
Na Parte 1, analisamos seis abordagens para a geração de vídeos longos — TTT, LoL, Self Forcing, Self Forcing++, Infinite Talk e Helios — e concluímos que o SVI é o único caminho disponível hoje sem a necessidade de retreinar um modelo de 14B. Este post é sobre como foi o processo de desenvolvimento: como funciona o loop de costura de clipes, por que a Reciclagem de Erros (Error-Recycling) é importante e os números de produção da nossa primeira implementação no TurboWan.
A escolha: SVI (Stable Video Infinity)
A filosofia central do SVI é transformar a geração de duração infinita na costura de um número finito de clipes curtos com transferência de memória cuidadosamente projetada. Isso parece modesto até perceber que resolve a maioria dos problemas de engenharia de uma só vez: sem retreinamento do modelo base (apenas um pequeno LoRA montado sobre o TurboWan), VRAM constante, compatível com destilação de velocidade existente e pesos LoRA oficiais públicos.
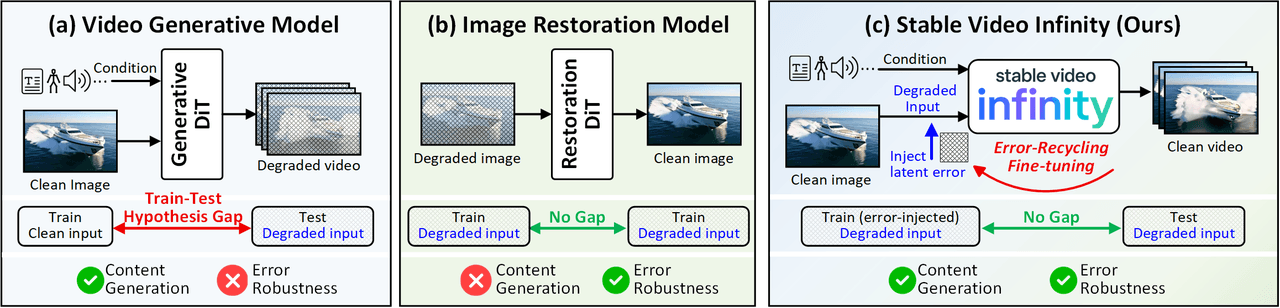
O modelo mental do SVI. (a) Modelos generativos de vídeo padrão possuem uma lacuna entre treino e teste — eles treinam com entradas limpas, mas enfrentam entradas ruidosas com acúmulo de erros na inferência. (b) Modelos de restauração de imagem são robustos a erros, mas não conseguem gerar conteúdo novo. (c) O Fine-Tuning com Reciclagem de Erros do SVI une ambos — usando erros autogerados como sinais de supervisão para que o modelo aprenda ativamente a identificar e corrigir seus próprios erros de geração.
Como funciona a costura de clipes
Cada clipe tem 81 quadros (5s a 16fps). A geração é apenas um loop: condicionar o próximo clipe a uma âncora de identidade global e a uma ponte de movimento de curto prazo do clipe anterior, e então concatenar.
Clipe 1. Entradas: imagem de referência + memória de movimento vazia. Saída: um clipe de 5s. Extrair memória de movimento: o latente dos últimos 4 quadros. Clipe 2. Entradas: imagem de referência + memória de movimento do clipe 1. Saída: um clipe de 5s. Extrair memória de movimento do seu final. ... Repetir para N clipes, depois concatenar clipe 1 + clipe 2 + … + clipe N no vídeo longo.
A parte limpa é que não é necessária nenhuma modificação de atenção DiT. O contexto histórico é concatenado no nível da entrada como latentes, e um pequeno LoRA ensina o modelo a usar esse prefixo.
Latente de âncora. Imagem de referência fornecida pelo usuário, codificada pelo VAE → mantém a aparência do assunto/personagem globalmente consistente. Latente de movimento. Latente dos últimos 4 / 8 / 12 quadros do clipe anterior → diz ao modelo como o último segmento terminou. Padding (Preenchimento). Alinha o formato da entrada para que o DiT veja uma sequência concatenada organizada: âncora + movimento + padding.
Fine-Tuning com Reciclagem de Erros (Error-Recycling)
O detalhe que faz o SVI se sustentar ao longo de muitos clipes é como seu LoRA é treinado. A inferência padrão sempre começa o denoising a partir de ruído gaussiano puro — mas na costura de vídeos longos, erros de clipes anteriores contaminam o condicionamento para clipes posteriores. Se você treinar apenas com entradas de referência limpas, você terá embutido a lacuna entre treino e inferência.
Treinamento padrão: as entradas de referência de cada clipe são verdades fundamentais (ground truth) limpas → o modelo nunca vê o tipo de contexto histórico ruidoso que ele realmente enfrenta na inferência, e descontinuidades se acumulam.
Reciclagem de Erros: durante o treinamento, injete deliberadamente os erros passados do próprio modelo nas entradas de referência, para que o LoRA aprenda explicitamente a operar em um contexto histórico ruidoso. As descontinuidades visuais nas fronteiras dos clipes caem drasticamente.
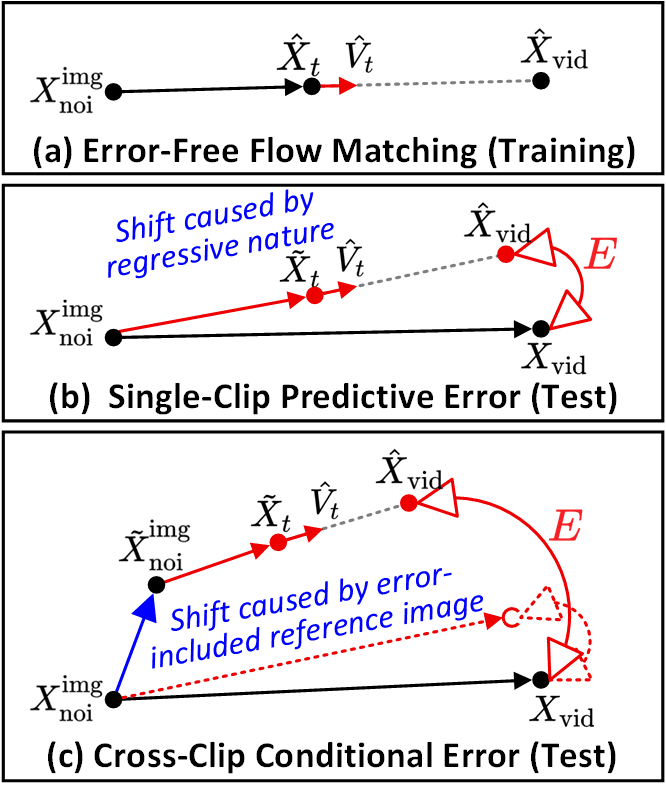
O SVI identifica dois tipos principais de erro. (a) Error-Free Flow Matching é a trajetória durante o treinamento. (b) Erro Preditivo de Clipe Único — o desvio por clipe entre o caminho de denoising e a trajetória ideal. (c) Erro Condicional entre Clipes — imagens de referência contaminadas por erros causam desvio em cascata entre os clipes. A Reciclagem de Erros injeta ambos explicitamente.
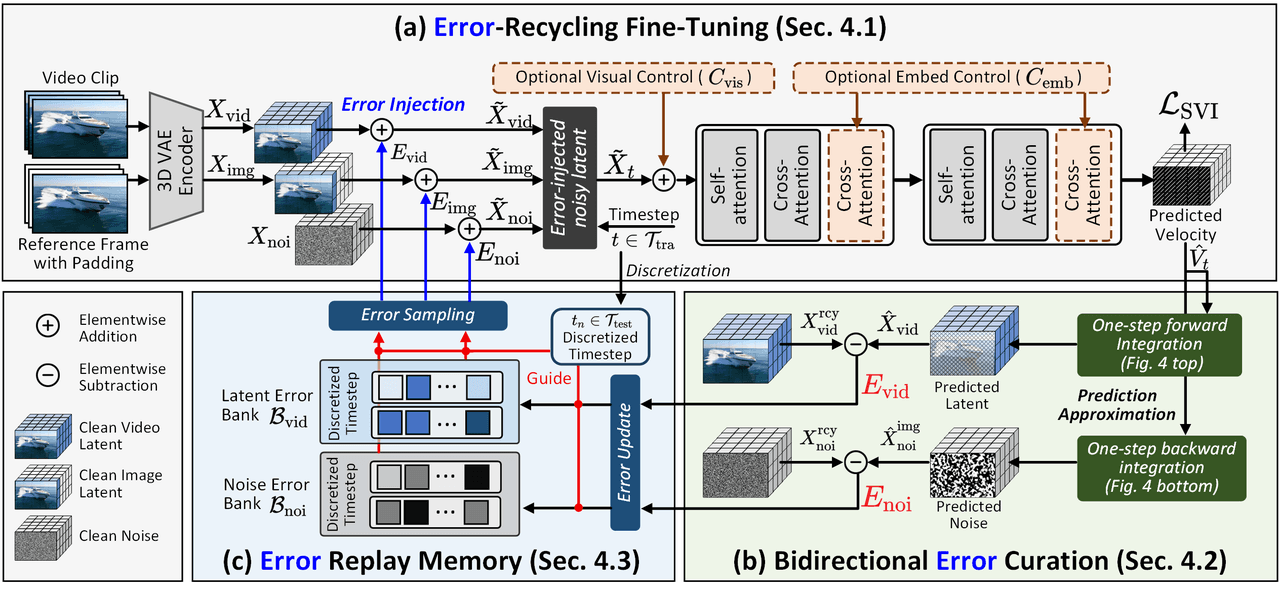
Estrutura de treinamento SVI. (a) Injetar erros autogerados do DiT no espaço latente para quebrar a suposição de ausência de erro. (b) Calcular eficientemente erros bidirecionais via integração de um passo para frente/trás. (c) Armazenar erros em uma Memória de Replay e reamostrar dinamicamente para reutilização, formando um ciclo de supervisão de erro em malha fechada.
O SVI separa dois tipos de erro. O Erro Preditivo de Clipe Único é o desvio por clipe entre o caminho de denoising e a trajetória ideal. O Erro Condicional entre Clipes é o desvio em cascata causado quando imagens de referência contaminadas por erros fluem para o próximo clipe. A Reciclagem de Erros injeta ambos, para que o LoRA aprenda tolerância a erros explícita.
Variantes LoRA
O SVI oferece três variantes — SVI-Shot para imagem estática → clipe curto, SVI-Dance para movimento humano (também pode aceitar entrada de sequência de pose) e SVI-Film para vídeos longos de várias tomadas/transições de cena. Hiperparâmetros: 81 quadros por clipe, num_motion_frames ∈ {4, 8, 12}, rank do LoRA tipicamente entre 16–64.
Empilhando no TurboWan
Montamos o LoRA do SVI sobre o TurboWan (uma versão do Wan otimizada para velocidade pela Atlas), e mantemos nosso LoRA especializado na pilha para controle de estilo. Na inferência, vários pesos LoRA são sobrepostos ao mesmo tempo.
Base. TurboWan LoRA 1. LoRA especializado — controle de conteúdo/estilo. LoRA 2. LoRA SVI — consistência de vídeo longo. Combinado. Velocidade TurboWan + continuidade de vídeo longo SVI + estilo picante, tudo em uma única passagem de inferência.
O fluxo completo de inferência é direto: codifique a referência em um latente de âncora, concatene-o com o latente de movimento do clipe anterior e o padding, execute o denoising do TurboWan, decodifique, anexe e atualize o latente de movimento a partir do final do clipe recém-gerado. Após N iterações, concatene tudo em um vídeo.
1. Codifique a imagem de referência → latente de âncora.
2. y = concat(latente de âncora, latente de movimento, padding).
3. Execute o denoising de 5 passos do TurboWan condicionado a y e ao embedding de texto.
4. Decodifique o VAE do clipe e anexe à lista de saída.
5. Defina o latente de movimento = final (últimos num_motion_frames) do clipe recém-gerado.
6. Repita para N clipes, depois concatene todos.
Alguns números de produção
Teste padrão: uma única imagem de referência e 3 prompts, gerando ~15s de saída (3 clipes × 5s):
| Métrica | Valor |
|---|---|
| Duração gerada | 15s (3 clipes) |
| Tempo de inferência por clipe | ~14s (TurboWan fp8, GPU única) |
| Tempo total de inferência | ~42s |
| Consistência do assunto | Boa |
Um exemplo prático: Aventura do Gato
Para tornar o comportamento entre clipes concreto, executamos um caso de 15 segundos com uma referência e três tomadas. O prompt de estilo fixou um visual Pixar com iluminação quente; o personagem era um gatinho malhado laranja com olhos grandes e curiosos; as três tomadas levaram-no do parapeito da janela para a calçada, até encontrar um golden retriever, cada uma com sua própria direção de câmera.

Clipe 1 (0–5s): o gatinho laranja estilo Pixar no parapeito da janela, com a câmera recuando lentamente de um close-up. O estilo e o personagem permanecem estáveis entre os quadros.

Clipe 2 (5–10s) na fronteira de transição: a aparência do gatinho corresponde ao Clipe 1, então ele vira e muda a postura ao pular para baixo. O latente de movimento carregou o estado do movimento através da fronteira.

Clipe 3 (10–15s): um golden retriever é introduzido e a cena transita para uma fronteira interno/externo. O estilo Pixar do gatinho permanece estável nos três clipes.
Métricas agregadas para a execução:
| Métrica | Valor |
|---|---|
| Duração total | 15s (3 clipes × 5s) |
| Quadros totais | 240 quadros (16fps) |
| Tempo total de inferência | 33s (TurboWan, GPU única) |
| Taxa tempo-por-vídeo | 2.2 s/s |
| Consistência do assunto | Gatinho laranja Pixar estável durante todo o vídeo |
| Descontinuidade na fronteira | Sem cortes bruscos óbvios |
Isso é um vídeo de 15 segundos em 33 segundos em uma única GPU, com consistência de assunto entre os clipes — bem dentro da espera de ≤ 60s que definimos como nossa meta. Em um conjunto de teste interno de 14 casos, 9 casos retornaram sem problemas óbvios (taxa de aprovação de 64%).
A observação honesta final é que, na geração de vídeo, velocidade, duração e qualidade são três cantos de um triângulo de ferro. Nenhuma abordagem única hoje lidera nos três ao mesmo tempo. O trabalho interessante está em escolher de qual canto você pode abrir mão, considerando o hardware de hoje e seu orçamento de treinamento. O SVI abre mão de um pouco de duração e um pouco de qualidade nas fronteiras — e, em troca, entregamos vídeo longo com fidelidade de classe Wan2.2, em uma única GPU, hoje.






