大多數人仍認為「更好的用詞」等於「更好的圖像」。這在兩年前或許是真的,但現在已經不是了。
在 2026 年,真正的差距不在於模型本身,而在於「描述者」與「建構者」的區別。前者只會輸入「電影級光影、4k、超精細」等字眼;而後者則是在構建場景——規劃光線方向、深度層次與攝影機視角。
如果你的圖像看起來依然平淡,問題很可能不在模型,而在於你給它的資訊不足。
為何你的提示詞(Prompt)已不再足夠(2026 年觀點)
籠統的提示詞已經失效了。模型已經處理過數百萬次「最高品質」或「高細節」這類詞彙,它們現在幾乎無法帶來任何改變。
真正重要的是什麼?是結構化的輸入。光線從哪裡來?前景與背景分別有什麼?你使用的是什麼鏡頭?現代模型能精準響應這些變數,並忽略無用的贅詞。
以下是一個常見案例。有人寫道:「一幅光線柔和的精美肖像」。模型產出的圖像卻顯得扁平,原因是什麼?因為缺乏光線方向、缺乏深度區隔、缺乏攝影機視角。模型只能靠猜,而猜測的結果通常就是平庸。
你需要做的轉變很簡單:停止描述結果,開始建構場景。
7 個進階技巧
-
明確定義光線走向
「柔和光線」太模糊了。側光、逆光、頂光——這些詞彙能給模型具體的指引。方向創造陰影,陰影創造深度,深度則賦予圖像真實感。
與其寫「柔和的人像光影」,不如試試:
一位女性的肖像,左側打光,臉部右側呈現柔和陰影,背景帶有細膩的環境光

你可以立刻看出差別。模型清楚地知道光線的位置。
-
運用真實攝影燈光設定
三點照明、輪廓光(Rim lighting)、倫勃朗光(Rembrandt lighting)。這些不僅是專業術語,更是模型在訓練過程中見過成千上萬次的模式。使用這些術語,能讓你的輸出更穩定。
範例:
運動鞋產品照,三點照明設定,強主光,柔和補光,細膩的輪廓光將產品從深色背景中分離出來

這比單寫「戲劇性光影」的效果好得多。
-
層層構建深度
平淡的圖像通常是因為所有元素都位於同一個平面。透過明確指明前景、中景和背景來解決這個問題。
範例:
木桌上的咖啡杯(前景),正在使用筆電的人(中景),暖色調燈光且模糊處理的咖啡館內部(背景)

現在,模型有了空間關係可以發揮。
-
使用攝影術語,而非風格標籤
「賽博龐克風格」太模糊。「35mm 鏡頭、低角度、廣角鏡頭」則精確得多。攝影參數直接對應圖像的建構方式。
將這些技巧牢記在心:
- 35mm:呈現自然、日常的視覺感
- 85mm:適合人像,具備壓縮感
- 廣角:用於營造戲劇張力與宏大尺度
- 低角度、平視、俯視:調整視角
範例:
特寫肖像,85mm 鏡頭,淺景深,平視角度,柔和的背景虛化

這比單寫「美學肖像」給予模型明確得多的指令。
-
利用對比引導視覺焦點
目標不是讓畫面處處都有細節,而是創造「對比」。明與暗的對比、冷與暖的對比、清晰主體與模糊背景的對比。
三種有效的對比類型:
- 光影對比:黑暗背景下的明亮主體
- 色彩對比:冷色背景下的暖色聚光燈
- 細節對比:清晰的主體與模糊的環境
範例:
主體由暖色聚光燈照亮,背景為深冷色調,高對比光影,強烈的主體聚焦
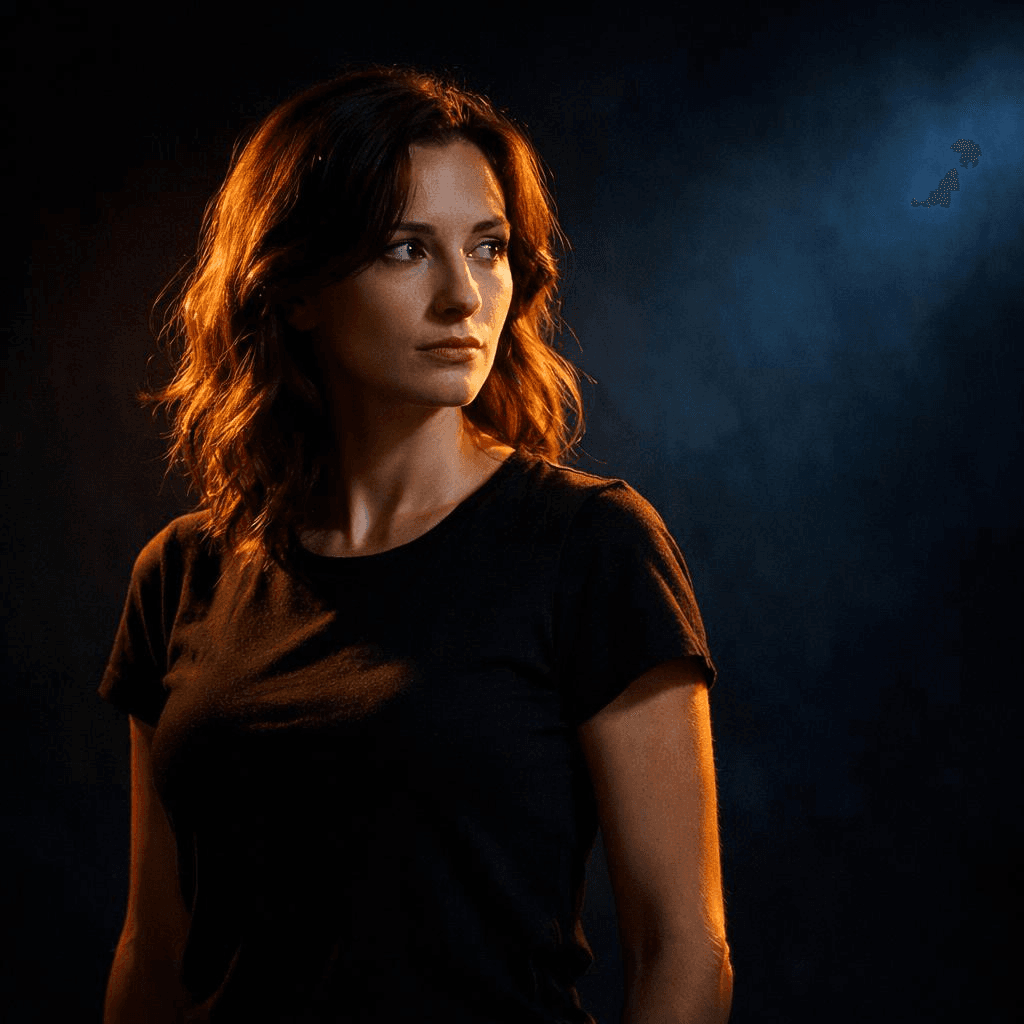
這樣一來,觀者的目光會準確地落在你想要的地方。
-
加入限制以清理雜訊
冗長的提示詞容易變得混亂。與其增加更多細節,不如加上限制。告訴模型你「不需要」什麼。沒有雜物,沒有畸變,沒有多餘的物體。
範例:
極簡產品照,置中構圖,乾淨的白色背景,無雜亂,無文字,無畸變

限制條件往往比額外的描述更有效。
-
像導演一樣迭代,而非賭博
沒人能一次就獲得完美的最終成品。專業人士會生成、調整、再生成。
一個簡單的工作流程:
- 第一步:基礎構圖、主體與環境
- 第二步:加入方向性光影與對比
- 第三步:精煉細節、移除雜訊
每一輪迭代都會改善結果。這就是從「碰運氣」轉向「穩定產出」的方法。
總結:專業提示詞框架
不要再寫長句形式的提示詞了。將它們視為模組化系統來撰寫。
這是一個有效的結構:
plaintext1[主體] + [環境] + [光影] + [攝影機] + [構圖] + [色彩] + [限制條件]
看看基本提示詞與結構化提示詞的差別。
範例:從基本提示詞到專業提示詞
基本提示詞(普通用戶):
穿著白色夏季連衣裙的女模特,乾淨背景,攝影棚燈光,高細節,電商風格

專業提示詞(結構化):
一位穿著白色夏季連衣裙的女模特(主體),站在極簡風格的攝影棚中,背景為米色質感牆面(環境),右側側光在身體左側投下柔和陰影,細膩的輪廓光將剪影與背景分離(光影),使用 85mm 鏡頭拍攝,平視角度(攝影機),主體略微偏離中心,淺景深,柔和的前景虛化增加層次感(構圖),溫暖的自然色調,柔和的對比度(色彩),乾淨的構圖,無雜亂,無畸變,無多餘物體(限制條件)

結論:從「提示」到「執導」
獲得一張精美的圖像固然很好,但實際項目需要數百張穩定且高品質的視覺素材。手動輸入提示詞無法擴展。
你會遇到實際問題:延遲、每張圖像的成本,以及如何在批量生產中維持視覺風格一致性。單靠提示詞設計無法解決這些問題,你需要一套系統。
這就是基於 API 的圖像生成變得至關重要的原因。與其每次都在網頁界面輸入提示詞,不如將生成功能整合到你的工作流程中。結構化的提示詞可以重複使用、自動化,並隨著時間推移進行優化。
像 Atlas Cloud 這類平台提供了統一的 API 層來實現這一目標。
如果你是: • 想要輕鬆且經濟地存取 AI 能力的開發者。 • 處理需要多領域應用 AI 的團隊。 • 需要可靠 AI 來支援重要業務的公司。 • 使用 ComfyUI 和 n8n 等工具的用戶。
嘗試使用 Atlas Cloud,你會發現自己從「實驗」階段轉向了「高效生產」階段,且無需從零開始構建基礎設施。
未來的關鍵不在於孤立地編寫更好的提示詞,而在於建構可控、可重複、適合生產的視覺系統。
常見問題
為什麼我的 AI 圖像看起來還是很平?
圖像顯平通常代表你缺少了「深度線索」。試想攝影的原理:深度源於陰影、物體的遮擋以及焦點的差異。你的提示詞必須明確指出這些細節。
舉個簡單的例子:「一個人坐在桌子旁」。這對深度幾乎沒有任何描述。試著改為:「一個人坐在桌子旁(中景),帶有城市燈光的模糊窗戶(背景),焦點清晰的咖啡杯(前景)」。現在,模型就有了層次可以發揮。
光影是另一個常見誤區。許多提示詞只提到環境光,這會導致整張圖看起來平坦且均勻。請加入一個方向性光源:側光、逆光、輪廓光。任選一種,模型便會開始生成陰影,你的圖像瞬間就有了立體感。
還有一點:不要試圖填滿畫面的每一個角落。留白與虛化非常有用,它們能引導觀者看向重點。有時候,減少細節反而能帶來更強的深度感。
AI 能取代產品攝影嗎?
在許多情況下是可以的。但我們必須誠實面對它的適用與不適用場景。
如果你需要拍攝一隻豪華手錶的「英雄照」——那種金屬上的每一道反光都至關重要、皮革錶帶的紋理必須精確無誤的鏡頭——傳統攝影依然勝出,這種專業攝影棚的品質是 AI 目前難以完全取代的。
但對於幾乎其他所有需求,AI 都更快、更便宜。目錄照片、生活場景、季節性變換、A/B 測試素材等,你可以在幾秒鐘內生成一張乾淨的白色背景產品照,然後將其置入海灘、冬季小屋或現代廚房場景中,使用 AI 產品攝影生成器即可完成。
無需租用攝影棚、無需燈光設備、無需修圖,每張圖只需幾分錢。
對於小型品牌和直接面對消費者的初創企業來說,這完全改變了競爭格局。他們現在能產出與大預算公司相抗衡的視覺內容,這在兩年前是根本不可能的。
OpenAI 的視覺生成模型與前代有何不同?
新模型 GPT‑image‑1.5 在底層架構上進行了幾項調整。它採用了 Diffusion Transformer 架構,簡單來說,它能更精準地處理空間關係。
舊版本經常將複雜場景拆解成互不協調的部分,例如手可能會漂浮在杯子旁而不是握著它,或者陰影方向錯誤。新版本能保持元素間的連結:手會正確地握住杯子,陰影也會落在正確的位置。
文字渲染是另一個重大躍進。舊版本產出的文字通常是亂碼,而 GPT‑image‑1.5 可以生成多種語言的可讀文字,甚至能在同一張圖中混用英文與中文,這在現在已經能穩定實現了。
該模型還原生支援更高解析度——無需放大即可達到 2K,產出的偽影更少、細節更銳利。
當然,這也有缺點:模型對模糊的提示詞容忍度降低了。你不能再只說「一張好的人像」就指望它變出魔法。你必須更謹慎。但當你給出結構化的指令(光影方向、深度層次、攝影參數)時,它的輸出品質遠超任何前代模型。






