Google 在 I/O 2026 大會上推出了 Gemini Omni——這是一款透過自然語言對話即可進行影片編輯的多模態模型,無需使用時間軸或關鍵影格。網路上瘋傳的展示影片(泡泡雕塑、液態鏡面、小提琴手)證明了一個真正的典範轉移:這不僅是「文字生成影片」,而是「文字編輯現有影片」(text-to-edit-the-video-you-already-have)。這就是影片創作領域的「iPhone 相機時刻」。值得注意的是,語音、音訊編輯以及 Pro 進階版功能目前尚未開放,這是官方刻意的安排。
凌晨 1 點。你已經花了四個小時編輯一段 30 秒的短片。專案檔裡堆疊了 47 個圖層。你拖曳關鍵影格拖到手腕痠痛。客戶剛傳來訊息:「可以把光線調整得溫暖一點嗎?」而身為專業人士的你,正準備全部重來。
過去這就是工作常態。那確實「曾經」是工作常態。
2026 年 5 月 19 日,Google 悄然終結了這個時代。
在 I/O 2026 大會上,該公司發表了 Gemini Omni——這是一款多模態模型,它將影片編輯變成了我們大多數人認為還需要十年才能實現的樣子:一場正常的對話。
核心承諾:不再需要「操作」影片,只需與它「對話」
整個產品的訴求可以用一句話總結:你不再需要「操作」影片,你只需告訴它你想要什麼。
Google 的官方公告直言不諱地指出:「每個指令都建立在前一個指令之上。你的角色保持一致,物理規則依然成立,場景也會記得之前發生的事情。」
這不是 Veo 的簡單更新。Google DeepMind 的產品頁面給出了更精準的定位:「你可以將 Gemini Omni 想像成影片版的 Nano Banana。」去年,Nano Banana 讓照片編輯變得像輸入文字一樣簡單,現在 Omni 將同樣的能力帶到了動態影像上。
該系列的首款模型——Gemini Omni Flash——目前已在 Gemini 應用程式、Google Flow 和 YouTube Shorts 中正式啟用。
這句話將重塑你對整個類別的認知:在 TechCrunch 與 DeepMind 團隊的訪談中,研究工程師 Gabe Barth-Maron 將人們使用 Omni 創作的內容描述為「個性化迷因」(personalized memes)。
這就是核心論點。影片創作已從「工藝」轉向了「表達」——就像當年 iPhone 淘汰 DSLR 相機,攝影技術所經歷的遷徙一樣。
引爆 Twitter 的展示影片
行銷文案看再多也比不上實際演示。目前網路上有三段展示影片最受矚目:
- 泡泡雕塑:餵給 Omni 一段石雕影片,輸入指令「把雕塑變成泡泡做的」,下一次渲染的成品保留了原有的構圖、光影與陰影,但雕塑變成了會折射環境光的透明肥皂材質。
- 液態鏡面:當手觸摸鏡子時,輸入指令要求 Omni「讓鏡面像液體一樣美麗地漣漪,並將人的手臂轉變為反射鏡面材質」。據 Windows Report 記錄,漣漪在物理層面上向外擴散,手臂上的鍍鉻反射了真實的室內環境。
- 鏈式編輯:Google 的小提琴手演示展示了單一主體在三輪編輯後的變化:舞台場景 → 轉移至戶外環境 → 切換為過肩鏡頭。三次編輯,同一人,面部表情、姿勢、握琴動作完全一致。

這不是簡單的文字轉影片,而是「文字編輯現有影片」。兩者的區別雖然細微,卻徹底改變了一切。
為什麼創作者們為之瘋狂
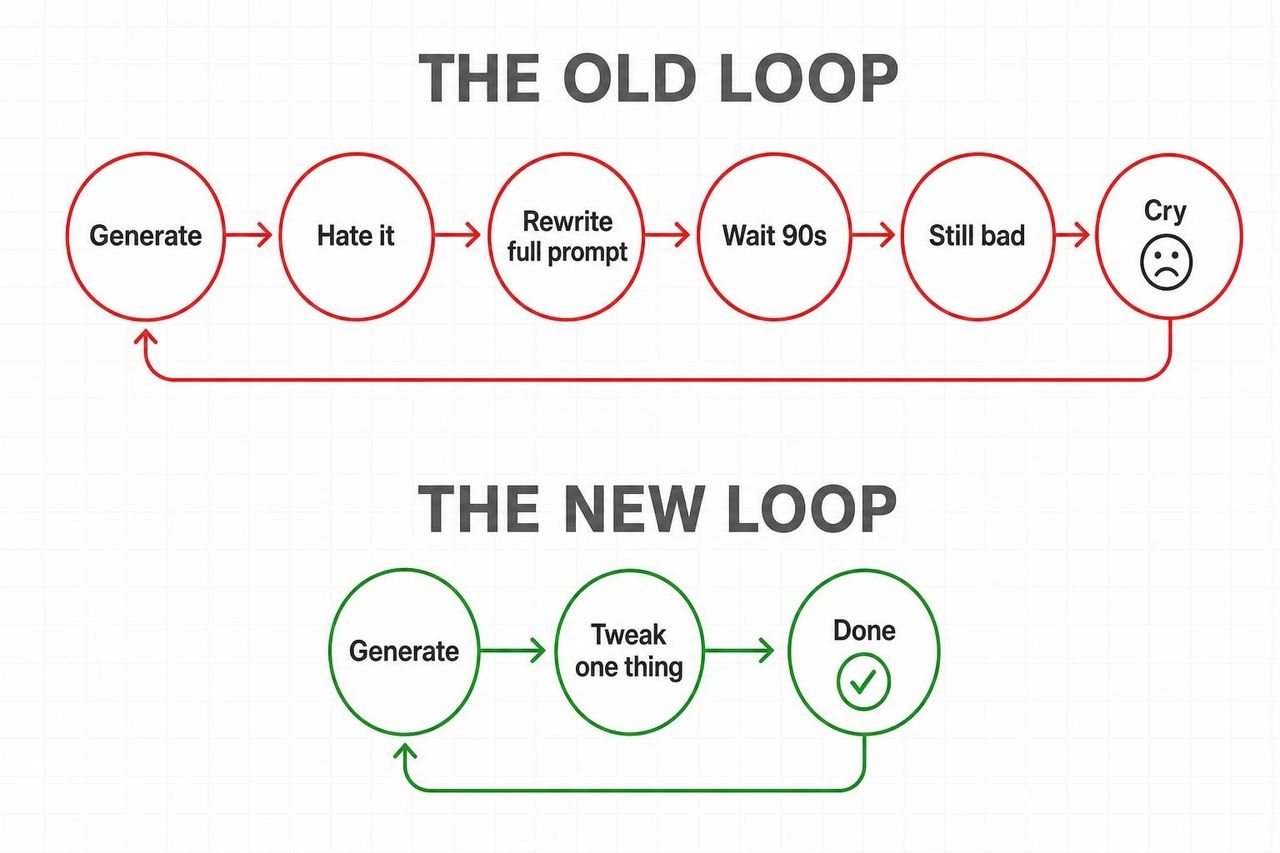
這項發布之所以比其他模型更能引起轟動,原因很簡單:Omni 打破了生成式影片中最糟糕的循環。
舊循環:生成 → 不滿意 → 重寫整段提示詞 → 等待 90 秒 → 效果依然不佳 → 重複過程。
新循環:生成 → 「把光線改為黃金時刻」 → 完成 → 「現在減慢鏡頭推近的速度」 → 完成。
Android Central 的評論毫不留情:「Gemini Omni 可能會讓傳統的影片編輯軟體感覺像古董一樣。」TechRadar 也表達了類似但更細膩的觀點,並指出動作現在可以在不同編輯步驟中保持連貫,而不必在每次輸入提示詞後重置。
開發者們已經行動起來。在開發者論壇 V2EX 上,一位中國開發者在發布當天就進行了測試,並寫道:「基於對話修改影片內部的物體——這種互動方式顯然是未來的方向。速度和一致性超出了我的預期。」在 X 上,免疫學家兼 AI 評論員 Dr. Derya Unutmaz 在主題演講後幾分鐘內發文:「哇!Google DeepMind 剛剛發布了一個名為 Gemini Omni 的驚人 AI 多模態模型。影片看起來太棒了!必須趕快試試!」
當 AI 界的意見領袖與開發者論壇在幾小時內達成共識時,這就標誌著一個真正的轉折點已經出現。
Google 悄悄保留的界線
如果只寫讚美之詞而不提及風險,是不負責任的。

Engadget 指出了最顯而易見的問題:「Veo 3.1 和其他影片生成 App 的主要問題在於影片常有『恐怖谷』效應,且常被終端使用者詬病。最終成品的品質能否符合 Google 高調的宣傳,還有待觀察。」
DataCamp 的實測也發現了一個真實的物理錯誤——一台投石機將拋射物向後方發射。評論者還指出,該模型尚未公布基準測試分數,因此第三方驗證還需數週時間。
此外,官方還有一個刻意的遺漏:不支援現有影片內部的語音與音訊編輯。正如 Google 自己承認的,公司「仍在測試這項功能,並設法了解如何負責任地將其提供給使用者」。翻譯過來就是:深偽(Deepfake)風險確實存在,他們將最危險的功能暫時隱藏了起來。
每個 Omni 生成的片段都會帶有 Google 的隱形 SynthID 水印以及 C2PA 內容憑證——在 Gemini 應用程式、Chrome 和 Google 搜尋中皆可驗證內容來源。這不再是選配,而是現在的必要門檻。
這對你的工作流程意味著什麼
去掉行銷炒作,你將獲得一些真正嶄新的東西:
- 工具即對話:沒有時間軸,沒有圖層,沒有關鍵影格。只有文字。
- 回饋循環大幅縮短:過去需要 90 秒才能完成的重生成,現在變成 10 秒的微調。
- 專業門檻降低:當任何有品味的人都能像回覆 Slack 訊息一樣快速迭代影片時,瓶頸就從「執行能力」轉移到了「創意想法」。
對於行銷團隊、獨立創作者、教育工作者以及任何曾經需要「快速製作 10 秒短片」的人來說——這就是轉折點。不是因為模型已經完美,而是因為這種互動模式終於對了。
未來的影片編輯不再需要軟體,只需要詞彙。
用於影片生產的一站式 API
儘管 Google 正將 Gemini Omni Flash 推廣至 Gemini 應用程式和 Google Flow 給一般使用者,但希望將同款多模態影片引擎嵌入自身工作流程的開發者和產品團隊,需要一個穩定且可預測的 API 層。
Atlas Cloud 透過與 OpenAI 相容的統一 API 提供 Gemini Omni Flash,同時支援 300 多種圖像、影片和 LLM 模型——讓你無需處理多個供應商帳號、計費入口網站或 SDK,即可整合 Google 原生的多模態模型。
Gemini Omni Flash 的兩種版本現已在 Atlas Cloud 上線:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| 版本 | 最佳用途 | 輸入格式 | 解析度 | 長度 | 起步價格 |
|---|---|---|---|---|---|
| Gemini Omni Flash 文字轉影片 (開發者) | 純提示詞驅動的電影級生成 | 文字(最多 20,000 字元) | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash 圖片轉影片 (開發者) | 根據真實參考圖生成主體一致的影片 | 文字 + 最多 7 張參考圖 | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
快速入門——用 5 行程式碼生成 Gemini Omni Flash 影片:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API 會立即回傳一個預測 ID——透過查詢 /api/v1/model/prediction/{id} 即可獲得渲染後的 MP4 網址。完整的架構說明、7 種語言的程式碼範例以及無程式碼操作介面(Playground)皆可在上述連結的模型頁面中查看。
給正在開發相關應用者的一點提醒
每個像這樣的模型發表背後,都有一個尷尬的現實:下一季,又會有三個標榜「世界最強影片模型」的公告出現。每個模型都有不同的 SDK、不同的認證流程、不同的速率限制以及不同的定價模式。你的團隊將會花上一週時間來適應每一個新模型,然後再花一週時間淘汰上一個。
這正是 Atlas Cloud 要解決的問題。
我們為開發者提供一個可存取 300 多種模型的終端點——涵蓋所有主流基礎模型、頂尖開源版本,以及在圖像、影片和推理領域快速迭代的專家模型。只需一行程式碼即可切換模型。無需重新整合 SDK,即可進行並排基準測試。今天熱門的模型上線後,下個月隨時可切換到最新的熱門模型,完全無需重寫程式碼。
因為 AI 領域目前唯一確定的事,就是排行榜每週都在變。請以此為基礎進行開發。






