
GLM API for Autonomous Task Execution
GLM 是 Zhipu AI 旗下 Z.ai 的旗艦 LLM 系列,而 GLM API 涵蓋從具備代理能力的 GLM-5 到高效率的 357B MoE GLM-4.6。這些模型專精於自主任務執行、複雜代理編排,以及生產級程式開發。在 Atlas Cloud 上,單一統一端點即可讓你在 Day-0 存取整個 GLM 系列,並享有按用量計費與可靠的生產環境正常運行時間。立即開始建置。
探索領先模型
Atlas Cloud 為您提供最新的行業領先創意模型。
GLM API 模型比較:從 GLM-4.6 到 GLM-5.2
依照你的工作負載與預算,選擇最合適的 endpoint。
| 模態 | 描述 |
|---|---|
| GLM-5.2 | GLM-5.2 是專為 agent 導向場景打造的模型,可將自然語言提示與 tool-call 上下文轉換為結構化推理、function calls 與自主任務執行。它針對模型必須自行規劃、行動並反覆迭代的複雜問題進行調校。當你要建構自主 agents 與長週期、使用工具的工作流程時,可優先選用;價格為每百萬 input tokens $1.4、每百萬 output tokens $4.4。 |
| GLM-5.1 | 將程式開發任務或多步驟問題交給 GLM-5.1,它能產出強大的程式設計結果,並提供穩定的逐步執行能力。作為 Z.AI 最新旗艦模型,它也帶來更自然的對話體驗與更精緻的前端美感。適合打造複雜 web apps 與 agent pipelines 的團隊使用,價格為每百萬 input tokens $1.4、每百萬 output tokens $4.4。 |
| GLM-5v Turbo | GLM-5v Turbo 可將文字提示快速轉換為 completions,同時保留旗艦模型強化後的程式設計能力與穩定的多步驟執行表現。這個 turbo 版本優先降低延遲,適合互動式、高吞吐量產品,且不犧牲對話的流暢與精緻度。當回應速度最重要時可選用;價格為每百萬 input tokens $1.2、每百萬 output tokens $4。 |
| GLM-5 Turbo | GLM-5 Turbo 讓文字輸入後能高速產出 completions,是針對延遲最佳化的旗艦模型,具備強化的程式設計能力與可靠的多步驟推理。它能維持自然回覆與乾淨的前端生成品質,同時提升即時使用情境下的吞吐量。非常適合聊天介面與快速 agent 迴圈,計費為每百萬 input tokens $1.2、每百萬 output tokens $4。 |
| GLM-5 | GLM-5 接收文字指令,並生成程式碼、推理鏈與對話回覆,是 Z.AI 的核心旗艦版本。其主要升級聚焦於更強的程式設計能力,以及在複雜 agent 任務中更穩定的多步驟執行。它是全端開發與日常推理的均衡選擇,價格為每百萬 tokens:input $1、output $3.2。 |
| GLM-4.7 | 向 GLM-4.7 提出程式開發或 agent 編排需求,它能以可靠的多步驟執行與自然對話回應。這款旗艦級模型結合強化的程式設計能力與精緻的前端輸出,價格也更易於負擔。適合對成本敏感的生產工作負載,計費為每百萬 input tokens $0.6、每百萬 output tokens $2.2。 |
| GLM-4.6 | GLM-4.6 是 Zhipu AI 推出的 357B-parameter 高效率 Mixture-of-Experts 模型,可將文字提示映射為高品質 completions,並具備強大的吞吐量。其 MoE 設計只會啟用每次請求所需的 experts,讓分析與內容任務的推論保持高效率。可部署於資料分析、投影片草稿與 web content 場景,價格為每百萬 tokens:input $0.6、output $2.2。 |
GLM API 的核心能力
從稀疏 Mixture-of-Experts 核心與 200K-token context,到原生 tool calling 與可切換的 thinking modes,GLM API 將 Z.ai 旗艦級推理與程式碼堆疊整合在單一 OpenAI-compatible endpoint 之後。
大規模稀疏 Mixture-of-Experts
稀疏 Mixture-of-Experts 核心每次查詢只啟用約 40 billion 個參數,並從規模大得多的專家池中調用能力。其結果是在每次呼叫不需承擔 dense-model 成本的情況下,提供深度知識與精準回憶。
內建於 GLM API 的 Agentic Execution
GLM API 內建規劃邏輯,讓 agent 能執行長週期、多步驟任務而不偏離方向。這種穩定性適合自動化軟體開發、研究 pipeline,以及需要在多個步驟中保持一致性的 workflow。
經強化調校的程式碼與推理能力
Reinforcement-learning post-training 讓模型的程式碼生成與演算法推理能力,相較早期 GLM 版本大幅提升。開發者能獲得更可靠的 full-stack 輸出,並在小型邏輯錯誤容易累積放大的場景中,得到更強的結構化問題解決能力。

具備 Sparse Attention 的 200K Context Window
每個模型都能處理 200K tokens 或更長的 context,並支援最高 128K output tokens;sparse attention 讓這種規模保持可負擔。完整 repository、長篇合約與研究簡報都能一次納入視野。
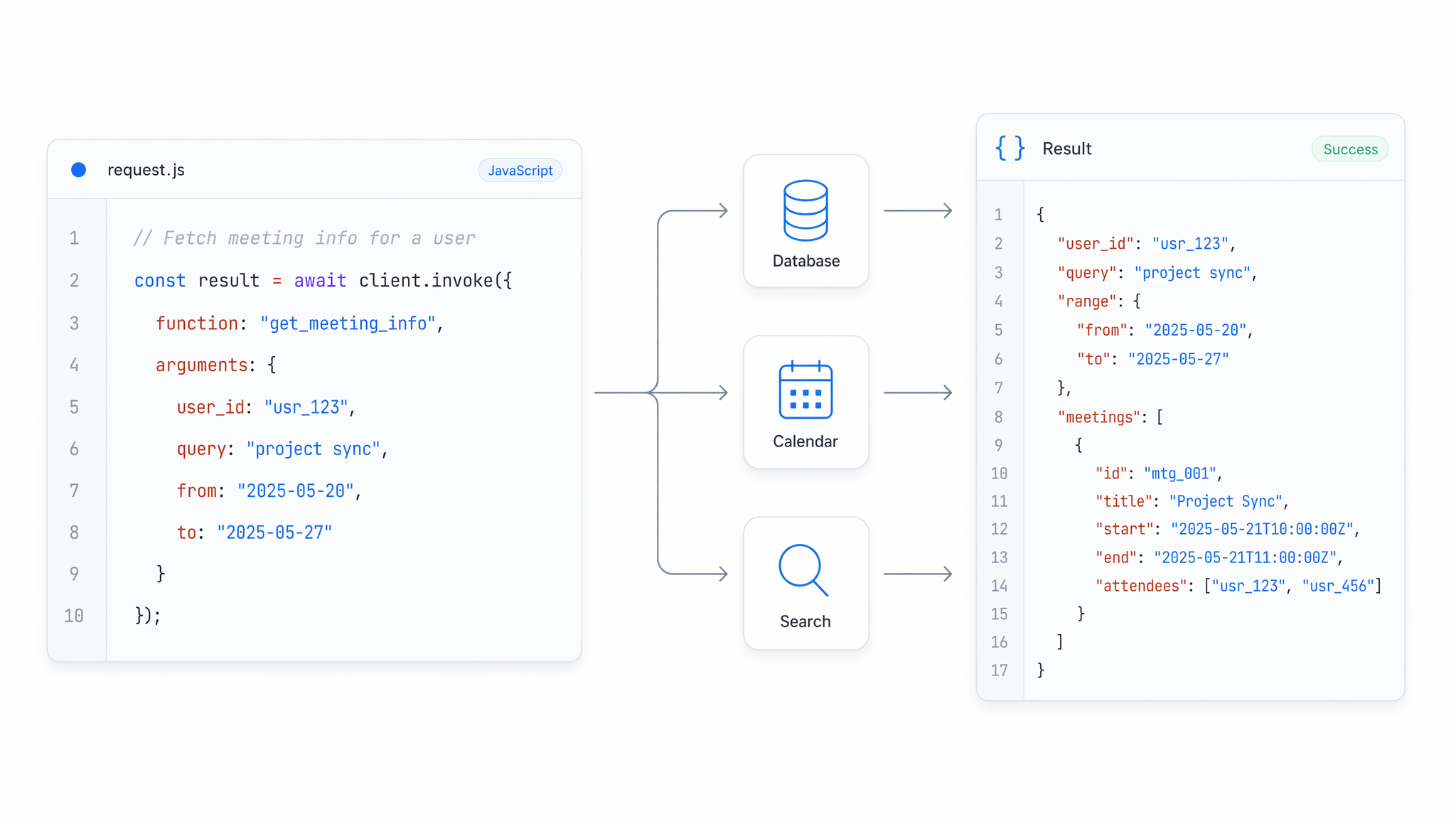
透過 GLM API 進行原生 Tool Calling
透過原生 function calling 與結構化 JSON 輸出,將外部工具與服務接入 GLM API。模型會判斷何時呼叫工具、依你的 schema 格式化參數,並回傳機器可讀的結果。
一把 Key 存取完整 GLM API Lineup
一把 OpenAI-compatible key 即可存取完整 GLM API lineup,從旗艦 GLM-5.2 到 Turbo tiers,以及具成本效益的 GLM-4.6。先在較輕量的 tier 上建立 prototype,再用一行設定推進到 production,並採用 pay-as-you-go pricing。
GLM API 正面對決:一份簡報,三個模型比較
透過 GLM API 發送單一建置請求,觀察 GLM 5.2、DeepSeek V4 Pro 與 GLM 5 如何將相同指令轉化為可運作的互動頁面,讓你一眼衡量前端品質、版面邏輯與互動打磨程度。
產生一個完整、單一檔案、自包含的 HTML 文件(所有 CSS 與 JavaScript 皆內嵌,絕對不可有外部相依性、不可使用 CDNs、不可使用圖片 URL、不可使用外部字型),呈現一個互動式「Aurora Tuning Console」——全視窗 WebGL 體驗,描繪午夜極地天空,極光必須在 GLSL fragment shader 內即時計算,絕不可用 sprites、textures 或 particle stacks 偽造。 核心渲染要求:渲染單一全螢幕 quad,並在 fragment shader 中完成所有視覺工作。北極光必須由分層 fractal value/simplex noise(fbm,4–6 octaves)程序生成,並透過 uniform clock 隨時間流動與扭曲,形成高聳的垂直光幕,會呼吸、漣動、糾結並消散。將極光建模為自發光的體積光暈:沿垂直衰減累積亮度,在每道光幕底部加入柔和 bloom,並在深暗上空散佈微弱漂移的星塵 noise。畫面構圖為極簡低地平線的仰望視角——約 80% 天空,底部有深色剪影山脊與鏡面般靜止的湖面,湖面以柔和漣漪、垂直鏡像的方式反射極光與星星。基礎色盤為近黑的靛藍(深藍紫夜色);極光是唯一高飽和元素——克制、發光、半透明,絕不俗豔。 互動(皆需即時、流暢且反應明確): - 滑鼠在天空中拖曳會像拉動布料一樣「牽引」光幕——將指標位置/速度送入 shader uniforms,讓極光朝游標彎曲、伸展並流動,放開後以溫和慣性緩緩回復。 - 滑鼠滾輪捲動可循環切換「season」,讓極光色帶在 emerald green → magenta → indigo(並返回)之間連續插值,以平滑漸層變化呈現,而不是離散跳變。 - 雙擊會在天空中該位置點燃一顆新星:它會脈衝(sinusoidal brightness),並在湖面投下相符倒影。需支援多顆星同時存在。 - 保留細緻的閒置動畫,讓第一道光幕在載入時彷彿緩慢甦醒並展開——營造安靜、神聖、寒冷且靜止的氛圍。 UI 與打磨:在角落放置一個小巧、優雅、半透明的控制覆層,顯示目前 season/color,以及一行淡淡的操作提示(拖曳/捲動/雙擊),以乾淨現代、冷色調美學設計,並帶有柔和淡入淡出轉場。需完全響應式:在視窗尺寸變更時調整 WebGL canvas 並更新 resolution uniforms,使其填滿任何 viewport,且在高 DPI 螢幕上保持銳利。使用 requestAnimationFrame 以穩定 60fps 為目標。若 WebGL 不可用,需提供優雅的 fallback 訊息。優先重視 noise flow 的數學品質、體積光暈以及互動流暢度——這正是能力較強的模型應該明顯勝過較弱模型之處。
Generated with GLM 5.2 on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GLM 5 on Atlas Cloud
建立一個完整、單一檔案、自包含的 HTML 文件(所有 CSS 與 JavaScript 皆內嵌於同一檔案,完全零外部相依性——不可使用 CDNs、不可使用外部 scripts、不可使用 web fonts、不可使用圖片 URL、不可從網路擷取 SVG assets;所有聲音都用原生 Web Audio API 生成,所有視覺都用 CSS 與 Canvas/DOM 繪製),可直接在任何現代瀏覽器開啟並執行一台可玩的 cyberpunk step-sequencer drum machine,視覺語彙為 1980s synthwave neon。 核心樂器:渲染一個發光的 step matrix,規格為 16 欄 × 6 軌,水平鋪排在螢幕上,每列對應一個聲部——Kick、Snare、Closed Hi-Hat、Open Hi-Hat、Clap 與 Synth Bass。96 個 cells 都是可點擊的 pad;點擊可切換開/關,啟用的 cell 會以高飽和 magenta-to-cyan 光暈亮起,未啟用的 cell 則是在近黑靛藍背景上的昏暗內凹矩形。使用者透過逐欄點亮 cells 來編排節拍。支援按住拖曳在 cells 間塗抹,一次切換多個 cell。 音訊:使用 Web Audio API 即時合成所有鼓聲——kick 為快速振幅衰減的音高滑降 sine,snare 與 clap 為帶 envelope 的濾波白噪音爆發,closed 與 open hi-hats 為 high-passed noise,分別具有短衰減與長衰減,synth bass 則是 detuned saw/square 經 resonant low-pass filter,演奏可選 root note。使用精準的 look-ahead clock 排程 steps(不要用天真的 setInterval timing),讓 loop 在高 tempo 下仍然穩如磐石。播放時持續循環 16-step pattern。 Transport 與控制項固定在底部對稱控制列:大型 Play/Stop 按鈕、BPM dial 或 rotary knob(可拖曳,範圍約 60–200 BPM,預設 120)並有即時數值顯示、master volume fader、各軌 mute 按鈕、Clear 按鈕,以及會產生合理節拍的 Randomize 按鈕。移動中的 playhead——一道垂直光刃——需與音訊完美同步掃過 grid,且它擊中的每個 active cell 都會綻放徑向 ripple pulse 並逐漸淡出。加入即時 oscilloscope/waveform 顯示,將 master output amplitude 視覺化,並隨聲音即時反應。 視覺風格:深靛藍到紫羅蘭的漸層背景,暗到近乎黑色;grid lines 與 UI accents 使用 electric magenta 與 cyan;所有亮度都來自元素自發光與 hit-flash bloom(box-shadow glow、帶有 additive 感的高光),營造深夜地下俱樂部隨 loop 脈動的氛圍。將完整 grid 置中於畫面,保持對稱版面,底部以控制列壓縮空間,並具備響應式設計,讓 grid 在較小 viewport 也能優雅縮放。加入細緻的動畫 scanline 或 chromatic shimmer 增添氣氛,但不可影響可讀性。 互動需求:一切都要即時回應——點擊 pads、拖曳 BPM knob 與 volume fader、切換 mutes、按空白鍵 Play/Stop,以及按數字鍵跳轉 bass root note。狀態(哪些 cells 啟用、BPM、volume、mutes、播放狀態)必須乾淨管理,確保 UI 與音訊永不脫節。頁面上的第一次互動也應解鎖/恢復 AudioContext。優先重視緊密的音訊視覺同步、playhead 與 ripples 的流暢 60fps 動畫,以及開箱即令人滿意、具有音樂性的成果。
Generated with GLM 5.2 on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GLM 5 on Atlas Cloud
開發者如何運用 GLM API
從自主程式碼代理與長期研究,到對話式產品與高量資料分析,GLM API 為開發者提供一個相容 OpenAI 的 endpoint,用於打造可靠、以代理驅動的軟體。

使用 GLM API 打造自主程式碼代理
GLM models 專為自主執行任務而設計,能在多步驟工作流程中規劃、撰寫並改進程式碼,同時不遺失專案脈絡。開發團隊仰賴它來驅動 PR 審查機器人、重構助理與建置流程。

長期研究與工作流程編排
穩定的多步驟推理能力,讓這些 models 能拆解龐雜的研究問題、呼叫外部工具,並在一連串相依動作中維持脈絡。非常適合需要自動化多來源彙整與跨平台作業的分析師與產品團隊。

打造精緻的前端介面
GLM models 能將粗略的 mockup 與純文字描述,轉換成乾淨、響應式且具備良好視覺完成度的介面程式碼。個人創業者與重視設計的開發者,能更快速地交付功能原型與正式環境 UI。

基於 GLM API 的對話式產品
想打造更像真人的助理嗎?GLM API 提供自然的對話體驗,並以穩定推理能力作為支撐,可驅動聊天機器人、客服 copilots 與應用程式內助理,在冗長且分支複雜的對話中仍保持連貫。

工具呼叫後端與函式執行
由於這些 models 是為工具使用而打造,它們能在 agentic systems 中選擇函式、格式化參數,並串接 API 呼叫。工程師可用它將 GLM 接入編排層、RAG pipelines 與 multi-agent stacks。

使用 GLM API 擴展資料分析
運用 GLM API 對大型文件、試算表與報告進行推理,並透過高效率的 Mixture-of-Experts 設計擷取結構化洞察。非常適合需要可靠、高量分析的金融、法律與營運團隊。
GLM API 與競品 LLM:規格與定價矩陣
在 Atlas Cloud 上,依據上下文長度、輸出上限與透明的隨用隨付定價,比較每個 GLM API model 與主流文字 LLM。
| Model | Context Window | Max Output | Input($/1M tokens) | Output($/1M tokens) |
|---|---|---|---|---|
| GLM 5.2 | 1M | 128K | $1.40 | $4.40 |
| GLM 5.1 | 203K | 203K | $1.40 | $4.40 |
| GLM 5 | 203K | 203K | $1.00 | $3.20 |
| GLM 4.7 | 203K | 203K | $0.60 | $2.20 |
| DeepSeek V4 Pro | 1M | 384K | $1.74 | $3.45 |
| Kimi K2.7 Code | 256K | 256K | $0.95 | $4.00 |
| MiniMax M3 | 512K | 512K | $0.60 / $1.20 >512K | $2.40 / $4.80 >512K |
如何在 Atlas Cloud 上使用 GLM
幾分鐘即可上手 — 按照以下簡單步驟,透過 Atlas Cloud 平台整合和部署模型。
建立 Atlas Cloud 帳戶
在 atlascloud.ai 註冊並完成驗證。新用戶可獲得免費額度,用於探索平台和測試模型。
為何在 Atlas Cloud 使用 GLM
將先進的 GLM 模型與 Atlas Cloud 的 GPU 加速平台相結合,提供無與倫比的效能、可擴展性和開發體驗。
效能與靈活性
低延遲:
GPU 最佳化推理,實現即時回應。
統一 API:
一次整合,暢用 GLM、GPT、Gemini 和 DeepSeek。
透明定價:
按 Token 計費,支援 Serverless 模式。
企業與規模
開發者體驗:
SDK、資料分析、微調工具和模板一應俱全。
可靠性:
99.99% 可用性、RBAC 權限控制、合規日誌。
安全與合規:
SOC 2 Type II 認證、HIPAA 合規、美國資料主權。
GLM API:開發者常見問題解答
GLM API 讓開發者能夠存取 Z.ai(Zhipu AI)的 GLM 系列開放權重大型語言模型,包括 GLM-5.2、GLM-5、GLM-4.7 和 GLM-4.6。這些模型專為程式開發、多步驟推理與自主代理任務而設計。在 Atlas Cloud 上,你可以透過單一 OpenAI-compatible endpoint 存取整個系列,並採用隨用隨付計價。
Atlas Cloud 託管目前的 GLM 產品線,包括 GLM-5.2、GLM-5.1、GLM-5、GLM-5 Turbo、GLM-5v Turbo、GLM-4.7 和 GLM-4.6。旗艦版本著重於複雜的 agentic 與程式開發工作,而 Turbo 變體則優先提供更快、低延遲的回應。若要在不同模型之間切換,只需變更請求中的模型識別碼。
註冊 Atlas Cloud、產生一組 API key,並將你現有的 OpenAI-compatible client 指向我們的 endpoint。由於 GLM API 遵循 OpenAI 請求格式,多數整合只需要變更 base URL 和模型名稱,就能開始送出請求。存取方式採隨用隨付,具備透明的每次呼叫計價,且不需訂閱。
計價採隨用隨付,依 token 計費,且不需訂閱。GLM-4.7 和 GLM-4.6 起價為每百萬 input tokens $0.60、每百萬 output tokens $2.20;GLM-5 為 input $1.00、output $3.20;GLM-5.2 為 input $1.40、output $4.40。快取 input 會以較低費率計費,可降低重複上下文的成本。
Atlas Cloud 上的 GLM 模型提供約 200K tokens 的大型 context window,旗艦版本的最大輸出可達約 131K tokens。這樣的容量足以在單一請求中載入完整程式碼庫、長篇文件或延伸的代理歷史。GLM 系列中也有更長上下文的變體,因此請查看各模型頁面以確認其確切限制。
支援。GLM 模型支援 tool 與 function calling,以及 structured JSON output,讓它們能直接整合到需要機器可讀回應的 agentic pipeline 與生產系統中。搭配 OpenAI-compatible 格式,GLM API 能輕鬆接入既有的工具使用工作流程。
這些模型專為程式設計、長程推理與自主代理執行而打造。常見用途包括完整程式碼庫分析、全端原型開發,以及多步驟研究或工作流程自動化。旗艦 GLM-5 系列可處理最具挑戰性的 agentic 工作,而 GLM-4.6 則在日常任務中提供速度與能力的良好平衡。
GLM 的旗艦模型定位為在程式開發與 agentic benchmark 上,能與領先閉源模型競爭的開放權重替代方案。主要的實務吸引力在於成本,因為其 per-token pricing 僅為同級專有模型的一小部分,同時仍維持強大的程式設計表現。對於需要在預算與品質之間取捨的團隊,GLM 以較低費率提供前沿級能力。
可以。Atlas Cloud 透過 OpenAI-compatible endpoint 提供 GLM 模型,因此任何可接受自訂 base URL 和模型名稱的框架或 SDK,都能以最少變更呼叫這些模型。這讓你可以將 GLM 直接放入既有的 tool-calling agents、coding assistants 與 multi-step orchestration pipelines。今天就開始建置。
是。GLM 系列由 Z.ai(Zhipu AI)以寬鬆授權釋出為 open-weight models,因此被廣泛視為領先的 open-source 選項。在 Atlas Cloud 上,你可以取得這些模型的託管式、生產就緒存取能力,無需自行託管或維護基礎架構。
探索更多系列
Seedance 2.0
Seedance 2.0 API 為您提供 ByteDance 多模態影片模型的生產級存取權限——支援四模態輸入(文字、影像、影片、音訊),以及業界領先的「Universal Reference」(通用參考)系統,可在不同鏡頭間鎖定構圖、運鏡與角色動作。只需一次 API 呼叫即可整合導演級控制,固定費率為 $0.09/秒,即時取得金鑰,無需排隊——由企業級正常運行時間與合規性提供保障。Seedance 2.0 原生 4K 現已上線!
Grok Imagine
Grok Imagine API 為開發者提供 xAI 的圖像、影片和音訊生成一站式套件。它可以生成解析度高達 2K 且支援多語言文本渲染的圖像,以及長達 15 秒且帶有原生同步音訊和基於參考圖像編輯功能的影片。在 Atlas Cloud 上,只需一個金鑰即可執行每個 Grok Imagine 模式,因此您可以在圖像、影片和音訊之間無縫切換,無需單獨設定,每張圖像 0.02 美元起,每秒 0.05 美元起。
Gemini Omni Flash
Gemini Omni API 將 Google DeepMind 於 Google I/O 2026 發表的多模態影片生成與編輯模型帶進你的技術棧。Gemini Omni 將 Gemini 的推理引擎與生成式媒體融合,可接受文字、圖片、影片與音訊的任意組合輸入,產生一致且以知識為根據的輸出。透過自然對話持續打磨成果:替換物件、改寫場景、切換風格,同時維持物理規律、角色與畫面連貫性不變。Atlas Cloud 透過單一整合 API 提供完整的 Gemini Omni Flash 系列——文字生成影片、支援最多 7 張參考圖片的圖片生成影片,以及參考圖生成影片——採每秒計費、價格透明,$0.112 起,無需訂閱。立即開始打造。
GPT Image 2
GPT Image 2 API 為開發者提供了訪問 OpenAI 最新圖像模型的途徑,它是 GPT Image 1.5 的繼任者。該模型可生成和編輯圖像,能夠在拉丁和 CJK 文字上實現準確的文本渲染,並在海報、樣機和資訊圖表方面具備強大的排版能力。在 Atlas Cloud 上,您可以透過一個統一的 API 與 300 多個模型一起訪問它,並享受免費額度、99.99% 的正常運行時間,且無需 OpenAI 組織驗證。
Google最強大的創意模型現已在Atlas Cloud上全面可用。Veo 3.1提供電影等級的影片生成,Nano Banana 2支援高保真圖像建立,而Gemini為每個工作流程帶來多模態智慧。透過單一API key即可存取完整的Google模型套件,提供Day-0可用性和隨用隨付(pay-as-you-go)定價。
Seedance 2.0 Mini
Seedance 2.0 Mini 將 ByteDance 的多模態影片生成技術引入到對速度和成本要求極高的工作流程中。它以更輕量的佔用空間提供 Seedance 2.0 的核心能力——更快的生成速度、更低的單支影片成本,並且使用您現有的同款 API 整合。對於運行高吞吐量流水線或進行大規模原型設計的團隊來說,Mini 是最實用的預設選擇。
ByteDance
從電影級影片生成到高保真影像建立,ByteDance 最強大的模型現已在 Atlas Cloud 上線。以最低的推論定價和零基礎設施開銷,大規模執行 Seedance 和 Seedream。
Alibaba
Atlas Cloud 將 Alibaba 的全系模型陣容整合至同一個 API 中:Qwen 適用於語言和圖像任務,Wan 適用於高達 1080p 的影片生成。所有模型均採用按需付費模式,無需訂閱。您可以使用現有的 OpenAI 兼容客戶端,透過單一的 base URL 存取 Alibaba API。
OpenAI
Atlas Cloud 為您提供存取完整 OpenAI API 產品線的權限,從用於圖像生成的 GPT Image 2 到用於影片的 Sora 2。每個模型均採用按需付費模式,無月度消費限制。使用相容 OpenAI 的 API,只需簡單替換基礎 URL 即可輕鬆接入。
xAI
在 Atlas Cloud 上使用 xAI API 建構完整的影像與影片處理管線。以 2K 解析度生成、使用參考影像進行編輯,並將影像動畫化為音訊同步的影片片段。
Kwaivgi
Kwaivgi API 價格低於標準定價 15%。Atlas Cloud 提供對最新 Kling 版本的零日(Day-0)存取權限,採用按需付費定價且無席位限制。一個帳戶,一個金鑰,暢享從標準版到大師版的所有 Kling 模型。
Seedream 5.0 Pro
Seedream 5.0 Pro API 為開發者在 Atlas Cloud 上提供了字節跳動的可控圖像編輯模型。它透過錨點和座標精確定位編輯,將圖像分離為可編輯圖層,融合多個參考,並精準匹配顏色和材質,支援 2K 和 3K 解析度的多語言文本。在 Atlas Cloud 上,您只需一個金鑰即可存取!


