
中國 AI 實驗室已經悄悄構建了當今市面上最強大的一些開源程式設計模型。對於那些只關注 Anthropic 和 OpenAI 市場動態的開發者來說,來自 DeepSeek、月之暗面 (Moonshot)、智譜 AI (Zhipu)、MiniMax 和阿里巴巴目前所提供的廣泛選擇著實令人驚喜。
2026 年值得探討的問題不再是「這些模型好不好」,而是「哪個模型適合哪種工作負載」、「大規模運行它們的成本是多少」,以及「如何將它們整合到你現有的工具中」。本指南將涵蓋這三方面:各實驗室的模型介紹、完整的規格與成本對照表、實用的工作負載路由指南,以及針對 Claude Code、Codex 和 OpenClaw 的設定配置。
![]()
為什麼最佳開源程式設計 LLM 正受到重視
轉折點是 2024 年 12 月發布的 DeepSeek V3。它在 HumanEval 上得分 89.1%,在 SWE-bench Verified 上得分 42.0%,當時已足以與 Claude 3.5 Sonnet 和 GPT-4o 競爭,且採用了專家混合 (MoE) 架構,每次前向傳遞僅激活 6710 億參數中的 370 億 (DeepSeek-V3 技術報告,2024 年 12 月)。該架構帶來的效率解釋了為什麼推理成本能大幅降低。
這一結果將開發者的目光吸引到了更廣闊的中國開源生態系統上。事實證明,DeepSeek 並非個例。月之暗面 (Moonshot AI) 的 Kimi K2 系列一直在長文本基準測試中處於領先地位;阿里巴巴的 Qwen2.5-Coder 系列在程式設計基準測試中名列前茅;智譜 AI (Zhipu) 的 GLM-5 系列則能產生精確的結構化輸出,這對於代理 (Agentic) 工作流至關重要。
對開發者而言,實際意義在於:現在有五家獨立的實驗室提供能處理生產環境編碼任務的模型,這些模型擁有開放權重或商業 API 存取權,且價格遠低於專有模型。
最佳開源程式設計 LLM 背後的實驗室
DeepSeek:編碼優先的設計與 MoE 效率
DeepSeek AI 成立於 2023 年,由幻方量化 (High-Flyer Capital) 支持,從一開始就將編碼作為其模型核心。DeepSeek-Coder 是最早引起開源社群高度關注的專用代碼生成模型之一。V3 和 V4 系列在保持強大編碼性能的同時,將能力擴展到了通用推理領域。
了解 MoE 架構對於理解其定價至關重要。透過每次 token 僅激活部分參數,請求的計算成本遠低於同等品質的稠密模型。這種效率體現在 API 定價上,這就是為什麼 DeepSeek V4 Flash 每千 token 0.23 credits 的輸入價格能夠在不犧牲簡單任務品質的情況下實現。
月之暗面 (Moonshot AI/Kimi)、智譜 AI (GLM)、MiniMax 與阿里巴巴 (Qwen)
月之暗面 (Moonshot AI) (成立於 2023 年,北京) 以長文本推理聞名。Kimi K2 系列具備 262K token 的上下文窗口,專為需要將大型程式碼庫放入單次呼叫的文檔密集型和代碼密集型任務而設計。
智譜 AI (Zhipu AI) (成立於 2019 年,源自清華大學 KEG 實驗室) 是中國資歷最深的 AI 公司之一。GLM 系列已迭代五代,每一代都在提升結構化輸出的可靠性和指令遵循能力。GLM-5.1 反映了多年來在精確任務執行方面的對齊工作。
MiniMax (成立於 2021 年) 從多模態領域擴展到代碼模型,推出了 M2 系列。MiniMax M2.5 和 M2.7 提供了涵蓋中階市場的性價比選擇。
阿里巴巴 Qwen 團隊在強大的編碼模型基礎上構建了 Qwen3.6-plus。該系列在多語言代碼生成方面表現始終穩定,且 256K+ 的上下文窗口處於現有選項的頂端 (QwenLM GitHub,2025)。
最佳開源程式設計 LLM 比較:上下文、成本與規格
以下是按輸入費率排序的當前模型完整表格,以便快速比較成本結構:
| 模型 | 實驗室 | 上下文 | 輸入費率 | 輸出費率 | 快取寫入 | vs 官方 |
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0.23 | 0.46 | 0.046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0.42 | 0.62 | 0.193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0.65 | 2.18 | 0.109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1.09 | 5.45 | 0.182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1.72 | 7.26 | 0.290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1.82 | 5.81 | 0.363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2.36 | 4.00 | 0.109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2.54 | 7.99 | 0.472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2.87 | 5.75 | 0.231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3.30 | 9.90 | 0.660 | -50% |
費率為每 1,000 token 的 credits。「vs 官方」是指相比該模型官方 API 費率節省的比例。
幾點觀察:首先,DeepSeek V4 Flash 的輸入 0.23 與 V4 Pro 的 2.87 來自同一實驗室,這意味著單一模型家族內部的最便宜與最強大版本之間有 12.5 倍的成本差距。其次,Kimi K2.5 以 1.09 的輸入費率提供了 262K 上下文窗口,這對於不需要 V4 Pro 等級但需要長文本處理的任務來說極具吸引力。第三,Qwen3.6-plus 的輸出費率為 9.90,是組內最高的,這表明它在設計上傾向於更長、更詳盡的生成結果。
每種開源程式設計 LLM 的最佳適用場景
這是實務應用部分。當你運行代理化 (Agentic) 編碼會話時,上述費率將直接影響你的路由決策。
輕量與背景任務:DeepSeek V4 Flash 用於 Docstrings、變數重新命名、簡單代碼補全、格式轉換以及編碼代理自動進行的所有背景效用呼叫。其輸入 0.23 和輸出 0.46 的費率使其成為組內最便宜的選擇。當 Claude Code 將背景任務路由到 Haiku 模型槽位時,將其指向 DeepSeek V4 Flash 可以確保背景噪聲成本低廉,同時將主會話留給更強大的模型。
兼顧預算與性能的編碼:DeepSeek V3.2 和 MiniMax M2.5 DeepSeek V3.2 在 160K 上下文窗口下提供 V3 架構,價格優惠 55%。對於不想支付完整 V4 Pro 價格但需要穩健編碼能力的開發者來說,V3.2 是務實之選。MiniMax M2.5 以 0.65 的輸入費率填補了類似區間,在上下文重要性高於極致價格時非常有用。
長文本工作負載:Kimi K2.5 和 K2.6 這兩款 Kimi 模型均提供 262K 上下文窗口。對於傳遞大型程式碼庫片段、分析冗長的對話歷史或多文件重構任務,Kimi K2.5 是不錯的選擇。而 K2.6 (1.72 輸入費率) 則在 K2.5 的基礎上提升了能力,適合品質優先於純成本的場景。
結構化輸出與指令精確度:GLM-5 和 GLM-5.1 智譜 AI 的 GLM 模型在指令遵循方面表現卓越。對於需要可靠結構化輸出 (特定 JSON schema、格式化代碼片段、一致的 API 回應結構) 的管道,GLM-5 和 GLM-5.1 非常值得一試。其輸出費率較高,反映了它們傾向於產生詳盡、精細的補全結果。
旗艦級推理:DeepSeek V4 Pro 和 Qwen3.6-plus 對於複雜的架構決策、除錯多系統交互,或首輪生成品質至關重要的任務,V4 Pro 和 Qwen3.6-plus 是頂級選擇。V4 Pro 的 1M 上下文窗口是其核心賣點;Qwen3.6-plus 的 256K+ 窗口在 DeepSeek 家族之外也處於領先地位。
模型路由:最常被忽視的開源程式設計 LLM 策略
對於使用這些中國開源 LLM 的開發者來說,最高效的優化不是選擇最好的單一模型,而是針對同一會話中的不同任務類型進行路由。
考慮一個典型的代理編碼會話:規劃方法 (複雜,需要 V4 Pro)、編寫核心演算法 (複雜,V4 Pro)、生成測試案例 (中階,MiniMax M2.5 或 Kimi K2.5)、為新函數編寫 Docstrings (輕量,V4 Flash)、讀取文件 (輕量,V4 Flash)。如果全部使用 V4 Pro,那麼這些輕量步驟的成本將比必要高出 12.5 倍。
這筆帳很容易算。假設會話中的 50 次 API 呼叫有 60% 是簡單任務,平均每次 2,000 輸入 + 500 輸出 token。若在 V4 Flash 上運行:
- 成本:30 次呼叫 × (2,000 × 0.23 + 500 × 0.46) = 30 × (460 + 230) = 20,700 credits
若全在 V4 Pro 上運行:
- 成本:30 次呼叫 × (2,000 × 2.87 + 500 × 5.75) = 30 × (5,740 + 2,875) = 258,450 credits
僅僅這 30 次呼叫就有 12.5 倍的差距。模型路由帶來的效益立竿見影。
如何選擇適合你工作流的最佳開源程式設計 LLM
以下決策樹涵蓋了大多數開發者的場景:
- 你需要單次請求的最大上下文:選擇 DeepSeek V4 Pro (1M) 或 Qwen3.6-plus (256K+)。它們能處理大型代碼庫輸入而無需分塊。
- 成本是首要約束:簡單任務選 DeepSeek V4 Flash,中等複雜度任務選 DeepSeek V3.2 或 MiniMax M2.5。
- 你需要可靠的結構化輸出:從 GLM-5.1 開始,並根據你的具體架構要求進行測試。
- 你正在構建多步驟代理管道:按步驟複雜度路由。效用步驟用 Flash,中階推理用 Kimi K2.5 或 GLM-5,規劃與除錯用 V4 Pro。
- 你想要嘗試第一個模型:DeepSeek V4 Pro 是首次評估中國 LLM 的開發者的自然預設選項。它文檔完善,在 (r/LocalLLaMA) 上擁有最廣泛的社群覆蓋,並提供旗艦級的編碼品質。
實際挑戰在於,高效路由要求所有模型都位於同一個 API 金鑰和 Base URL 之後。管理十個不同的 API 帳戶是不現實的。這正是統一閘道解決的問題:一個端點,一個金鑰,模型選擇僅是一個參數。
在你的編碼工具中運行開源程式設計 LLM
Atlas Cloud Coding Plan 將本指南涵蓋的所有十個模型整合在單一 API 金鑰和 Base URL 之下,價格比官方 API 低 45-55%。各主流編碼工具的設定如下。
關於 Base URL 的提示:Claude Code 使用 https://api.atlascloud.ai 且不帶 /v1 後綴。其他所有工具 (Codex, OpenClaw, OpenCode, Cursor) 均使用 https://api.atlascloud.ai/v1 並帶有後綴。如果搞錯,會產生無法直接指向原因的認證錯誤。
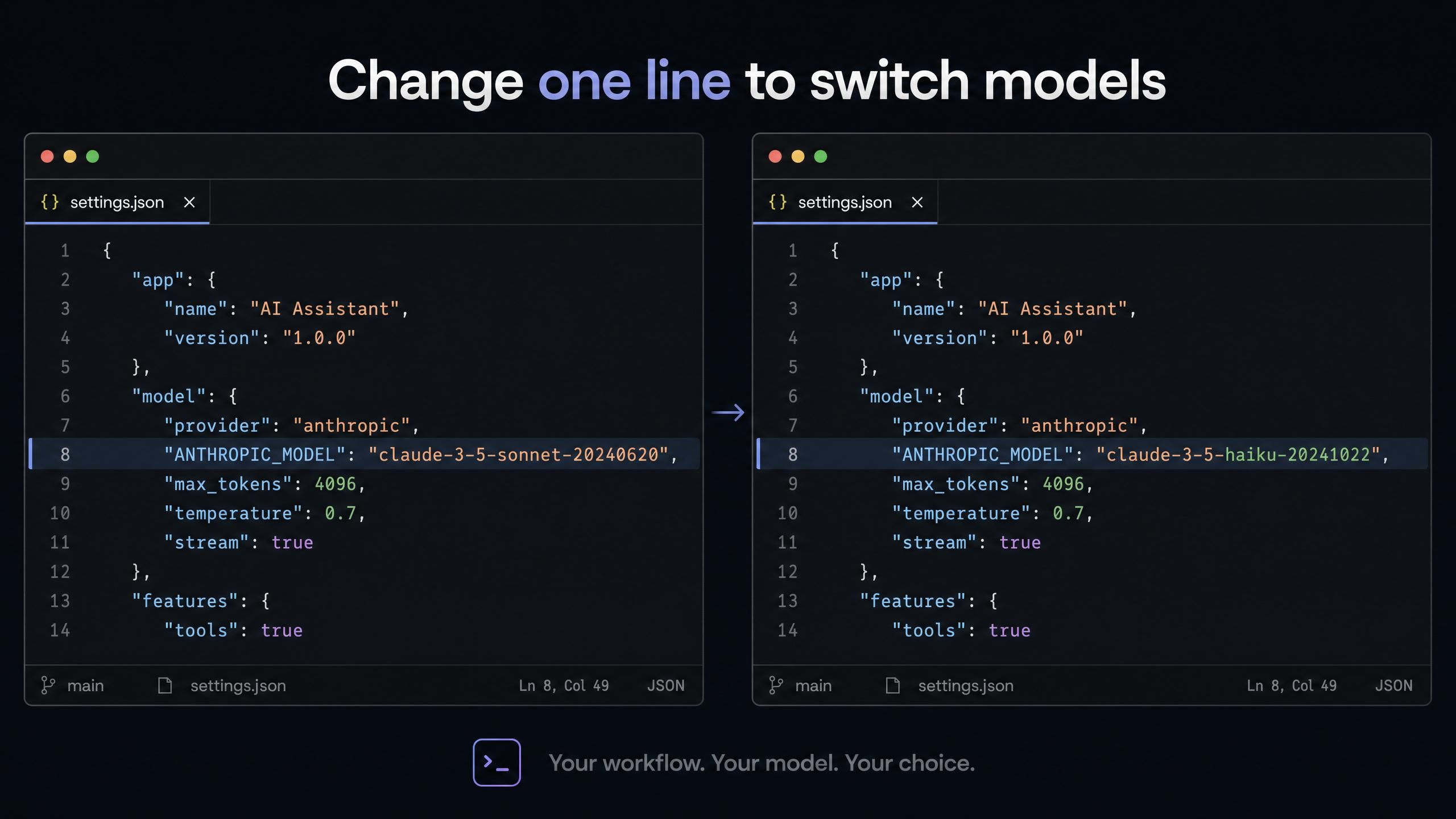
Claude Code (~/.claude/settings.json):
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
ANTHROPIC_DEFAULT_HAIKU_MODEL 對應 Claude Code 的背景任務槽位。將其設為 DeepSeek V4 Flash,所有自動化的效用呼叫都會使用最便宜的模型,而你的主 Prompt 使用 V4 Pro,無需任何額外的路由邏輯。
Codex (~/.codex/config.toml + ~/.codex/auth.json):
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
OpenClaw:運行 openclaw onboard,選擇 QuickStart,然後選擇 Custom Provider。輸入 https://api.atlascloud.ai/v1 作為 Base URL,貼上你的金鑰,輸入模型 ID (例如 moonshotai/kimi-k2.5),並選擇 OpenAI 相容協議。
在這些設定中切換模型只需修改一行代碼。無論選擇哪個模型,API 金鑰和 Base URL 都保持不變。
最佳開源程式設計 LLM 常見問題
DeepSeek 真的是最好的開源程式設計 LLM 嗎? 對大多數開發者來說,基於社群覆蓋率、基準測試成績以及 1M 上下文窗口與價格的平衡,DeepSeek V4 Pro 是首選。但「最好」在很大程度上取決於任務類型。對於長文本,Kimi K2.5/K2.6 提供 262K token;對於結構化輸出,GLM-5.1 更勝一籌。重點在於,「最好」取決於你正在構建的產品。
這些模型與 Claude Sonnet 或 GPT-4o 在編碼方面相比如何? 在標準編碼基準測試中,頂級開源模型與美國專有模型之間的差距自 2024 年以來已大幅縮小。DeepSeek V3 在發布時已在多個基準上與 Claude 3.5 Sonnet 持平。專有模型目前在細膩的指令解釋和受益於廣泛 RLHF 調整的任務上仍具優勢。但對於大多數代碼生成、重構和除錯任務,對開發者而言的實際差異很小。
我能在同一個管道中使用多個開源 LLM 嗎? 可以。當所有模型透過閘道共享 Base URL 和 API 金鑰時,你可以為每個請求指定不同的模型 ID。這意味著你可以在一個自動化工作流中,針對不同步驟混合使用 DeepSeek V4 Flash、Kimi K2.5 和 V4 Pro,無需管理多個帳戶。
我應該先試哪個模型? 從 DeepSeek V4 Pro 開始。它擁有最豐富的文檔、最廣泛的社群討論和最清晰的性能資料。建立基準後,針對上下文密集型步驟測試 Kimi K2.5,針對背景效用任務測試 DeepSeek V4 Flash。
開源 LLM 對企業代碼安全嗎? 這取決於你的部署模型。對於透過第三方閘道的 API 存取,適用該閘道的數據處理政策。可自託管的開源權重模型則賦予你對代碼位置的完全控制權。在 r/LocalLLaMA 的共識是,API 使用方式應遵循與任何第三方 API 相同的數據審查標準,而非特殊擔憂類別。
總結
現在有五家實驗室提供足以處理嚴肅生產編碼工作的模型,它們的成本和能力涵蓋範圍足夠廣,如果仍然堅持一刀切的選擇,那你無疑是在浪費預算。
實踐策略:選擇一個能讓你透過單一金鑰存取所有這些模型的閘道,以 DeepSeek V4 Pro 為基準,然後利用上述路由指南將簡單任務分流至更便宜的模型層級。對於大多數開發者而言,僅僅這一項路由優化就能在不改變輸出品質的前提下顯著降低成本。
模型規格與費率基於 2026 年 5 月的 Atlas Cloud Coding Plan 文件。DeepSeek V3 基準數據來自 2024 年 12 月的 DeepSeek-V3 技術報告。費率可能會有變動,請在作出計費決策前與各服務商確認最新數據。






