bases de código completas, documentos longos ou históricos de conversação estendidos sem truncamento. Seus 536 mil pulls são modestos para os padrões desta lista, mas preenchem uma lacuna que nenhum outro modelo aqui cobre neste tamanho.
- Parâmetros: 13B
- VRAM: ~9 GB
- Ideal para: Análise de documentos longos, chat com contexto estendido e revisão de base de código completa
- Plataforma: Ollama
O domínio da série Dolphin nas contagens de download do Ollama reflete um padrão que a comunidade documentou: modelos sem censura ajustados de um único autor com uma metodologia consistente superam tentativas isoladas de abliteracão. A abliteracão remove pesos de recusa de um único modelo. O ajuste fino constrói um comportamento sem censura estável em diversos tipos de prompt. Essa consistência é a razão pela qual 5 das 10 primeiras posições pertencem ao trabalho de Eric Hartford, e não a qualquer arquitetura base única.
Como configurar modelos Ollama sem censura localmente?
Em 2026, três comandos instalam qualquer modelo Ollama no Mac, Linux ou Windows: instale o Ollama de ollama.com, execute ollama pull [nome-do-modelo], depois ollama run [nome-do-modelo] (documentação do Ollama, 2026). Nenhuma chave de API é necessária. Nenhuma moderação de conteúdo externa se aplica. Seu prompt nunca sai do seu hardware.
Para o dolphin-llama3 como exemplo concreto: ollama pull dolphin-llama3 baixa o arquivo 8B de 4,7 GB. ollama run dolphin-llama3 abre um prompt interativo. Todo o processo de inferência roda na sua GPU ou CPU local.
O LM Studio fornece uma interface gráfica de desktop para usuários que preferem não trabalhar no terminal. Ele usa os mesmos arquivos de modelo GGUF que o Ollama usa, com uma interface visual para seleção de modelo e ajuste de parâmetros. O llama.cpp é o motor de inferência subjacente por trás de ambas as ferramentas e suporta o uso direto via linha de comando quando você precisa de mais controle sobre níveis de quantização e configurações de comprimento de contexto.
Desenvolvedores que desejam requisitos de hardware específicos e configurações de quantização para rodar os melhores modelos locais de IA sem censura de 2026 em GPUs de consumo encontrarão no guia completo de configuração local os detalhes sobre configurações mínimas de VRAM e erros comuns de configuração.
Quais modelos OpenRouter sem censura estão disponíveis sem uma GPU local?
Em 2026, o OpenRouter hospeda LLMs sem censura via API, removendo totalmente o requisito de GPU. O modelo venice/uncensored está disponível como um modelo de nível gratuito a US$0 por milhão de tokens de entrada e saída (OpenRouter, página do modelo venice/uncensored, 2026). Isso torna os modelos sem censura do OpenRouter o ponto de entrada prático para usuários sem hardware dedicado.
A compensação é direta: o OpenRouter roteia seu prompt através de sua infraestrutura, portanto, a conversa não é privada da mesma forma que em um modelo local. Modelos Ollama locais mantêm tudo no seu dispositivo. Nenhuma abordagem é universalmente melhor. A escolha certa depende do seu modelo de ameaça e disponibilidade de hardware.
11. venice/uncensored: Modelo OpenRouter sem censura gratuito
O modelo Venice Uncensored no nível gratuito do OpenRouter. Uma base Mistral-Small 24B, ajustada para saída sem censura pela Cognitive Computations em colaboração com Venice.ai. Janela de contexto de 32K, US$0 por milhão de tokens. O nível gratuito do OpenRouter aplica um limite de plataforma de 200 solicitações por dia em modelos gratuitos.
- Parâmetros: 24B
- VRAM: Nenhuma necessária (hospedado na nuvem)
- Ideal para: Testar LLMs sem censura sem hardware local; gratuito dentro dos limites de uso da plataforma
- Plataforma: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: Modelo grande sem censura via OpenRouter
Modelo de 70B para roleplay criativo e seguimento de instruções da Sao10k, ajustado para saída sem censura. Baseado no Llama 3.3 70B com 131K de contexto. Mantido ativamente com uso real no OpenRouter e pesquisável por nome na busca global da plataforma.
- Parâmetros: 70B
- VRAM: Nenhuma necessária (hospedado na nuvem)
- Ideal para: Escrita criativa complexa, roleplay e cadeias de instruções longas sem hardware local
- Plataforma: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: Modelo leve sem censura via OpenRouter
O Lunaris 8B é um modelo versátil generalista e de roleplay da Sao10k, baseado no Llama 3 8B. É uma fusão estratégica de vários modelos projetada para equilibrar a criatividade com lógica melhorada e conhecimento geral, oferecendo uma experiência melhorada em relação ao Stheno v3.2 com maior criatividade e raciocínio. A opção sem censura de menor custo no OpenRouter, a US$0,04/US$0,05 por milhão de tokens, com mais de 6 bilhões de tokens de uso real na plataforma.
- Parâmetros: 8B
- VRAM: Nenhuma necessária (hospedado na nuvem)
- Ideal para: Conversação leve sem censura e escrita criativa com custo mínimo
- Plataforma: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: Modelo de escrita criativa sem censura via OpenRouter
Cydonia 24B V4.1 é um modelo de escrita criativa sem censura da TheDrummer, baseado no Mistral Small 3.2 24B, com bom recall, aderência a prompts e inteligência. Janela de contexto de 131K. Mantido ativamente e diretamente pesquisável por nome na busca global do OpenRouter.
- Parâmetros: 24B
- VRAM: Nenhuma necessária (hospedado na nuvem)
- Ideal para: Escrita criativa e roleplay sem censura sem hardware local
- Plataforma: OpenRouter
Como acessar modelos de imagem e vídeo sem censura via Atlas Cloud
Em 2026, a maioria dos modelos de imagem e vídeo sem censura exige hardware GPU local ou uma plataforma de API dedicada, porque os provedores de nuvem tradicionais aplicam filtros de conteúdo que bloqueiam saídas NSFW no nível da inferência. Atlas Cloud é uma plataforma de API de modelos construída especificamente para remover essa restrição, cobrindo mais de 300 modelos curados de texto, imagem, vídeo e áudio.
Começar leva três etapas:
- Crie uma conta em atlascloud.ai
- Gere uma chave de API no painel
- Chame o endpoint do modelo usando a chave — modelos de imagem e vídeo usam seu próprio formato REST; endpoints de LLM seguem o formato OpenAI Chat Completions
O que torna a Atlas Cloud relevante especificamente para casos de uso sem censura:
- A política de privacidade da plataforma afirma: "Seu conteúdo gerado nunca é usado para treinamento e nunca é revisado por ninguém." Este é um compromisso publicado e explícito, não uma suposição padrão.
- Nenhum limite diário de geração se aplica a qualquer modelo no catálogo.
- O catálogo de imagens sem censura cobre 33 modelos de texto para imagem começando em US$0,003 por imagem.
- O catálogo de vídeos sem censura cobre mais de 10 modelos de vídeo NSFW começando em US$0,01/seg.
O catálogo completo de modelos sem censura pode ser navegado em Uncensored AI. Os modelos nº 15 a nº 20 nesta lista são todos acessíveis através de uma única chave de API da Atlas Cloud.
Quais são os melhores modelos de IA de imagem sem censura para geração de conteúdo NSFW e adulto?
Em 2026, a arquitetura FLUX alimenta a maioria das gerações de imagem sem censura de alta qualidade, disponível via API da Atlas Cloud através de faixas de preço e qualidade (Atlas Cloud, lista de modelos de texto para imagem, 2026). O catálogo da Atlas Cloud cobre 33 modelos de texto para imagem no total. Os casos de uso incluem arte, design de personagens, modelos de lingerie sem censura e geração de retratos adultos, criação de ativos de jogos e ilustração em lote em volume.
A página inicial da Atlas Cloud afirma "Mais de 300 modelos curados de texto, imagem, vídeo e áudio", e a política de privacidade da plataforma para seu catálogo sem censura diz: "Seu conteúdo gerado nunca é usado para treinamento e nunca é revisado por ninguém."
Para uma análise completa de ferramentas de imagem sem censura baseadas em navegador e API, o guia dos melhores geradores de imagem de IA NSFW sem censura cobre ambas as categorias com comparações de capacidade. Desenvolvedores focados especificamente na arquitetura FLUX podem ler o guia de gerador de imagem sem censura FLUX para detalhes de ajuste fino e fluxo de trabalho.
Para fluxos de trabalho que começam de uma imagem existente em vez de um prompt de texto, o guia de imagem para imagem de IA sem censura e o guia dos melhores editores de imagem de IA sem censura cobrem pipelines de transformação e edição, respectivamente. Equipes focadas em estilo anime ou saída de personagens ilustrados encontrarão opções especializadas no guia de geradores de imagem de IA anime sem censura.
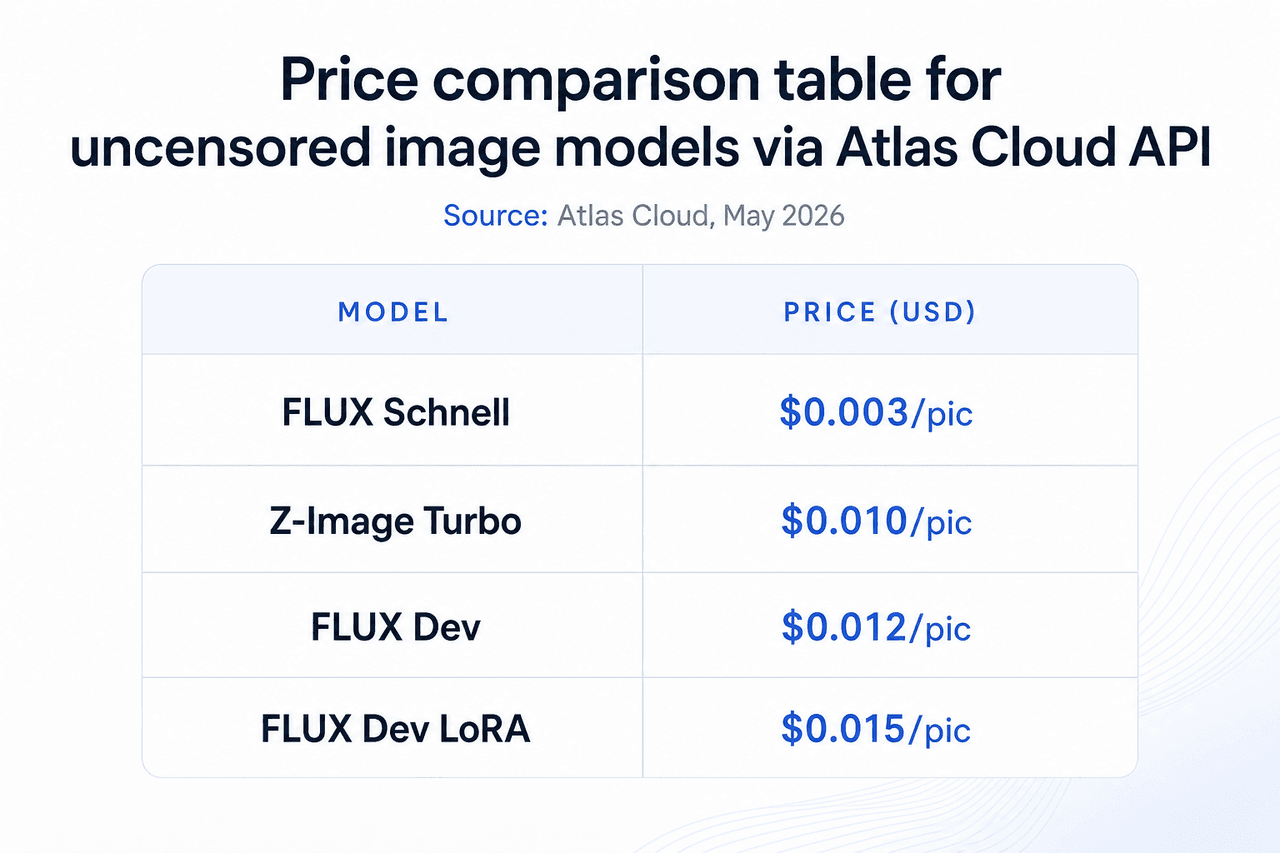
15. FLUX Schnell: Modelo de IA de imagem sem censura mais rápido para geração em lote
A opção de menor custo no catálogo de imagens da Atlas Cloud. A US$0,003 por imagem, é a ferramenta certa para fluxos de trabalho de geração em lote onde a velocidade e o volume importam mais do que detalhes finos. Nenhum limite diário se aplica e nenhum conteúdo é armazenado para treinamento.
- Preço: US$0,003/img
- VRAM: Nenhuma necessária (acesso via API)
- Ideal para: Geração de imagem em lote, prototipagem rápida e saída sem censura de alto volume
- Plataforma: API Atlas Cloud
A US$0,003 por imagem, um orçamento de US$3,00 produz 1.000 imagens. Esse custo por saída é menor do que as taxas de armazenamento em nuvem para os arquivos resultantes na maioria dos provedores. Isso muda a economia para estúdios que anteriormente rodavam equipamentos de GPU locais caros durante a noite para geração em lote: a abordagem de API é agora mais barata e mais rápida para trabalho de volume.
16. FLUX Dev: Modelo de IA de imagem sem censura de maior qualidade para produção final
Quatro vezes o custo do FLUX Schnell, com anatomia, iluminação e detalhes de textura notavelmente melhores. Para saída de qualidade final onde imagens individuais importam, o preço de US$0,012 é um passo prático acima. Ele atende a peças de portfólio, conteúdo adulto comercial e ativos de produção onde a qualidade é a principal restrição.
- Preço: US$0,012/img
- VRAM: Nenhuma necessária (acesso via API)
- Ideal para: Imagens únicas de alta qualidade, peças de portfólio e ativos de produção final
- Plataforma: API Atlas Cloud
17. FLUX Dev LoRA: Modelo de imagem sem censura com treinamento de estilo personalizado
O ajuste fino LoRA injeta um estilo personalizado, aparência de personagem ou assunto na base FLUX Dev. Este é o modelo para usar quando você precisa de uma aparência de personagem consistente em um lote ou deseja um estilo específico aplicado a cada imagem em um conjunto. A Atlas Cloud gerencia o carregamento do LoRA no servidor.
- Preço: US$0,015/img
- VRAM: Nenhuma necessária (acesso via API)
- Ideal para: Consistência de personagens, treinamento de estilo personalizado e séries de imagens com marca
- Plataforma: API Atlas Cloud
18. Z-Image Turbo: Modelo de IA de imagem sem censura econômico com qualidade de nível intermediário
Posicionado entre o FLUX Schnell e o FLUX Dev na curva de preço-qualidade. A US$0,01 por imagem, o Z-Image Turbo oferece uma arquitetura diferente otimizada para velocidade sem a simplificação de imagem que o Schnell faz em seu ponto de preço mais baixo. A escolha prática quando a qualidade do Schnell não é suficiente e o custo do FLUX Dev é muito alto para o volume necessário.
- Preço: US$0,01/img
- VRAM: Nenhuma necessária (acesso via API)
- Ideal para: Geração de volume moderado onde qualidade e custo precisam equilibrar
- Plataforma: API Atlas Cloud
Quais são os melhores modelos de vídeo de IA sem censura para animação NSFW em 2026?
Em 2026, a geração de vídeo sem censura requer um pipeline separado da geração de imagem, porque as plataformas de vídeo convencionais aplicam filtros de conteúdo idênticos e recusam-se a animar conteúdo NSFW mesmo quando a imagem de origem foi gerada em outro lugar (Atlas Cloud, catálogo de modelos sem censura, 2026). A página de vídeo sem censura da Atlas Cloud traz a manchete "Liberdade Criativa Irrestrita. Sem Filtros. Sem Limites" e cobre mais de 10 modelos de vídeo NSFW, com o catálogo completo também incluindo variantes da série Wan 2.6, Wan 2.5 e Van.
19. Wan 2.2 Turbo Spicy Infinite I2V: Modelo de vídeo sem censura de menor custo
A opção de nível de entrada para animação NSFW a partir de uma imagem estática. A US$0,01/seg, é a maneira mais eficiente de custo para animar uma imagem estática em conteúdo de vídeo NSFW. A resolução chega a 1080p com duração de clipe variável, tornando-o o ponto de partida certo para pipelines de produção preocupados com o orçamento.
- Preço: US$0,01/seg
- Resolução: 1080p
- Duração: Variável
- Ideal para: Animação NSFW eficiente em custos e visualização de conceitos de movimento
- Plataforma: API Atlas Cloud
20. Seedance v1.5 Spicy: Modelo de vídeo sem censura de maior qualidade para saída final
A opção de qualidade cinematográfica no catálogo. A US$0,049/seg, custa cerca de 2,5 vezes mais que o Wan 2.2 Turbo Spicy Infinite, mas produz movimento mais suave, melhor coerência do assunto entre quadros e transições mais naturais. Para saída de vídeo NSFW de qualidade final, onde a fidelidade visual é a principal preocupação, esta é a opção de topo na linha de vídeo sem censura da Atlas Cloud.
- Preço: US$0,049/seg
- Resolução: 720p
- Duração: 5s
- Ideal para: Vídeo NSFW de qualidade final, conteúdo adulto profissional e saída pronta para entrega
- Plataforma: API Atlas Cloud
O guia dos melhores geradores de imagem para vídeo de IA sem censura cobre o catálogo completo de variantes da série Wan 2.7 e Wan 2.2 Spicy com todas as opções de duração e resolução.
Guia de seleção rápida de modelos de IA sem censura
| Necessidade | Recomendado |
|---|---|
| Melhor LLM sem censura geral | llama2-uncensored ou dolphin-llama3 |
| Tarefas de programação | dolphin-mixtral 8x7B ou dolphincoder |
| Roleplay e escrita criativa | hermes3 |
| Abaixo de 4GB VRAM | dolphin-phi 2.7B |
| Geração de imagem sem censura | FLUX Schnell via Atlas Cloud (US$0,003/img) |
| Vídeo NSFW a partir de imagem | Wan 2.2 Turbo Spicy Infinite via Atlas Cloud (US$0,01/seg) |
Perguntas frequentes sobre modelos de IA sem censura
Qual é o modelo de IA mais sem censura em 2026?
Por contagem de downloads no Ollama, o llama2-uncensored lidera com 2,6 milhões de pulls, tornando-o a opção mais validada pela comunidade entre os modelos de IA sem censura de 2026 (Ollama, pesquisa de modelos sem censura, 2026). Por capacidade bruta, o dolphin-llama3 oferece mais: chamada de função, até 256K de contexto e uma arquitetura base Llama 3. A resposta depende se estabilidade comprovada ou capacidade moderna importa mais para o seu caso de uso.
Quais modelos sem censura rodam no Ollama?
Dez modelos desta lista rodam como modelos Ollama sem censura: llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored e everythinglm. O modelo comunitário jaahas/qwen3.5-uncensored também roda no Ollama para uso multilíngue. Todos são instalados com ollama pull [nome-do-modelo].
Quais modelos sem censura estão disponíveis no OpenRouter?
Em 2026, o OpenRouter hospeda LLMs sem censura via API, removendo totalmente o requisito de GPU. As opções incluem o modelo venice/uncensored no nível gratuito a US$0 por milhão de tokens (200 solicitações por dia), além de modelos pagos, incluindo Sao10K Euryale 70B, Lunaris 8B e TheDrummer Cydonia 24B (OpenRouter, página do modelo venice/uncensored, 2026). Esses modelos OpenRouter sem censura não exigem GPU local e nenhum investimento em hardware para começar.
Qual é a diferença entre um modelo sem censura abliterado e um ajustado (fine-tuned)?
A abliteracão remove pesos de recusa de um modelo cirurgicamente no nível dos pesos. Modelos sem censura ajustados como a série Dolphin são treinados em conjuntos de dados que não reforçam o comportamento de recusa em primeiro lugar. A comunidade considera consistentemente que os modelos ajustados são mais estáveis: a abliteracão pode introduzir saída inconsistente em diversos tipos de prompt, enquanto o ajuste fino produz resultados confiáveis, o que explica por que os modelos Dolphin dominam as contagens de download do Ollama.
Posso rodar modelos de IA sem censura localmente em um laptop?
Sim. O dolphin-phi 2.7B roda com menos de 4 GB de VRAM, tornando-o o ponto de entrada para implementação em laptop com uma GPU dedicada. Com 6-8 GB de VRAM, você pode rodar qualquer modelo 7B desta lista. Gráficos integrados não funcionarão. O guia de configuração local para modelos de IA sem censura cobre configurações mínimas de hardware e configurações de quantização em detalhes.
Conclusão
O melhor modelo de IA sem censura em 2026 depende inteiramente do seu caso de uso. Para trabalho geral de LLM, o dolphin-llama3 é a opção mais capaz no Ollama. Para laptops, o dolphin-phi cobre o requisito de VRAM abaixo de 4 GB. Para acesso a LLM na nuvem sem hardware, o venice/uncensored no nível gratuito do OpenRouter é o ponto de partida prático a US$0 por milhão de tokens. Para geração de imagem sem censura em escala, o FLUX Schnell via API Atlas Cloud produz saída a US$0,003 por imagem sem limite diário. Para vídeo NSFW, o catálogo da Atlas Cloud começa em US$0,01/seg com uma política verificada de não treinamento e não revisão.
Leitores que buscam uma visão geral completa de ferramentas de IA sem censura para imagens, vídeo e editores encontrarão o guia de geradores de imagem de IA sem censura cobrindo todo o panorama.






