AI 影片中的原生音訊生成已經徹底改變了製作流程。直到最近,使用 AI 生成影片還意味著必須先產出一段無聲素材,然後在額外的步驟中尋找、編輯並同步音訊。這種額外的步驟不僅增加了時間、成本和複雜度,而且結果往往不盡人意。到了 2026 年,三大領先模型現在可以在一次生成中,同步產出影片及其對應的音訊:Google DeepMind 的 Veo 3.1、快手的 Kling 3.0 以及生數科技的 Vidu Q3。
本比較指南將詳細解析每個模型如何處理音訊,包括音質、語言支援、同步精準度、定價及實際應用場景。無論您是開發內容工作流的工程師、大規模製作廣告的行銷人員,還是探索 AI 輔助前期製作的電影製作人,本指南都將協助您為工作流程選擇最適合的音訊模型。
*最後更新:2026 年 2 月 28 日*
查看這些模型的並排比較:
音訊模型總覽
| 功能 | Veo 3.1 | Kling 3.0 | Vidu Q3 |
|---|---|---|---|
| 開發者 | Google DeepMind | 快手 | 生數科技 |
| 原生音訊 | 有 | 有 | 有 |
| 音訊語言 | 以英語為主 | 英語、中文、日語、韓語、西班牙語 | 以英語為主 |
| 唇形同步 | 情境式 | 多語言唇形同步 | 情境式 |
| 音訊類型 | 環境音 + 對話 | 環境音 + 多語言對話 | 環境音 + 對話 |
| 最大時長 | 8 秒 | 10 秒 | 16 秒 |
| 最大解析度 | 720p | 1080p | 1080p |
| Atlas Cloud 價格 | USD 0.09/秒 (快) / USD 0.18/秒 (標準) | USD 0.095/秒 (Pro) | USD 0.06/秒 |
| 每 8 秒片段成本 | USD 0.72 (快) / USD 1.44 (標準) | USD 0.76 | USD 0.48 |
| 最佳音訊優勢 | 環境音景 | 多語言對話 | 影音同步平衡 |
原生音訊在 AI 影片中如何運作
在深入了解各模型之前,了解此處「原生音訊」的含義很有幫助。傳統的 AI 影片模型生成的是無聲影片檔。音訊(無論是環境音、音樂、對話還是音效)都必須使用其他工具單獨生成,或從庫中採購,然後在後期製作中手動與影片同步。
原生音訊模型在創建影片的同一個推理過程中產生音軌。模型讀取文字提示詞,生成視覺畫面,並同時產生與視覺內容情境對齊的音軌。海灘場景會配上海浪聲;說話的人會配上唇形同步的對話;城市街道會配上交通噪音。音訊直接嵌入在輸出檔案中,無需額外的 API 呼叫,也無需後期同步步驟。
這點至關重要,因為:
- 消除了整個製作步驟:團隊不再需要分別尋找、編輯和同步音訊。
- 同步精準度更高:由於音訊和影片是同時生成的,時間對齊比後期強行貼合更自然。
- 成本降低:無需單獨的音訊生成 API、庫存音訊授權或音訊編輯工具。
- 迭代更快:單次 API 呼叫即可產生完整的資產,可直接進行審閱。
Veo 3.1:電影級環境音
音訊能力
Veo 3.1 處理音訊的方式如同音效設計師對待電影拍攝現場。它的強項在於環境音,聽起來就像是與影片同時在現場捕捉到的一樣。輸入「日出時的挪威峽灣」,輸出內容就會包含風聲、水拍打岩石的聲音以及遠處的鳥鳴。輸入「繁忙的東京十字路口」,輸出內容則會提供交通噪音、行人交談聲和行人紅綠燈的信號聲。
該模型會處理提示詞中的音訊情境線索,並生成與視覺環境相符的聲景。這不是隨機噪音疊加在影片上,而是回應場景中特定元素的語境感知生成。
對話處理:Veo 3.1 在收到提示時可以生成口語音訊,但其強項顯然在於環境與氛圍音,而非多語言對話。該模型對英語口語的處理相當不錯,但沒有像 Kling 3.0 那樣具備明確的多語言唇形同步功能。
音質:Veo 3.1 的音訊輸出乾淨,沒有明顯的雜訊或數位噪點。頻率範圍聽起來自然,環境元素融合流暢。在我們的測試中,音質始終與其高水準的電影級影片輸出保持一致。
Veo 3.1 音訊優勢
- 同級最佳的環境聲景,聽起來就像現場錄音
- 音訊輸出乾淨,無雜訊
- 強大的情境感知,音訊元素能精確匹配視覺元素
- 專業級電影品質,價格為 USD 0.09/秒(快)或 USD 0.18/秒(標準)
- 非常適合品牌內容、自然景觀和氛圍感強的作品
Veo 3.1 音訊限制
- 以英語為主,多語言對話能力有限
- 沒有明確的語言選擇參數
- 8 秒的最大時長限制了音訊敘事的複雜度
- 環境音是其強項,對話與口語屬於次要功能
Veo 3.1 程式碼範例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Veo 3.1 搭配音訊豐富的提示詞 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "google/veo3.1/text-to-video", 17 "prompt": "Close-up of a barista pouring steamed milk into a latte, " 18 "espresso machine hissing in the background, soft jazz " 19 "playing in a cozy cafe, warm morning light through windows", 20 "duration": 8, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
Kling 3.0:多語言對話領航者
音訊能力
Kling 3.0 採用了完全不同的音訊處理方式。當 Veo 3.1 在環境聲景中脫穎而出時,Kling 3.0 是圍繞多語言對話生成與唇形同步而構建的。該模型原生支援英語、中文、日語、韓語和西班牙語五種語言的音訊生成,並具備與所生成語音相符的精確嘴部動作。
這不是簡單地將語音合成層疊加在影片上。模型會同時生成角色的臉部運動、嘴型和時間軸,與音軌完美匹配。結果就是角色看起來真的在講提示詞中指定的語言。
對話處理:這是 Kling 3.0 的核心音訊特徵。在提示詞中指定語言,模型就會生成角色講該語言的畫面,並伴隨適當的唇形同步。在測試中,西班牙語提示詞產生了令人信服的結果,嘴部動作自然,語氣起伏到位。日語和韓語的輸出同樣令人印象深刻,且配合了符合文化習慣的肢體語言。
環境音:Kling 3.0 同樣能生成環境音,但這點相對其對話能力而言是次要的。背景音效存在且符合情境,但缺乏 Veo 3.1 那種電影般的聲景深度。
音質:語音清晰自然。在同時包含對話和沉重環境音的複雜場景中,偶爾會出現些許雜訊,但對於以對話為主的內容,其音質已達到生產等級。
Kling 3.0 音訊優勢
- 支援 5 種語言的多語言對話,具備精確的唇形同步
- 符合文化的語音節奏與肢體語言
- 強大的角色焦點音訊,非常適合「大頭照」(talking-head)內容
- 三者中最長的 10 秒時長
- 非常適合多語言行銷與全球化內容
Kling 3.0 音訊限制
- 定價較高,為 USD 0.095/秒 (Pro)
- 環境音質低於 Veo 3.1 的電影標準
- 極其嚴格的內容審核可能會誤標無辜的提示詞
- 語言表現不一,英語與中文表現最強
Kling 3.0 程式碼範例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Kling 3.0 搭配多語言對話提示詞 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 17 "prompt": "A professional female presenter speaking in Spanish, " 18 "looking directly at camera, modern office background, " 19 "warm studio lighting, corporate presentation style", 20 "duration": 10, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
Vidu Q3:平衡型的影音生成
音訊能力
生數科技的 Vidu Q3 定位介於 Veo 3.1 的環境音專長與 Kling 3.0 的對話專長之間。該模型能生成涵蓋環境聲景與基礎對話的同步音訊,為音訊生成提供了一種平衡方案。
對話處理:Vidu Q3 生成的語音具備不錯的唇形同步準確度。它主要以英語為主,沒有 Kling 3.0 的多語言能力。語音輸出清晰自然,儘管還未達到 Kling 3.0 五語言支援那樣的語言深度。
環境音:環境音生成表現稱職且具備情境感知能力。模型會閱讀提示詞中的場景描述並產生適當的背景音。其品質介於 Kling 3.0 的功能性環境音與 Veo 3.1 的電影級聲景之間。
音質:整體音訊輸出乾淨,適合生產使用。Vidu Q3 的優勢在於一致性——音質在不同類型的提示詞中都相當可靠,既不會出現某些專用模型偶有的驚艷表現,也不會出現極大落差。
Vidu Q3 音訊優勢
- 同時涵蓋對話與環境音的平衡方案
- 不同內容類型間保持一致的品質
- 中檔定價,為 USD 0.06/秒
- 對於需要語音與環境音兼顧的團隊來說性價比高
- 乾淨、無雜訊,適合生產環境使用
Vidu Q3 音訊限制
- 以英語為主,缺乏多語言對話能力
- 音質未達 Veo 3.1 的電影級高峰
- 唇形同步準確度低於 Kling 3.0 的多語言標準
- 16 秒最大時長
- 生態系統相較 Veo 與 Kling 較不成熟
Vidu Q3 程式碼範例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Vidu Q3 搭配平衡音訊提示詞 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "shengshu/vidu-q3/text-to-video", 17 "prompt": "A young man unboxing a new smartphone at a desk, " 18 "speaking excitedly about the features, natural room " 19 "lighting, casual vlog style, ambient room sounds", 20 "duration": 8, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
影音並排比較
各類別音訊品質排名
| 類別 | 第 1 名 | 第 2 名 | 第 3 名 |
|---|---|---|---|
| 環境/場景音 | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| 對話 (英語) | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| 多語言語音 | Kling 3.0 | -- | -- |
| 唇形同步精確度 | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| 音效 | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| 整體影音同步 | Veo 3.1 | Kling 3.0 | Vidu Q3 |
| 音訊一致性 | Vidu Q3 | Veo 3.1 | Kling 3.0 |
定價比較
| 模型 | 費用/秒 | 8 秒片段 | 10 秒片段 | 100 片段 (8 秒) |
|---|---|---|---|---|
| Vidu Q3 | USD 0.06 | USD 0.48 | USD 0.60 | USD 48.00 |
| Veo 3.1 Fast | USD 0.09 | USD 0.72 | N/A (上限 8s) | USD 72.00 |
| Kling 3.0 Pro | USD 0.095 | USD 0.76 | USD 0.95 | USD 76.00 |
在大規模生產時,價格差異顯而易見。一個月生產 500 個片段的團隊,使用 Vidu Q3 需支出 USD 240,使用 Veo 3.1 Fast 需 USD 360,而 Kling 3.0 Pro 則需 USD 380。問題在於 Kling 3.0 的多語言對話功能是否值得比 Veo 3.1 的電影環境音或 Vidu Q3 的平衡方案支付更高昂的價格。
時長與解析度
| 模型 | 最大時長 | 最大解析度 | 影格率 |
|---|---|---|---|
| Vidu Q3 | 16 秒 | 1080p | 24fps |
| Kling 3.0 | 10 秒 | 1080p | 30fps |
| Veo 3.1 | 8 秒 | 720p | 24fps |
Vidu Q3 在時長上以 16 秒領先,而 Kling 3.0 在解析度上佔有明顯優勢。對於對話密集的內容,多出來的時間長度意味著更完整的句子和自然的節奏。
如何透過 Atlas Cloud API 存取這些模型
這三款具備音訊能力的影片模型皆可透過單一 Atlas Cloud API 金鑰存取。無需分別維護 Google、快手和生數科技的帳戶。
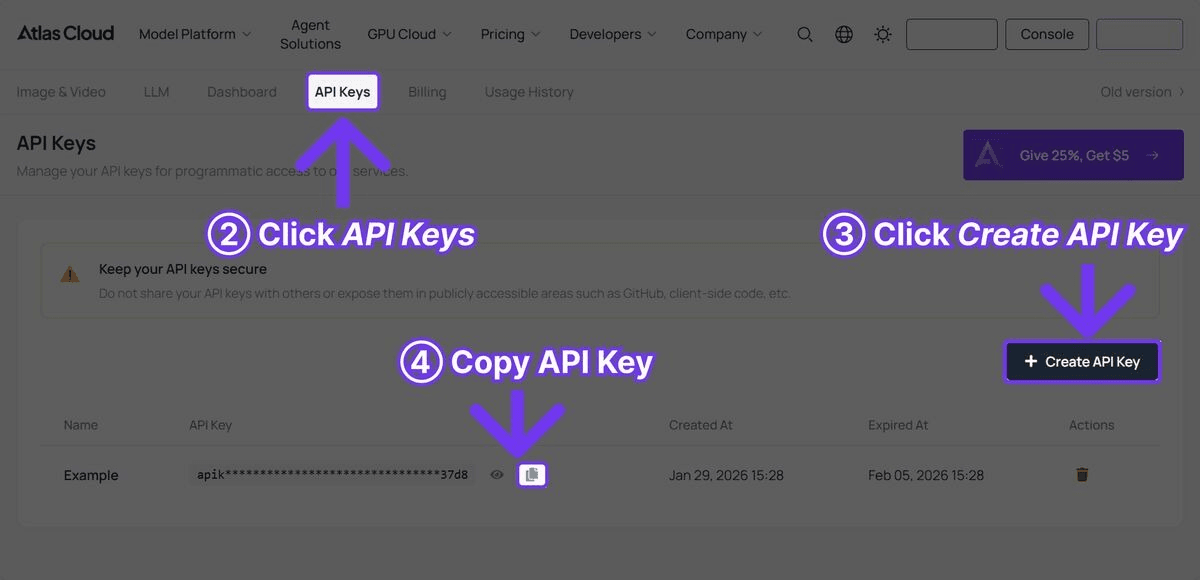
第 1 步:取得您的 API 金鑰
在 Atlas Cloud 註冊並導航至 API Keys 標籤頁。
第 2 步:比較所有三款模型
以下是一個完整的 Python 指令碼,使用相同的提示詞從所有三款模型產生帶有音訊的影片,方便您比較結果:
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7HEADERS = { 8 "Authorization": f"Bearer {API_KEY}", 9 "Content-Type": "application/json" 10} 11 12PROMPT = ("A street musician playing acoustic guitar on a cobblestone " 13 "sidewalk at golden hour, passersby dropping coins, warm natural " 14 "lighting, documentary style") 15 16models = { 17 "Veo 3.1": { 18 "model": "google/veo3.1/text-to-video", 19 "duration": 8 20 }, 21 "Kling 3.0": { 22 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 23 "duration": 10 24 }, 25 "Vidu Q3": { 26 "model": "shengshu/vidu-q3/text-to-video", 27 "duration": 8 28 } 29} 30 31request_ids = {} 32 33for name, config in models.items(): 34 response = requests.post( 35 f"{BASE_URL}/model/generateVideo", 36 headers=HEADERS, 37 json={ 38 "model": config["model"], 39 "prompt": PROMPT, 40 "duration": config["duration"], 41 "resolution": "1080p" 42 } 43 ) 44 result = response.json() 45 request_ids[name] = result["request_id"] 46 print(f"Submitted {name}: {result['request_id']}") 47 48# 輪詢三者狀態 49completed = {} 50while len(completed) < len(request_ids): 51 for name, rid in request_ids.items(): 52 if name in completed: 53 continue 54 status = requests.get( 55 f"{BASE_URL}/model/prediction/{rid}/get", 56 headers={"Authorization": f"Bearer {API_KEY}"} 57 ).json() 58 if status["status"] == "completed": 59 completed[name] = status["output"]["video_url"] 60 print(f"{name} done: {status['output']['video_url']}") 61 time.sleep(5) 62 63print("\nAll videos generated. Compare the audio quality:") 64for name, url in completed.items(): 65 print(f" {name}: {url}") 66```
如何選擇模型
何時選擇 Veo 3.1:
- 內容是氛圍導向或環境導向:自然紀錄片、旅遊內容、品牌電影、房地產導覽——任何環境音重於對話的場景。
- 預算為首要限制:USD 0.09/秒(快)的定價讓 Veo 3.1 成為具備電影品質的實惠選項。每月產出數百個片段的團隊將看到顯著成本節省。
- 電影級品質是優先順序:Veo 3.1 的視覺精緻度與環境音質結合,能產生如同專業製作的內容。
- 無需多語言對話:如果需求是環境氛圍而非對話,Veo 3.1 是明確的選擇。
何時選擇 Kling 3.0:
- 內容需要角色講多種語言:這是 Kling 3.0 的核心賣點。目前沒有其他模型能在此水準上生成具備唇形同步的多語言對話。
- 唇形同步準確度至關重要:對於大頭照影片、解說類內容,或任何角色直接面對鏡頭說話的場景,Kling 3.0 是目前市面上最準確的模型。
- 需要更長的片段與多語言音訊:Kling 3.0 的 10 秒上限與五語言支援提供了 Veo 3.1(8 秒)無法比擬的靈活性。
- 項目目標為全球市場:支援五種語言意味著單一工作流即可生產出適用於英語、中文、日語、韓語和西班牙語市場的內容。
何時選擇 Vidu Q3:
- 需要對話與環境音的平衡:Vidu Q3 能稱職地處理兩者,且不偏廢任何一端,使其成為多功能的選擇。
- 預算有限但有品質要求:USD 0.06/秒,Vidu Q3 是三者中定價最親民的模型,比 Veo 3.1 Fast (USD 0.09) 和 Kling 3.0 Pro (USD 0.095) 都更便宜。
- 一致性重於極致品質:Vidu Q3 在各種提示詞下都能穩定產出好音訊,這對自動化工作流來說很有價值,因為人工審閱在該流程中是不切實際的。
- 項目為純英語且對音訊有中等需求:若要英語對話且具備不錯的環境音,Vidu Q3 是一項穩健的選擇。
音訊提示詞技巧
要從這些模型獲得最佳音訊效果,需要特定的提示技巧。以下策略適用於所有三款模型:
1. 明確指出聲源
模型根據提示詞中的聲音線索生成音訊。您描述得越具體,結果就越好。
- 有效:「雨滴敲擊鐵皮屋頂,遠處雷聲隆隆,窗台上貓咪發出的呼嚕聲」
- 無效:「雨天和貓」
2. 分開描述視覺與音訊
將提示詞結構化,明確分開描述視覺與音訊元素,這有助於模型為兩者賦予適當的權重。
- 有效:「廚師在木製砧板上切菜——菜刀切過芹菜的清脆聲、旁邊鍋中油炸的滋滋聲、廚房通風扇的嗡嗡聲」
- 無效:「廚師在廚房做飯」
3. 為 Kling 3.0 指定對話語言
當使用 Kling 3.0 製作多語言內容時,明確說明語言與情境:
- 「一位日本導遊用日語講解寺廟歷史,語氣清晰且熱情」
- 「一位西班牙新聞主播在專業演播室環境中,用正式的西班牙語播報頭條新聞」
4. 使用音訊氛圍描述詞
描述音訊氛圍的詞彙對所有三款模型都有幫助:
- 「安靜、親密的氛圍」與「吵雜、繁忙的氛圍」
- 「透過窗戶傳來的悶響」與「乾淨的近距離收音」
- 「大教堂的迴音」與「枯燥的演播室聲學環境」
5. 控制在時長限制內
音訊敘事必須適應模型的時間限制。不要在 8 秒的模型上要求 30 秒的獨白。請根據限制設計音訊元素:
- 一句簡短對話 (Kling 3.0)
- 一個環境音景 (Veo 3.1)
- 一個簡短的音訊片段 (Vidu Q3)
應注意的音訊限制
所有模型共同點
- 音樂生成有限:這些模型都無法可靠地生成複雜音樂。環境類音樂元素(柔和爵士、遠處收音機聲)可行,但請勿期待完整的管弦樂配樂。
- 音訊混音為自動完成:您無法控制對話、環境音與音效之間的相對音量。模型會在內部進行這些決策。
- 無僅有音訊輸出:這些模型生成的是帶有音訊的影片。如果您需要純音訊生成,專用的音訊 AI 工具會更適合。
- 時長限制音訊敘事:8-10 秒的時長限制意味著音軌必然簡短,複雜的音訊故事或長篇對話在單次生成中無法實現。
特定模型限制
- Veo 3.1:對話功能次於環境音。不建議用於以語音為主的內容。
- Kling 3.0:嚴格的內容審核可能會意外封鎖提示詞,即使包含某些無害的音訊情境。
- Vidu Q3:環境音與對話都未達到其他兩款模型的品質高峰,它屬於通用型而非專精型模型。
常見問題 (FAQ)
我可以關閉音訊生成嗎?
音訊作為影片輸出的一部分原生生成。如果您需要靜音影片,可以使用任何標準影片編輯工具或 FFmpeg 指令在後期處理中剔除音軌。
哪款模型影音同步最好?
在我們的測試中,Veo 3.1 在環境與場景內容方面產生了最緊密的整體影音同步。Kling 3.0 在對話唇形同步上表現突出。Vidu Q3 整體良好,但在兩項指標上均非領先。
我可以生成 Kling 3.0 支援的五種語言以外的語言嗎?
目前只有 Kling 3.0 提供明確的多語言音訊生成,且僅限於英語、中文、日語、韓語和西班牙語。其他語言可能會產生結果,但準確度無法保證。
我需要另外購買音訊 API 嗎?
不需要。音訊已自動包含在影片輸出中。沒有單獨的音訊 API 端點,沒有額外的參數需要開啟,且音訊生成也不需額外收費。API 產生的影片檔包含了兩條音軌。
音訊品質足夠商業使用嗎?
是的,適用於大多數商業應用。這三款模型產出的音訊皆乾淨、符合情境且可供生產使用。若用於高階廣播或院線發行,您可能需要透過後期製作來增強或替換音訊,但對於社交媒體、網路內容、行銷與廣告而言,原生音訊已綽綽有餘。
總結
「最好」的音訊 AI 影片模型完全取決於您的專案需要什麼樣的音訊。
Vidu Q3 是價格最親民的音訊模型(USD 0.06/秒),並提供長達 16 秒的片段。它能稱職地處理對話與環境音,是各類混合內容的可靠選擇。
Veo 3.1 是電影級環境音的冠軍。如果您的內容以環境、氛圍或品牌為重點,且不需要多語言對話,Veo 3.1 能以 USD 0.09/秒(快)或 USD 0.18/秒(標準)提供最高水準的影音品質。
Kling 3.0 是唯一具備唇形同步多語言對話的模型。如果您的工作流需要角色以多種語言說話並保持精確的嘴部動作,此水準目前無其他替代品。其定價(Pro 版 USD 0.095/秒)對於此獨特功能來說相當合理。
實際建議:三者皆用。單一 Atlas Cloud API 金鑰讓您能存取所有模型。將 Veo 3.1 用於氛圍與品牌內容;將 Kling 3.0 用於需要多語言口說者的場合;將 Vidu Q3 用於對語音與環境皆有需求的通用型內容。一個帳戶、一個餘額、三款強大模型,靈活選擇最適合每個專案的工具。






