
Há alguns meses, definimos um objetivo enganosamente simples: produzir vídeos coerentes e de alta qualidade com mais de 15 segundos, em uma única GPU, em menos de um minuto de tempo de processamento. Os modelos de difusão de vídeo atuais, como o Wan2.2, são bons em clipes de 3 a 5 segundos. Expandir isso para 10s, 30s ou um minuto é onde as coisas ficam interessantes.
Esta publicação documenta o caminho que realmente seguimos. Analisamos seis abordagens presentes em artigos recentes e relatórios técnicos — TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk e Helios —, medimos os prós e contras e, finalmente, optamos pelo SVI (Stable Video Infinity), integrado ao TurboWan em nosso DiffSynth Engine. Analisaremos cada uma dessas rotas, como o SVI funciona e, em seguida, os números de produção.
Por que vídeos longos são difíceis
Três coisas quebram quando você ultrapassa cerca de cinco segundos.
A barreira da VRAM
O Wan2.2 utiliza Full Attention com custo O(n²) no número de tokens latentes. A matemática é implacável:
5s (81 frames): ~32,7 mil tokens, matriz de atenção ~10 GB.
10s (165 frames): ~65,5 mil tokens, matriz de atenção ~40 GB — já ultrapassa a capacidade de uma única GPU.
30s (~500 frames): ~200 mil tokens, inviável.
Na prática, apenas o Self Forcing preenche a maior parte dos 129 GB de um H200 a 165 frames apenas para o cache KV.
Desvio temporal (Temporal drift)
Mesmo quando a memória está ok, três tipos de desvio surgem. O artigo Helios os nomeou: desvio de posição (assuntos vagando pelo quadro), desvio de cor (mudança gradual de matiz e brilho) e desvio de restauração (o modelo corrige excessivamente e produz descontinuidades visíveis).
Consistência causal
A difusão de vídeo padrão usa Full Attention bidirecional — cada frame presta atenção em todos os outros. Isso significa que não há saída de streaming: você não pode mostrar o frame 1 até que o frame N esteja concluído.
Nosso objetivo concreto era modesto: vídeo ≥15 segundos, continuidade visual suave, assuntos estáveis durante todo o clipe, tempo total de espera inferior a 60 segundos, treinamento mínimo e uma forte preferência pela reutilização de pesos que já possuímos.
A pesquisa
Analisamos seis famílias. Os nomes são, em sua maioria, títulos de artigos; as categorias serão importantes mais adiante.
Rota 1 · TTT (Test-Time Training)
Artigo: One-Minute Video Generation with Test-Time Training (arXiv 2504.05298, abr. 2025).
A ideia é realizar o fine-tuning do modelo durante a inferência para que ele se lembre do que já gerou. Uma pequena camada TTT (um MLP de 2 camadas, além de uma porta e uma atenção local) é inserida após a Atenção em cada Bloco Transformer, e o modelo é treinado em um currículo que avança de clipes curtos até um minuto completo.
Inserção por bloco: Após a atenção padrão, insira uma Porta, uma Camada TTT e uma Atenção Local, seguidas por uma LayerNorm.
Currículo: Treinar em janelas progressivamente mais longas — 3s → 9s → 18s → 30s → 60s.
Custo: 256 H100s por ~50 horas.
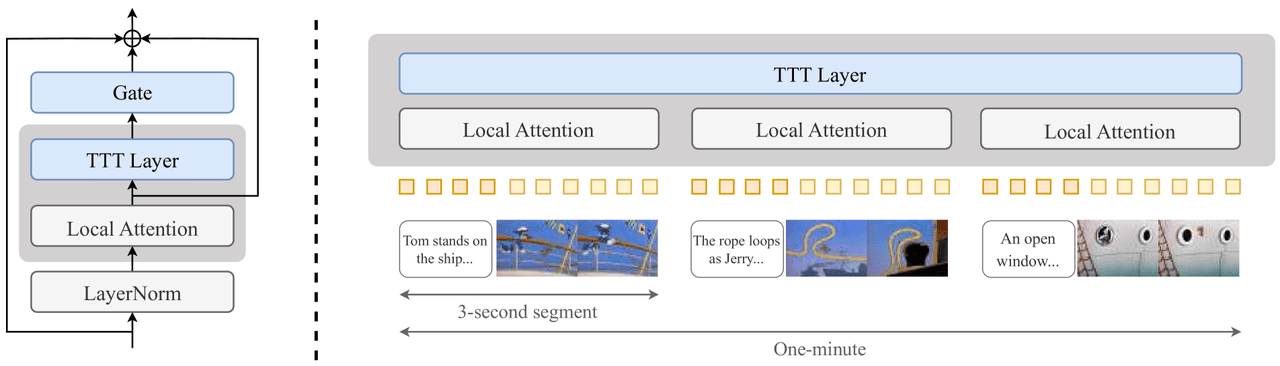
TTT — esquerda: ponto de inserção (Porta + Camada TTT + Atenção Local + LayerNorm, anexada após a Atenção padrão via residual). Direita: vídeo segmentado em clipes de 3 segundos, cada um gerenciado internamente pela Atenção Local, com a Camada TTT carregando a memória global entre os segmentos.
Funciona — o artigo alcança a geração de 1 minuto. Mas o custo de treinamento é enorme, os experimentos cobrem apenas o CogVideoX 5B (a transferência para o Wan2.2 14B não é comprovada) e as camadas TTT inseridas conflitam com as otimizações de kernel nas quais já confiamos. Veredito: não selecionado.
Rota 2 · LoL (Longer than Longer)
Artigo: LoL: Longer than Longer, Scaling Video Generation to Hour (arXiv 2601.16914, jan. 2026).
O LoL foca em um modo de falha específico em vídeos longos autorregressivos — o sink-collapse, onde a atenção multi-head converge inteiramente para o frame âncora e o vídeo reverte periodicamente ao seu estado inicial. A correção é o Multi-Head RoPE Jitter: perturbações de fase aleatórias por head que quebram a homogeneidade entre heads. Sem treinamento, tipo plug-in.
Modo de falha: sink-collapse — sob RoPE autorregressivo, as fases posicionais de frames distantes realinham-se periodicamente com a âncora, a atenção se concentra e o conteúdo volta para o frame âncora.
Correção: Dê a cada head de atenção seu próprio pequeno deslocamento de fase aleatório. Os heads não podem mais colapsar na mesma coluna. Sem necessidade de retreinamento, integra-se aos modelos existentes.
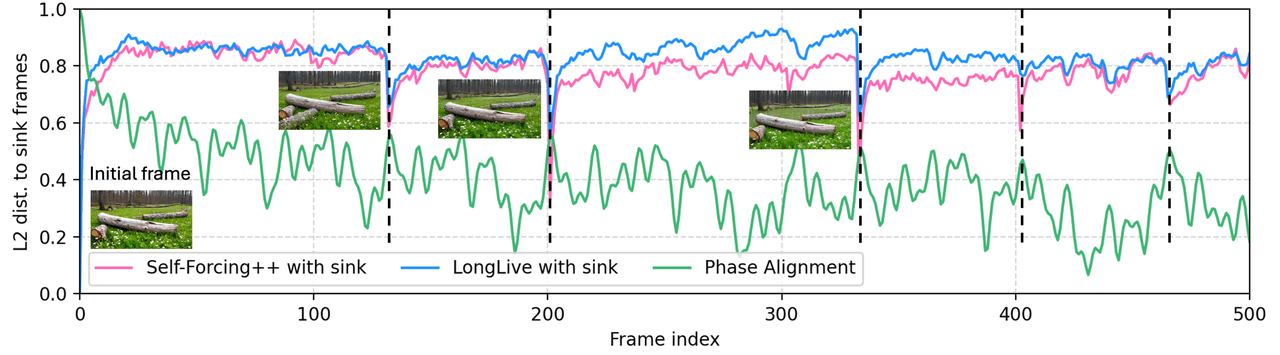
Distância L2 até a âncora vs. índice do frame. Self-Forcing++ (vermelho) e LongLive (azul), ambos com sink, voltam repetidamente para posições de frame específicas — são eventos de sink-collapse onde o vídeo reverte para a âncora. O Alinhamento de Fase do LoL (verde) elimina o efeito de snap-back.
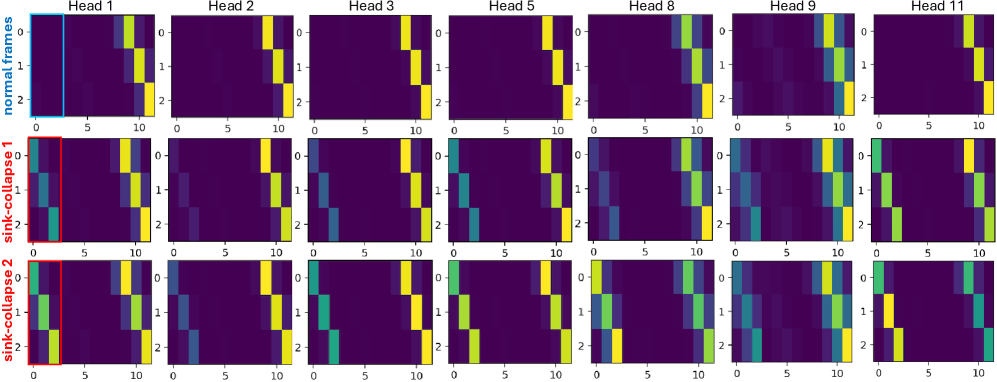
Mapas de atenção por head. Linha superior: frames normais — os heads têm padrões visivelmente diferentes. Linhas inferiores: durante o sink-collapse — todo head parece igual, todos colapsados na coluna do frame âncora. O RoPE Jitter restaura a diversidade por head.
O LoL atinge vídeos de 12 horas no CogVideoX/HunyuanVideo com pouca perda de qualidade. O problema é que todas as demos são cenas quase estáticas; não sabemos como ele sobrevive a dança, esportes ou qualquer coisa com movimento intenso. Além disso, teríamos que modificar a atenção do Wan2.2. Veredito: o custo de adaptação é muito alto para ganhos não comprovados em conteúdo com movimento. Não selecionado.
Rota 3 · Self Forcing (Causal Wan2.2)
Artigo: Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion (arXiv 2506.08009, NeurIPS 2025 Spotlight).
O Self Forcing substitui a Full Attention bidirecional do Wan2.2 por atenção causal: um frame só presta atenção nos frames anteriores a ele. Essa simples mudança libera a geração por streaming — assim que o primeiro segmento é concluído, decodifique e envie.
Bidirecional: todo frame presta atenção em todos os outros → deve finalizar todos os 40 passos de denoise antes que qualquer frame possa ser mostrado. Causal: um frame só vê o passado → o primeiro segmento pode fazer streaming assim que terminar.
O truque de treinamento é o que dá o nome ao artigo. Em vez de treinar com contexto de ground-truth limpo (Teacher Forcing) ou com máscaras de atenção personalizadas (Diffusion Forcing), o Self Forcing executa o caminho de inferência real com um cache KV rotativo, para que as distribuições de treino e inferência coincidam.
Loop de geração: aplique denoise no próximo pequeno segmento de frames usando o cronograma de passos comprimidos do DMD, condicionado a um cache KV rotativo construído a partir de frames já gerados.
Stream: assim que um segmento termina, decodifique via VAE e emita.
Carry-over: empurre os latentes do novo segmento para o cache KV para que o próximo segmento possa prestar atenção nele.
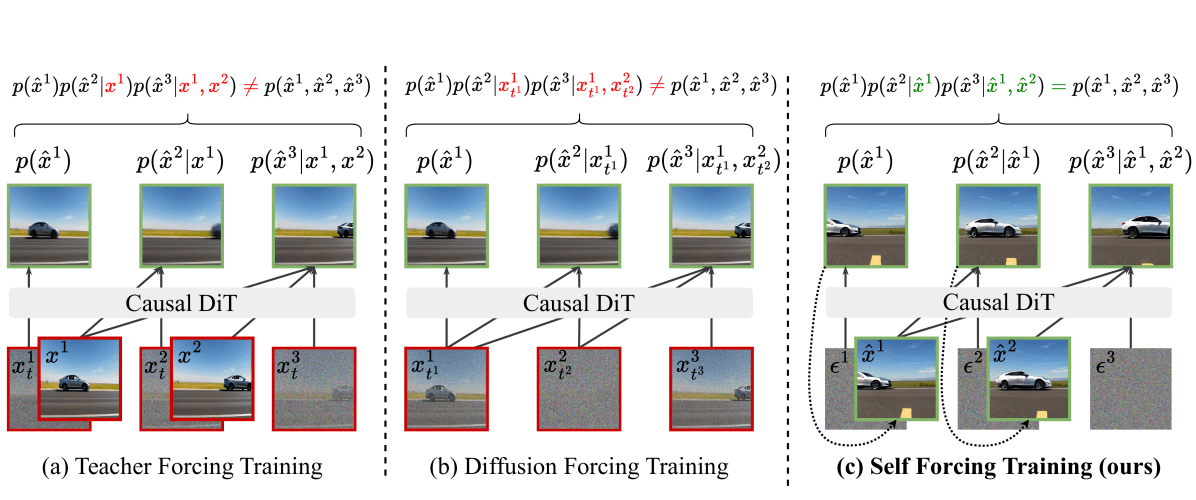
Três paradigmas de treinamento comparados: (a) Teacher Forcing treina em frames limpos — na inferência, frames com ruído causam desvio fora da distribuição; (b) Diffusion Forcing usa máscaras de atenção personalizadas, mas ainda tem desvio entre treino e inferência; (c) Self Forcing reproduz o processo de inferência real usando cache KV rotativo, alinhando totalmente treino e inferência.
Medimos no framework FastVideo, em um único H200:
| Duração | Frames | Tempo | VRAM |
|---|---|---|---|
| 5s | 81 frames | 70s | — |
| 10s | 165 frames | 168s | 129 GB (perto da capacidade) |
| 20s | 321 frames | 287s | 129 GB (cache KV limitado a 42 frames) |
Esta é a resposta arquiteturalmente mais limpa, e gostamos muito dela. Mas 10s já saturam a VRAM de um H200, a qualidade cai em 165 frames, o modelo original precisa de fine-tuning de atenção causal e o streaming real também precisa de um Causal Conv3D no VAE.
Veredito: aguardaremos a comunidade resolver os problemas de VRAM e qualidade. Não adotado por enquanto.
Rota 4 · Self Forcing++
Artigo: Self-Forcing++: Towards Minute-Scale High-Quality Video Generation (arXiv 2510.02283, out. 2025).
Baseia-se no Self Forcing com três adições: Backward Noise Initialization (cada novo segmento começa a partir de ruído integrado retroativamente a partir de frames já gerados, removendo descontinuidades nas fronteiras dos segmentos); Extended DMD alignment (corte janelas de 5s de um longo rollout e alinhe contra a saída de janela curta de um professor); e um estágio de GRPO com recompensa de fluxo óptico para impulsionar movimentos mais dinâmicos.
Passo 1. Auto-execução (self-rollout) do aluno por muito mais de 5 segundos, acumulando um rascunho longo usando um cache KV rotativo. Passo 2. Corte janelas aleatórias de 5s desse rascunho, execute-as através do Extended DMD contra a distribuição de janela curta do professor para alinhar. Passo 3. Refine com GRPO usando a magnitude do fluxo óptico como recompensa, impulsionando o modelo para movimentos mais dinâmicos. Truque. Cada novo segmento começa com ruído integrado retroativamente do segmento anterior, não de um Gaussiano novo — assim, as fronteiras dos segmentos não apresentam saltos.
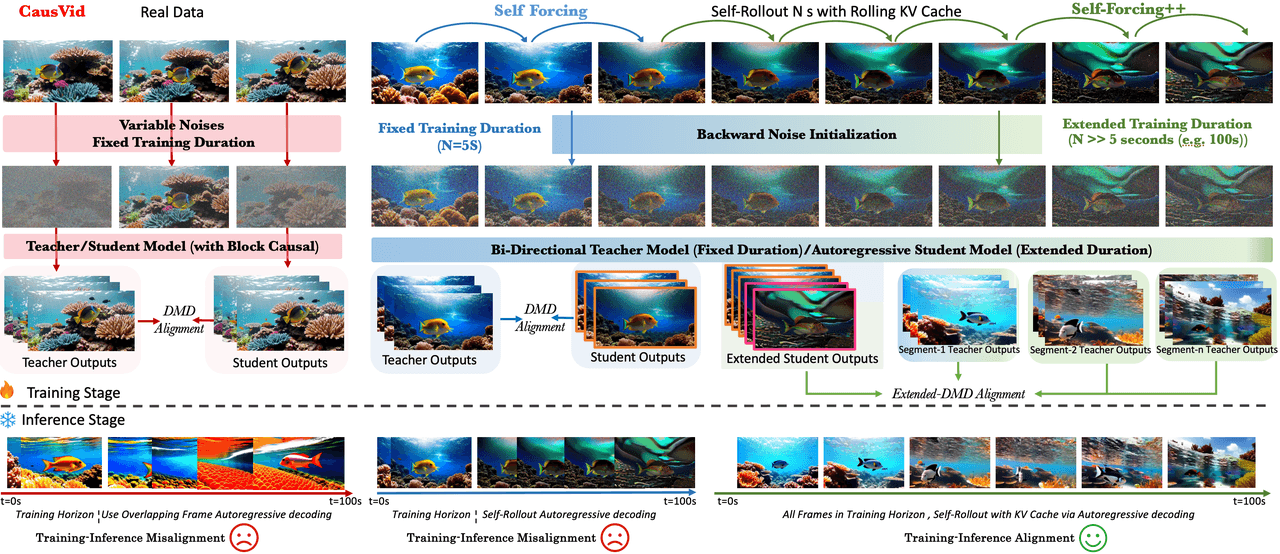
Esquerda para a direita: CausVid (duração de treinamento fixa, desvio treino-inferência) → Self Forcing (duração fixa + alinhamento DMD) → Self-Forcing++ (duração estendida + Inicialização de Ruído Reverso + alinhamento DMD Estendido). As linhas inferiores mostram a correspondência entre o estágio de treinamento e o estágio de inferência.
Resultado: vídeo em escala de minutos (até cerca de 4m15s) em um Wan2.1 1.3B. Ótimo artigo. Para produção, encontramos duas barreiras: o conteúdo é majoritariamente estático (pouco movimento), o modelo base é de 1.3B (muito abaixo do Wan2.2 14B) e não há código ou pesos lançados para inicializar. Veredito: não selecionado por enquanto.
Rota 5 · Infinite Talk (A2V)
Um tipo de problema completamente diferente — Áudio-para-Vídeo, onde o áudio impulsiona a geração contínua de rostos falando.
Bundle de entrada por segmento: os latentes ruidosos do novo segmento, os recursos de áudio para essa janela de tempo, a imagem de referência fornecida pelo usuário, o último frame do segmento anterior e um peso de condicionamento suave. Identidade de referência: a imagem de referência mantém a aparência estável a longo prazo. Restrição adaptativa: o peso suave aperta ou relaxa a referência com base no desvio de similaridade. Ponte de movimento: o último frame do segmento anterior carrega o movimento através das fronteiras.
É bom para o que se propõe — rostos falando, indefinidamente. Mas a arquitetura difere o suficiente do Wan2.2 que requer treinamento dedicado e não generaliza para cenas gerais. Veredito: valioso em um nicho estreito, não é uma solução de vídeo longo geral.
Rota 6 · Helios
Artigo: Helios: Real Real-Time Long Video Generation Model (PKU-YuanGroup, arXiv 2603.04379, mar. 2026).
No momento da redação, o Helios é o SOTA para vídeo longo — 14B parâmetros, 19,5 FPS em tempo real em um único H100. O truque é comprimir frames históricos em uma pirâmide de três níveis e injetá-los no denoise do frame atual, para que o orçamento de tokens permaneça constante, não importa quão longo seja o vídeo.
Memória de Termos Múltiplos. O histórico de curto prazo (últimos 3 frames) mantém a resolução total; médio prazo (últimos 20 frames) recebe compressão moderada; longo prazo (tudo anteriormente) recebe compressão pesada. O orçamento total de tokens é constante, independentemente da duração do vídeo. Atenção de Orientação (Guidance Attention). Dentro de cada bloco DiT, os KVs históricos limpos e os QKVs ruidosos atuais são processados separadamente para que o ruído histórico não possa contaminar o denoise atual. Amostragem Piramidal. Amostre em baixa resolução primeiro para definir a estrutura, depois refine para alta resolução para adicionar detalhes — cerca de 2,3× menos tokens no total.
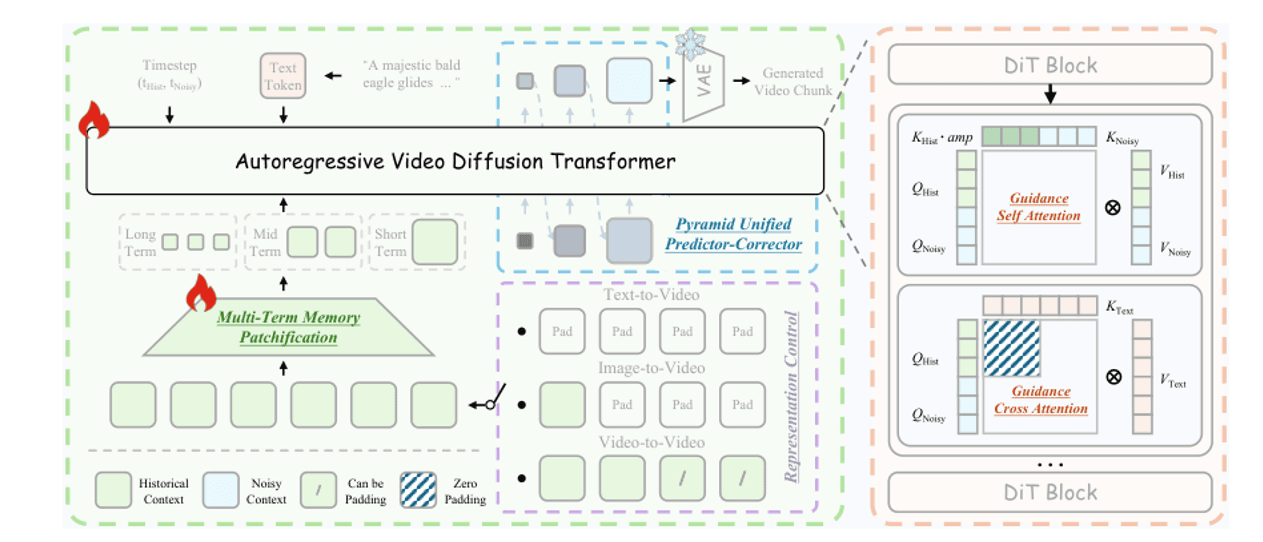
Arquitetura Helios. Esquerda: Injeção de Histórico Unificado — histórico de curto/médio/longo prazo comprimido em diferentes taxas, concatenado com o frame atual antes de entrar no DiT. Direita: Preditivo-Corretor Piramidal Unificado — baixa contagem de tokens primeiro para definir a estrutura, depois alta contagem de tokens para refinar detalhes, reduzindo o cálculo em ~2,3×.

O artigo Helios define e visualiza sistematicamente três categorias de desvio na geração de vídeos longos: (a) desvio de posição, (b) desvio de cor, (c) desvio de restauração (ruído), (d) desvio de restauração (desfoque). A Guidance Attention foi especificamente projetada para lidar com todos os três.
O throughput medido do Helios no H200 é impressionante — praticamente constante com a duração:
| Duração | Tempo | Throughput |
|---|---|---|
| 240 frames (10s) | 24s | ~10 FPS |
| 480 frames (20s) | 42s | ~11,4 FPS |
| 960 frames (40s) | 82s | ~11,7 FPS |
| H100 GPU único (Helios-Distilled) | — | 19,5 FPS |
O problema é que a Patchificação de Memória de Termos Múltiplos precisa de retreinamento completo de um modelo 14B. Não há pesos lançados — apenas um relatório técnico — então não podemos simplesmente adicionar um LoRA. Veredito: uma direção de médio a longo prazo; não implantável hoje.
Resumo da Comparação de Rotas
Todas as seis rotas lado a lado, com o SVI adicionado como a linha com a qual finalmente nos comprometemos:
| Abordagem | Duração Máx. | Qualidade | Treino Necessário | Dificuldade de Eng. | Generalidade | Rec. |
|---|---|---|---|---|---|---|
| TTT | 1 minuto | Alta | Treinamento pesado | Alta | Média | ★★☆ |
| LoL | Escala de hora | Média (estático apenas) | Treinamento necessário | Média | Média | ★★☆ |
| Self Forcing | Teoricamente ilimitada | Média (cai > 10s) | Modelo existente | Alta (problemas de VRAM) | Alta | ★★★ |
| Self Forcing++ | Escala de minutos | Baixa (maioria estática) | Treinamento necessário | Muito alta (sem código) | Alta | ★☆☆ |
| Infinite Talk | Ilimitada | Alta (rosto falando) | Treinamento necessário | Alta | Baixa (apenas A2V) | ★★☆ |
| Helios | Teoricamente ilimitada | Alta (SOTA da indústria) | Retreinamento total | Muito alta (sem pesos) | Alta | ★★★☆ |
| SVI | Ilimitada | Média-Alta | LoRA open-source | Média | Alta | ★★★★ |
Uma taxonomia que surgiu da pesquisa
Se você observar com atenção, cada abordagem que pesquisamos se encaixa em um de três grupos.
Tipo A — estender o alcance da atenção (Self Forcing, LoL, TTT). Fazer com que o modelo processe sequências mais longas diretamente. Qualidade teórica mais alta. A VRAM cresce quadraticamente, então a engenharia atinge um limite por volta dos 10s hoje.
Tipo B — compressão hierárquica de histórico (Helios). Comprimir frames passados e injetá-los como condicionamento. Ignora a VRAM. Custa um retreinamento completo de um modelo 14B.
Tipo C — geração contínua baseada em estado (SVI, Infinite Talk). Decompor o vídeo longo em clipes curtos com estado sobreposto. VRAM constante, duração ilimitada, treinamento apenas por LoRA. A troca são possíveis descontinuidades nas fronteiras dos clipes e desvios de longo prazo não limitados que você pode gerenciar, mas não eliminar.
Para este trimestre, o Tipo C é o que lançamos. Para o próximo ano, o Tipo B é onde estamos acompanhando a literatura.
Na próxima publicação, entraremos em detalhes sobre como foi o lançamento — seis abordagens para a geração de vídeos com ≥15 segundos, por que escolhemos o SVI e como são os números de produção. Leia a Parte 2 →






