
大多數開發者認為 Codex CLI 的運作方式像聊天機器人:你發送訊息,模型回覆,結束。但事實並非如此。Codex 執行的是一個代理循環(agent loop),這意味著每個任務都涉及多次 API 呼叫,且上下文視窗會在每次迭代後不斷擴大。當 Codex 完成一項中等複雜度的任務時,總 Token 數往往是你預期單次呼叫的三到五倍。
這就是幾乎所有「我觸及了使用上限」案例背後的根本原因。你並不是在與速率限制政策作鬥爭,而是在應對代理工作流(agentic workflow)的自然經濟學,且這種經濟成本會迅速累加。
一旦你了解成本的真正來源,解決方案就會變得顯而易見,而不是盲目猜測。
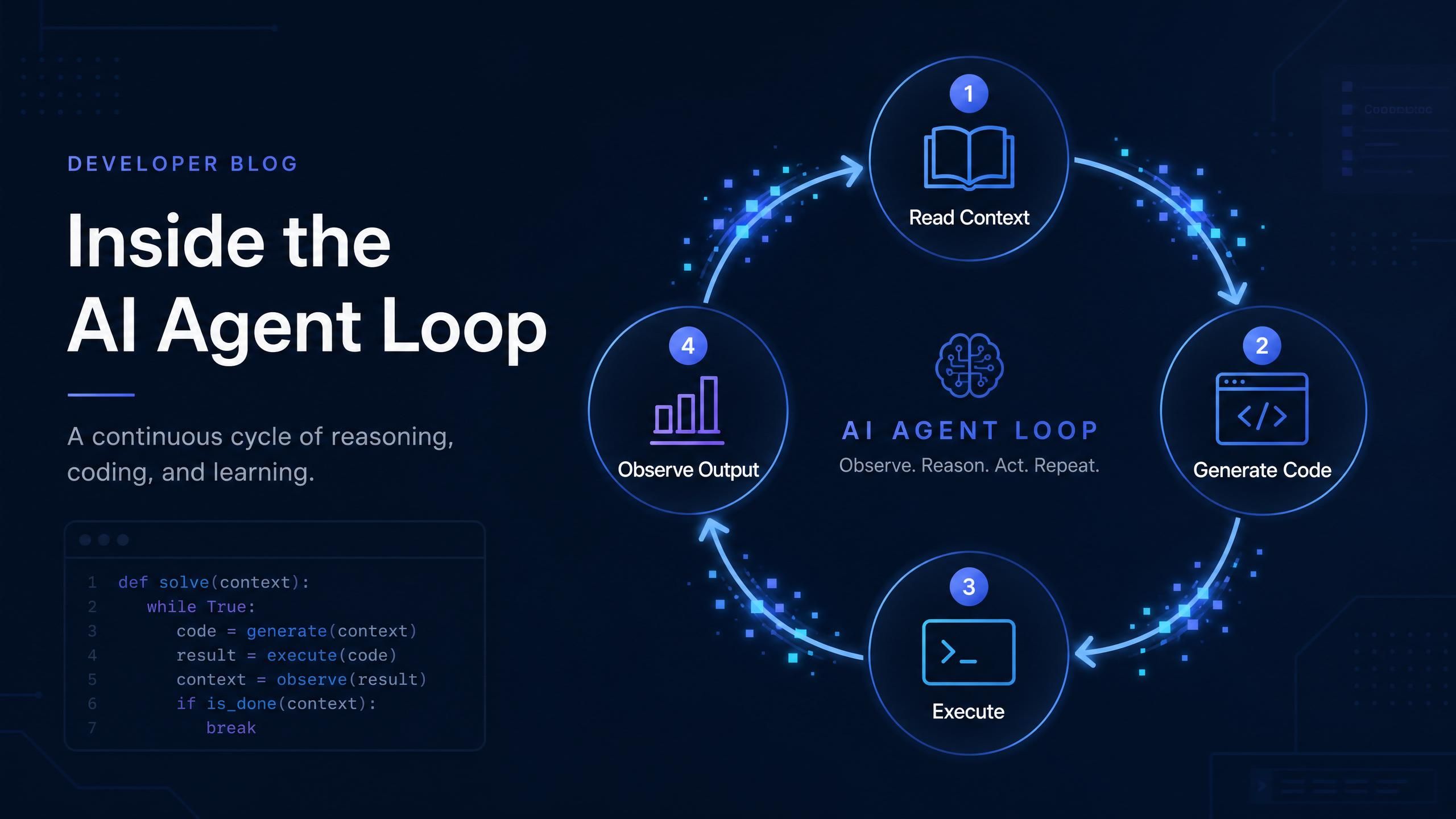
Codex CLI 如何在單次工作階段中累積成本
一個典型的 Codex 任務若需要四次迭代,其成本並非單次呼叫的 4 倍,而是高出許多,因為上下文會隨著每次轉折(turn)而增長。
以下是底層實際發生的狀況。在第一次迭代中,Codex 讀取你的專案檔案及任務描述,向模型發送約 5,000 到 7,000 個輸入 Token,並獲得回覆。在第二次迭代中,它會包含先前的對話紀錄,以及執行所生成程式碼後的新觀察結果。該次呼叫的輸入 Token 數可能會跳升至 8,000 或 10,000。到了第四次迭代,累積的上下文可能已達 14,000 個輸入 Token,而這在概念上仍是同一個任務。
Codex 任務在 4 次迭代中的上下文增長
| 迭代 | 輸入 Token |
|---|---|
| 迭代 1 | ~5,000 |
| 迭代 2 | ~7,000 |
| 迭代 3 | ~9,500 |
| 迭代 4 | ~14,000 |
| 總計 | ~35,500 |
在代理工作階段中,上下文大小會隨著迭代累加。一項 4 次迭代的任務總共可能消耗 35,500 個輸入 Token,而非單次呼叫的 5,000 個。實際數量取決於專案規模與檔案上下文。
實際影響是:一項 4 次迭代的任務成本並非單次呼叫的 4 倍,由於上下文不斷增長,其成本接近 7 到 8 倍。以本例而言,整個任務共消耗約 35,500 個輸入 Token 和 4,000 個輸出 Token。你選擇的模型決定了這項任務究竟是消耗 9,000 點數還是 120,000 點數,儘管是在同一個 Codex CLI 上且任務描述完全相同。
這 13 倍的差距正是 Codex 使用上限解決方案的核心:不在於請求限制,而在於選擇哪個模型來運行循環。
Codex 使用上限解決方案:優先進行檔案範圍界定(File Scoping)
這是無需成本且效果最顯著的優化手段。
Codex 在進行任何 API 呼叫前,都會讀取你的專案檔案以建立上下文。雖然它會遵守你的 .gitignore,但大多數程式碼庫中都有大量 .gitignore 不會排除的內容:類型宣告檔案、廠商文件、編譯後的輸出目錄、測試裝置(test fixtures)、種子數據、生成的 CSS 或 SVG。所有這些內容都會進入第一次迭代的上下文視窗,並增加後續每次呼叫的基礎成本。
解決方法是刻意排除。在專案根目錄下添加一個 .codexignore 檔案,語法與 .gitignore 相同。建議加入的常見模式:
plaintext1dist/ 2.next/ 3build/ 4node_modules/ # 以防 .gitignore 有遺漏 5*.d.ts # TypeScript 宣告檔案 6*.min.js 7*.min.css 8test/fixtures/ 9test/snapshots/ 10docs/vendor/
或者,當任務僅限於特定模組時,請從該目錄內部執行 Codex,而不是從專案根目錄執行。代理程式會從其工作目錄讀取檔案,因此執行 cd packages/auth && codex session 只會讀取該套件的檔案,而非整個 monorepo。
在 r/LocalLLaMA 上討論此問題的開發者一致指出,未受控的檔案上下文是代理工具導致意外 API 支出激增的主要原因。在中型專案中,在觸碰任何其他設定前先做好這一點,通常能將每個工作階段的 Token 數減少 30% 到 60%。
在多套件專案中,從相關套件的子目錄而非 monorepo 根目錄執行 Codex,使單次任務的上下文從約 18,000 個 Token 降至約 5,000 個。這個差異會在每一次迭代中累加。
改變長期成本計算的 Codex 使用上限解決方案
一旦你收緊了檔案上下文,下一個結構性調整就是你所運行的模型。
Codex CLI 透過 config.toml 支援自訂 API 提供商。任何實作了 OpenAI Chat Completions 格式的提供商都可以直接替換使用。這意味著你可以運行完全相同的 Codex CLI 工作流,但由不同模型提供動力,且每個 Token 的成本大不相同。
為什麼這很重要?因為點數乘數(或每 Token 費率)會乘以每次迭代中的每個 Token。在一項消耗 35,500 個輸入 Token 和 4,000 個輸出 Token 的 4 次迭代任務中,從高乘數模型切換到低乘數模型絕非小調整。對於同一個任務,這意味著消耗 9,545 點數與 119,145 點數之間的差異。
Atlas Cloud 的 Coding Plan 提供了一系列開源模型,價格比官方 API 費率低 45% 到 55%,且皆可透過單一 API 金鑰在 OpenAI 相容的端點上存取。你只需將 Codex 指向 https://api.atlascloud.ai/v1,設定你的模型 ID,工作流中的其他部分皆無需更動。
解讀乘數:哪種 Codex 使用上限解決方案適合各類任務
以下是使模型選擇具體化的計算方式。使用我們 4 次迭代的任務(總計 35,500 個輸入 Token,4,000 個輸出 Token),以下是各可用模型的每任務點數成本:
各模型每 4 次迭代 Codex 任務的點數消耗
| 模型 | 點數 / 任務 | vs. 最便宜 |
|---|---|---|
| deepseek-v4-flash | 9,545 | 🟢 基線 |
| deepseek-v3.2 | 17,390 | 1.8x |
| minimax-m2.5 | 31,845 | 3.3x |
| kimi-k2.5 | 60,695 | 6.4x |
| deepseek-v4-pro | 119,145 | 12.5x |
| glm-5.1 | 122,025 | 12.8x |
來源:根據 Atlas Cloud 2026 年 6 月發佈的乘數計算。對於兩者皆能完成的任務,DeepSeek V4-Flash (9,545) 比 DeepSeek V4-Pro (119,145) 每任務便宜 12.5 倍。
憑藉 Starter 方案的每日 800,000 點數(10 美元/月),你可以執行:
- DeepSeek V4-Flash: 800,000 / 9,545 = 每天 83 次四迭代任務
- DeepSeek V4-Pro: 800,000 / 119,145 = 每天 6.7 次任務
在 Lite 方案(20 美元/月,基於目前等級配置,每天 220 萬點數):
- DeepSeek V4-Flash: 2,200,000 / 9,545 = 每天 230 次任務
- DeepSeek V4-Pro: 2,200,000 / 119,145 = 每天 18 次任務
實用的架構是:DeepSeek V4-Flash 能妥善處理絕大多數的 Codex 任務。編寫工具函數、產生測試、修復 Lint 錯誤、重新命名變數、建構模板——這些都不需要最前線的推理能力。V4-Flash 支援 100 萬個 Token 的上下文視窗,並能勝任這些任務。V4-Pro 和 Kimi K2 則值得用於真正困難的問題:複雜的多檔案重構、偵錯晦澀的生產問題、處理不熟悉的框架。
針對適當的任務選擇合適的模型並非品質上的妥協,而是「不該用大錘來敲細釘子」。
V4-Flash 與 V4-Pro 之間的差異不僅僅是「便宜與否 vs. 品質」。在常規 Codex 任務中,品質差異微乎其微,但成本差異高達 12.5 倍。在檔案範圍界定之後,將 V4-Pro 保留給真正複雜的工作階段,是槓桿效益最高的優化手段。
透過工作階段界限解決 Codex 使用上限
有一個行為改變在每週累積下來意義重大:謹慎決定何時開始新的 Codex 工作階段,何時繼續現有的。
每個工作階段都會累積對話紀錄。工作階段持續越長,後續每次呼叫的基礎上下文就越大。一個以 5,000 個 Token 的第一輪對話開始並運行了六次交流的工作階段,到最後可能有 18,000 個 Token 的上下文。如果你在同一個工作階段中轉向一個新的、無關的任務,你現在每次呼叫都在為包含這些不相關的先前上下文付出代價。
開始一個全新的工作階段是免費的。Codex 會以清爽的狀態初始化,且僅讀取與你目前工作目錄相關的檔案。經驗法則是:
- 任務順利完成且下一個任務獨立?開始新工作階段。
- 從一個模組切換到另一個且無共享程式碼?開始新工作階段。
- 繼續在同一個檔案上以相同目標進行迭代?繼續執行。
- 從實作階段轉向文件撰寫?開始新工作階段。
這雖然不如檔案範圍界定或模型選擇那樣戲劇化,但在整個工作週累積下來,尤其是在密集的衝刺(sprint)期間,能帶來顯著的節省。
Codex 使用上限解決方案:每日重置點數的實踐方式
了解計費模式能幫助你現實地規劃使用量。
標準 API 點數池給你每個月 X 個 Token,讓你隨意使用。結構性問題在於:高強度的編碼日會迅速耗盡點數池,導致該月剩下的時間可用額度比預期的少。如果你在兩天的密集衝刺中燒掉了 40% 的月度預算,未來三週你都得在該赤字下運作。
每日重置模型則不同。你每天獲得固定數量的點數,無論前一天使用了多少,它們都會在午夜重新整理。輕鬆的週二不會懲罰忙碌的週四。每一天都從相同的每日預算開始。
各方案等級的每日點數分配
所有等級皆在午夜每日重置 · 按量付費包(Pay-as-you-go packs)會堆疊在上方作為溢出使用
| 方案 | 價格 | 每日點數 |
|---|---|---|
| Starter | 10 美元 / 月 | 800K / 天 |
| Lite | 20 美元 / 月 | 2.2M / 天 |
| Plus | 50 美元 / 月 | 4.8M / 天 |
| Max | 100 美元 / 月 | 9.8M / 天 |
來源:Atlas Cloud Coding Plan,2026 年 6 月 · 未使用的點數不會結轉,但你也永遠不會因為前幾天的高強度工作而以耗盡的預算開始新的一天。
當你在特別激烈的任務中耗盡每日點數時,按量付費的充值包會自動填補空缺。這些充值包有效期為 90 天,你可以同時堆疊多個包,且僅在耗盡每日訂閱點數後才會使用它們。訂閱涵蓋基礎使用量,充值包涵蓋溢出部分。
如果你中途改變主意,升級方案費用會按比例計算。公式很簡單:(新價格 - 目前價格) × (剩餘天數 / 30)。例如,在剩餘 14 天時從 Starter 升級到 Lite,費用為 (20 - 10) × (14 / 30) = 4.67 美元。升級後,更高的每日點數限制立即生效。
設定 Codex 使用上限解決方案:完整配置
將 Codex CLI 指向自訂提供商的設定包含兩個檔案。在 macOS 或 Linux 上:
步驟 1: 建立或編輯 ~/.codex/config.toml
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-flash" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
步驟 2: 建立或編輯 ~/.codex/auth.json
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
requires_openai_auth = true 標記會告知 Codex 從 auth.json 的 OPENAI_API_KEY 欄位讀取 API 金鑰。你的 API 金鑰來自於購買 Coding Plan 後的 Atlas Cloud 計畫管理儀表板。
若要為特定工作階段切換模型,請更改 config.toml 中的 model 行。如果你想在複雜任務中使用更強大的模型,請切換至 deepseek-ai/deepseek-v4-pro 或 moonshotai/kimi-k2.6,任務結束後再切回輕量模型。這只需編輯一行。
設定完成後,像平常一樣啟動 Codex:
plaintext1codex
選擇略過更新檢查的選項,即可開始使用 Atlas Cloud 的模型執行 Codex。介面與指令與預設的 Codex 體驗完全相同。
關於 Codex 使用上限解決方案的常見問題
為什麼 Codex 每個任務消耗的 Token 比我預期的多?
Codex 執行的是代理循環,而非單次 API 呼叫。每次迭代都包含累積的對話紀錄以及執行程式碼後的新觀察結果。在一項 4 次迭代的任務中,第四次迭代時的上下文視窗大小可能是第一次的兩倍。所有迭代的總 Token 消耗量通常是單次呼叫的三到五倍。
對於剛起步的人來說,最好的 Codex 使用上限解決方案是什麼?
從檔案範圍界定開始:添加一個 .codexignore 檔案,排除 dist/、build/、*.d.ts 檔案、測試裝置及其他非必要的內容。這是免費的,通常在中型專案中能將上下文大小減少 30% 到 60%。完成後,下一個最有影響力的改變是切換至像 DeepSeek V4-Flash 這樣的低乘數模型執行常規任務,與相同工作階段的重型模型相比,可將每任務點數消耗減少高達 12 倍。
我可以在 Windows 上執行 Atlas Cloud 的 Codex 嗎?
可以。在 Windows 上,將設定檔放置在 %USERPROFILE%.codex\config.toml 和 %USERPROFILE%.codex\auth.json。檔案格式與欄位名稱與 macOS/Linux 版本相同。Base URL、API 金鑰和模型 ID 在所有平台上運作方式一致。
當我的每日點數用完時會發生什麼事?
如果你有啟用的按量付費點數包,系統會在耗盡每日訂閱點數後自動扣除這些點數包。如果沒有點數包,進一步的請求將會被拒絕,直到午夜每日點數重新整理為止。你可以隨時從計畫儀表板購買充值包;它們會立即啟用且有效期為 90 天。
指向自訂提供商後,我需要改變 Codex 工作流嗎?
不需要。無論底層提供商是誰,Codex CLI 的指令、標記和行為皆相同。唯一可見的差異是回應你任務的模型。如果你配置的模型不是 Codex 原生訓練的模型,回應風格可能會稍有不同,但工具的操作方式保持不變。大多數開發者在初始設定更改後,不會感受到任何工作流中斷。
總結
本文的核心洞察在於:Codex CLI 的成本並非神秘難解。它們來自一個可預測的來源:隨著迭代增長的上下文,乘以你的模型收取的每 Token 費率。一旦你看清這一點,干預手段就變成了機械性的步驟:
- 透過檔案範圍界定減少 Codex 的讀取範圍(免費,影響大)
- 根據任務複雜度匹配模型(每任務成本可變動高達 12 倍)
- 在任務獨立時開始全新的工作階段(防止上下文膨脹)
- 使用每日重置點數方案以避免月中耗盡問題
任何一項措施都有幫助。這四項結合起來,能讓 Codex 的每日高強度使用保持永續,而不會觸及上限或看到 API 帳單不可預測地飆升。
如果你想嘗試自訂提供商路線,Atlas Cloud Coding Plan 除了支援 Codex,也支援 Claude Code、OpenCode、Cursor 及直接 API 呼叫。每月 10 美元、每日 800K 點數的 Starter 等級是一個合理的起點;如果需要更多額度,你可以按比例在月中升級。
為不同類型的 Codex 任務在 DeepSeek V4-Flash 和 V4-Pro 之間做選擇 → 代理編碼工作流的模型選擇指南






