
從一句描述環境的文字開始,我最終得到了一個可以在遊戲引擎中行走、跳躍,並在充滿塞爾達(Zelda)風格的生物發光峽谷中漫步的 3D 綁定角色。這整個過程中,我從未打開過任何建模軟體,也沒有寫過一行底層渲染代碼。
本文將帶您走過完整的製作流程,包括我在過程中犯下的錯誤。我所使用的每一項 AI 能力都來自同一個平台——Atlas Cloud,且整個工作流只需一個 API Key 即可運行。
簡而言之:曾經需要一個團隊的工作,現在只需一個 API
過去,開發一款可遊玩的 3D 遊戲意味著要跨越數道技術門檻。你必須學會使用 ZBrush 或 Blender 進行建模,為角色綁定骨骼(Rigging),通過關鍵影格或動作捕捉製作動畫,最後編寫代碼將這些資源導入遊戲引擎。對於大多數初學者來說,其中任何一個步驟都足以讓專案在開始前就宣告中止。
我想測試的事情很簡單:AI 現在是否能將這些步驟串聯起來,讓完全沒有建模或程式背景的人,也能創作出一個真正在引擎中運行的 3D 遊戲 Demo?
經過實測,答案是肯定的。整個 AI 管線,從圖像生成、3D 轉換到貼圖與天空盒(Skybox)製作,全都透過同一個 API Key 完成。至於較為複雜的工程工作,包括 Blender 的組裝與 Godot 專案設置,則由 Claude 進行編排。我的角色主要是檢查結果,並描述我接下來想要什麼。
一個 API Key 支撐整個工作流。 GPT Image 2、遊川 MJ V8.1、Nano Banana 2、Seed 3D、混元 3D 及其他模型,全都透過 Atlas Cloud 使用同一個 Key 運行。無需在多個平台之間反覆註冊、分別充值或手動整合不同的 API。
完整工作流概覽(按實際操作順序)
plaintext1① GPT Image 2 → 環境概念圖,確立美學:塞爾達風格渲染 + 暗黑生物發光峽谷 2② GPT Image 2 edit → 將環境處理為「3D 立體模型(Diorama)」,清理成等距視角的基礎圖像 3③ 混元 3D (Hunyuan 3D) → 進行壓力測試,將整個場景一次性轉化為 3D 4④ GPT Image 2 → 使用相同模型生成 360° 天空盒,用作遊戲星空背景 5⑤ 遊川 MJ V8.1 → 設計遊俠角色概念,定義主角靈魂 6⑥ Nano Banana 2 → 保持角色一致性,重繪為正面 T-pose 參考圖 7⑦ Seed 3D → 將角色圖轉為 3D,獲得乾淨的頭髮與手指幾何結構、綁定友好的結構、內建 PBR 及字節跳動的 Seed 模型 8⑧ Nano Banana 2 + 混元 3D → 獨立構建燈籠道具 9⑨ Mixamo + Blender × Claude → 利用 Mixamo 自動綁定並生成走/跑/跳動畫,隨後由 Claude 通過 MCP 處理 Blender 內的導入、材質掛載、對齊及 GLB 匯出 10⑩ Godot 4 → 整合所有資源:角色控制器、第三人稱相機、天空盒、體積霧與發光燈籠
步驟 ① 到 ⑧ 全部使用了 Atlas Cloud 提供的 AI 能力,該平台定位為「All Media AI 的單一 API」,提供統一接口調用超過 300 種模型。這包括步驟 ⑤ 的遊川 MJ。步驟 ⑨ 的 Mixamo、步驟 ⑩ 的 Godot,以及負責材質設置的 Blender,皆為免費的第三方工具。
以下是實作過程,以及我在每個步驟中實際使用的提示詞(Prompts)。
步驟 1 | GPT Image 2:繪製世界
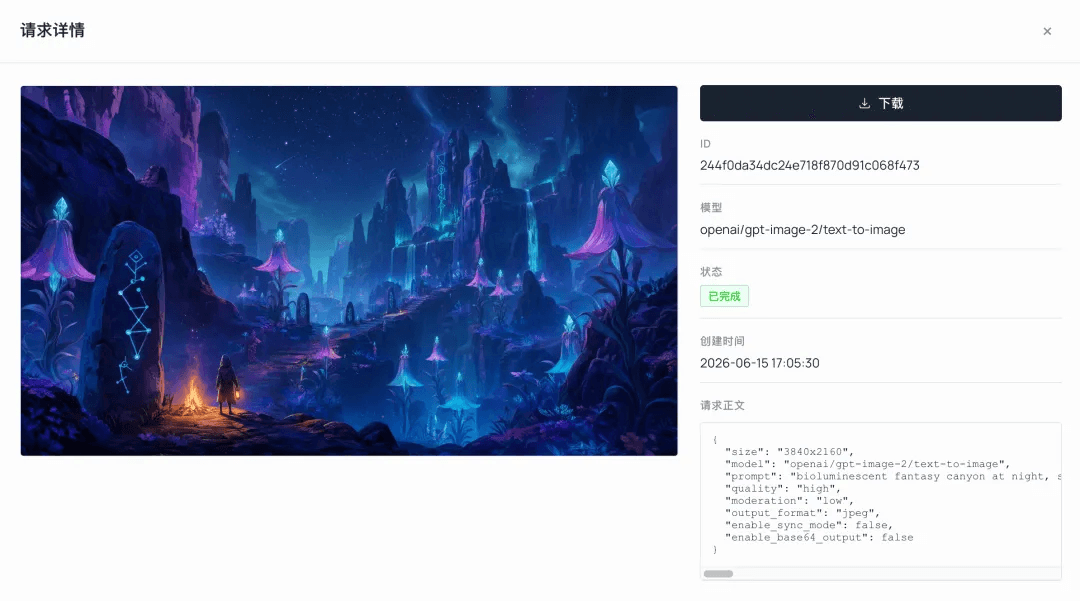
起點並非角色,而是整個世界的美學風格。我使用 Atlas Cloud 上的 GPT Image 2 生成了環境概念圖,定義了整體格調:塞爾達風格渲染,結合暗黑生物發光峽谷。
環境提示詞 ('text-to-image';在 Playground 參數中將長寬比設置為 '16:9'):
plaintext1bioluminescent fantasy canyon at night, stylized painterly game concept art, towering deep-indigo and magenta rock cliffs glowing with teal veins, tall bell-shaped glowing flora with crystal tips, ancient carved standing stones with angular constellation glyphs, winding ridge path, a small hooded ranger with a warm lantern beside a campfire for scale, misty atmospheric depth, starry night sky, cool teal-and-violet palette with warm amber accent, dreamy magical mood, soft cel-shaded painterly rendering, cinematic wide establishing shot, high detail
這張圖成為了整個專案的美學定海神針。色彩、光影和世界觀都在此定調。現階段唯一的任務是確認畫面是否好看,至於能不能建模,那是後續的問題。
為什麼選擇 GPT Image 2 製作環境: 對於「環境場景+後續立體模型轉換」的工作流,在我的測試中,GPT Image 2 是最穩定的選項。它的構圖清晰,色彩保留良好。當我嘗試使用其他圖像模型進行立體模型轉換時,它們經常將圖片洗成白模(灰模),導致後續建模所需的色彩和材質資訊丟失。因此,在環境軌道上,我始終保持使用 GPT Image 2。
步驟 2 | GPT Image 2 'edit':將環境轉為 3D 立體模型 (Diorama)
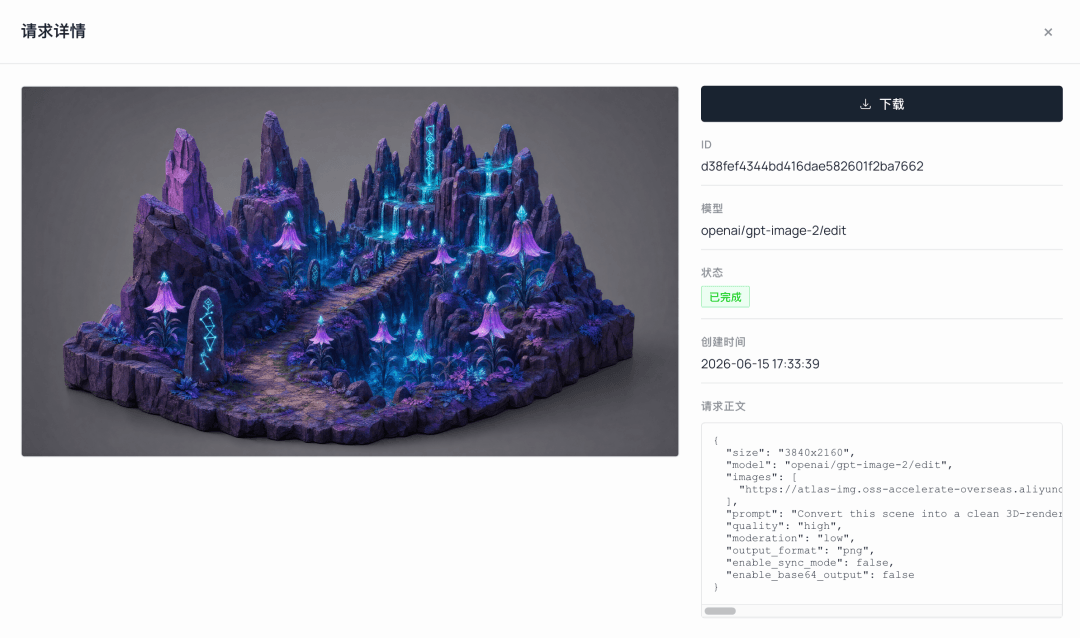
接下來,必須將概念圖轉化為 3D 模型能理解的形式。廣角概念繪畫並不適合作為直接建模的輸入源,光影太過戲劇化且背景過於雜亂。所以我先使用 GPT Image 2 的 edit 功能,將其清理成等距視角的 Diorama 基礎圖,為下個階段做好材質準備。
立體模型轉換提示詞 (GPT Image 2 'edit',以步驟 1 的環境圖為輸入):
plaintext1Convert this scene into a clean 3D-renderable isometric diorama, keeping ALL original colors and textures fully intact — purple-magenta rock, teal glowing bell flowers, carved runestones, mossy ground. Plain simple background. Even soft neutral lighting so the true surface colors read clearly; remove only the heavy colored rim-light, fog and warm campfire glow. Do NOT desaturate, do NOT turn into grey clay. Preserve material and texture detail, single connected terrain chunk, 3/4 orthographic view, no text, no characters.
此處最容易踩的坑:不要讓圖片變成灰白色的灰模。 混元模型會直接讀取輸入圖像中的色彩資訊作為材質。如果你餵給它一張灰模圖,它就只能返回一個灰模模型。這就是為什麼提示詞明確強調 'keeping ALL original colors'(保留所有原始色彩)且 'Do NOT desaturate'(不要去飽和)。目標是僅移除強烈的輪廓光、霧氣和營火的光暈,同時保留基礎色彩與材質細節。
步驟 3 | 混元 3D:一次性將整個場景轉為 3D
這一步是刻意的壓力測試。我沒有將場景拆分為獨立資源,而是將上一步得到的完整立體模型圖放入混元 3D 中,測試它能否一次性重建整個場景。
結果比預期更實用。這個 Diorama 模型約有 10 萬個面(faces)。其整體結構、岩石形狀和地形關係保存得很好,並且自帶了 PBR 貼圖,而非單純的白模。我原本預期它會更接近浮雕,但經過 Diorama 前處理後,全場景模型的可用性遠超預期。這是一個值得記錄的驚喜。
背後原理備註: 這部分使用了混元 3D 的單圖生成(image-to-3D)。當給定一張完整的廣角圖像時,它依賴影像學與風格推斷來填補缺失的三維結構。最令人印象深刻的是,即使只有一張正向廣角圖,它也能在相同風格下合理推斷出看不見的背部與底部,產生一個完整的三維場景,而非平面的浮雕。對於 Diorama 而言,這已經非常強大。若需要更細緻的環境,更正統的做法仍是將場景拆分為獨立資源,逐一建模後再在引擎中組裝。
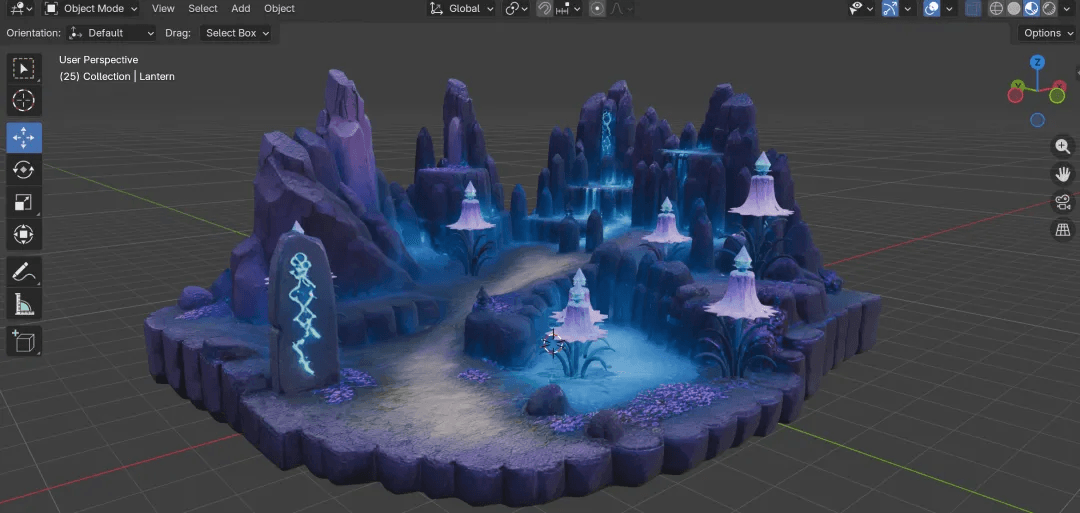
為什麼環境選擇混元而非 Seed 3D: 我針對同一張 Diorama 圖像運行了兩個模型。對於環境而言,混元產生的紋理更飽滿、更紮實。岩石花紋和地面細節表現更好。Seed 的環境嘗試丟失了相當多紋理,整體看起來較為粗糙。因此針對環境與場景,我選擇了混元。針對角色,結論則相反,詳見步驟 7。
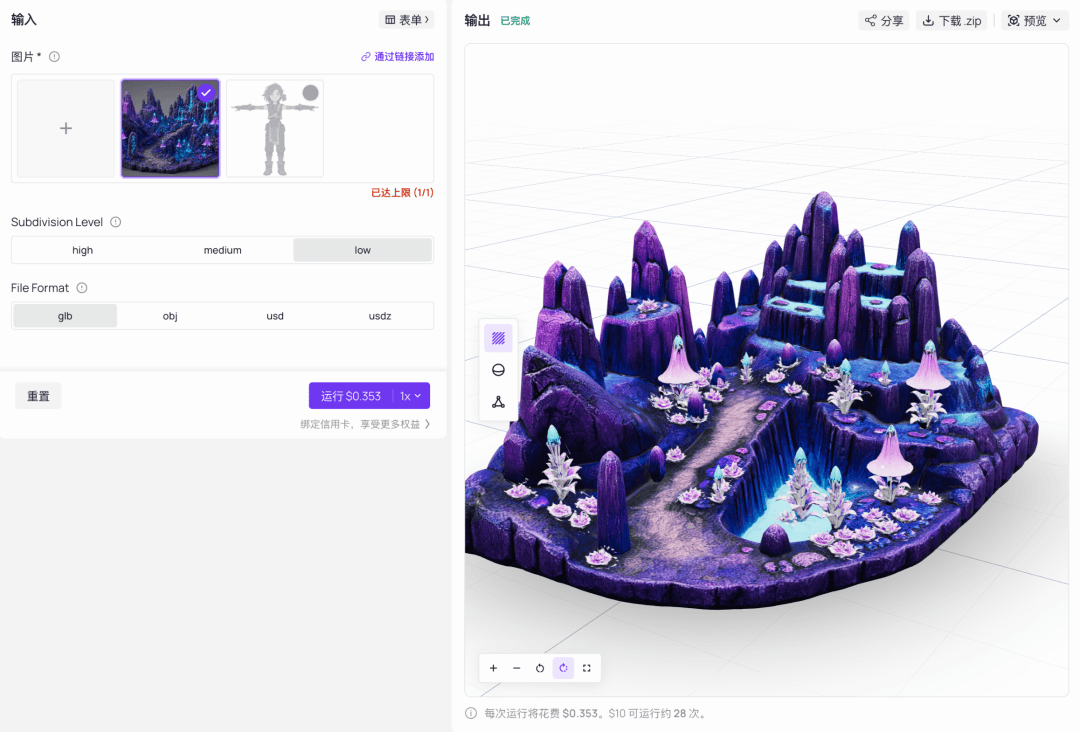
貫穿全專案的一條鐵律:將面數控制在 10 萬以內。 在遊戲中,運行順暢的模型遠比細節過多但卡頓的模型重要。一旦面數過高,綁定會變得困難,引擎負載變重,反覆迭代耗時漫長。對於可玩的遊戲資源,5 萬到 10 萬個面通常已足夠。建模軟體可能動輒提供 50 萬甚至 100 萬個面,那是適合影視或 3D 列印的標準,可遊玩的 Demo 不需要這麼做。
步驟 4 | GPT Image 2:生成 360° 天空盒
遊戲中的星空並未建模,而是引擎中的天空盒(Skybox)——一種包裹住整個世界的全景圖。我再次使用 GPT Image 2,分兩步完成:
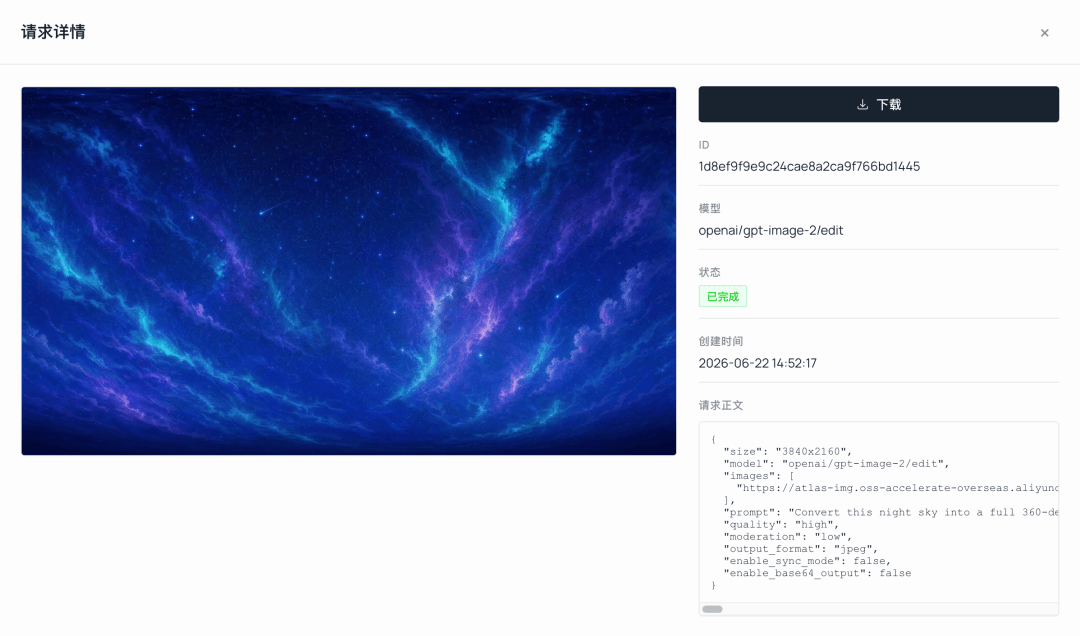
- 首先,以步驟 1 的環境概念圖作為 image-to-image 參考,生成了一張乾淨的星空,去除地形,僅保留天空。色彩與氛圍與原始設定保持一致:深靛色到皇家藍的漸層、密集的星星、青綠色極光、流星與星雲。
- 接著使用
edit將該圖轉換為長寬比 2:1、左右邊緣無縫銜接的 360° 等距圓柱全景圖,隨時可放入引擎作為天空盒。
乾淨天空提示詞 (image-to-image,參考步驟 1 環境圖;長寬比 '2:1'):
plaintext1A pure night sky only, no terrain and no horizon line, bioluminescent dark fantasy game sky: smooth deep indigo-to-royal-blue gradient, a dense field of bright white and pale-cyan stars, soft flowing teal-green aurora ribbons, a faint cyan-and-magenta nebula glow, one or two thin meteor streaks, dreamy magical atmosphere, soft cel-shaded painterly rendering, no ground, no mountains, no characters, sky fills the entire frame.
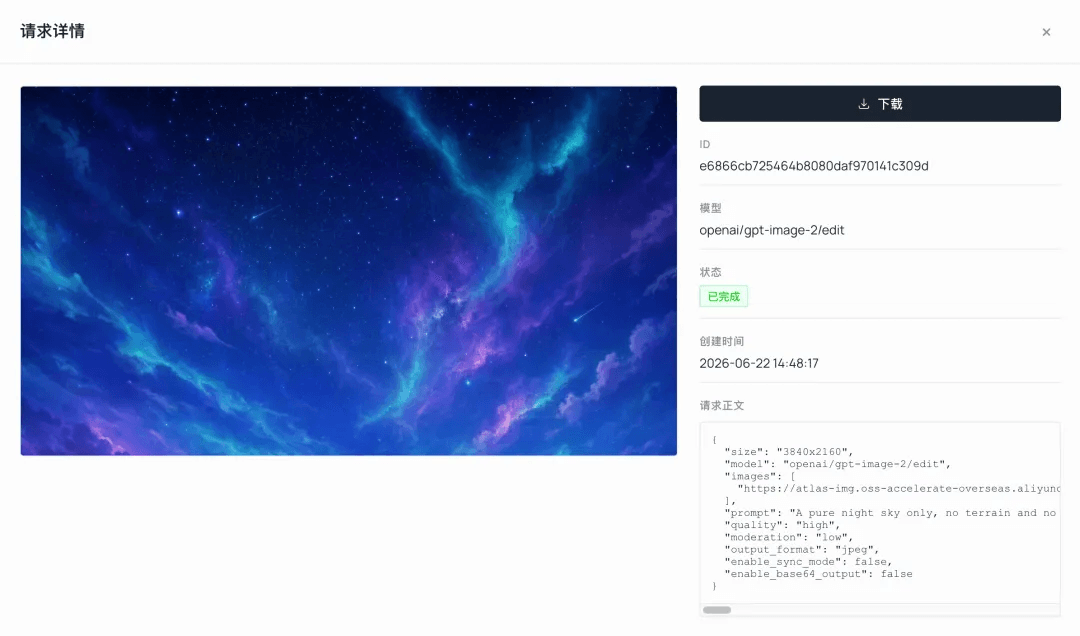
轉換為 360° 全景圖 ('edit',使用上述天空圖;長寬比 '2:1'):
plaintext1Convert this night sky into a full 360-degree equirectangular spherical panorama with a 2:1 aspect ratio, for use as a seamless game skybox. Wrap horizontally so the left and right edges line up with no visible seam. Keep the same teal-and-violet palette, bright stars and soft aurora. No ground, no characters, seamless tiling.
此步驟再次體現了「一個 Key 涵蓋全流程」的優勢。環境圖、Diorama 底圖與天空盒全都由 GPT Image 2 生成,甚至無需切換模型。
步驟 5 | 遊川 MJ V8.1:繪製遊俠主角
環境確立後,就是主角登場的時候了。角色是專案的靈魂。我選用 Atlas Cloud 上的遊川 MJ V8.1,因為其風格一致性與視覺氛圍與專案極為契合。
我想要一位屬於這個世界的藍髮女性遊俠:高馬尾、帶有發光青色符文飾邊的貼身皮革背心、修身的長袖內層、露指手套、合身長褲與結實的靴子。
角色提示詞 (純文字描述;長寬比與風格強度在參數面板設定,未寫入提示詞):
plaintext1full body character design of a young female explorer-ranger, athletic slim build, short tousled hair or a low tied-back ponytail (no long loose hair over the shoulders), wearing a fitted sleeveless leather tunic with glowing teal-rune trim over a slim close-fitting long-sleeve underlayer, fitted trousers tucked into sturdy boots, fingerless gloves and forearm bracers, a small warm-amber lantern clipped at the hip, gentle determined expression, bioluminescent dark fantasy style, cool teal-and-violet palette with warm amber accent glow, soft cel-shaded painterly rendering, calm neutral standing pose with arms held clearly away from the torso, clean plain background, full body visible head to toe, clearly separated arms and legs, NO cape, NO robe, NO flared sleeves, NO face-covering hood, game character concept art, high detail
參數設置: 長寬比 '2:3' 用於垂直全身圖,Style 'raw',Stylize '250'。

全專案最重要的教訓:選擇一個「綁定友好型」的角色。
我最初版本的設計是一位連帽神官,袖子寬大、長袍拖地,加上連帽遮臉與披肩長髮。美術圖雖然精美,但綁定完全崩潰。長袍將雙腿合併成一個圓錐裙,自動綁定無法辨識雙腿在哪裡;寬大的袖子變成隨風飄動的碎片,骨骼無法正確驅動,動起來就嚴重穿模。連帽與臉部共用一個網格,導致骨骼牽引時臉部嚴重變形。
根本問題在於:懸空且寬鬆的布料,那是「布料模擬」的範疇。強行套用在剛性骨骼上,對於初學者來說有明顯的限制。
這就是為什麼選擇肢體分明、穿著貼身的角色會更好。提示詞中反覆出現的
fitted(貼身)、NO flared sleeves(無寬袖)、clearly separated arms and legs(四肢分明)與NO hood(無連帽),絕非偶然。每一條指令都是為了封鎖特定的失敗模式。選對角色,能為後續的綁定省下一半的麻煩。
步驟 6 | Nano Banana 2:保持一致性,重繪正面 T-Pose
MJ 生成的圖固然精美,但依然是插畫,姿勢與視角不規則,無法直接用於建模。3D 建模與綁定最理想的輸入來源是:正面 T-Pose 參考圖,手臂水平伸展、四肢分明且對稱性清晰。這能給 AI 最大的機率將其準確提升為三維立體。
這一步交給了 Nano Banana 2。它將 MJ 概念圖重繪為乾淨的正面 T-Pose,同時保留了角色特徵。我還去掉了她手中的燈籠(燈籠稍後會單獨建模),並縮短、拉平了腰間的布片,以免變成另一個「布料模擬」問題。
T-Pose 處理提示詞 (NB2 'edit',以所選 MJ 角色圖為輸入):
plaintext1Redraw this exact character in a clean front-facing T-pose for 3D modeling: both arms extended straight out horizontally to the sides with a clear visible gap between the arms and the torso, hands open and empty, legs straight and clearly apart (not touching), standing upright, symmetric, facing forward. Keep the identical character identity — blue tousled short hair with a small ponytail, same face, sleeveless vest with glowing teal-rune trim, fitted long-sleeve underlayer, fingerless gloves, fitted trousers, chunky boots, cool teal-and-violet palette with warm accents. Remove the lantern and any held prop. Replace the bulky side hip pouch with a slim flat tactical belt. Shorten the hanging front cloth flap so it ends above mid-thigh, never between the legs. Even neutral lighting, plain pure white background, no shadows, full body head to toe, clearly separated arms and legs, everything fitted close to the body, NO cape, NO robe, NO flared sleeves, NO hood, clean game-character reference.

選擇 Nano Banana 2 的理由很實際:它在保留角色一致性方面表現極佳,換姿勢或視角時臉部與服裝不會偏移。且它速度快、成本低,這讓反覆迭代變得毫無壓力。
這一步本質上是整個管線的「翻譯官」。它將人類看起來好看的圖像,轉化為 3D 模型能讀懂的圖像。
為什麼是 T-Pose 而非 A-Pose?手臂水平伸展時,腋下與軀幹的遮擋最小。Image-to-3D 生成的幾何結構會更乾淨,自動綁定軟體也能更準確地辨識骨架結構。
再補充一點:在將圖片送入 3D 生成模型前,務必徹底清理圖片。使用純白背景、將角色居中、全身入鏡、簡化背景、確保畫面中只有一個主體。步驟 7 的 Seed 3D 模型高度依賴這張圖片來重建角色。輸入對象越乾淨、越突出,生成的幾何結構就越準確。諸如
plain pure white background、full body head to toe與clearly separated arms and legs這些指令都有其必要性。
步驟 7 | Seed 3D:從正面圖到全貼圖角色
這是重頭戲。角色部分,我使用了 Atlas Cloud 上的 Seed 3D(字節跳動模型)。餵入上一步的 T-Pose 正面圖,它直接生成了帶有 PBR 貼圖的完整角色模型。幾何結構與材質一次性到位。同一個 API Key 無縫銜接了從圖像生成到 3D 生成的全過程。
為什麼角色用 Seed,環境卻用混元?我針對相同的素材測試了兩個模型,結論是應該依據應用場景分配:

| 場景 | 模型 | 理由 |
|---|---|---|
| 角色 | Seed 3D | 它在處理頭髮、臉部遮擋的分離上更乾淨,且手套與手指的幾何結構與貼圖更好,更適合作為綁定對象。缺點是遠看時紋理稍顯粗糙。 |
| 環境 | 混元 3D | 如步驟 3 所述,它對岩石紋理等表面細節的處理更飽滿、紮實。 |
為什麼角色工作優先考慮幾何而非貼圖: 角色後續需要綁定與動畫。幾何拓撲結構(如頭髮與臉部是否正確分離、手指是否乾淨)決定了角色能否被完美綁定,這些是不可逆的缺陷。紋理粗糙則是較輕的問題,透過引擎內的光影調試可以彌補,且後續也可以重新烘焙材質。對於角色,Seed 的幾何結構優勢更為關鍵。
實測中,Seed 3D 表現優異。僅憑一張正面圖,它就合理推斷出了後腦勺、身體背面與腳底的樣式,且保持了風格統一。它自帶 PBR 材質,且頭髮與手指生成得非常乾淨——這正是它適合作為綁定角色模型的原因。
Seed 面板設置:
Subdivision Level有三個等級。low約為 10 萬個面,medium為 50 萬,high為 100 萬。遵從面數原則,我為角色選擇了low。格式方面選擇GLB,它包含 PBR 貼圖並能被 Blender 與 Godot 原生識別。下載內容為.zip檔。
步驟 8 | Nano Banana 2 + 混元 3D:構建燈籠道具
我沒有將燈籠與角色模型焊接在一起,而是將其製作為獨立的資源。這樣可以保持綁定與動畫的乾淨,在引擎中只需將燈籠掛載到角色的手骨上即可。
首先,用 Nano Banana 2 生成一張 3/4 視角的乾淨燈籠圖。我確保材質中沒有烘焙發光效果,將亮度的呈現留在引擎內部處理。
燈籠道具提示詞 (NB2 'text-to-image'):
plaintext1A single rugged adventurer's handheld lantern as a standalone 3D game asset, compact portable explorer design, weathered dark gunmetal-and-brass frame with glowing teal-rune engravings, a warm-amber glowing crystal core behind simple flat glass panels, ONE single sturdy fixed carry ring on top only — no side handle, no swinging bail, a few practical leather straps and rivets, bioluminescent dark fantasy style matching a teal-and-violet explorer with warm amber accents, centered on a pure white background, even neutral studio lighting, full object visible, 3/4 orthographic view, true material colors, no strong glow baked in, no shadows, clean reference.
接著送入混元 3D Pro,設置 face_count 為 4 萬,開啟 enable_pbr,格式選 GLB。金屬框與裝飾性的符文材質都被很好地保留了下來。
為什麼道具選用混元而非 Seed: 混元 Pro 允許將
face_count降至 4 萬,而 Seed 的最低下限是 10 萬。對於小道具,4 萬面在引擎中更輕量。

步驟 9 | Mixamo:免費綁定與走跑跳動畫
至此,模型還只是一座雕像。要讓它動起來,需要骨架與動畫。我使用了 Adobe 的免費工具 Mixamo 網頁版。你只需登入 Adobe ID 即可使用,無需編寫程式碼。
綁定與動畫都在 Mixamo 內完成,使用其原生骨架,無需重定向、無需插件、也無需在 Blender 中處理繁雜的工作流。 這就是選擇 Mixamo 的主因。初學者只需上傳模型、點選幾個關鍵點,即可下載一個能走能跳的角色。
- 綁定: 上傳角色模型,標記下巴、手腕、肘部、膝蓋與胯部。Mixamo 會自動生成標準的人形骨架。由於這位遊俠穿著緊身衣且四肢分明,Mixamo 一次就成功識別肢體並完成了乾淨的綁定。
- 動畫: 在 Mixamo 動畫庫中搜尋
Walking、Running與Jumping,直接應用於角色並預覽效果。 - 下載: 針對每個動畫選擇
FBX Binary,勾選With Skin(包含模型),並勾選In Place(原地運動),這樣位移將由引擎程式碼處理,而非動畫自帶位移(否則會導致角色跑出鏡頭)。
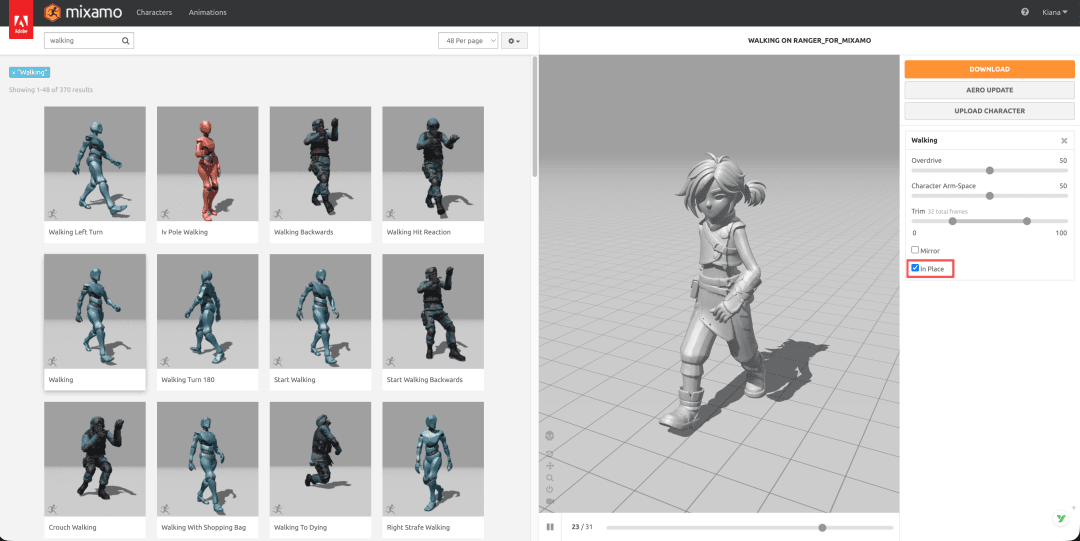
實際遇到的坑 No. 1: 匯入 FBX 時出現 "unable to map your existing skeleton" 錯誤。第一次我是讓 Claude 操作 Blender 匯出 FBX,Mixamo 認為檔案已經包含了骨架,嘗試進行映射導致失敗。Claude 給出的解決方案是將模型匯出為 OBJ,OBJ 不包含骨架概念,強制 Mixamo 重新進行自動綁定,完美繞過了問題。由於綁定不需要貼圖,OBJ 格式已足夠。
實際遇到的坑 No. 2: Mixamo 下載的模型縮放比例為 0.01。匯入 Blender 或遊戲引擎後,角色會變得極小。Claude 自動檢測到模型過小,並將物件縮放比例重置為 1.0(約 1.5 公尺的人類身高)。
幕後真相: Mixamo 處理了自動綁定與動畫,但 Blender 內部的清理工作基本由 Claude 完成。
更精確地說,Claude 是通過 MCP 與 Blender 連結的。你可以將 MCP 理解為一座橋樑,讓 AI 直接操作電腦軟體。它為我處理了一連串零碎、易出錯的步驟:自動匯入 Mixamo 下載的 FBX、恢復縮放比例、對齊網格與骨骼、將 Mixamo 剝離的貼圖重新掛載回 Seed 原廠材質,最後匯出引擎可用的 GLB。我只需檢查結果,並告訴它下一步。
步驟 10 | Godot 4:引擎整合與行走實現
最後一步是 Godot 4。它免費、開源、安裝包僅約 100MB,無需註冊,且對 GLB 原生支援。這是氛圍融合的地方。引擎本身不是重點,如果你熟悉 Unity,道理也是一樣的。我選擇 Godot 是因為它輕量且學習曲線短。其專案檔為純文字,這意味著 Claude 可以直接編寫、修改並運行整個 Godot 專案,無需我手動拉控制項。
Claude 自動將三個 GLB 資源匯入專案:角色、環境與燈籠,隨後配置了以下內容:
- 角色控制器: 使用
CharacterBody3D加上幾十行 GDScript,實現了 WASD 移動、Shift 奔跑、空白鍵跳躍、滑鼠旋轉相機,以及跟隨角色的第三人稱相機。 - 動畫狀態機: 靜止時 Idle,移動時 Walk/Run,空中時 Jump。只需幾個條件判斷切換 Mixamo 動畫。
- 天空盒:
WorldEnvironment連結PanoramaSkyMaterial,放入步驟 4 生成的 360° 全景圖,星空立刻環繞整個世界。 - 體積霧與輝光: Godot 4 內建真實體積霧,結合鈴鐺狀花朵的自發光與 Bloom 特效,迅速營造出夢幻峽谷的氛圍。
- 燈籠光影: 將燈籠作為角色手骨的子物件,內部放置暖黃色
OmniLight3D點光源。光源隨角色移動,照亮地面,帶來強烈的探索感。
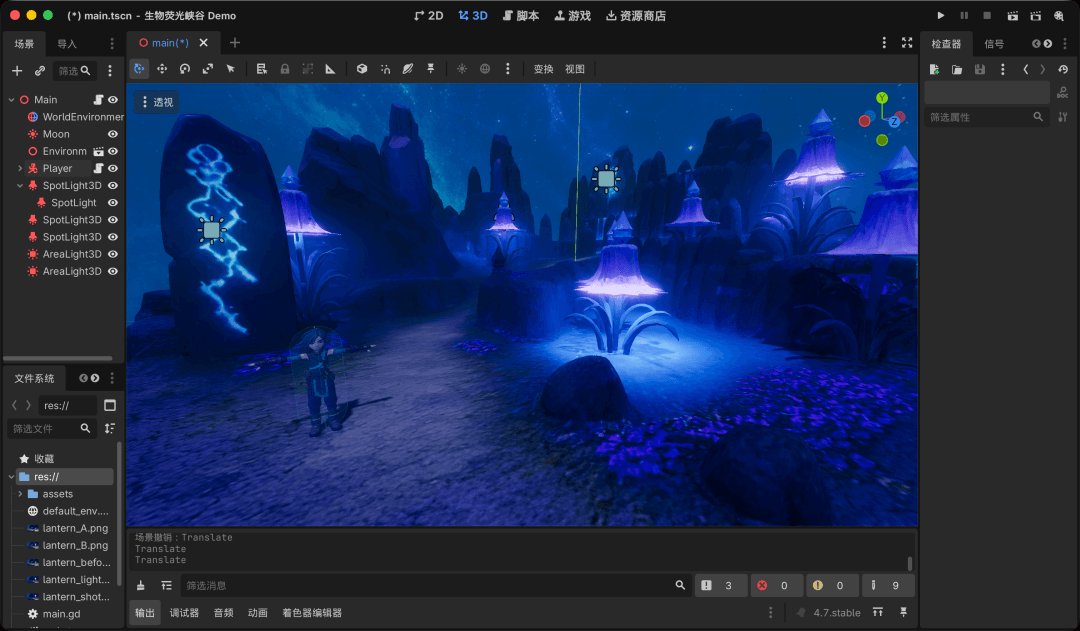
Godot 專案本身也由 Claude 編寫。專案配置、場景與控制器腳本皆為純文字。我描述想要的互動與相機氛圍,Claude 直接在專案中寫入、修改、運行檢查,直到效果滿意。
從圖像生成、3D 生成到 Blender 組裝與 Godot 場景配置,Claude 承包了程式設計師的工作。我只需要描述我想要的。我說我沒寫過一行底層代碼,並不是說沒有代碼,而是 Claude 為我分擔了技術負擔。
為什麼我選擇 Atlas Cloud 作為整個工作流的平台
這個工作流最困難的部分,並不一定是學習某個工具,而在於「在十幾個平台間來回跳轉」,每個平台都有各自的註冊、帳單與 API 整合問題。Atlas Cloud 簡化了一切:
- 全流程一個 API Key: 這是最重要的點。GPT Image 2 負責環境與天空盒,MJ 負責角色,Nano Banana 2 負責視角轉換,Seed 3D 與混元 3D 負責建模:所有模型共用一個 Key。無需切換、無需重複整合。這是單人完成專案的現實基礎。
- One API for All Media AI: 一個接口可以調用超過 300 種模型,涵蓋圖像生成、3D、影像與大語言模型。切換模型時,只需更改模型名稱參數。
- 新增的 3D 模型類別: 3D 生成類別納入了字節跳動的 Seed 3D 與騰訊的混元 3D。一鍵式生成帶 PBR 貼圖的 Image-to-3D 是讓工作流跑通的最後一塊拼圖。實測中,Seed 在角色表現更好,混元在環境表現更好。
- 同一個 Key 涵蓋前沿大模型: 別忘了幕後的總指揮。Atlas Cloud 同時提供前沿 LLM API。LLM、影像模型、3D 模型全都在同一個 Key 下,這才實現了單人工作流。
- 具競爭力的定價: 圖像與 3D 生成的成本低廉,足以支持反覆嘗試與修正。
- 不只是 API:MCP、CLI 與技能: 該接口兼容 OpenAI,可作為隨插即用的整合方案。不僅如此,Atlas Cloud 還提供自己的 MCP Server、命令行 CLI 與技能(Skills)。當 AI 自己能調用平台模型時,將影像、3D 與完整工作流連結成一條線,就變得自然而然。
一句話總結:曾經需要一個團隊和十幾個帳號才能完成的工作,現在一個人、一個 API Key,從一句文字描述開始,就能得到一個能跑、能跳的 3D 世界。
現在嘗試看看
打開 Atlas Cloud,進入最新的 3D 模型類別,從生成你的第一個角色開始。你不需要具備建模或程式背景,AI 能搞定建模,引擎能帶出氛圍,而你的工作,就是去想像那個世界。
本文使用的所有模型,包括 GPT Image 2、遊川 MJ V8.1、Nano Banana 2、Seed 3D、混元 3D 以及 Claude,皆可在同一個模型池中找到。
如何在 Atlas Cloud 上使用這些模型?
Atlas Cloud 允許你並行使用模型——先在 Playground 中測試,再通過一個 API 進行調用。
方法 1:直接在 Atlas Cloud Playground 中使用
點擊連結 https://www.atlascloud.ai 即可在網頁 Playground 中使用。
方法 2:通過 API 調用
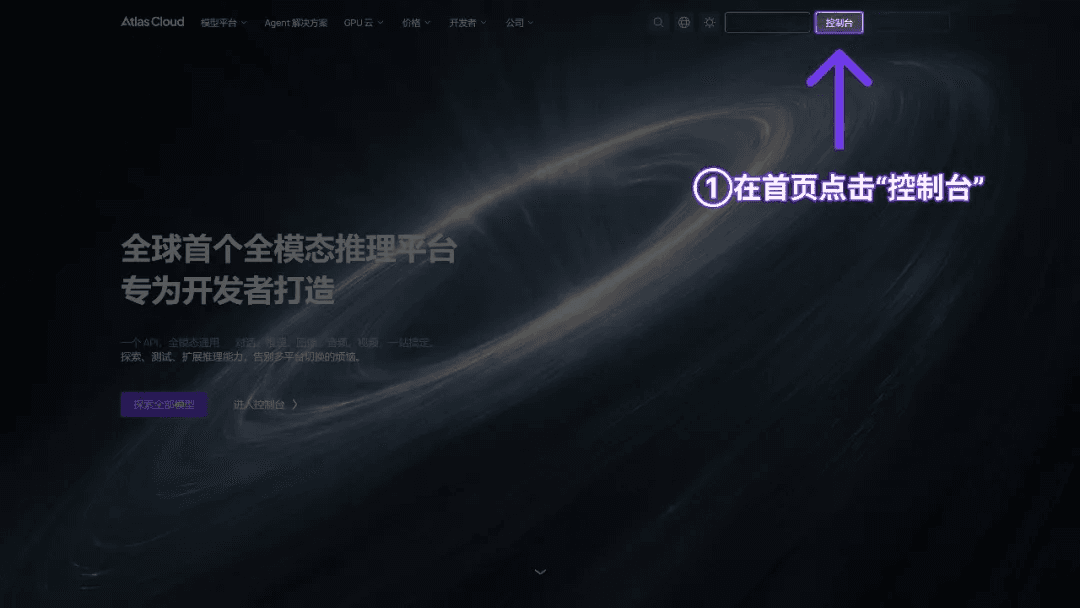
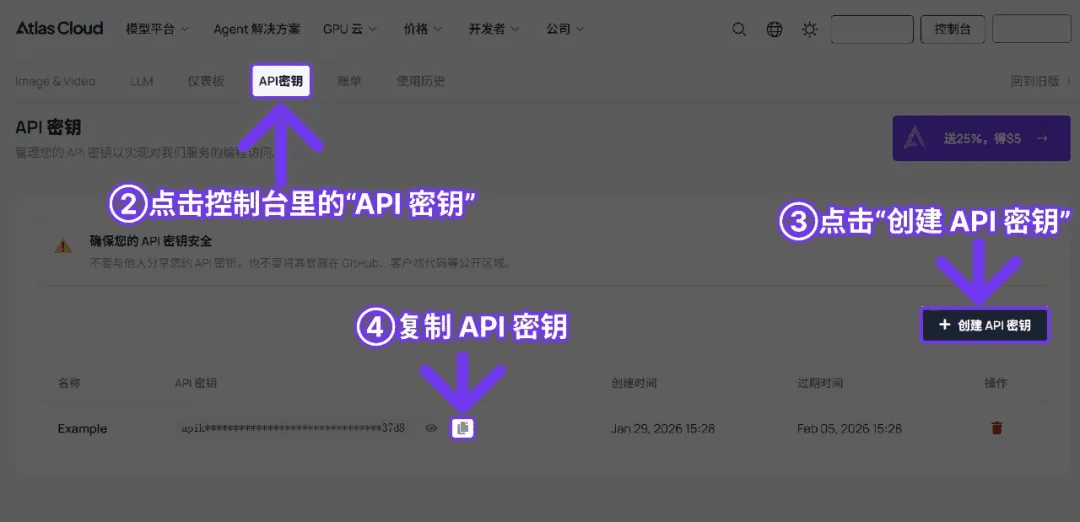
步驟 1:取得 API Key
在你的 Console 創建一個 API Key,並複製以備後續使用。
步驟 2:查看 API 文件
在我們的 API 文件 中查看端點、請求參數與認證方法。






