Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API tar Google DeepMinds multimodala modell för videogenerering och redigering, presenterad på Google I/O 2026, till din stack. Gemini Omni förenar Geminis resonemangsmotor med generativa medier och tar emot valfri blandning av text, bilder, video och ljud för att skapa konsekventa, kunskapsförankrade resultat. Förfina resultaten genom naturlig konversation – byt ut objekt, skriv om scener och skifta stil medan fysik, karaktärer och kontinuitet förblir intakta. Atlas Cloud erbjuder hela Gemini Omni Flash-utbudet – text-till-video, bild-till-video med upp till 7 referensbilder och referens-till-video – via ett enhetligt API med transparent prissättning per sekund från $0.112 och utan abonnemang. Börja bygga i dag.
Utforska de Ledande Modellerna
Atlas Cloud förser dig med de senaste branschledande kreativa modellerna.







Fyra sätt att generera med Gemini Omni Flash API
Välj den Gemini Omni Flash API-slutpunkt som passar uppgiften, från text-till-video och bild-till-video till referensdriven generering och konversationsbaserad redigering.
| Modalitet | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Har du bara en text-prompt? Gemini Omni Flash Text-to-Video API förvandlar den till ett 720p-klipp med synkroniserat ljud i ett enda steg, och följer resonemangsdriven regi för scen, rörelse och kamera för klipp på upp till 10 sekunder. |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video API animerar en stillbild till rörelse och förankrar källan som startbild. Med naturliga rörelser och synkroniserat ljud väcker den produktbilder, porträtt och koncept till liv i 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Styr en generering med upp till sju referensbilder och tre korta videoklipp med hjälp av Gemini Omni Flash Reference-to-Video API. Den håller karaktär, stil och scen konsekvent genom hela klippet, perfekt för varumärkes- och serieinnehåll. |
| Gemini Omni Flash Video Edit API | När ett klipp behöver ändras tillämpar Gemini Omni Flash Video Edit API instruktioner på naturligt språk via ett tillståndsbaserat (stateful) Interactions API. Det byter ut element, justerar belysningen och ändrar stil på scener samtidigt som resten av materialet hålls intakt över olika interaktionsomgångar. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
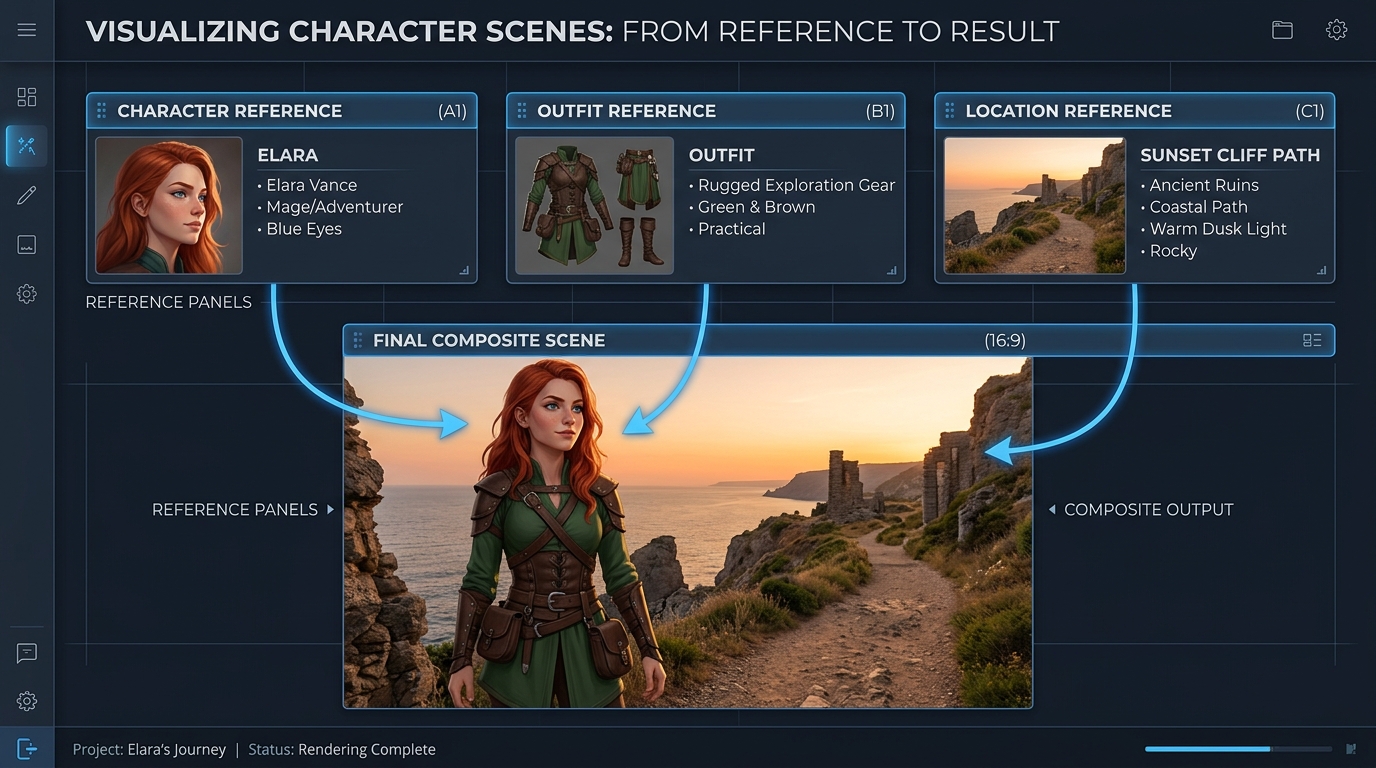
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Hur Gemini Omni Flash API står sig i jämförelse
Se hur modeller från olika leverantörer står sig — jämför prestanda, priser och unika styrkor för ett välgrundat beslut.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Redigering av färdig video genom konversation | Yes | Ja, tillståndsbevarande | Text, bild, video, audio |
| Veo 3.1 | Cinematiska klipp med scenutökning | Yes | No | Text, bild, referens |
| Seedance 2.0 | Referensstyrd video av toppkvalitet | Yes | No | Text, bild, video, ljud |
| Kling 3.0 | Multi-shot-berättande med AI-regissör | Yes | No | Text, bild, referens |
Hur man använder Gemini Omni Flash på Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Skapa ett Atlas Cloud-konto
Registrera dig på atlascloud.ai och slutför verifieringen. Nya användare får gratis krediter för att utforska plattformen och testa modeller.
Varför Använda Gemini Omni Flash på Atlas Cloud
Att kombinera de avancerade Gemini Omni Flash-modellerna med Atlas Clouds GPU-accelererade plattform ger oöverträffad prestanda, skalbarhet och utvecklarupplevelse.
Prestanda & flexibilitet
Låg Latens:
GPU-optimerad inferens för realtidsresonemang.
Enhetligt API:
Kör Gemini Omni Flash, GPT, Gemini och DeepSeek med en integration.
Transparent Prissättning:
Förutsägbar fakturering per token med serverlösa alternativ.
Företag & Skala
Utvecklarupplevelse:
SDK:er, analys, finjusteringsverktyg och mallar.
Tillförlitlighet:
99.99% drifttid, RBAC och efterlevnadsredo loggning.
Säkerhet & Efterlevnad:
SOC 2 Type II, HIPAA-anpassning, datasuveränitet i USA.
Vanliga frågor om Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Utforska Fler Familjer
Seedance 2.0
Seedance 2.0 API ger dig produktionsåtkomst till ByteDances multimodala videomodell — quad-modala inmatningar (text, bild, video, ljud) och ett branschledande "Universal Reference"-system som låser komposition, kamerarörelser och karaktärers handlingar mellan tagningar. Integrera kontroll på regissörsnivå med ett enda API-anrop, ett fast pris på 0,09 $/s, omedelbar nyckel och ingen väntelista — med stöd av upptid och efterlevnad i företagsklass. Seedance 2.0 Native 4K är nu live!
Grok Imagine
Grok Imagine API ger utvecklare xAI:s bild-, video- och ljudgenerering i en och samma svit. Det producerar bilder i upp till 2K med flerspråkig textrendering, plus video på upp till 15 sekunder med inbyggt, synkroniserat ljud och referensbaserad redigering. På Atlas Cloud körs alla Grok Imagine-lägen med en enda nyckel, så att du kan växla mellan bild, video och ljud utan separata inställningar, från 0,02 USD per bild och 0,05 USD per sekund.
Gemini Omni Flash
Gemini Omni API tar Google DeepMinds multimodala modell för videogenerering och redigering, presenterad på Google I/O 2026, till din stack. Gemini Omni förenar Geminis resonemangsmotor med generativa medier och tar emot valfri blandning av text, bilder, video och ljud för att skapa konsekventa, kunskapsförankrade resultat. Förfina resultaten genom naturlig konversation – byt ut objekt, skriv om scener och skifta stil medan fysik, karaktärer och kontinuitet förblir intakta. Atlas Cloud erbjuder hela Gemini Omni Flash-utbudet – text-till-video, bild-till-video med upp till 7 referensbilder och referens-till-video – via ett enhetligt API med transparent prissättning per sekund från $0.112 och utan abonnemang. Börja bygga i dag.
GPT Image 2
GPT Image 2 API ger utvecklare tillgång till OpenAI:s senaste bildmodell, uppföljaren till GPT Image 1.5. Den genererar och redigerar bilder med exakt textåtergivning i latinska och CJK-tecken, plus en stark komposition för affischer, mockups och infografik. På Atlas Cloud når du den via ett enhetligt API tillsammans med över 300 modeller, med gratis krediter, 99,99 % upptid och utan krav på OpenAI-organisationsverifiering.
Googles mest kraftfulla kreativa modeller är alla tillgängliga på Atlas Cloud. Veo 3.1 levererar filmisk videogenerering, Nano Banana 2 driver skapandet av högupplösta bilder, och Gemini tillför multimodal intelligens till varje arbetsflöde. Få tillgång till hela Googles modellsvit via en enda API key med Day-0-tillgänglighet och pay-as-you-go-prissättning.
Seedance 2.0 Mini
Seedance 2.0 Mini tar ByteDances multimodala videogenerering till arbetsflöden där hastighet och kostnad är avgörande. Det levererar kärnfunktionerna i Seedance 2.0 med ett lättare fotavtryck – snabbare generering, lägre kostnad per video och samma API-integration som du redan använder. För team som kör pipelines med hög volym eller gör prototyper i stor skala är Mini den praktiska standarden.
ByteDance
Från filmisk videogenerering till skapande av högupplösta bilder, ByteDances kraftfullaste modeller är live på Atlas Cloud. Kör Seedance och Seedream i stor skala med de lägsta inferenspriserna och noll infrastrukturkostnader.
Alibaba
Atlas Cloud samlar Alibabas hela modellutbud under ett enda API: Qwen för språk- och bilduppgifter, Wan för videogenerering upp till 1080p. Få tillgång till varje modell med betala-för-användning (pay-as-you-go) helt utan abonnemang. Alibaba API är tillgängligt via en enda bas-URL (base URL) med din befintliga OpenAI-kompatibla klient.
OpenAI
Atlas Cloud ger dig tillgång till hela utbudet av OpenAI API, från GPT Image 2 för bildgenerering till Sora 2 för video. Varje modell är tillgänglig via betala-för-användning (pay-as-you-go) utan månatliga bindningstider. Integrera med ett enda byte av bas-URL med hjälp av det OpenAI-kompatibla API:et.
xAI
Bygg kompletta bild- och videopipelines med hjälp av xAI API på Atlas Cloud. Generera i 2K, redigera med referensbilder och animera bilder till ljudsynkroniserade klipp.
Kwaivgi
Kwaivgi API till 15 % under standardpriset. Atlas Cloud ger Day-0-åtkomst till nya Kling-versioner med pay-as-you-go-prissättning och utan platsbegränsningar. Ett konto, en nyckel, varje Kling-modell från standard- till masternivå.
Seedream 5.0 Pro
Seedream 5.0 Pro API ger utvecklare ByteDances kontrollerbara bildredigeringsmodell på Atlas Cloud. Den placerar redigeringar exakt med ankare och koordinater, separerar bilder i redigerbara lager, slår samman flera referenser och matchar exakta färger och material, med flerspråkig text i 2K och 3K. På Atlas Cloud når du den via en enda nyckel!


