
現今的 AI 虛擬人(AI avatars)已經能夠進行實時對話,甚至讓你隨時打斷它們的發言,而且你可以透過開源專案自行架設,將所有數據留在本地。本文將拆解如何利用 OpenTalking 構建一個生產級的實時數位人類,並分析它在費用上如何比 HeyGen 這類按分鐘計費的服務更具優勢。
讓我印象最深刻的一刻是:當螢幕上的虛擬人正在說話時,我中途插話,它立即停止傾聽,接著針對我的內容做出回應。這不是預先渲染好的播放片段,而是真實的雙向互動。字幕同步滾動,延遲感低到讓你感覺不到是在與 AI 對話。
最棒的是,建構它的第一步完全免費,甚至不需要顯示卡(GPU)。
為什麼要先強調這一點?因為當大多數人聽到「數位人類」時,腦海中浮現的還是兩年前那些僵硬的 PPT 木偶:表情凍結、單向播放、對你的話充耳不聞。所以真正的問題不是「數位人類能賺錢嗎」,而是:
在 2026 年,AI 虛擬人究竟進步到什麼程度了?
它們已經從「會動的影片」進化成了「會回應的實體」。在 GPT-4o 的實時演示之後,整個行業的標準都提升到了:實時、可中斷、可反向提問。今年,開源界推出了不少佳作,例如 SoulX-LiveAct、阿里巴巴的 Mnn3dAvatar、duix.ai 和 LiveTalking。而我今天要拆解的是一個將整條管線銜接得異常乾淨的專案:OpenTalking。
廢話不多說,我們直接進入三個重點:它的功能、它的價值,以及非開發者該如何搭建。
1. 它的功能:真正會回應的虛擬人
OpenTalking 是一個開源的實時數位人類對話編排框架。簡單來說,它串聯了整個迴圈——使用者發言 → 語音轉文字 (STT) → LLM 思考回應 → 文字轉語音 (TTS) → 虛擬人說話並透過 WebRTC 推送到瀏覽器——這一切都在一條實時管線中完成。
它能實現的功能:
- 實時對話——它現場回答你,而非播放預錄影片
- 可中斷性——你可以在它說話時插嘴,它會停下來聽(這是最有「人味」的部分)
- 字幕事件——說話時字幕會實時呈現
- 語音/形象複製——支援音訊/文字驅動生成,你可以打造自己的數位分身
將此應用於商業場景,價值非常具體:一個 24/7 不需休息的直播帶貨主播,或是一個在凌晨 3 點隨時在線、且能應對突發追問的客服專員。
2. 它的價值:數據揭曉
對於非開發者來說,最關心的問題是:這能節省開支還是能賺錢?以下是公開數據顯示的趨勢:
- 傳統的人類團隊品牌直播每個月營運成本約為 ¥15 萬–25 萬;而 AI 虛擬人直播估計僅需幾千到 ¥2 萬/月——成本下降了約 90%(參考艾瑞諮詢《2026 年數位人類電商直播白皮書》)。
- 數位人類客服能過濾 60% 以上的高頻問題,並降低 30–60% 的營運成本。
現在看看另一條路——像 HeyGen 這樣的 SaaS 服務。它確實是開箱即用的,效果也很好,但它是按分鐘計費的:API 費用標準生成約 $1/分鐘,Avatar IV 為 $4/分鐘,Avatar V 為 $3/分鐘;而 Creator 方案($29/月)僅包含 200 個積分——這僅夠製作約 10 分鐘的高階虛擬人影片。
感受一下這個差異:SaaS 意味著你使用的每一分鐘都要付費。而自建的開源方案是一次性建構,之後主要的成本只有電費和 GPU 折舊。對於需要長期、大量運作的業務(例如日均直播)來說,這兩者的成本曲線最終會呈現巨大的差距。
3. 非開發者如何從零 GPU 開始搭建
這是本文的核心。OpenTalking 最聰明的設計在於,它不強迫你第一天就購買 GPU。它提供了三個你可以循序漸進的部署層級:
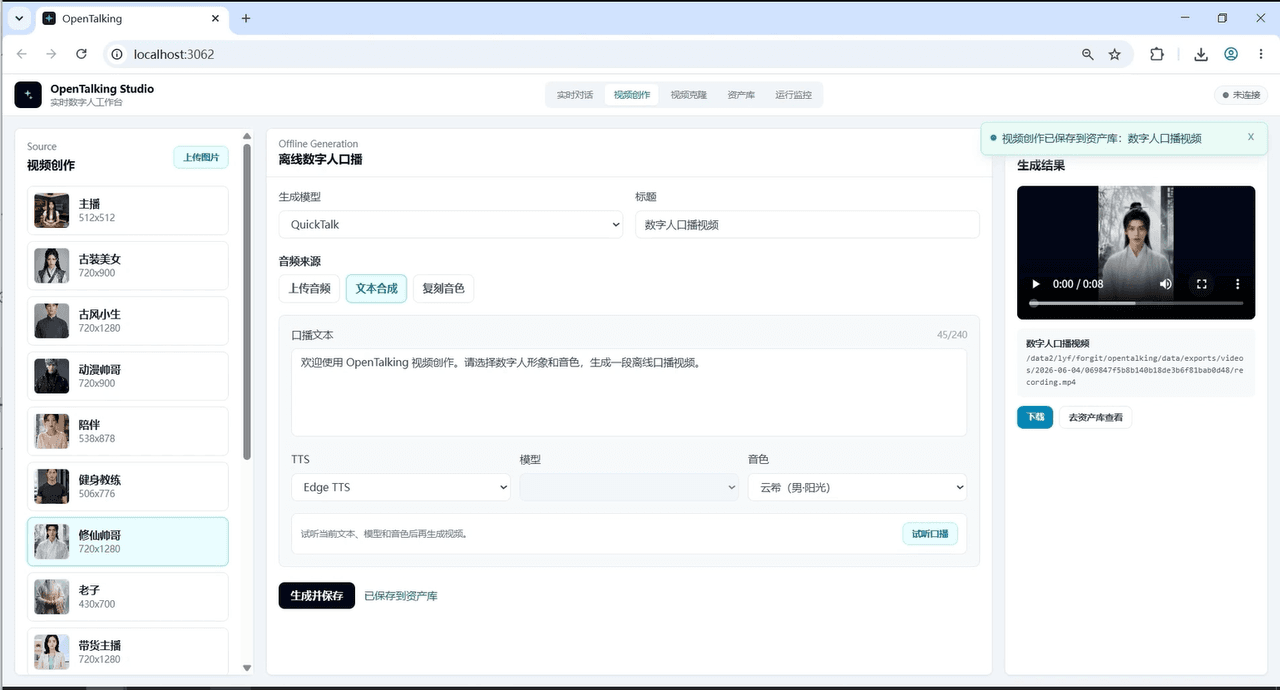
第 0 步 — Mock 模式(無需 GPU,先驗證邏輯)
在普通電腦上使用模擬後端來啟動整個產品迴圈——前端互動、會話狀態、完整對話流程。重點是:在花錢買 GPU 之前,先確認這就是你想要的產品形態。大多數人因為「還沒開始就要買顯卡」而卻步,這裡你可以先進行無成本的預演。
第 1 步 — 給它大腦和嘴巴(LLM)
為了讓虛擬人能對話,你需要連接一個 LLM。OpenTalking 支援 OpenAI 相容的 API,所以你不需要寫程式碼——只需輸入端點和金鑰即可。在此步驟中,我使用了 AtlasCloud 的金鑰:一個金鑰即可呼叫 DeepSeek、Seedance、Nano Banana 等模型,免去了註冊多個帳號的麻煩。語音/TTS 可以在網頁介面上直接選取。
第 2 步 — 加入消費級 GPU,切換真實渲染模型
當邏輯跑通且模型連接完成後,即可關閉模擬,掛載真實的渲染後端。在本地,一張如 RTX 3060(8GB VRAM)的消費級顯卡就足夠啟動;它支援 QuickTalk、Wav2Lip、MuseTalk、FlashTalk 等多種模型——你可以根據品質與速度的需求進行選擇。
第 3 步 — 隨業務規模擴充
當業務增長時,它支援擴充至多 GPU 甚至像華為昇騰 910B2 這樣的 NPU。這意味著該系統可以陪你從「在筆電上搞測試」一路成長到「企業級私有化部署」——中間不需要更換框架。
4. 為什麼不直接用 SaaS?開源/自建的勝算在哪
讓我們引用業界熟知的品牌進行誠實的比較(每個方案都有其優勢,不拉踩):
| 維度 | OpenTalking (開源、自建) | HeyGen / D-ID (SaaS) | ComfyUI 虛擬人工作流 |
|---|---|---|---|
| 架設難度 | 中等(需部署,但有 Mock 模式緩衝) | 最低(開箱即用,效果好) | 高(需連接節點、調試圖表) |
| 計費方式 | 一次性建構;後續主要是硬體/電費 | 持續按分鐘/積分計費 | 免費(自託管) |
| 數據安全 | 本地化,數據不離域 | 上傳至對方伺服器 | 本地化 |
| 實時 + 可中斷 | 原生支援 | 專注影片生成;實時對話受限 | 多為離線渲染 |
| 自訂化 | 高(後端可插拔、編排可編輯) | 低(標準化產品) | 高(彈性節點生態) |
平心而論:HeyGen 這類 SaaS 在「省心」方面確實勝出——如果你不想處理部署,只需結果且用量不大,那是正確的選擇。ComfyUI 的節點生態和控制力也很強。OpenTalking 的優勢不在於「在圖像品質上碾壓一切」,而在於兩點:數據永遠留在你的設備上(這是政府、金融、醫療或任何不希望將客戶對話交給第三方的企業的硬性要求),以及沒有按分鐘累計的計費壓力(對於長期、高頻業務,這能帶來巨大的長期收益)。
選擇哪一個,取決於你的業務是「偶爾生成剪輯」還是「每日高強度運作」,以及你是否介意數據交由他人處理。
結語
回到開頭的問題——AI 虛擬人進步到什麼程度了?答案是:它們已經可以與你實時對話、允許你打斷,並且能在你自己的機器上運行。門檻比你想像的低:先用無成本的 Mock 模式驗證想法,確認需求後再投入資金。對於初次涉足此領域的非開發者來說,這或許是最穩妥的入門方式。
❓ 常見問題 (FAQ)
Q:構建這個系統需要什麼 GPU?
A:要運行本地真實渲染模型,一張 RTX 3060(8GB VRAM)級別的消費級顯卡即可入門;之後可擴充至多 GPU 或昇騰 NPU。但請注意,第 0 步(Mock 模式)無需 GPU,普通電腦即可驗證邏輯。
Q:我沒有 GPU,可以試用嗎?
A:可以。Mock 模式完全不需 GPU 即可驗證整個對話流程;如果你需要真實模型但沒有顯卡,可以透過雲端/遠端推理進行計算,將渲染工作轉移到雲端。
Q:相比 HeyGen,它實際能節省多少成本?
A:結構上,它取消了按分鐘計費的機制。HeyGen 的 API 大約為 $1–4/分鐘,且其方案積分每月僅夠使用約 10 分鐘;自建則是一次性建構,後續只有硬體和電費。運行時間越長、使用量越大,自建的優勢就越明顯。對於偶爾製作片段的需求,SaaS 的確更省事。
Q:可以用於商業用途嗎?
A:在技術上,它覆蓋了商業應用所需的功能——實時對話、客服、直播分身——且具備私有化部署和數據本地化的特點。但在正式上線前,請確認你所選用的渲染模型、語音和形象授權的合規性。虛擬人涉及他人的臉部和聲音——請務必先取得授權。
Q:我是完全的初學者,該從哪裡開始?
A:① 在 Mock 模式下執行專案,體驗瀏覽器中的對話流程;② 連接一個 OpenAI 相容的 LLM 金鑰(為方便起見,可以在 AtlasCloud 上獲取一個——多模型通用,一個金鑰搞定);③ 選擇一個語音;④ 最後再增加 GPU 並切換到真實渲染模型。先驗證,後付費。






