
如果您正在評估用於程式編碼、邏輯推理或代理(agentic)管道的開源模型,Kimi K2.6 和 GLM 5.1 無疑都會出現在您的候選名單上。兩者均來自中國頂尖的 AI 實驗室,皆支援 OpenAI 相容的 API,且在開發者真正關心的複雜任務上表現出色。
問題在於它們並非完全可互換。它們擁有不同的上下文視窗(context windows)、成本結構以及各自的優勢,這些差異在特定的使用場景中會顯現出來。若為工作負載選擇了錯誤的模型,您不是錯失了效能優化的機會,就是為不需要的容量支付了過高的成本。
本文詳細拆解了這兩款模型之間的真實差異:這些規格在實踐中意味著什麼、各模型的適用場景與侷限,以及當您進行大規模運作時的成本效益分析。

Kimi K2.6 與 GLM 5.1:快速總結
Kimi K2.6 是月之暗面(Moonshot AI)K2 系列中的最新款模型,代表了他們當前的旗艦產品線。Moonshot 是 Kimi 助手的開發商,K2.6 是他們在長上下文推理與具競爭力定價策略上的核心佈局。其 262K 的上下文視窗是該模型的亮點之一。
GLM 5.1 來自智譜 AI(Zhipu AI),這是一家中國資歷深厚的 AI 研究機構。GLM(通用語言模型)系列已歷經多次迭代,而 5.1 是智譜當前最頂尖的產品。它在開源社群中以指令遵循的精確度與結構化輸出品質享有盛譽。
兩款模型均提供 OpenAI 相容的 API,這意味著將它們連接到 Claude Code、Codex 或 OpenClaw 等工具非常簡單。兩者的選擇最終取決於三個關鍵因素:每次請求所需的上下文長度、預期使用量下的 Token 成本,以及您的任務是否更偏向其中一款模型的優勢領域。
模型背景介紹
Kimi K2.6 與 GLM 5.1 上下文視窗對比
上下文視窗是兩者最清晰且客觀的差異點之一。Kimi K2.6 支援 262K Token 的上下文視窗,而 GLM 5.1 支援 200K。最大輸入容量上有 31% 的差距。
對於典型的程式編碼任務,兩者在日常使用中通常不會達到這些限制。一般的代碼審查、除錯或文檔生成請求皆可在兩個視窗內輕鬆容納。這種差距在特定場景下才顯得重要:
- 大型程式碼庫分析:在單次請求中傳入數萬行代碼進行重構或架構審查。
- 長時代理會話:對話經過多次轉折與工具調用後積累了大量上下文。
- 文檔密集型管道:需要將大篇幅文本傳入單次調用中的研究、總結或分析任務。
如果您的工作負載經常接近其他模型的上下文極限,Kimi K2.6 的 262K 視窗能為您提供更多緩衝,減少實作分塊(chunking)或上下文摘要邏輯的需求。如果您的典型請求小於 50K Token,那麼兩者都提供了充足的容量,視窗大小的差異就不再是關鍵因素。

程式編碼與推理優勢
兩款模型在編碼任務上表現都很出色,但它們的設計側重點導致了實踐中的行為差異。
Kimi K2.6 專為長上下文理解而構建。這使它非常適合多檔案重構、理解程式碼庫中某部分的變更如何影響其他部分,以及在模型需要跨多步驟維繫大量狀態的擴展推理鏈任務。Moonshot AI 正是圍繞這些場景定位 K2.6 的。
GLM 5.1 則秉持了智譜 AI 對精確指令遵循與結構化輸出的專注。針對詳細規格產生代碼、從自然語言提取結構化格式,或管理複雜的工具調用架構等任務,皆能發揮其優勢。其定價中稍高的輸出費率(7.99 對比 7.26)也暗示了該模型傾向於提供更詳盡、深入的補全結果。
對於大多數比較這兩款模型的開發者來說,在典型編碼任務上的效能差異並不如品牌印象中那麼巨大,更直接的差異在於具體的規格與成本數據。
Kimi K2.6 與 GLM 5.1:Token 成本與積分費率
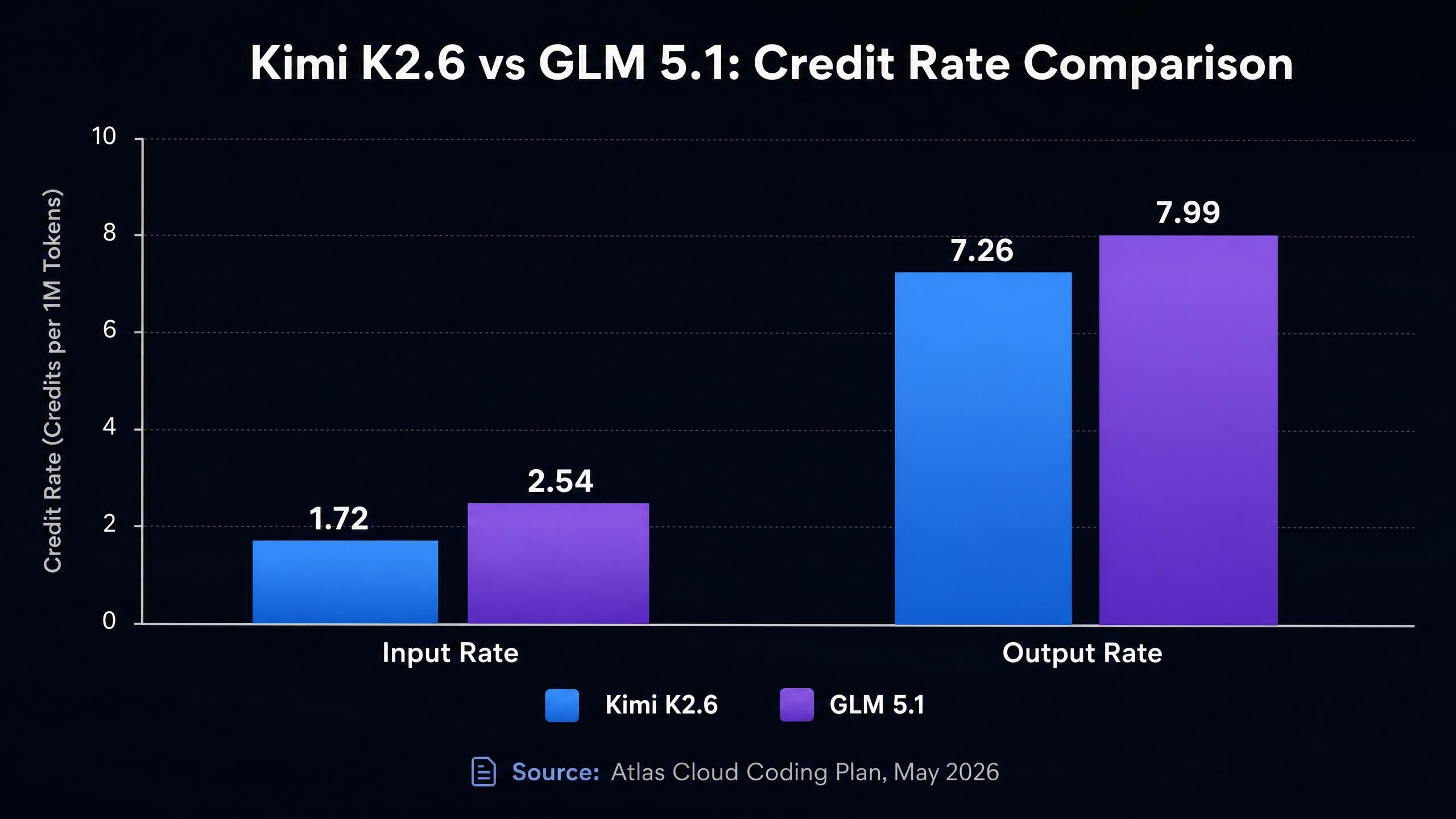
這是比較中最具體的部分。兩款模型均可透過 Atlas Cloud Coding Plan 使用,其積分費率如下(Atlas Cloud Coding Plan,2026 年 5 月):
| 模型 | 上下文 | 輸入費率 | 輸出費率 | 快取寫入 | vs. 官方 |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 便宜 45% |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 便宜 45% |
有幾個重點值得注意:
GLM 5.1 的輸入費率(2.54)比 Kimi K2.6(1.72)高出約 48%。在需要傳遞檔案內容、大量代碼歷史或長對話累積的編碼情境中,輸入 Token 往往佔成本的大頭。若一個管道每天運行 1,000 次請求,且每次請求輸入 10K Token,使用 GLM 5.1 的成本將比 Kimi K2.6 高出約 48%。
輸出費率兩者較接近,但 Kimi K2.6 仍具優勢(7.26 對比 7.99,約有 10% 的差距)。快取寫入費率同樣是 Kimi K2.6 較低(0.290 對比 0.472),這對於使用 Prompt 快取重複系統提示詞或靜態上下文的工作流來說,長期下來累積差異顯著。
綜合計算:對於一個 5,000 輸入 Token 與 1,000 輸出 Token 的請求,積分成本計算如下:
- Kimi K2.6:(5,000 × 1.72) + (1,000 × 7.26) = 8,600 + 7,260 = 15,860 積分
- GLM 5.1:(5,000 × 2.54) + (1,000 × 7.99) = 12,700 + 7,990 = 20,690 積分
在這種輸入/輸出比例下,Kimi K2.6 每次請求的成本便宜約 23%。在大規模應用時,這會累積成可觀的預算差異。
兩款模型透過該閘道器的定價皆比官方 API 價格低 45%,在該模型層級中保持一致。
Kimi K2.6 與 GLM 5.1 在代理編碼工作流中的表現
代理工具會放大模型間的每項成本與能力差異。
在多步驟編碼代理中,每一次工具調用都是獨立的 API 請求。每個請求都攜帶累積的對話上下文,生成輸出作為下一步的輸入,並增加您的總運算帳單。一個在單次會話中執行 40 次 API 調用的工作流,成本不僅是單次請求價格的 40 倍;它還會迅速累積上下文,導致隨會話推進,輸入 Token 數量不斷攀升。
Kimi K2.6 在代理任務中的優勢:長會話中累積的上下文日益龐大時,或是涉及讀取與修改大型代碼檔案、需要透過多次調用來控制成本的管道。更大的上下文視窗意味著更少的會話重置,減少對代理工作記憶的干擾。
GLM 5.1 在代理任務中的優勢:當每個步驟都需要精確、結構化良好的輸出,且單次調用的指令準確度優於跨會話的上下文深度時。如果您的代理需要根據嚴格的型別架構生成代碼、管理複雜的函數簽章,或在每次轉折中產生一致的格式化輸出,GLM 5.1 的指令遵循能力會更直接有效。
兩款模型透過標準的 OpenAI 相容設定,皆能與 Claude Code、Codex、OpenClaw 和 Cursor 無縫協作。整合方式相同,僅需更改模型 ID 即可。
如何測試並選擇最適合您的模型
Kimi K2.6 與 GLM 5.1:如何精準決策
決定這兩款模型孰優孰劣,最可靠的方式不是閱讀比較文章(包括這一篇),而是將它們實際應用在您的任務中並親自比較輸出品質。好消息是,當兩者都透過同一個 API 金鑰與基礎 URL 使用時,這變得非常容易。
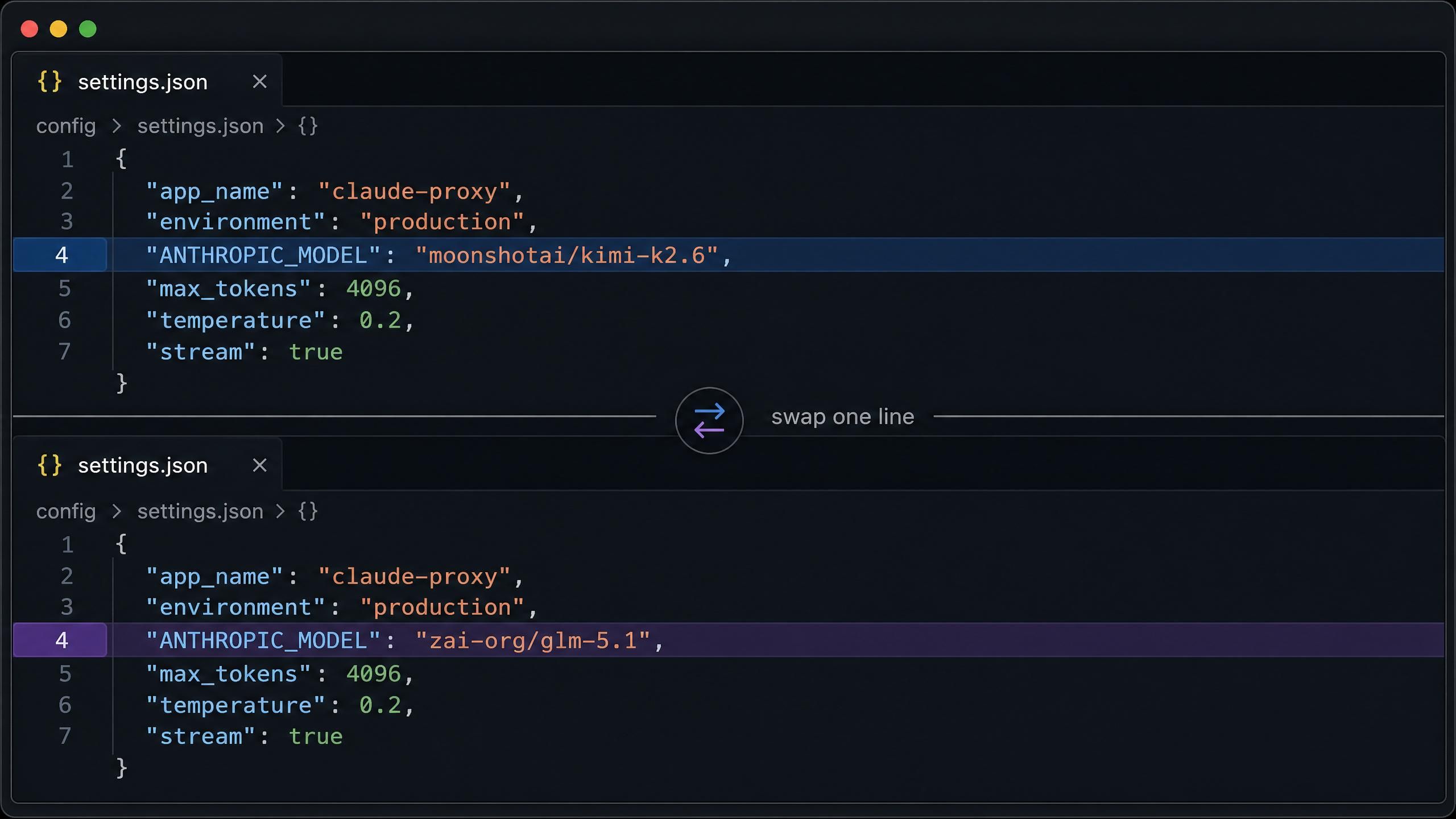
Atlas Cloud Coding Plan 將 Kimi K2.6 和 GLM 5.1 放置在同一個端點下。切換兩者僅需修改一行配置,這意味著您可以在不重新建構整合的情況下,連續運行您的真實工作負載以進行對比。
對於 macOS 或 Linux 上的 Claude Code,完整配置位於 ~/.claude/settings.json。請先設定為 Kimi K2.6:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
若要切換至 GLM 5.1,只需將上述三個模型欄位中的 moonshotai/kimi-k2.6 改為 zai-org/glm-5.1 即可,其餘配置不變。請注意,Claude Code 的基礎 URL 為 https://api.atlascloud.ai,結尾無需 /v1。
對於 Codex,配置會拆分到兩個檔案中。~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
對於 OpenClaw,請執行 openclaw onboard,選擇 QuickStart,然後選擇 Custom Provider。輸入 https://api.atlascloud.ai/v1 作為基礎 URL,貼上您的 Atlas 金鑰,並選擇您想要測試的模型 ID。
Atlas Cloud 計畫提供兩種形式:每日自動補充積分的月費訂閱(適合持續的日常使用),以及 90 天有效期的即用即付方案(適合變動或實驗性工作負載)。由於您可能需要同時測試兩款模型,即用即付方案能提供更大的靈活性,無需綁定月度用量。
Kimi K2.6 與 GLM 5.1:常見問題解答
哪款模型在大規模運作下成本更低?
Kimi K2.6 在輸入與輸出 Token 的單價上皆較便宜。輸入成本的差距最大(GLM 5.1 的輸入費率高出約 48%),這在涉及大量上下文的編碼工作流中最為關鍵。在高請求量下,這些差異會轉化為顯著的預算優勢。
哪款模型在中文任務處理上更好?
兩者皆具備強大的中文語言能力,這與其開發背景相符。智譜 AI 的 GLM 5.1 在中文任務處理上有著極為成熟的紀錄,這源於 GLM 系列多代產品的累積。Kimi K2.6 同樣因 Moonshot AI 對中國使用者的產品定位,在中文處理上表現優秀。對於以中文為主的任務,兩者皆表現穩健,其中 GLM 5.1 基於長期積累略有優勢。
我可以在同一個管道中混合使用這兩款模型嗎?
可以。透過統一的閘道器,您只需在每次請求時更改模型參數,即可將同一管道的不同步驟分配給不同模型。例如,您可以使用 Kimi K2.6 處理上下文密集的分析步驟(低輸入成本、大視窗),並使用 GLM 5.1 進行結構化輸出步驟(更強的指令遵循),且只需使用同一個 API 金鑰。
262K 與 200K 的上下文差異值得關注嗎?
對於大多數日常編碼任務,不需要。這兩個視窗都足以滿足典型請求。差異在於:如果您的會話經常累積 150-200K Token、需要傳入大型代碼檔案進行分析,或者在不重置的情況下運行長時間的代理會話,那麼此差異才具參考價值。如果您平時的請求很少超過 50K Token,這不會是決定性因素。
這些模型在配合 Claude Code 使用時需要特殊配置嗎?
不需要除了上述內容之外的特殊配置。Claude Code 會從 ~/.claude/settings.json 讀取模型設定,只要您指向的是提供 OpenAI 相容格式的閘道器,它就能正常連接。唯一要注意的是 Claude Code 的基礎 URL 格式:它使用 https://api.atlascloud.ai 且不包含 /v1,這點與大多數其他工具不同。
最終結論:Kimi K2.6 與 GLM 5.1
這兩款模型的選擇與其說是選出「勝者」,不如說是選擇「最合適的工作負載」。
Kimi K2.6 是更具成本效益的預設選擇。它的 Token 單價更低、單次請求能容納的上下文更多,且非常適合編碼代理常見的大輸入量、長上下文任務。如果您是在大規模環境下優化成本,或者經常處理大型代碼庫,從數據上來看它是更強的選擇。
GLM 5.1 則憑藉精確的指令遵循與一致的結構化輸出,證明了其較高定價的價值。如果您的管道不那麼依賴上下文深度,但要求每個單獨生成步驟的高準確度,那麼針對您的特定任務類型進行測試是值得的。
實踐建議:從 Kimi K2.6 開始以利用其成本優勢與更大的上下文視窗;運行您的真實任務,若對於結構化輸出品質有疑慮,再針對同樣的任務測試 GLM 5.1。透過 Atlas Cloud Coding Plan 以官方 45% 折扣率將兩款模型置於同一 API 金鑰下,測試成本極低,足以讓真實的效能數據引導您的決策。
模型規格與積分費率截至 2026 年 5 月 Atlas Cloud Coding Plan 文件為止。模型能力反映來自 Moonshot AI 與智譜 AI 的公開資訊。費率如有變動,請直接向各供應商確認最新數據。






