
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Utforska de Ledande Modellerna
Wan-2.6 Image-to-image
Supports image editing and mixed text and image output to meet diverse generation and integration needs.
Wan-2.6 Image-to-video
A speed-optimized image-to-video option that prioritizes lower latency while retaining strong visual fidelity. Ideal for iteration, batch generation, and prompt testing.
Wan-2.6 Video-to-video
A speed-optimized video-to-video option that prioritizes lower latency while retaining strong visual fidelity. Ideal for iteration, batch generation, and prompt testing.
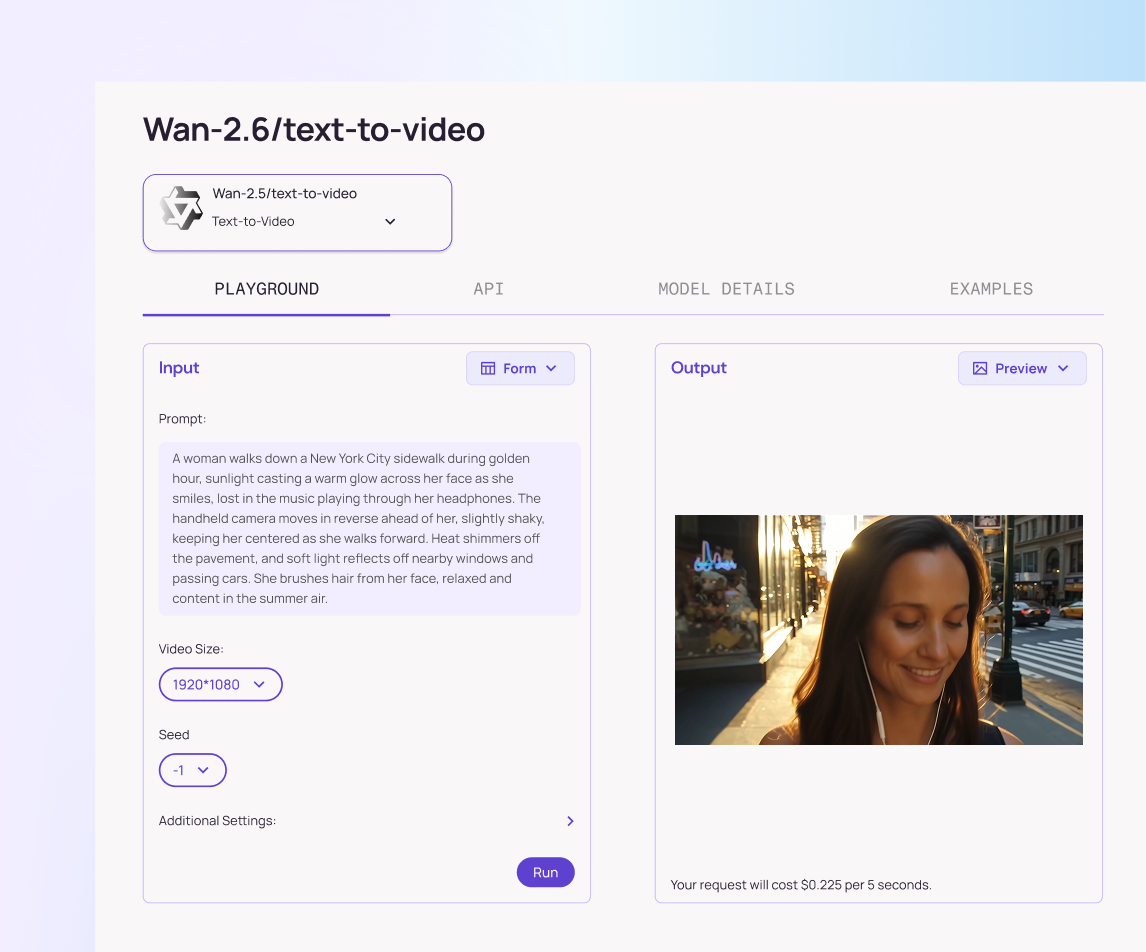
Wan-2.6 Text-to-video
A speed-optimized text-to-video option that prioritizes lower latency while retaining strong visual fidelity. Ideal for iteration, batch generation, and prompt testing.
Wan-2.6 Text-to-image
Generates images based on text, supports various artistic styles and realistic photographic effects, and meets diverse creative needs.
Vad Som Utmärker Sig - Wan2.6 Video Models

Native A/V Sync
Generates perfectly aligned visuals and sound for an immediately usable result.

Fluid, Realistic Motion
Delivers natural movement, smooth camera paths, and cinematic pacing.

Extended Clip Duration
Creates up to 15-second videos for richer storytelling.

Scalable Model Variants
Chooses between an efficient 5B model or a powerful 14B model.

Flexible Prompt Inputs
Understands Chinese, English, and other languages natively.
Precision Lip-Sync
Provides an advanced lip-sync engine aligns mouth movements.
Vad Du Kan Göra - Wan2.6 Video Models
Generate cinematic clips up to 15 seconds length at 480p, 720p, or 1080p resolutions.
Sync visuals and audio in one pass — lip-sync, dialogue, sound effects and background music come together automatically.
Animate a single image or key frame into smooth, temporally consistent motion while preserving character with image-to-video.
Create full assets from one place—generate both still images and audio that match your video for end-to-end content production.
Iterate quickly in the Atlas Playground with adjustable clip length, guidance strength, and motion settings.
Varför Använda Wan2.6 Video Models på Atlas Cloud
Att kombinera de avancerade Wan2.6 Video Models-modellerna med Atlas Clouds GPU-accelererade plattform ger oöverträffad prestanda, skalbarhet och utvecklarupplevelse.
Synced by design. Wan 2.6 generates video with native audio-visual sync, precise lip-sync, and cinematic motion in every shot.
Prestanda & flexibilitet
Låg Latens:
GPU-optimerad inferens för realtidsresonemang.
Enhetligt API:
Kör Wan2.6 Video Models, GPT, Gemini och DeepSeek med en integration.
Transparent Prissättning:
Förutsägbar fakturering per token med serverlösa alternativ.
Företag & Skala
Utvecklarupplevelse:
SDK:er, analys, finjusteringsverktyg och mallar.
Tillförlitlighet:
99.99% drifttid, RBAC och efterlevnadsredo loggning.
Säkerhet & Efterlevnad:
SOC 2 Type II, HIPAA-anpassning, datasuveränitet i USA.
Utforska Fler Familjer
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.

Endast på Atlas Cloud.

