
近期產業預測顯示,到 2030 年,多模態管線 (multimodal pipelines) 功能將內建於 80% 的企業軟體中,相較於 2024 年不到 10% 的比例,這將是一次巨大的飛躍。現在,使用者不僅期待智慧文本,更渴望看到豐富的圖像與流暢的影片。透過整合 Flux 圖像與影片技能 並結合統一平台,您只需幾分鐘即可添加強大的多模態功能。本指南將說明如何結合 Seedance-video-skill 文件 與 Flux 強大的 API,從簡單的文本生成專業級影片。
為什麼現在就應將多模態技術納入您的技術堆疊

- 使用者期望的轉變: 無論是電子商務商店、社群媒體動態牆還是行動應用程式,人們都期待動態的視覺體驗。
- 內容格式的變更: 內容從文本開始,演變為圖像,最終發展為影片。
- 停滯不前的代價: 如果您的 2026 AI 開發堆疊 僅能處理文本,您將因團隊仍需手動拍攝或設計圖形而錯失寶貴的上市時間。同時,您也會錯過擴展海量內容的機會。最糟糕的是,您會失去產品差異化。說實話,現在任何人都能建構簡單的文本包裝器。真正的 全端 AI 開發 代表掌控整個媒體管線。
您可能擔心媒體生成所需的龐大運算能力。但有了現代 API,可擴展推理 (scalable inference) 將在後端為您處理。您無需購買昂貴的 GPU 設備。
純文本堆疊與多模態堆疊對照表
| 類別 | 純文本堆疊 (僅 LLMs) | 多模態堆疊 (例如:Seedance-Video-Skill + Flux) |
|---|---|---|
| 使用者體驗 | 靜態、閱讀導向、需要專注 | 動態、高度視覺化、即刻吸引目光 |
| 內容輸出 | 文章、程式碼片段、文本摘要 | 文本、圖形、自訂產品圖像、影片 |
| 參與度等級 | 一般消費者參與度中等到低 | 高 (顯著延長使用者停留時間) |
| 應用場景 | 聊天機器人、資料分析、文案撰寫 | 電商廣告、社群媒體自動化、遊戲 |
| 基礎設施需求 | 簡單的 LLM API 存取 | 需要強大且具備 可擴展推理 的架構 |
| 成本結構 | 每次生成成本極低 | 運算成本較高,但媒體 ROI 巨大 |
| 管線複雜度 | 直接、單步驟生成 | 多階段 (文本 → 圖像 → 影片 → 編輯) |
那麼,該如何著手添加這些豐富的視覺效果呢?讓我們來看看拼圖的第一塊。
多模態管線第一步:透過 Flux API 生成高保真視覺效果

- 什麼是 Flux?為什麼開發者選擇它? Flux 是一款高保真圖像生成模型。開發者喜愛它,因為它能精準回應您的提示詞。您不需要猜測它會輸出什麼,它只會提供您所要求的精確結果。
- 值得了解的模型變體: 當您查看選項時,有幾種變體值得注意。Flux -schnell 專為極致速度打造,非常適合快速原型製作。Flux dev 則在品質與效率之間提供了極佳的平衡。然而,如果您正在建構嚴謹的商業應用,連接到 Flux.1 Pro API 將是獲得頂級、可靠結果的最佳選擇。
- 關鍵參數: 使用 API 的過程非常簡單。您主要需要調整三個關鍵參數。首先,設置 解析度,例如網頁文章常用的 1024x1024。其次,定義 步數 (steps)。更多的步數會產生更豐富的細節,但會增加些許處理時間。最後,調整 提示詞依從性 (prompt adherence),這控制了 AI 嚴格遵循您文本指令的程度。
- 簡單應用場景: 一位電商賣家透過呼叫 Flux Kontext (12B 參數,基於指令的編輯) API,將基礎攝影素材轉變為 完整的電商型錄。無需重新生成,只需利用自然語言提示詞編輯現有圖像,同時保留產品細節、紋理與品牌風格。
現在您擁有了清晰、高品質的靜態圖像,您可能會想:該如何讓它們動起來?
第二步:啟用 Seedance-Video-Skill 以實現電影級 AI 影片

- Seedance-Video-Skill 的功能: Seedance-Video-Skill 能讓您的媒體幾乎瞬間從靜態變為動態。它同時支援「文本轉影片」與 「圖像轉影片 (I2V)」 生成。您甚至可以執行進階的 「影片轉影片 (V2V)」 變換。
- 獨特之處: 它真正的獨特之處在於動作的一致性。您確實能獲得電影級的輸出品質。角色在行走時不會隨機融化,動作感非常穩定且自然。
- 文件重點:Seedance-video-skill 文件 非常簡潔,端點直觀。您只需選擇輸入模式、定義影片長度並設置目標解析度。如果您使用過標準 REST API,這會讓您感到十分熟悉。
- 小型應用場景: 一位 YouTuber 將單一 Flux 產品圖像直接轉換為 Seedance 2.0 的圖像轉影片模式,進而製作出 9 種以上的專業行銷格式(開箱、試穿、電影級廣告),且具備完美的連續性,解鎖了完整的 Flux 圖像與影片技能 工作流。他甚至無需聘請影片剪輯師。
靜態 → 動態管線對照表
| 功能 | 無 Seedance-Video-Skill | 使用 Seedance-Video-Skill |
|---|---|---|
| 將圖像轉換為影片 | 手動(需要複雜軟體) | 自動化 圖像轉影片 (I2V) API |
| 管線整合 | 分散式(涉及大量人工交接) | 統一化(無縫整合至自訂後端) |
| 內容製作速度 | 緩慢(每項廣告活動需耗時數天或數週) | 快速(數分鐘內即可製作數十種變體) |
| 可擴展性 | 受限於人工努力 | 近乎無限,完全由程式碼驅動 |
| 規模化成本 | 極高(需要龐大的創意團隊) | 高效率的 API 調用計費 |
| 迭代速度 | 緩慢,需等待手動渲染 | 即時,只需調整參數並重新執行 |
現在您有了 Flux 來製作驚豔的圖像,也有了 Seedance 來實現流暢的影片。但是,當您將它們串聯在同一個流暢的工作流程中時,會發生什麼事?
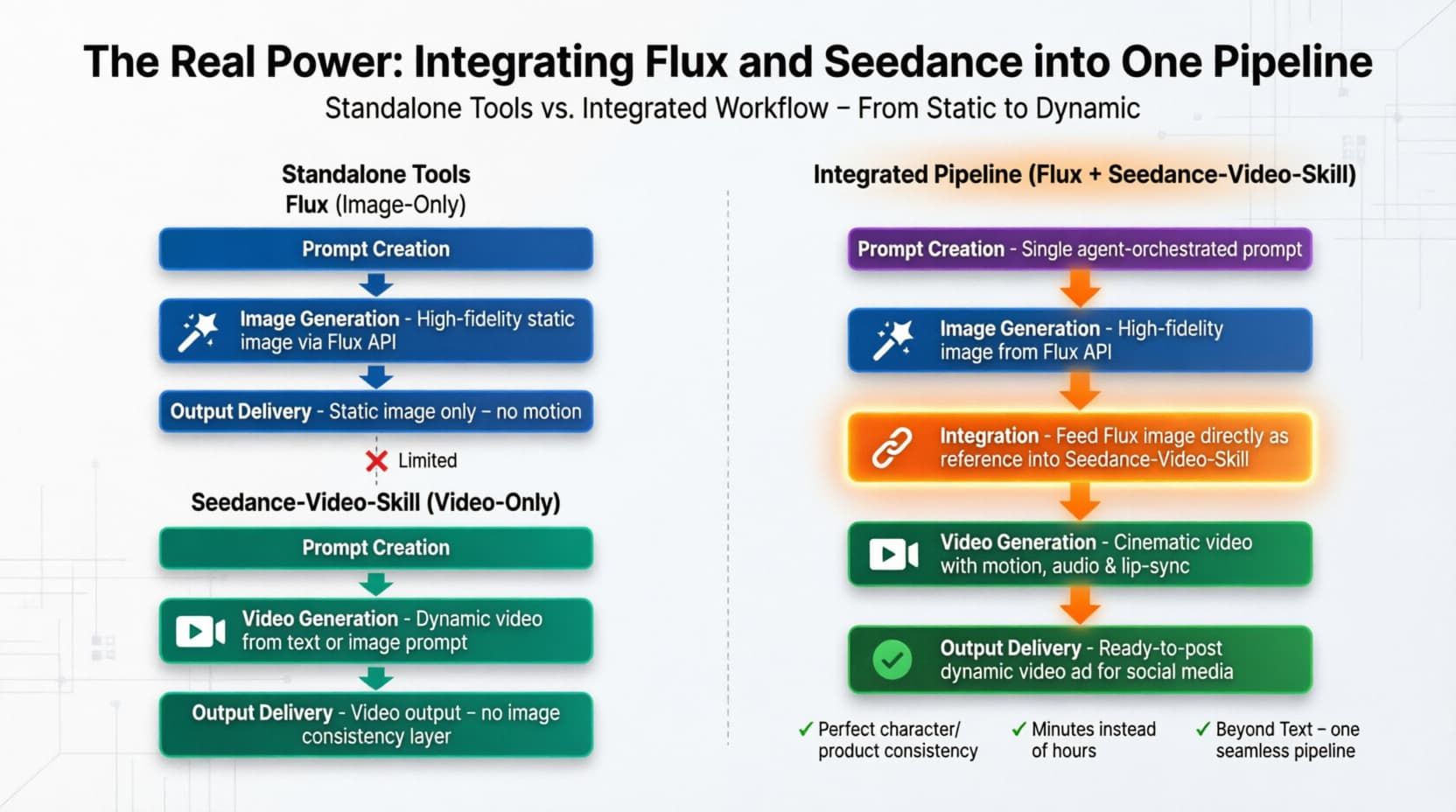
真正的威力:將 Flux 與 Seedance 整合至單一管線
- 「圖像轉影片」工作流: 過去,建構「圖像轉影片」工作流意味著下載龐大的檔案並處理雜亂的腳本。現在,您只需要將 Flux 輸出的圖像 URL 直接傳入 Seedance 輸入端即可。它們共同構成了統一的 Flux 圖像與影片技能。
- 我傾向使用像是 Atlas Cloud 這樣的統一 API 平台。您只需一個 API 金鑰並選擇一種調用模式,即可存取這兩款強大的模型。您無需管理不同的帳單設定,只需建構您的 多模態管線,讓平台處理重負載運算。
使用統一 API 平台顯然能使程式碼更乾淨。但除了簡化代碼之外,跳過直接存取模型還有哪些更深層的商業理由?
為什麼要使用統一 API 平台而非直接存取
當您使用 AI 聚合平台時,能簡化您的 全端 AI 開發。您可以在同一個地方處理所有需求。想要替換模型?只需更改一行程式碼,無需重寫整個後端。這使得管理您的 可擴展推理 基礎設施變得容易許多。此外,您還能在新模型發布的第一時間即時存取。
直接 API vs. 統一 API 平台
| 類別 | 直接整合(例如:自行呼叫 Flux/Seedance API) | 統一 API 平台 |
|---|---|---|
| 所需 API 金鑰 | 較多(多個 API、認證、配置) | 較少(單一入口點) |
| 模型切換 | 需要大幅重寫程式碼 | 只需更改模型名稱 |
| 帳單 | 發票分散、條款不一 | 統一、可預測的帳單(按秒或按影片計費) |
| 全球存取 | 通常需要自訂代理 (Proxy) | 內建全球邊緣優化 |
| 新模型支援 | 手動 (Built-in global edge optimized) | 自動化(發布即時存取) |
現在流程已經很清晰了,讓我向您展示如何從今天開始建構它。
三步驟快速上手
連結這些工具大約只需十分鐘。您只需遵循三個簡單步驟,即可全面升級您的 2026 AI 開發堆疊。
- 第一步: 從您選擇的統一 API 平台 取得您的專屬 API 金鑰。
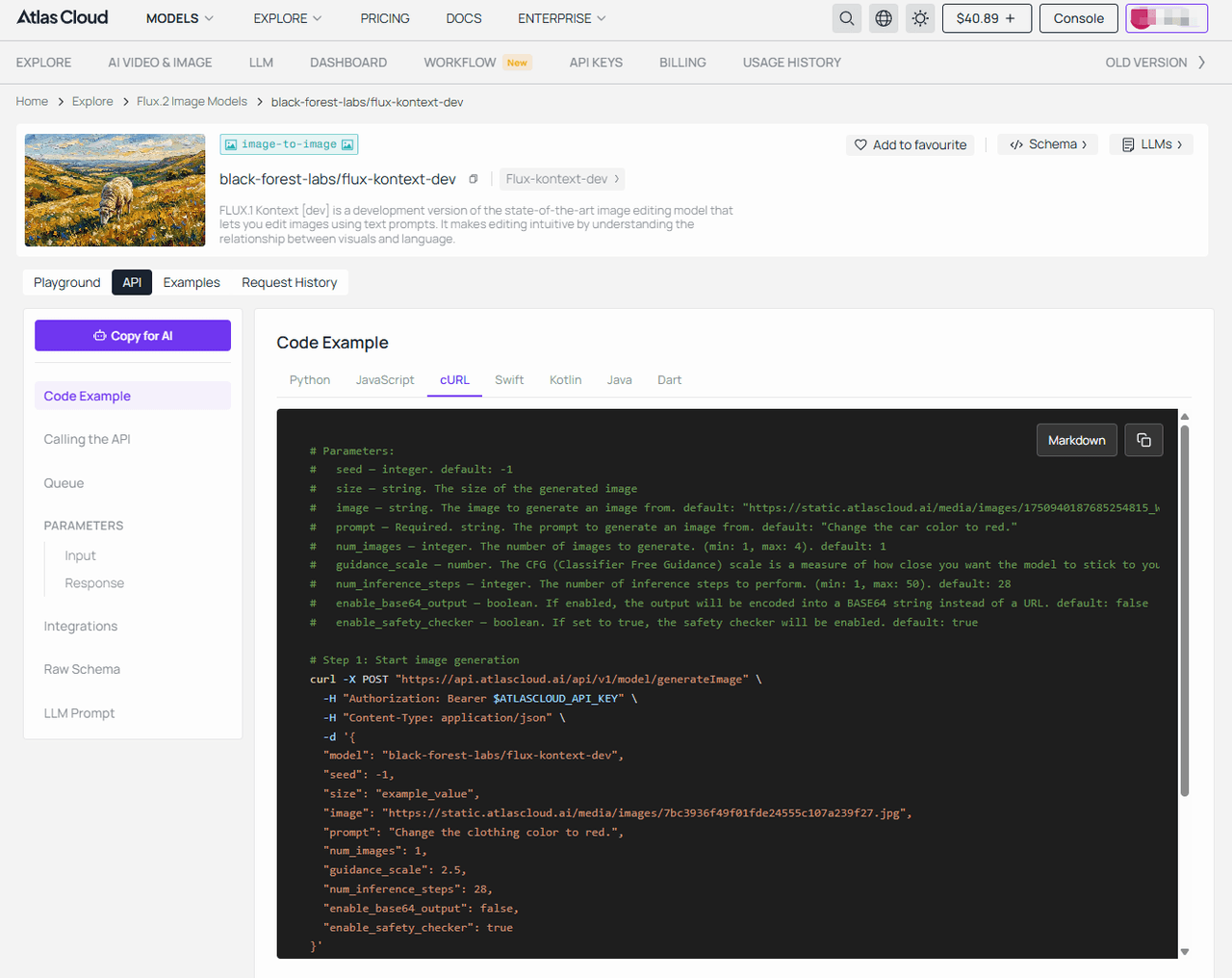
- 第二步: 呼叫 Flux 以生成您的基礎圖像。(以 flux-kontext-dev 為例)
plaintext1# 參數說明: 2# seed — 整數。預設值:-1 3# size — 字串。生成圖像的尺寸 4# image — 字串。用於生成的參考圖像。預設值:url... 5# prompt — 必要欄位。字串。生成圖像的提示詞。預設值:"Change the car color to red." 6# num_images — 整數。生成圖像數量 (1-4)。預設值:1 7# guidance_scale — 數值。CFG 指導比例 (1-20)。預設值:2.5 8# num_inference_steps — 整數。推理步數 (1-50)。預設值:28 9# enable_base64_output — 布林值。若啟用,將以 BASE64 字串輸出而非 URL。預設值:false 10# enable_safety_checker — 布林值。若設為 true,將啟用安全檢查。預設值:true 11 12# 第一步:啟動圖像生成 13curl -X POST "https://api.atlascloud.ai/api/v1/model/generateImage" \ 14 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 15 -H "Content-Type: application/json" \ 16 -d '{ 17 "model": "black-forest-labs/flux-kontext-dev", 18 "seed": -1, 19 "size": "example_value", 20 "image": "https://static.atlascloud.ai/media/images/7bc3936f49f01fde24555c107a239f27.jpg", 21 "prompt": "Change the clothing color to red.", 22 "num_images": 1, 23 "guidance_scale": 2.5, 24 "num_inference_steps": 28, 25 "enable_base64_output": false, 26 "enable_safety_checker": true 27}' 28 29# 回應:{"code": 200, "data": {"id": "prediction_id"}} 30 31# 第二步:輪詢結果 (將 {prediction_id} 替換為實際 ID) 32curl -X GET "https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" \ 33 -H "Authorization: Bearer $ATLASCLOUD_API_KEY"
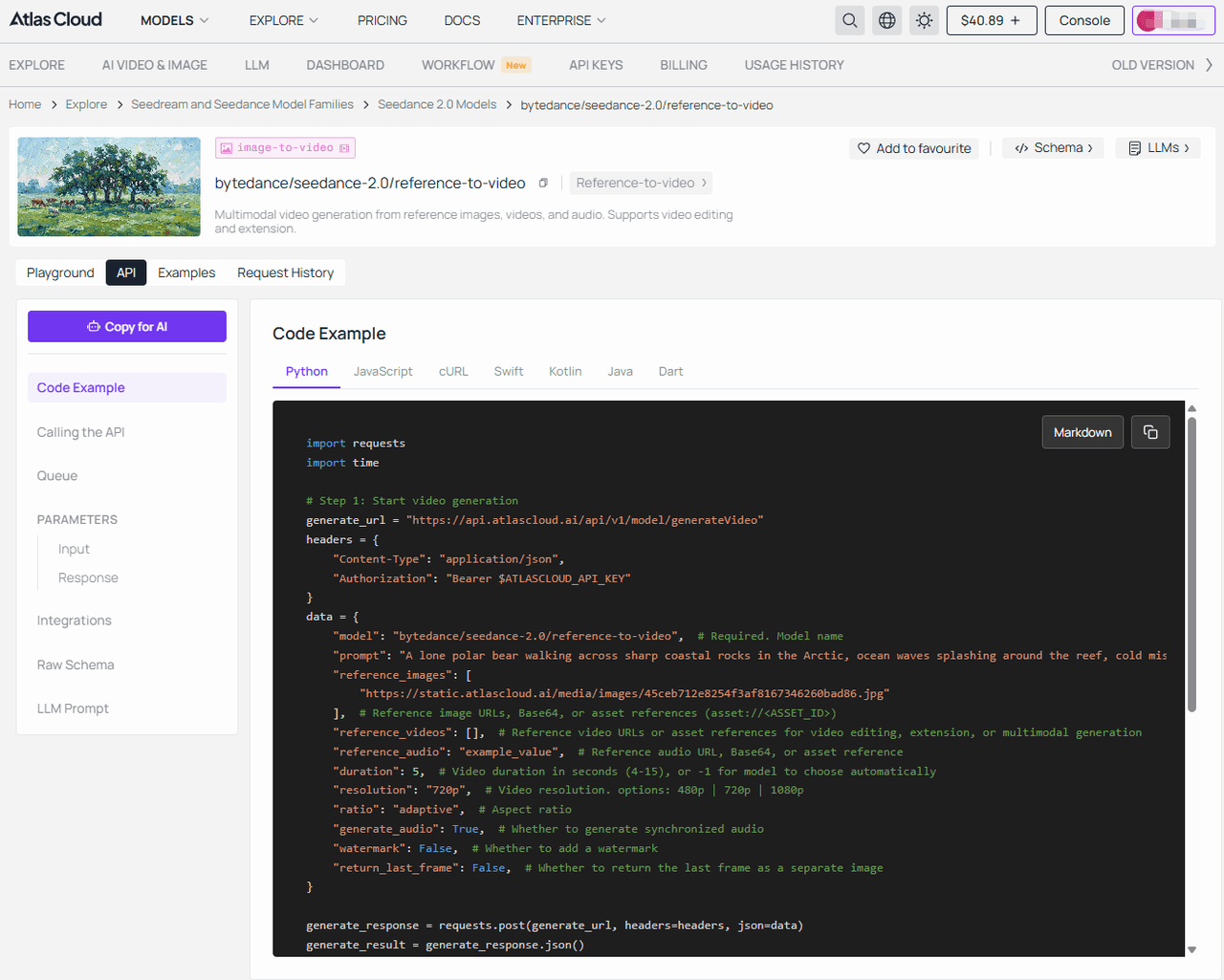
- 第三步: 將該圖像 URL 直接傳遞給 Seedance 進行影片處理。(以 Seedance 2.0 reference-to-video 為例)
plaintext1# 參數說明: 2# prompt — 字串。描述期望影片的文本。 3# reference_images — 陣列。參考圖像 URL。 4# duration — 整數。影片長度 (秒, 4-15)。預設值:5 5# resolution — 字串。影片解析度。預設值:"720p"。 6# ratio — 字串。長寬比。預設值:"adaptive" 7# generate_audio — 布林值。是否生成同步音訊。預設值:true 8 9# 第一步:啟動影片生成 10curl -X POST "https://api.atlascloud.ai/api/v1/model/generateVideo" \ 11 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 12 -H "Content-Type: application/json" \ 13 -d '{ 14 "model": "bytedance/seedance-2.0/reference-to-video", 15 "prompt": "A lone polar bear walking across sharp coastal rocks in the Arctic...", 16 "reference_images": [ 17 "https://static.atlascloud.ai/media/images/45ceb712e8254f3af8167346260bad86.jpg" 18 ], 19 "duration": 5, 20 "resolution": "720p", 21 "ratio": "adaptive", 22 "generate_audio": true 23}' 24 25# 回應:{"code": 200, "data": {"id": "prediction_id"}} 26 27# 第二步:輪詢結果 28curl -X GET "https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" \ 29 -H "Authorization: Bearer $ATLASCLOUD_API_KEY"
官方 Seedance-video-skill 文件 列出了所有您稍後可能需要調整的進階參數。
逐步轉換流程
| 步驟 | 操作內容 | 輸入 | 工具角色 | 輸出 | 重要性 |
|---|---|---|---|---|---|
| 1. 生成視覺資產 | 呼叫 Flux API 端點 | 文本提示 | Flux 生成高畫質影像 | 清晰的靜態圖像 URL | 建立視覺識別與品質基準 |
| 2. 添加動態與敘事 | 將影像 URL 傳至 Seedance | 圖像 URL + 動作設定 | 圖像轉影片 (I2V) 引擎 | 流暢的電影級影片片段 | 將靜態內容轉為引人入勝的媒體 |
| 3. 整合與傳遞 | 將最終媒體呈現給使用者 | 最終影片 URL | 統一聚合 API 平台 | 無縫的使用者體驗 | 驗證您的 全端 AI 開發 能力 |
在開始撰寫程式碼之前還有疑問嗎?讓我們現在解決它們。
常見問題 (FAQ)
Q1: 什麼是「Flux 圖像與影片技能」?它與傳統 API 有何不同?
Flux 圖像與影片技能實質上是一個結合的多模態管線。大多數傳統 API 僅輸出靜態圖片。此方法將 Flux 的超真實圖像輸出直接連結至影片生成,過程更具預測性,且比舊有工具更能精準執行您的提示詞。
Q2: 使用 Seedance-Video-Skill 能打造什麼文本 AI 做不到的功能?
例如自動化 TikTok 廣告、動態產品展示或互動式遊戲資產。純文本將您限制在聊天介面中;Seedance 則推動您進入 全端 AI 開發,讓您能完全控制豐富的動態視覺媒體。
Q3: Seedance-Video-Skill 如何將靜態影像轉為動態影片?
它使用先進的 圖像轉影片 (I2V) 甚至 影片轉影片 (V2V) 技術。您只需輸入圖像 URL,模型會預測自然的動作幀,同時保持主體穩定,避免其他工具中常見的怪異扭曲。
Q4: Flux 與 Seedance-Video-Skill 如何在單一工作流中協作?
您發送文本提示給 Flux 以生成高保真圖像,接著程式會立即擷取該影像 URL 並傳遞給 Seedance 以添加動作。這是自動化內容生成的「組合拳」。
Q5: 我需要分別為 Flux 和 Seedance 準備 API 金鑰嗎?
使用統一 API 平台,您只需一個 API 金鑰即可同時存取 Flux.1 Pro API 與 Seedance,這能讓帳單與程式碼保持精簡。
Q6: 使用統一 API 平台與直接整合模型相比有什麼好處?
這節省了大量工程時間,您可即時存取新模型。此外,若模型出現故障,您無需重寫後端。可擴展推理 已為您處理妥當,確保在高負載下仍能流暢運行。
Q7: 使用 Flux 與 Seedance 生成圖像和影片的成本是多少?
Atlas Cloud 採用嚴格的 API 調用隨用隨付制。圖像生成成本極低,影片成本略高,但與聘請人類影片剪輯師相比,API 點數的投資報酬率 (ROI) 非常驚人。
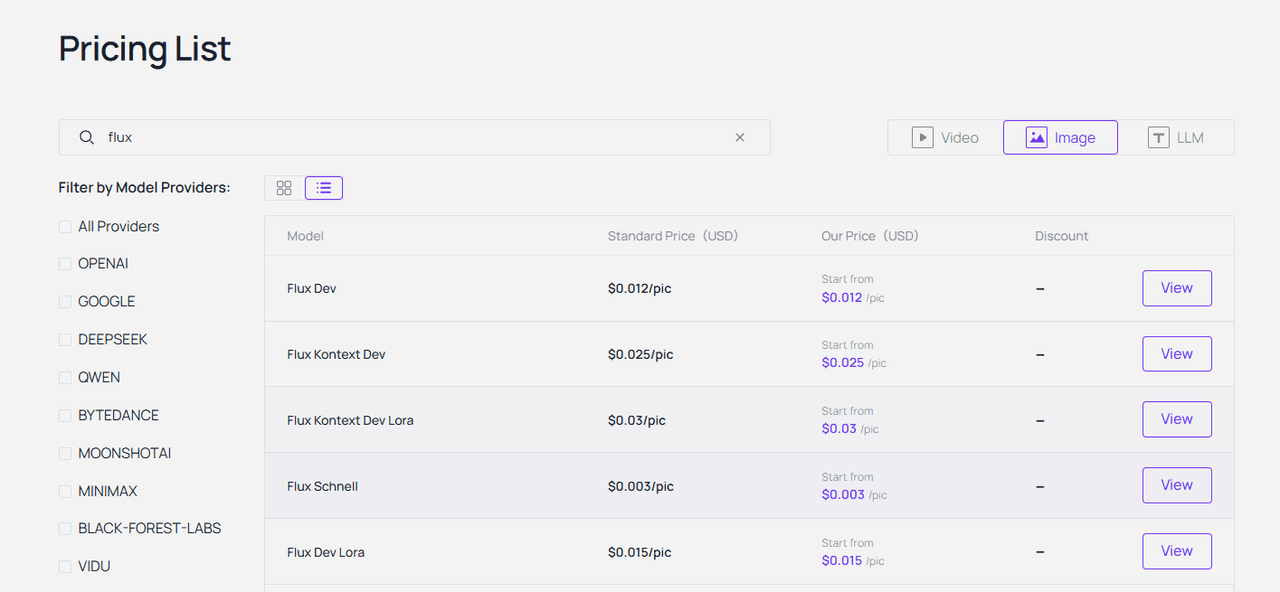
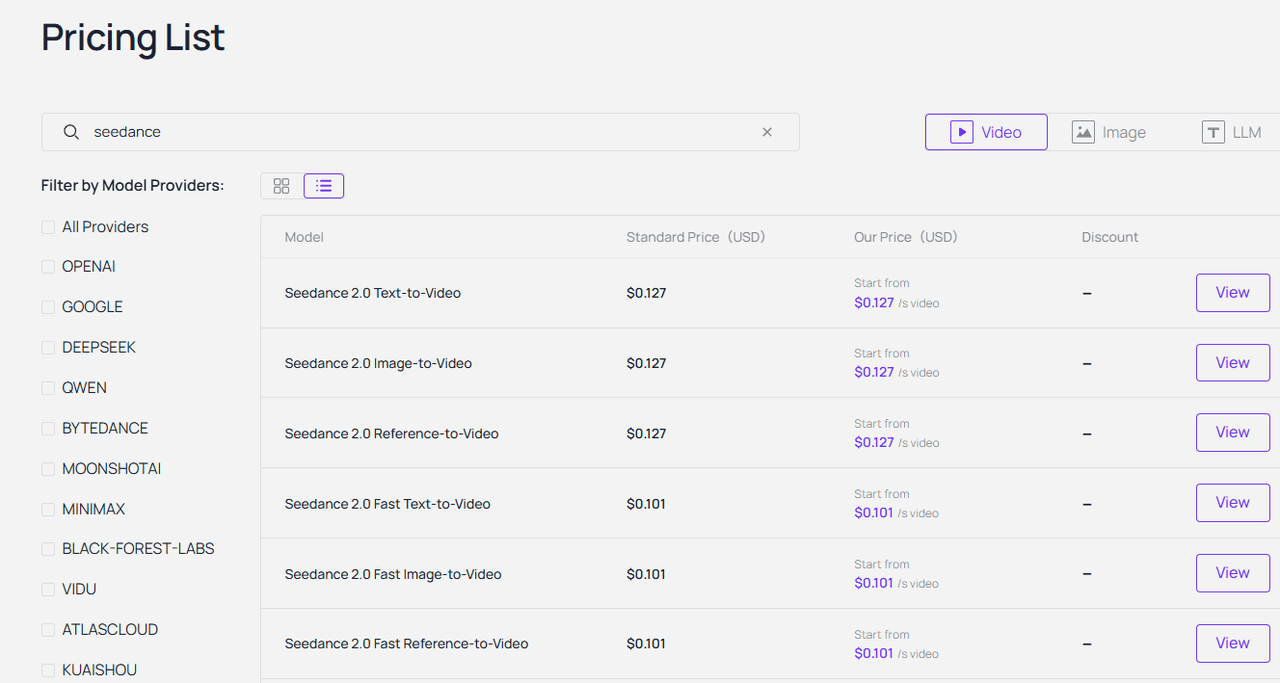
Q8: Seedance-video-skill 文件包含什麼內容?上手容易嗎?
Seedance-video-skill 文件非常易讀,涵蓋了端點、輸入模式與解析度限制。即便您對 API 不熟悉,通常也能在十分鐘內完成測試。
結論
單純添加文字聊天機器人已不足夠。若要為 2026 AI 開發堆疊 做足準備,您確實需要 多模態管線。結合 Flux 的精準度與 Seedance 的動態效果,可能是您目前能做的最明智決策。
一切盡在掌握:單一平台、兩款強大模型、零整合挫折。 取得您的 API 金鑰,親眼見證從零開始生成電影級媒體是多麼容易。立即開始實驗您自己的工作流程吧!






