
Grok Imagine Video Generation 是 xAI 的前沿多模態 AI 影片系統,它重新定義了創作者對單次 API 調用產出內容的期待。該模型基於 xAI Aurora 引擎構建,採用自回歸混合專家(MoE)網路,能同時處理文字、圖像、影片和音訊 Token。這種方法徹底取代了 Sora 和 Veo 等系統中常見的擴散 Transformer(diffusion-transformer)架構。
其核心優勢在於能在單次生成步驟中實現自然的音影同步,無需事後額外使用配音工具。
概覽:關鍵規格
| 功能 | 詳情 |
| 長度 | 1–15 秒 |
| 幀率 | 24 FPS |
| 解析度 | 480p / 720p |
| 音訊 | 原生口型同步、音效(SFX)、對話、環境音樂 |
| 排行榜 | Artificial Analysis Video Arena 第 1 名(Elo 1404 ±6) |
Grok imagine video generation 於 2026 年 5 月底發布,首次亮相即登頂 Artificial Analysis Video Arena 的「以圖生片」(Image-to-Video)排行榜,超越了 ByteDance 的 Seedance 2.0。對於任何追求快速、成品級影片且需內建音訊的現代數位工作流程而言,這已成為行業標竿。
理解 xAI Grok Imagine Video Generation 架構
要充分發揮 Grok 的功能,必須深入了解其運作機制。不同於將聲音與畫面分開縫合的傳統影片模型,Grok 將其視為單一實體。理解這一核心轉變,就能明白為何它的提示詞(Prompt)行為與渲染速度與市場上的替代方案截然不同。
什麼是 Grok Imagine 及其運作原理?
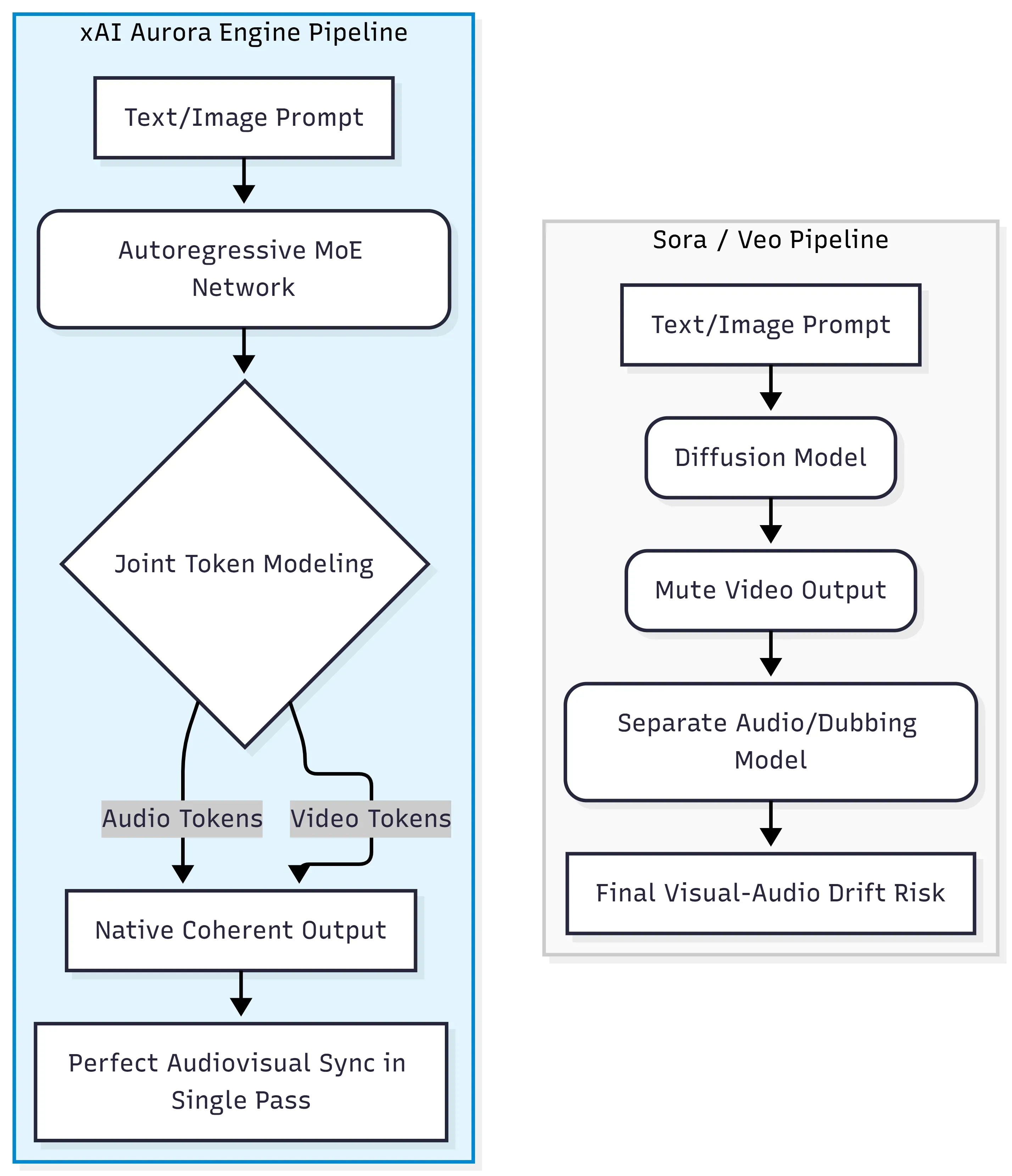
Grok Imagine Video Generation 的核心是 xAI Aurora 引擎,這是一種自回歸混合專家網路(MoE network),它在文字、圖像、影片和音訊組成的統一數據流中預測下一個 Token。這在架構上與 OpenAI Sora 和 Google Veo 使用的擴散 Transformer 範式完全不同,後者通常需要分階段生成或對齊影片與音訊。
擺脫擴散 Transformer 的束縛
傳統擴散模型通過將隨機雜訊逐步去噪,轉化為連續幀。它們擅長視覺品質,但將音訊視為後續補充,需要外部工具或後期製作流程來添加聲音。Aurora 則選擇了完全不同的路徑。
| 方法 | 架構 | 音訊處理方式 |
| Sora / Veo | 擴散 Transformer | 後期製作 / 獨立模型 |
| Grok Imagine Video | 自回歸 MoE | 原生單次生成 |
交錯式多模態 Token 處理
Aurora 並非按順序處理模態,而是處理交錯式多模態數據——這意味著視聽 Token(對話、音效、環境音樂)與影片幀是在同一次前向傳播(Forward Pass)中同時生成的。這種聯合 Token 建模技術,正是口型同步和與事件精準對齊的音效能由模型直接產出的關鍵,而非依賴獨立的對齊系統。
這段製作範例展示了 Aurora 的單次執行能力,引擎加速時的引擎轟鳴頻率與視覺上的加速度以及輪胎摩擦物理效果完美同步。
大規模訓練:Colossus
他們在 xAI 的 Colossus 超級電腦上訓練了此模型。該設施擁有約 55 萬個 NVIDIA GPU,耗電量約 2 吉瓦(GW)。這是目前全球規模最大的單點 AI 訓練叢集。這種大規模架構正是 Aurora 能在不降低品質的前提下混合四種媒體類型的秘密所在。
關鍵功能:以圖生片、格式設定與品質模式
儘管 Grok 支援文字生成影片,但其真正的企業級效能體現在「以圖生片」(I2V)工作流程中。透過輸入靜態參考圖,您可以立即鎖定角色特徵,將沉重的描述工作轉移為精確的機械控制。在選擇樣式模式之前,您需要設定核心流水線的限制。
Grok Imagine 的影片限制、長寬比與解析度為何?
將圖片轉為影片是 Grok Imagine 最實用的功能之一。只需上傳靜態照片並輸入簡單的提示詞描述動作,模型即可同時對圖像進行動畫處理並添加匹配的音訊。您可以通過長度、幀率、解析度和形狀四個設定完全控制最終格式。
長度和幀率
精細的時長控制允許您請求 1 到 15 秒之間的任何整數秒數。這在維持更長窗口內時間一致性的同時,將先前的 10 秒上限延長了 50%。所有輸出均以固定的 24 FPS 為基準渲染。
解析度選項
| 解析度 | 品質 | 處理速度 |
| 480p | 標準定義 | 較快(預設) |
| 720p | 高畫質(720p) | 較慢 |
對於最終成品或社交媒體發布,720p 是實用之選。使用 480p 進行快速迭代和提示詞測試。
長寬比變化
支援七種長寬比變化:
| 比例 | 最佳應用場景 |
| 16:9 | 寬螢幕 / YouTube(預設) |
| 9:16 | TikTok / Instagram Reels / Stories |
| 1:1 | 社交媒體縮圖 |
| 4:3 / 3:4 | 簡報 / 肖像 |
| 3:2 / 2:3 | 攝影格式 |
對於以圖生片,除非另行指定,否則輸出將預設採用輸入圖像的原生長寬比。
電影級動態與零樣本身份識別的提示詞工程指南
由於 xAI Aurora 引擎依賴聯合 Token 建模,您的提示詞策略必須有所調整。您不再需要花費 Token 來描述角色的外貌——輸入圖像通過零樣本身份保存(zero-shot identity preservation)自動處理。相反,您的提示詞應嚴格聚焦於定向運動、攝影機行為,以及至關重要的是,您希望引擎同步生成的聲學環境。
如何編寫 Grok Imagine Video 的最佳提示詞?
最重要的原則是:由於 Grok Imagine 支援零樣本身份保存,模型會直接從輸入圖像中獲取主體外觀。您無需重複描述髮色、服裝或面部特徵。應將每個字都花在動作動態、環境和攝影機方向上。
最佳提示詞語法
組合併使用這些優化的 Token 模組來構建高度受控的電影場景:
| 動作與運動 | 攝影機動態 | 聲學與環境 |
| ...自信地向前邁步,外套飄揚 | 推拉鏡頭緩慢後退 | ...濕潤路面上的霓虹倒影。音效:大雨濺在柏油路上的聲音 |
| ...在人群中疾跑,回頭看 | 低角度追蹤鏡頭,快速節奏 | ...在閃爍的螢光燈下。音效:低沉的人群嘈雜聲與喘息聲 |
| ...緩慢轉身,睜開雙眼 | 微距平移鏡頭,從左向右 | ...淺景深,漂浮的塵埃。音效:低沉的電影感重低音下降 |
場景 A:Cyberpunk 追逐序列(高動態、重度音訊同步)
提示詞:
動作與主體: 一名男子在霓虹燈照亮的潮濕巷子中快速奔跑。
攝影機動態: 攝影機保持低角度並緊緊跟隨他。背景模糊掠過,明亮的光線在螢幕上閃過。
音效: 快速的電子音樂混合著踩踏水窪的聲音和遠處的警笛聲。節拍與閃爍的霓虹燈完美匹配。
測試目的: 檢查 Aurora 引擎在快速運動中處理形狀的能力,並評估音訊與視覺(如合成器節拍與閃爍霓虹燈)的同步精確度。
優點(Grok 的出色表現):
- 零樣本身份保留: 從靜態種子圖像的轉換非常完美。風衣的褶皺皮革紋理與角色凌亂的黑髮保持穩定,沒有出現身份變形。
- 物理連貫性: Grok 在處理高速衝刺時沒有出現肢體複製或衣服穿模,這是擴散模型對手常見的失敗點。
- 動態光影物理: 濕潤路面上的粉色和藍色霓虹反射會隨攝影機的前向追蹤角度精確移動。
缺點(瓶頸所在):
- 音訊 Token 偏差: 雖然原生的單次音訊同步效果驚人,但引擎過度優先考慮「synthwave 音樂」Token,導致局部「水窪濺水」的音效被嚴重掩蓋。
- 運動壓縮: 在 720p 下,快速的攝影機移動會導致輕微的邊緣模糊,以及遠處背景文字(如 "MIDNIGHT DINER")周圍出現數位偽影。
場景 B:電影對話與情感爆發
提示詞:
動作與主體: 她發表一段緊張的電影演說,全神貫注地低聲說出 "It ends tonight"(今晚就此結束)。
攝影機動態: 當一陣強風吹亂她的頭髮時,攝影機緩慢推向她的臉部。
音效: 她低沉的嗓音與唇部動作完美匹配,混合著一陣突然的強風吹入麥克風並拂動她衣物的聲音。
測試目的: 這作為 xAI Aurora 引擎多 Token 整合的終極壓力測試。它迫使模型執行完美的唇型同步與動態面部肌肉運動,同時計算頭髮/衣物的複雜物理交互,並在單次推論中匹配真實的環境音效。
優點(Grok 的出色表現):
- 完美原生唇型同步: 說出的 "It ends tonight" 與角色的嘴唇和下顎運動完美吻合。這是自然發生的,無需額外剪輯。
- 微表情保留: 她的面部雀斑、眨眼和銳利的眼神保持原位,證明引擎在特寫鏡頭中也能穩定識別。
- 風力物理模擬: 當她講話結束時,一陣陣風吹過她的黑髮,髮絲的移動顯得極其逼真,保持了自然的蓬鬆感。
缺點(瓶頸所在):
- 音訊偽影:生成的語音雖然節奏良好,但帶有輕微的壓縮合成感,缺失了提示詞中要求的原始呼吸質感。
- 時間微變形:在風吹動的序列中,耳朵和髮際線周圍出現了細微的紋理融合,引擎在將運動髮絲與靜態皮膚背景分離時稍顯吃力。
規避陷阱:反例矩陣
由於目前的公共端點不支援專用的否定提示詞(Negative Prompt)參數,流水線工程師必須從傳統的擴散式提示詞邏輯轉變:
- ❌ 錯誤方法(擴散思維):"A man running, highly detailed, 4k, no blur, no distortion, cinematic lighting."
- 分析: 這會用無效 Token 填滿上下文窗口,並引入像 "no blur" 這樣的否定短語。Aurora 這種自回歸 MoE 網路可能會將這些詞誤解為語義錨點,反而生成您試圖避免的失真。
- ✅ 正確方法(Aurora 原生思維):"Strides forward dynamically. Sharp focus throughout, pristine cinematic textures, volumetric god rays piercing through dust."
- 分析: 這用肯定、決定性的空間和物理描述取代了排除法,引導引擎的 Token 預測路徑朝向清晰渲染。
專業建議:
當提示詞引入衝突的空間指令(如同時進行放大和向右平移)時,時間連貫性會降低。保持攝影機移動的單一性和方向性。對於超過 8 秒的片段,請圍繞一個連續的運動弧線編寫提示詞,而非多個場景切換。
Grok Imagine Video Generation API 整合:Python 與 REST 快速入門
從創意概念轉向生產擴展,需要將這些參數推送到官方 xAI API 網關。根據您當前的基礎設施以及您偏好自動化的後台處理還是輕量級自訂循環,xAI 提供了兩種不同的實作途徑。
如何調用 Grok Imagine 影片 API?
調用 Grok Imagine API 有兩種支援方式:原生的 xai_sdk Client(自動處理輪詢)以及通過 https://api.x.ai/v1 的 OpenAI 兼容 base_url REST 方式。兩者都需要將 API 金鑰身份驗證設定為環境變數。
先決條件
在編寫程式碼之前,請完成以下步驟:
- 在 console.x.ai 生成 API 金鑰
- 在 shell 中匯出金鑰:export XAI_API_KEY="your-key-here"
- 安裝 SDK:pip install xai-sdk
方法 1:原生 xai_sdk(推薦)
xai_sdk Client 在內部封裝了完整的非同步輪詢循環,因此只需調用 video.generate 端點即可獲得完成的影片物件:
python1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# 確保為「以圖生片」工作流程傳入參考圖像 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="your image", # 必須是 URL 或 base64 10 prompt="your prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# 固定:與標準 xai_sdk 回應結構對齊 17print(f"Generation Successful. Video URL: {response.video.url}")
無需手動輪詢。SDK 會提交請求、等待完成並返回 URL。
方法 2:標準 REST API(自訂非同步循環)
對於不支援原生 SDK 的環境,請使用底層 HTTP 端點。由於影片生成是異步的,您必須手動實作輪詢序列來追蹤執行狀態:
python1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "your image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. 提交影片生成請求 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. 輪詢狀態端點直至完成 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # 固定:與官方 xAI JSON 結構回傳對齊 31 print(f"Success! Asset Available At: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"Generation failed with status: {data['status']}") 35 break 36 37 time.sleep(5) # 安全的速率限制間隔
輪詢狀態參考
API 在生成期間會回傳四種狀態值之一:
| 狀態 | 含義 |
| pending | 處理中 |
| done | 影片就緒,URL 可用 |
| expired | 請求超時 |
| failed | 生成錯誤 |
建議每 5 秒輪詢一次以保持在合理的頻率限制內。
生產環境替代方案:透過 Atlas Cloud API 網關精簡流程
對於需要進階併發、統一帳單或高可用性路由的企業級流水線,透過第三方託管網關(如 Atlas Cloud)進行整合是可行的生產方案。除了不必在地端管理複雜的非同步輪詢和狀態檢查,Atlas Cloud 的統一封裝還能自動處理伺服器端隊列和狀態持久化。
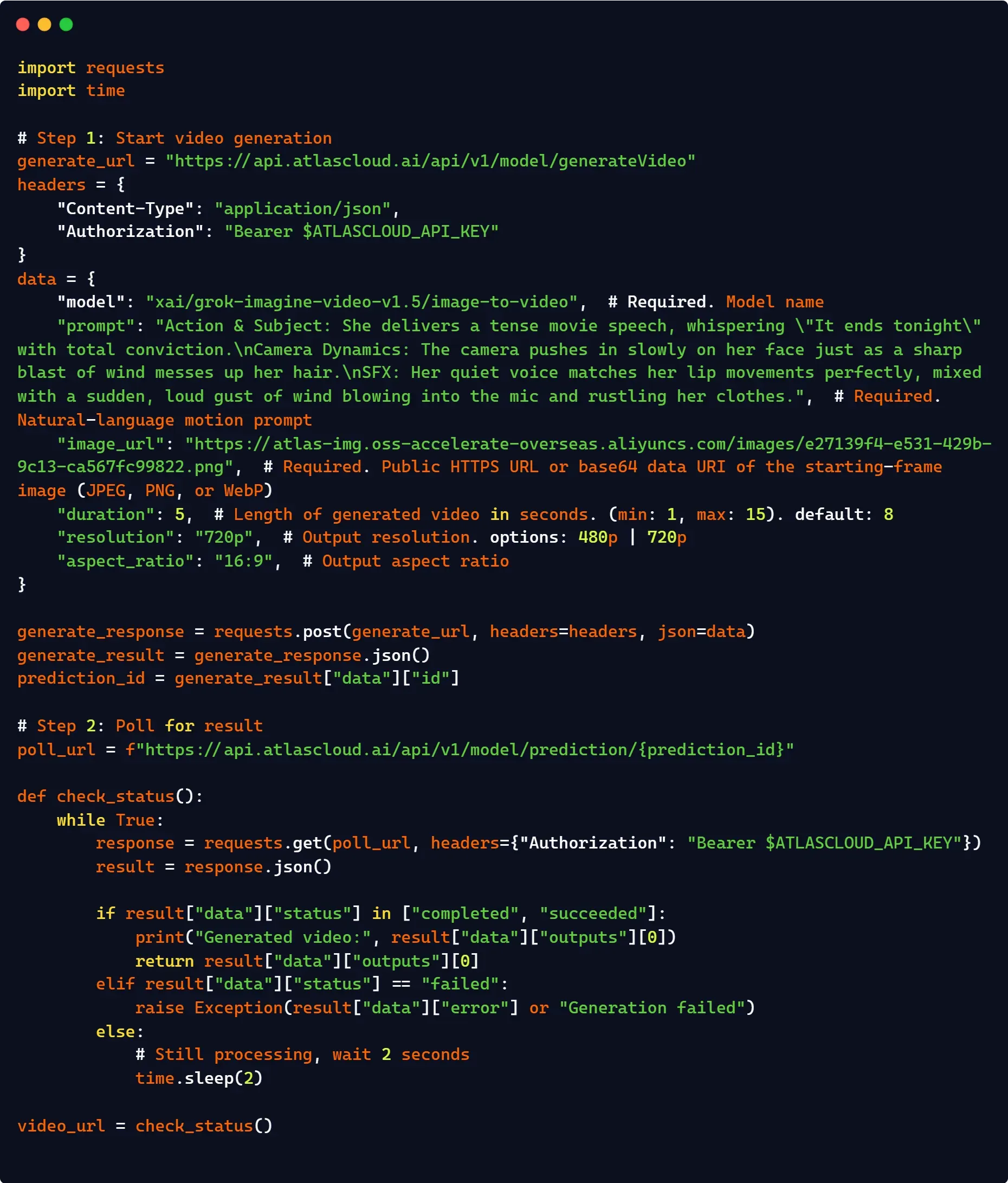
此外,它還提供無縫替換,透過統一的基礎 URL 路由請求,在最大限度減少程式碼變更的同時,解鎖通常超過標準 xAI 公共層級的企業級頻率限制。
基準效能:成本、延遲與競品對比
高保真的視聽輸出只有在符合嚴格的運算預算和延遲要求時,才適用於企業流水線。第三方壓力測試將 Grok 的生成速度和每秒成本與行業巨頭進行了直接對比。
Grok Imagine Video 是否比其他 AI 影片工具更快且更便宜?
在獨立基準測試中,答案基本上是肯定的。Grok Imagine Video 在 Artificial Analysis Video Arena 的「以圖生片」排行榜上以 1404 ±6 的 Elo 評分高居榜首,將 ByteDance 的 Seedance 2.0 擠下了冠軍寶座。
競品直接對比
| 模型 | 開發商 | 最大長度 | 最大解析度 | 原生音訊 |
| Grok Imagine V1.5 | xAI | 15s | 720p | 是 |
| Seedance 2.0 | ByteDance | 4–12s | 720p | 是 |
| Veo 3.1 | 8s | 1080p | 是 | |
| Sora 2 | OpenAI | 20s | 1080p | 是 |
| Runway Gen-4 | Runway | 10s | 1080p | 部分 |
推論速度與延遲
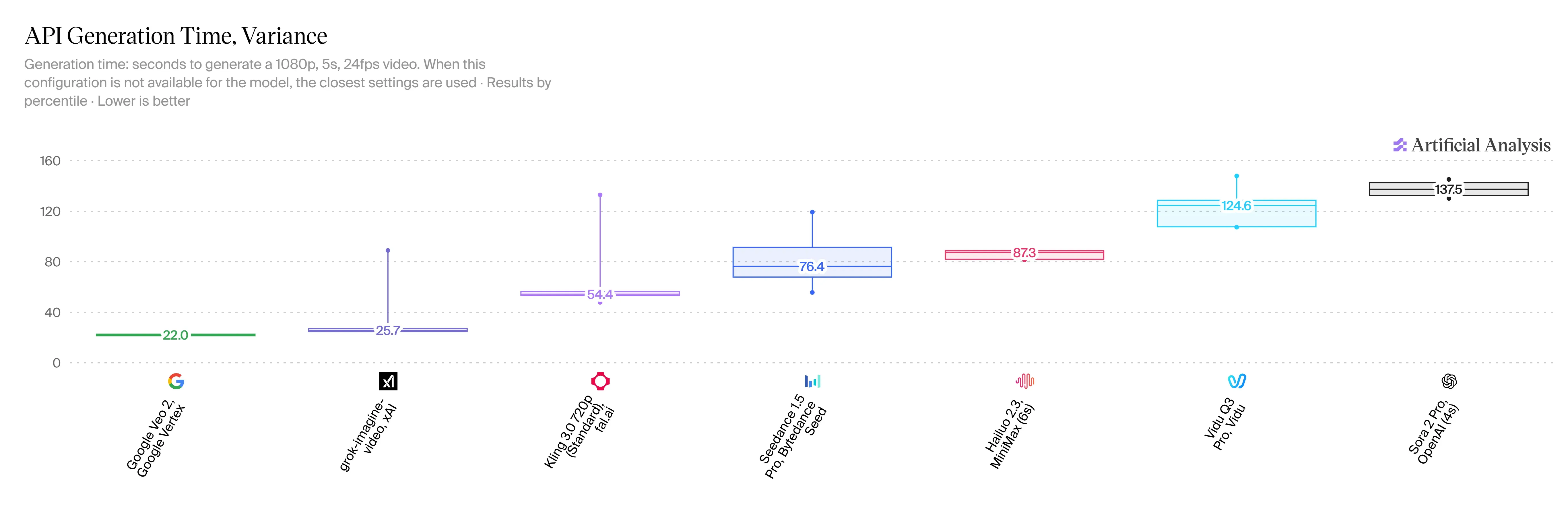
V1.5 的速度極快,這是使用者的巨大優勢。製作一個 5 秒、720p 的影片片段僅需 20 到 30 秒。與 HappyHorse 2.3 相比,這將等待時間縮短了 2 到 3 倍。儘管目前尚未有 Veo 3.1 的官方速度數據,但網路上普遍反饋生成類似片段需超過一分鐘。
定價結構
透過第三方 API 網關(如 Atlas Cloud)的 每秒定價結構 約為每秒影片生成 USD0.096。以此費率計算,一個 10 秒的片段成本約為 USD0.96,這使得獨立創作者和小團隊在進行最終生產前,可以低成本地嘗試多種提示詞變體。
企業安全、數據隱私與合規性
將專有媒體資產或客戶內容部署到任何雲端 AI 系統時,都會引發法律問題。對於商業製作公司而言,了解生成輸入的流向及隔離方式,與最終輸出品質同樣重要。
xAI 是否會使用我的 API 數據或生成的影片來訓練模型?
這是企業採用者最關心的問題之一。根據 xAI 的開發者條款,透過平台處理的 API 輸入和輸出雖需進行內容政策審核以確保安全,但均按照**設計隱私(Data Privacy by Design)**原則處理,即將推論數據與公共訓練流水線區隔開來。
合規框架概覽
提供 Grok Imagine 存取權的第三方 API 網關(如 Atlas Cloud)皆發布了其獨立的合規認證:
| 合規標準 | 狀態 |
| SOC 2 Type II 合規 | 已認證 |
| GDPR 數據駐留 | 符合 |
| HIPAA | 適用 |
專業用戶的關鍵隱私界線
專業人士在評估商業工作流程中的 Grok Imagine 時應注意以下事項:
- 生成的影片輸出會以臨時託管 URL 返回,預設情況下不會永久儲存。
- 內容政策審核會在交付前檢查輸出是否存在安全違規,但不會保留內容以供再利用。
- 模型訓練排除適用於 API 用戶:您的提示詞和生成的媒體不會被餵入公共模型訓練循環。
- GDPR 數據駐留合規性代表數據處理實踐符合歐洲對跨轄區操作團隊的處理標準。
對於需要正式數據處理協議或自訂保留政策的企業部署,建議直接透過 x.ai 聯繫 xAI 企業團隊。






