
ChatGPT API for Frontier GPT 5.6 Reasoning
ChatGPT API på Atlas Cloud samlar OpenAI:s senaste GPT 5.6-familj i en enda integration, från Sol för avancerat frontier-resonemang, till Terra för välförankrade produktionsarbetslaster och Luna för naturliga samtal och innehållsgenerering. Kör varje modell via en enda OpenAI-kompatibel nyckel, räkna med drifttid i produktionsklass och betala transparenta pay-as-you-go-priser som börjar på $1 per miljon indatatokens. Börja bygga i dag.
Utforska de Ledande Modellerna
Atlas Cloud förser dig med de senaste branschledande kreativa modellerna.
Välj rätt ChatGPT API-modell: alla endpoints jämförda
Fem endpoints för textgenerering, från frontier-reasoning till prisvärd konversation, alla levererade via en OpenAI-kompatibel nyckel med transparent pay-as-you-go-prissättning.
| Modalitet | Beskrivning |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Byggd för frontier AI-arbetslaster omvandlar GPT 5.6 Sol komplexa textprompter till djupa resultat med resonemang i flera steg för ambitiös problemlösning. Standardpriset är $5 per miljon input tokens och $30 per miljon output tokens, vilket gör den till flaggskeppsvalet när svarskvalitet väger tyngre än kostnad. |
| GPT 5.6 Terra API (Text to Text) | Behöver du en pålitlig standardmodell för produktion? GPT 5.6 Terra omvandlar prompter till välgrundad, praktisk text för verkliga arbetsflöden och analyspipelines för $2.50 input och $15 output per miljon tokens. Team använder den i kundnära applikationer där konsekvens är viktigare än experimentellt djup. |
| GPT 5.6 Luna API (Text to Text) | Skicka konversations- och kreativ trafik till GPT 5.6 Luna, en textmodell optimerad för naturlig dialog, innehållsgenerering och personliga AI-upplevelser. Med $1 input och $6 output per miljon tokens är den den mest ekonomiska ingångspunkten i denna ChatGPT API-serie och passar väl för chattprodukter och storskalig copygenerering. |
| GPT 5.4 API (Text to Text) | GPT 5.4 bearbetar textinstruktioner till tillförlitlig kod, längre innehåll och strukturerade problemlösningsresultat med hög träffsäkerhet. Som en avancerad multimodal modell till sin utformning hamnar den på mellannivåpris med $2.50 input och $15 output per miljon tokens, ett praktiskt val för kodningsassistenter och innehållsplattformar. |
| GPT 5.5 API (Text to Text) | När svåra problem motiverar premiumkostnad levererar GPT 5.5 avancerat resonemang, kodning och innehållsgenerering från en enda text-endpoint. Med ett pris på $5 input och $30 output per miljon tokens riktar den sig till komplexa arbetslaster med höga krav på tillförlitlighet, som agentorkestrering och teknisk analys. |
ChatGPT API: GPT 5.x-nivåer och öppna vikter
Få tillgång till hela GPT 5.x-utbudet och den öppenviktade GPT OSS 120B via en enda ChatGPT API, finjustera resonemangsinsatsen från low till xhigh, kombinera text, bilder och filer i ett enda anrop och anropa inbyggda verktyg med livewebbsökning med en OpenAI-kompatibel nyckel.
Text, bilder och filer i ett enda ChatGPT API-anrop
En enda ChatGPT API-begäran kan kombinera vanlig text, bild-URL:er och dokumentfiler i ett meddelande. Det eliminerar separata OCR- eller vision-tjänster, så att du kan sammanfatta skannade avtal eller läsa skärmbilder i ett enda steg.
Instruktionsföljsamhet i ChatGPT API
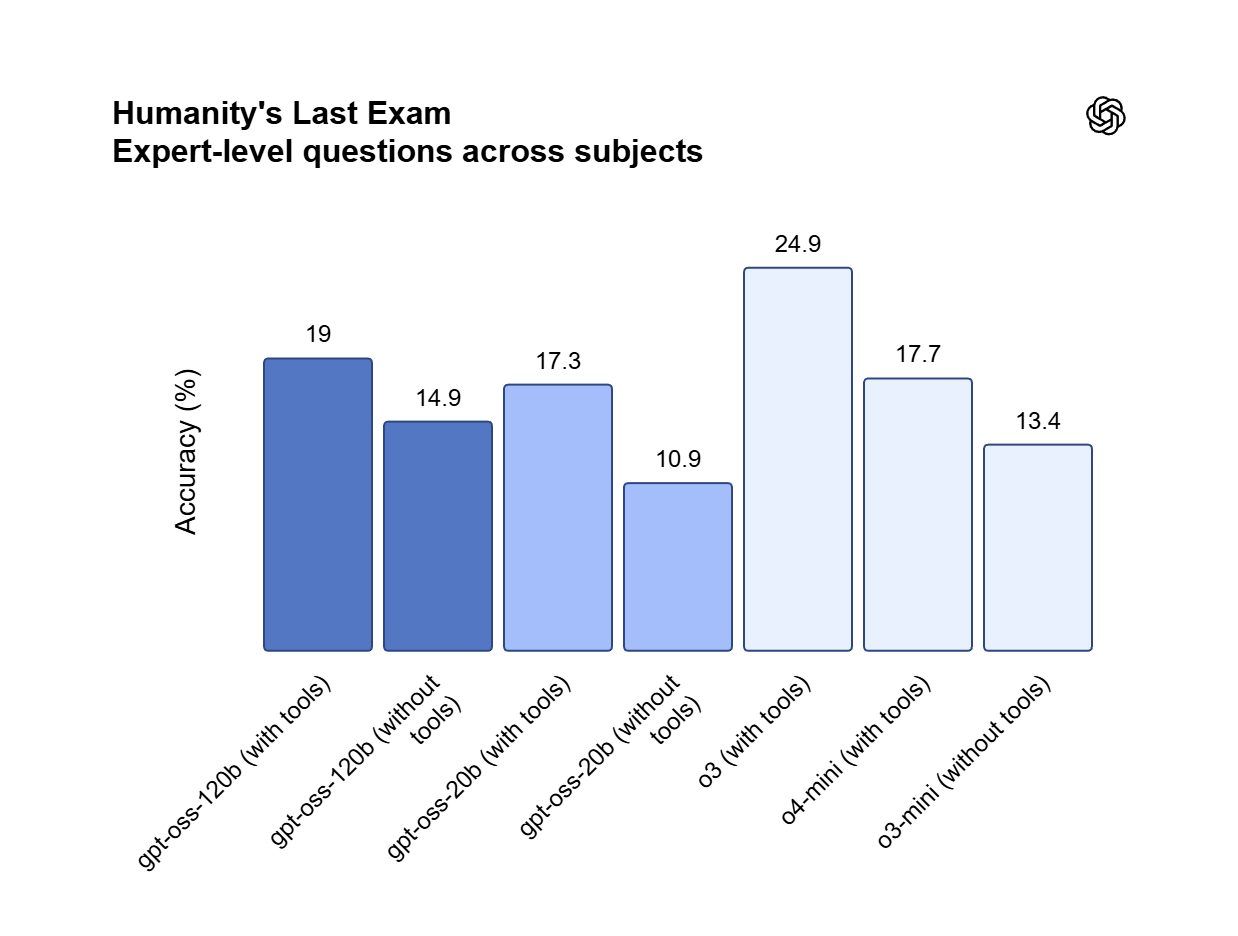
GPT OSS 120B följer skiktade systemprompter och håller format, begränsningar och ton stabila mellan outputs utan drift. Den tillförlitligheten passar autonoma agenter, strukturerad extrahering och produktionspipelines där output måste följa reglerna.
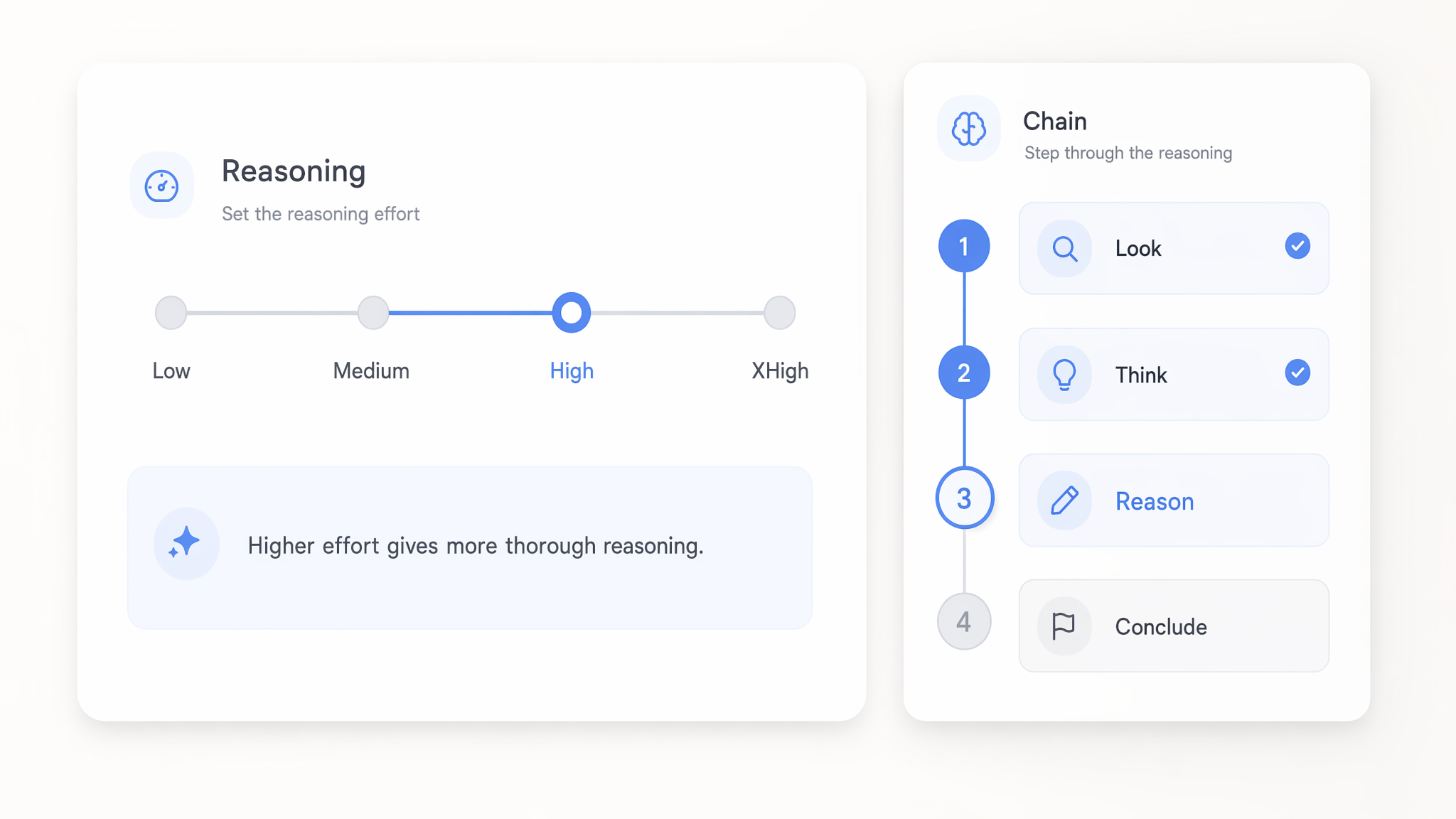
Ställ in resonemangsinsats från Low till xHigh
Ange resonemangsinsats för GPT 5.x-modeller var som helst från low upp till xhigh för att styra hur djupt de tänker innan de svarar. Låga inställningar besvarar enkla anrop snabbt och billigt, medan xhigh lägger mer beräkning på svår logik i flera steg.
Apache 2.0-vikter som du äger fullt ut
GPT OSS 120B distribueras under Apache 2.0-licensen och tillåter kommersiell användning samt privat finjustering på en enda 80GB GPU. Kör den on-premises för att behålla proprietära data internt och helt undvika avgifter per token.

Fem GPT-nivåer, en ChatGPT API
En enda ChatGPT API levererar hela GPT 5.x-utbudet, prissatt från Luna på $1 till Sol på $5 per miljon input tokens. Matcha varje anrop mot den nivå som motsvarar dess kostnads- och intelligenskrav, utan endpoint-ändringar.
Resonemang optimerat för Vibecoding
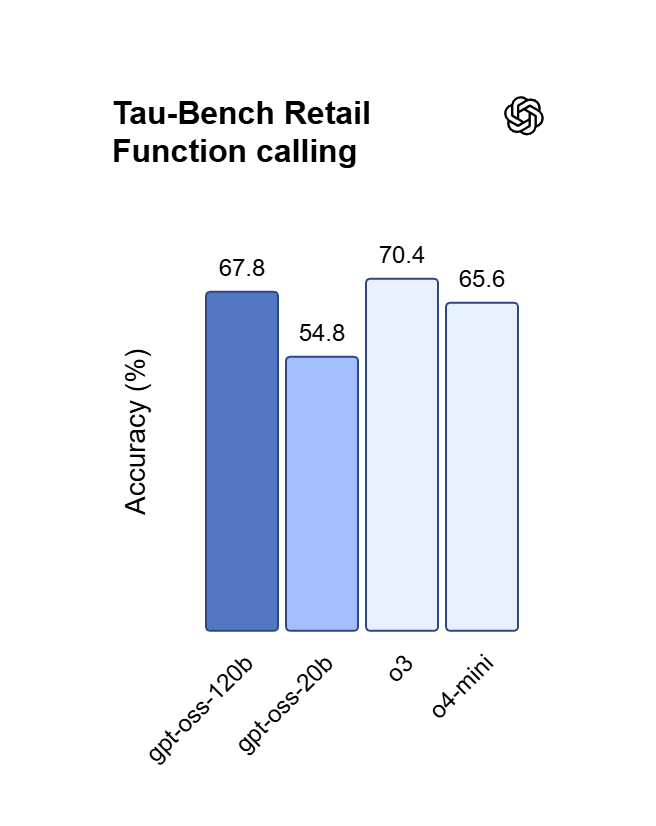
Nästan paritet med OpenAI o4-mini gör att GPT OSS 120B kan hantera kodsyntes i flera steg och matematiska bevis. Omvandla idéer på vanligt språk till fungerande webbappar, felsök nästlad logik och orkestrera komplexa flöden för uppgiftsschemaläggning.

Funktionsanrop med livewebbsökning
GPT 5.x-modeller stöder funktionsanrop med automatiskt verktygsval samt en inbyggd webbsökning som hämtar aktuella resultat. Strömma svar som server-sent events medan prompt caching sänker GPT 5.6 Sol cached input till $0.5 per miljon tokens.
En prompt, tre utmanare: ChatGPT API sida vid sida
Vi gav exakt samma bygginstruktion till modeller via ChatGPT API och två rivaliserande flaggskepp, och renderade sedan varje rått HTML-svar helt orört så att du kan jämföra resonemangsdjup, kodkvalitet och designkänsla sida vid sida.
Bygg en enda fristående HTML-fil (endast inline CSS och JavaScript — absolut inga externa bibliotek, CDNs, ramverk, typsnitt eller bild-URL:er) som öppnas direkt i valfri modern webbläsare och kör en levande, självväxande simulator av ett ekosystem i ett glasväxthus, helt renderad som platt Canvas/SVG-vektorillustration. Scenen ska fylla hela viewporten och föreställa ett kupolformat viktorianskt växthus: en böjd glaskupol löper över överdelen som inramande element, med rutor ritade som genomskinliga jadegröna polygoner med mjuka spegelblänk och tunna spröjslinjer, och en remsa mörk odlingsjord längs nederkanten. Den visuella riktningen är ren vektorillustration — blad och stjälkar ritade med skarpa nervlinjer och halvtransparenta lagerfyllningar, med en palett förankrad i dimmig salviagrön och mossbrun, med bärnstensfärgat solljus och jadeglas-accenter; ingen fotorealism, inga gradienter som texturer, håll det grafiskt och handillustrerat i känslan. Kärninteraktion: när användaren klickar någonstans på jorden planteras ett frö på den platsen, och växten växer i realtid med ett faktiskt L-system — implementera en rekursiv omskrivningsgrammatik (axiom plus produktionsregler med förgreningsklamrar och slumpad vinkel-/längdjitter per instans så att inga två växter blir identiska) och animera härledningen så att grenar sträcks ut, delar sig och vecklar ut blad gradvis under några sekunder i stället för att dyka upp helt färdiga. Tropiska ormbunkar och klätterrankor ska fototropiskt böja sig och krulla mot en dragbar sol: rendera en glödande bärnstensfärgad solskiva som användaren kan greppa och dra var som helst på himlen, och varje växande spets måste kontinuerligt rikta om sin tillväxtriktning mot solens aktuella position så att det syns tydligt hur hela trädgården lutar och klättrar när solen dras. Groddplantor ska vecklas ut med en easing-animation, och kondensdroppar ska bildas på glaset och långsamt glida nedåt i en loop. Driv allt med en dag-natt-cykel kopplad till solens position: omgivningsljuset och himlens färgsköljning ska glida mjukt längs en varm guld- till sval blågradient, solens läge ska styra riktningen och längden på mjuka växtskuggor som faller över golvet samt de drivande ljusfläckarna över glaset, och i skymningen ska eldflugor tona in som små pulserande ljuspunkter som driver bland bladverket. Kompositionen ska stråla med växtlighet från basen uppåt mot mitten, innesluten av kupolens båge. Använd requestAnimationFrame för en kontinuerlig, stillsamt andande animationsloop; håll prestandan jämn även med många växter på skärmen samtidigt. Inkludera subtila, diskreta kontroller (t.ex. en slider eller en automatiskt frammatande toggle för tid på dygnet, samt en återställ-/rensa-knapp) utformade för att matcha den illustrerade estetiken, plus en rad med tips som säger åt användaren att klicka på jorden för att plantera och dra solen för att styra tillväxten. Gör den responsiv för alla fönsterstorlekar, och låt den känslomässiga tonen vara lugn, stilla och levande — det första morgonljuset som faller in på snedden medan späda skott öppnar sig tillsammans. Detta är en generativ simulering, inte ett spel eller en dashboard: prioritera den genuina rekursiva tillväxtalgoritmen, animationsloopen och fysiken för ljus/skugga/fototropism.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Bygg en komplett HTML-sida i en enda fil med en interaktiv global dashboard för startup-finansiering, med fiktiva men internt konsekventa data för 8 branschsektorer över 5 år. All CSS och JavaScript måste vara inline, helt utan externa beroenden, inga chart libraries, inga CDNs, inga bilder. Rendera tre handkodade visualiseringar på canvas eller SVG: ett animerat stapeldiagram som sorteras om med easing när användaren väljer år via en slider, ett linjediagram med hover-tooltips som visar exakta värden och en vertikal följeguide, samt ett donut chart vars segment expanderar vid hover med en spring animation. Inkludera ett mörkt modernt UI med en accentpalett från violett till teal, animerade sifferräknare i fyra KPI-statkort, en rad sektorfilter med toggle chips som omedelbart uppdaterar alla diagram, och en växling mellan ljust och mörkt tema med mjuka färgövergångar. Layouten måste vara responsiv, kollapsa till en enda kolumn under 768px, och varje interaktion måste svara i realtid utan sidomladdningar.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Alla arbetsbelastningar som ChatGPT API kan driva
Från agentisk kodning och strukturerad extrahering till grundad supportchatt och innehåll i stora volymer dirigerar ChatGPT API på Atlas Cloud varje jobb till rätt GPT 5.6-nivå via en OpenAI-kompatibel nyckel.

Lansera agentiska kodningsverktyg med ChatGPT API
Dirigera komplexa omstruktureringar och kodsyntes över flera filer till GPT 5.6 Sol, familjens nivå för djupresonemang byggd för avancerade ingenjörsarbetsbelastningar. Team som bygger kodningscopiloter, automatiserade granskningsbotar och testgeneratorer får produktionsklassad logik.

Varumärkesanpassad innehållsgenerering i stor skala
GPT 5.6 Luna, familjens kreativa nivå, skriver utkast till blogginlägg, produktbeskrivningar och lokaliserad text med naturlig ton och personligt anpassat resultat. Innehållsteam och e-handelsplattformar producerar stora volymer text utan att offra varumärkesrösten.

Driv supportassistenter med ChatGPT API
Behöver du en chattbot som håller sig till manus? GPT 5.6 Terra levererar tillförlitliga, grundade svar byggda för konversation i produktion, så att supportteam och SaaS-produkter kan automatisera ärenden och avlasta återkommande frågor på ett tillförlitligt sätt.

Kunskapssystem med retrieval-augmented generation
Mata in hela policymanualer eller forskningsarkiv i en modell med lång kontext och få grundade svar med källtrogenhet. Juridiska, medicinska och interna sökteam får en tillförlitlig motor för retrieval-augmented frågebesvarande.

Strukturerad dataextrahering via ChatGPT API
Röriga fakturor, e-postmeddelanden och PDF:er omvandlas till ren JSON som nedströms system kan lita på. Tillförlitlig instruktionsföljning håller scheman intakta och betjänar datapipelines, CRM-automatisering och analysarbetsflöden som inte tål avvikelser.

Matcha varje uppgift med rätt modellnivå
När budget och latens spelar roll kan du växla mellan Sol, Terra och Luna via en OpenAI-kompatibel nyckel. Startups och indieutvecklare prototypar snabbt med betala-per-användning-prissättning och skalar sedan samma integration till produktion.
| Modell | Kontext | Maximal utdata | Indata | Positionering |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Text | Högeffektiv resonerande LLM |
| GLM-5 | 202.75K | 202.75K | Text | Flaggskeppsgrundmodell |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Allmän flaggskeppsmodell |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA agentisk kodning |
Hur man använder ChatGPT på Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Skapa ett Atlas Cloud-konto
Registrera dig på atlascloud.ai och slutför verifieringen. Nya användare får gratis krediter för att utforska plattformen och testa modeller.
Varför Använda ChatGPT på Atlas Cloud
Att kombinera de avancerade ChatGPT-modellerna med Atlas Clouds GPU-accelererade plattform ger oöverträffad prestanda, skalbarhet och utvecklarupplevelse.
Prestanda & flexibilitet
Låg Latens:
GPU-optimerad inferens för realtidsresonemang.
Enhetligt API:
Kör ChatGPT, GPT, Gemini och DeepSeek med en integration.
Transparent Prissättning:
Förutsägbar fakturering per token med serverlösa alternativ.
Företag & Skala
Utvecklarupplevelse:
SDK:er, analys, finjusteringsverktyg och mallar.
Tillförlitlighet:
99.99% drifttid, RBAC och efterlevnadsredo loggning.
Säkerhet & Efterlevnad:
SOC 2 Type II, HIPAA-anpassning, datasuveränitet i USA.
ChatGPT API: utvecklarfrågor besvarade
ChatGPT API låter utvecklare skicka prompts till OpenAI:s GPT-modeller och ta emot completions programmatiskt i stället för via chattgränssnittet. På Atlas Cloud når du hela GPT 5.6-utbudet, tillsammans med GPT 5.4 och GPT 5.5, via en enda OpenAI-kompatibel endpoint. Varje anrop debiteras per token med transparent pay-as-you-go-prissättning, så du betalar bara för det du genererar.
Fem modeller täcker spannet från djup resoneringsförmåga till vardaglig chatt. GPT 5.6 Sol är avsedd för ambitiös problemlösning och frontier-arbetslaster, GPT 5.6 Terra hanterar tillförlitliga produktionsflöden och GPT 5.6 Luna är optimerad för naturliga samtal och innehållsgenerering. GPT 5.4 och GPT 5.5 tillför multimodalt resonerande och kodning för team som vill ha beprövad allroundprestanda.
Generera en API-nyckel, peka din base URL mot https://api.atlascloud.ai/v1 och ange model ID, till exempel openai/gpt-5.6-terra. Eftersom ChatGPT API här är helt OpenAI-kompatibelt fungerar befintlig OpenAI SDK-kod efter att du bara har bytt base URL och nyckel. Det finns ingen väntelista och ingen prenumeration, och nya releaser kommer med Day-0 access, så du kan skicka din första begäran samma dag.
Prissättningen skalar med den modell du väljer. GPT 5.6 Luna är mest ekonomisk med $1 per miljon input tokens och $6 per miljon output tokens, GPT 5.6 Terra kostar $2.5 respektive $15, och GPT 5.6 Sol ligger på $5 respektive $30. Prompt caching sänker kostnaden för upprepad input, och debiteringen är fortsatt pay-as-you-go så att du bara debiteras för de tokens du använder.
Ja. Endpointen följer formatet OpenAI Chat Completions, så officiella OpenAI SDK:er, LangChain och de flesta OpenAI-kompatibla bibliotek fungerar när du har bytt base URL och nyckel. Det innebär att en befintlig ChatGPT API-integration kan flyttas över utan att du behöver skriva om din begärandelogik.
Streaming och function calling fungerar båda oförändrat jämfört med OpenAI:s implementation, så du sätter stream till true för token-för-token-output och skickar med en tools-array för att trigga funktionsanrop. Strukturerade JSON-svar följer samma OpenAI-kompatibla begärandeformat, vilket gör agentorkestrering och dataextraktionspipelines förutsägbara.
Dessa modeller accepterar stora prompts för arbetsflöden med långa dokument och hela kodbaser. Prissättningen är nivåindelad vid gränsen 272,000 tokens, med en standardnivå för prompts under den och en andra nivå för prompts som överstiger 272,000 tokens. Du kan därför mata in omfattande kontext i en enda begäran och veta exakt hur prisnivån ändras när prompten växer.
Matcha modellen mot uppgiften. Välj GPT 5.6 Sol när du behöver frontier-resonemang och ambitiös problemlösning, GPT 5.6 Terra för grundad analys i produktionsklass och GPT 5.6 Luna för konversationella eller kreativa uppgifter där kostnaden är viktigast. GPT 5.4 och GPT 5.5 förblir starka multimodala alternativ för kodning och allmänt resonerande.
Atlas Cloud kör ChatGPT API på hanterad infrastruktur som skalar med din trafik, så du slipper GPU-provisionering och nodorkestrering vid egen drift. Nya modellversioner släpps med Day-0 access, så att du håller dig uppdaterad utan migreringsarbete. Om dina behov växer täcker samma OpenAI-kompatibla nyckel varje modell i familjen, så skalning innebär aldrig en ny integration.
Utforska Fler Familjer
Seedance 2.0
Seedance 2.0 API ger dig produktionsåtkomst till ByteDances multimodala videomodell — quad-modala inmatningar (text, bild, video, ljud) och ett branschledande "Universal Reference"-system som låser komposition, kamerarörelser och karaktärers handlingar mellan tagningar. Integrera kontroll på regissörsnivå med ett enda API-anrop, ett fast pris på 0,09 $/s, omedelbar nyckel och ingen väntelista — med stöd av upptid och efterlevnad i företagsklass. Seedance 2.0 Native 4K är nu live!
Grok Imagine
Grok Imagine API ger utvecklare xAI:s bild-, video- och ljudgenerering i en och samma svit. Det producerar bilder i upp till 2K med flerspråkig textrendering, plus video på upp till 15 sekunder med inbyggt, synkroniserat ljud och referensbaserad redigering. På Atlas Cloud körs alla Grok Imagine-lägen med en enda nyckel, så att du kan växla mellan bild, video och ljud utan separata inställningar, från 0,02 USD per bild och 0,05 USD per sekund.
Gemini Omni Flash
Gemini Omni API tar Google DeepMinds multimodala modell för videogenerering och redigering, presenterad på Google I/O 2026, till din stack. Gemini Omni förenar Geminis resonemangsmotor med generativa medier och tar emot valfri blandning av text, bilder, video och ljud för att skapa konsekventa, kunskapsförankrade resultat. Förfina resultaten genom naturlig konversation – byt ut objekt, skriv om scener och skifta stil medan fysik, karaktärer och kontinuitet förblir intakta. Atlas Cloud erbjuder hela Gemini Omni Flash-utbudet – text-till-video, bild-till-video med upp till 7 referensbilder och referens-till-video – via ett enhetligt API med transparent prissättning per sekund från $0.112 och utan abonnemang. Börja bygga i dag.
GPT Image 2
GPT Image 2 API ger utvecklare tillgång till OpenAI:s senaste bildmodell, uppföljaren till GPT Image 1.5. Den genererar och redigerar bilder med exakt textåtergivning i latinska och CJK-tecken, plus en stark komposition för affischer, mockups och infografik. På Atlas Cloud når du den via ett enhetligt API tillsammans med över 300 modeller, med gratis krediter, 99,99 % upptid och utan krav på OpenAI-organisationsverifiering.
Googles mest kraftfulla kreativa modeller är alla tillgängliga på Atlas Cloud. Veo 3.1 levererar filmisk videogenerering, Nano Banana 2 driver skapandet av högupplösta bilder, och Gemini tillför multimodal intelligens till varje arbetsflöde. Få tillgång till hela Googles modellsvit via en enda API key med Day-0-tillgänglighet och pay-as-you-go-prissättning.
Seedance 2.0 Mini
Seedance 2.0 Mini tar ByteDances multimodala videogenerering till arbetsflöden där hastighet och kostnad är avgörande. Det levererar kärnfunktionerna i Seedance 2.0 med ett lättare fotavtryck – snabbare generering, lägre kostnad per video och samma API-integration som du redan använder. För team som kör pipelines med hög volym eller gör prototyper i stor skala är Mini den praktiska standarden.
ByteDance
Från filmisk videogenerering till skapande av högupplösta bilder, ByteDances kraftfullaste modeller är live på Atlas Cloud. Kör Seedance och Seedream i stor skala med de lägsta inferenspriserna och noll infrastrukturkostnader.
Alibaba
Atlas Cloud samlar Alibabas hela modellutbud under ett enda API: Qwen för språk- och bilduppgifter, Wan för videogenerering upp till 1080p. Få tillgång till varje modell med betala-för-användning (pay-as-you-go) helt utan abonnemang. Alibaba API är tillgängligt via en enda bas-URL (base URL) med din befintliga OpenAI-kompatibla klient.
OpenAI
Atlas Cloud ger dig tillgång till hela utbudet av OpenAI API, från GPT Image 2 för bildgenerering till Sora 2 för video. Varje modell är tillgänglig via betala-för-användning (pay-as-you-go) utan månatliga bindningstider. Integrera med ett enda byte av bas-URL med hjälp av det OpenAI-kompatibla API:et.
xAI
Bygg kompletta bild- och videopipelines med hjälp av xAI API på Atlas Cloud. Generera i 2K, redigera med referensbilder och animera bilder till ljudsynkroniserade klipp.
Kwaivgi
Kwaivgi API till 15 % under standardpriset. Atlas Cloud ger Day-0-åtkomst till nya Kling-versioner med pay-as-you-go-prissättning och utan platsbegränsningar. Ett konto, en nyckel, varje Kling-modell från standard- till masternivå.
Seedream 5.0 Pro
Seedream 5.0 Pro API ger utvecklare ByteDances kontrollerbara bildredigeringsmodell på Atlas Cloud. Den placerar redigeringar exakt med ankare och koordinater, separerar bilder i redigerbara lager, slår samman flera referenser och matchar exakta färger och material, med flerspråkig text i 2K och 3K. På Atlas Cloud når du den via en enda nyckel!


