
Kling 2.6 是目前最具指標性的 Kling AI 更新,但在深入體驗之前,您必須先了解一個重要的限制。
這次發布是 Kling 首次推出真正具備 原生音訊同步 (native audio sync) 的模型。在此之前,生成的影片幾乎等同於默片,創作者必須在製作完影片後,手動添加旁白、音效和背景音。全新的 VIDEO 2.6 模型徹底改變了這一切:它能同時生成視覺畫面、逼真的配音、對應的音效以及背景音頻。這項功能將該工具提升到了全新的層次。
優點與特色
該模型在視聽同步方面表現卓越。語音節奏、背景雜訊與螢幕動作完全一致,消除了以往影片與獨立音軌之間的不協調感。電影級的音效聽起來非常逼真,您可以清晰地聽到如營火燃燒、雨打街道以及嘈雜環境中層次豐富的背景音。目前支援六種音訊類型:
| 音訊類型 | 應用場景 |
| 語音旁白 | 產品影片、Vlog |
| 多角色對話 | 訪談、短劇 |
| 歌唱 / 饒舌 | 音樂表演 |
| 環境音 | 自然、城市場景 |
| 物體/動作音效 | 碰撞聲、機械運轉聲 |
| 混合音效 | 全沉浸式製作 |
主要限制
涉及三名或以上說話者的多角色對話場景,可能會產生語音分配不一致的問題。為了獲得最穩定的視聽同步效果,建議創作者將場景限制在兩名角色對話,或考慮更換畫面構圖。
效能比較
2.6 版本較舊款無聲模型有顯著提升。如果創作者需要完美的控制力或極高畫質的成品,可以選擇 Kling 3.0。不過,大多數內容創作者對 Kling 2.6 的評價極高,因為它以實惠的價格提供了出色的品質。
Kling 原生音訊剖析:對話、音效與環境音深度解析
Kling 2.6 不僅僅是在影片上方疊加音訊,而是在單次生成中,將三種音訊層與視覺畫面同步生成。以下是各個層面的實際運作方式:
對話與語音
Kling AI 的對話生成能力超乎多數創作者的預期。該模型能輕鬆處理單人演講、角色間對話、旁白、歌唱與饒舌,並根據不同風格調整情感基調。此外,該工具具備雙語能力,自然支援英文與中文語音輸出。若輸入其他語言,模型會自動將其翻譯成英文進行語音生成,且不會影響影片的整體輸出。
以上 8 秒影片展示了我們透過 Atlas Cloud 編排平台直接以 Kling 2.6 輸出的成果。透過上傳一張說話者的高解析度基礎圖片以及一段預錄的 8 秒英文語音軌,引擎成功實現了原生唇形同步。
請注意臉部肌肉同步如何順暢地對應複雜的音素,而沒有出現常見的「恐怖谷」式僵硬嘴部扭曲。這為快速生成 AI 品牌代言人素材提供了絕佳的藍圖。
節省時間的快速規則:
- 注意大小寫。一般詞彙使用小寫,名稱與縮寫詞使用大寫。
- 標記說話者。為每個人加上如 [Character A] 或 [Character B] 的標籤,以防 AI 將聲音混淆。
- 描述情緒。將語氣註記直接寫在標籤旁,例如 [Reporter, calm and steady voice]。
音效 (SFX)
2.6 版本中的 AI 影片音效是情境觸發式,而非手動指定。模型會讀取場景描述並推斷合適的聲音,根據您的動作詞彙直接生成音效。它可以創造碎石地上的腳步聲、玻璃破碎聲、輪胎摩擦聲或機械運轉聲。為了獲得最佳效果,請清晰命名具體的聲音來源。例如,寫下 [Wooden door slams shut, loud bang] 比單純說「有聲音」效果好得多。
環境音
環境音合成處理的是空間感層面:咖啡館的嗡嗡聲、敲打玻璃的雨聲、曠野上的風聲、地鐵進站聲。這些背景音軌會在對話與音效之下播放,為您的影片增添真實深度。請務必在提示詞中明確說明情境,例如使用 `[small room acoustics]` 或 `[open hall reverb]`,這能為模型提供明確目標並優化音訊。
時長:5 秒與 10 秒輸出
此選擇直接影響音訊的穩定性。對於語音密集的內容,Kling 5 秒 vs 10 秒影片的決策至關重要。
| 內容類型 | 建議時長 | 理由 |
| 純環境音 / 音效 | 5 秒 | 輸出清晰、緊湊 |
| 獨白 / 旁白 | 皆可 | 取決於劇本長度 |
| 多角色對話 | 10 秒 | 語音切換更穩定 |
| 歌唱 / 饒舌 | 10 秒 | 防止歌詞被切斷 |
針對歌唱或對話場景,建議使用 10 秒參數以獲得更完整且穩定的結果。短片段適合純氛圍或動作-音效搭配,但任何涉及對話的內容都受益於較長的時長,以避免最後幾秒出現音訊漂移。
Kling 2.6 完美視聽同步提示詞公式
Kling 2.6 的多數同步問題並非源於模型,而是源於過於籠統、讓模型有太多解讀空間的提示詞。將您的提示詞視為導演指令:定義越精確,推論引擎猜測的成分就越少,而節奏失調通常就發生在猜測的過程中。
核心公式
此 Kling 提示詞模板 直接映射了模型的生成處理方式:
場景 → 主體 → 動作與鏡頭 → 音訊藍圖
官方提示詞結構為:Scene (場景描述) + Element (主體描述) + Movement (動作描述) + Audio (對話/歌唱/音效/音樂) + Other (風格/情緒/鏡頭)。
每個區塊都供給生成管道的不同部分。遺漏其中任何一項,都會迫使模型自行填補,這就是 視聽節奏 崩潰的開端。
區塊拆解
| 區塊 | 應包含內容 | 常見錯誤 |
|---|---|---|
| 場景 | 地點、光線、時間 | 過於模糊:例如「一個房間」 |
| 主體 | 外貌、角色、畫面位置 | 未命名或僅使用代名詞的角色 |
| 動作與鏡頭 | 動作序列、Kling 鏡頭控制語言 (慢速推近、追蹤鏡頭、特寫) | 完全沒有鏡頭指令 |
| 音訊藍圖 | 引號內的對話、情緒標籤、音效標籤、環境音層 | 對話隱沒在描述性的長文中 |
現成範例:完美渲染的解剖
由於區域 API 的限制以及 Kling 原生平台上的排隊瓶頸,利用 Atlas Cloud 上的 kling-v2.6-std-avatar 管道 是進行大量自動化生產最可靠的路徑。雖然此特定層級限制您使用靜態談話人模式而非多代理動態場景,但它在精確的音素映射方面表現優異。
為了驗證我們核心公式的權威性,我們透過 Atlas Cloud 平台將上述藍圖輸入 Kling 2.6 (kwaivgi-kling-v2.6-std-avatar 層級)。上述 2 秒短片代表了未經修改、單次生成的商業成品。
讓我們分析為何這段渲染能實現完美的自然感,而沒有掉入「恐怖谷」:
- 第 0 幀構圖鎖定: 透過使用女性主持人的初始圖片,且已將智慧手錶定位在臉頰旁,我們消除了肢體扭曲的風險。AI 無需猜測複雜的骨骼機制,僅需對微表情進行動畫處理。
- 音素唇形同步精確度: 注意主持人唇部動作與牙齒追蹤如何與「Zero lag. All day battery.」快速變化的音節完美吻合。
- 電影級光影與景深: 淺景深(奶油般的散景背景)過濾掉了背景雜訊,迫使 AI 管道將 100% 的運算力專注於渲染真實的皮膚毛孔與銳利的衣物紋理。
時長與音訊窗口
了解 Kling AI 最大片段時長 對音訊規劃至關重要。目前輸出上限為 10 秒。對於上述產品演示,選擇 10 秒是正確的,它給了旁白從容結尾的空間,不會中斷最後一個字。5 秒短片適用於純氛圍或無需講話的動作音效搭配。
在撰寫提示詞之前,請務必先根據片段長度規劃劇本長度,而非反之。
圖生影工作流:利用 Kling 運動控制保持角色一致性
對於專業創作者而言,文生影只是起點。Kling 圖生影 (Image-to-Video) 工作流 才是建構角色導向內容的核心,而搭配 Kling 2.6 運動控制,您能獲得純文字提示詞無法比擬的一致性。
I2V 管道如何錨定身份
在「圖生視聽模式」中上傳參考圖片時,它便與模型簽署了一份「視覺合約」。輸入圖片指定了主體的外貌、構圖、風格與其他視覺特徵,使生成的影片更貼近原始圖片。這是 AI 角色一致性 的基礎:模型將上傳的臉孔、衣物與構圖視為固定限制,而非建議。
這對以下情況最為重要:
- 需要在多個片段中保持同一張臉孔的品牌代言人內容
- 需要在不同場景中維持外觀的 IP 角色
- 視覺識別度為資產一部分的產品演示主持人
運動控制:投射物理數據
參考圖片鎖定外貌,Kling 2.6 運動控制 則透過將動作參考的姿勢、姿態與運動數據投射到生成的角色身上,增添物理層面。動作參考作為表演模板,模型在傳輸身體力學的同時,保留了由輸入圖片錨定的視覺身份。
這種身份(圖片)與動作(參考影片)的分離,使得 參考影片 AI 動畫 方法比單純透過文字描述動作更為可靠。
I2V 中的唇形同步與音訊對齊
當在圖生影模式中啟用原生音訊時,Kling 2.6 唇形同步 會自動處理。語音控制功能允許您使用 [Character@VoiceName] 格式將特定聲音綁定到角色,讓模型精確複製人聲特質以執行指定的內容。
| 輸入層 | 控制內容 |
| 參考圖片 | 臉孔、衣物、構圖、視覺風格 |
| 動作參考 | 手勢、姿勢變化、身體律動 |
| 語音控制綁定 | 音色、呈現風格、跨語言一致性 |
| 提示詞音訊區塊 | 對話內容、情緒標籤、環境音層 |
現成範例:將核心公式應用於圖生影 (I2V) 工作流
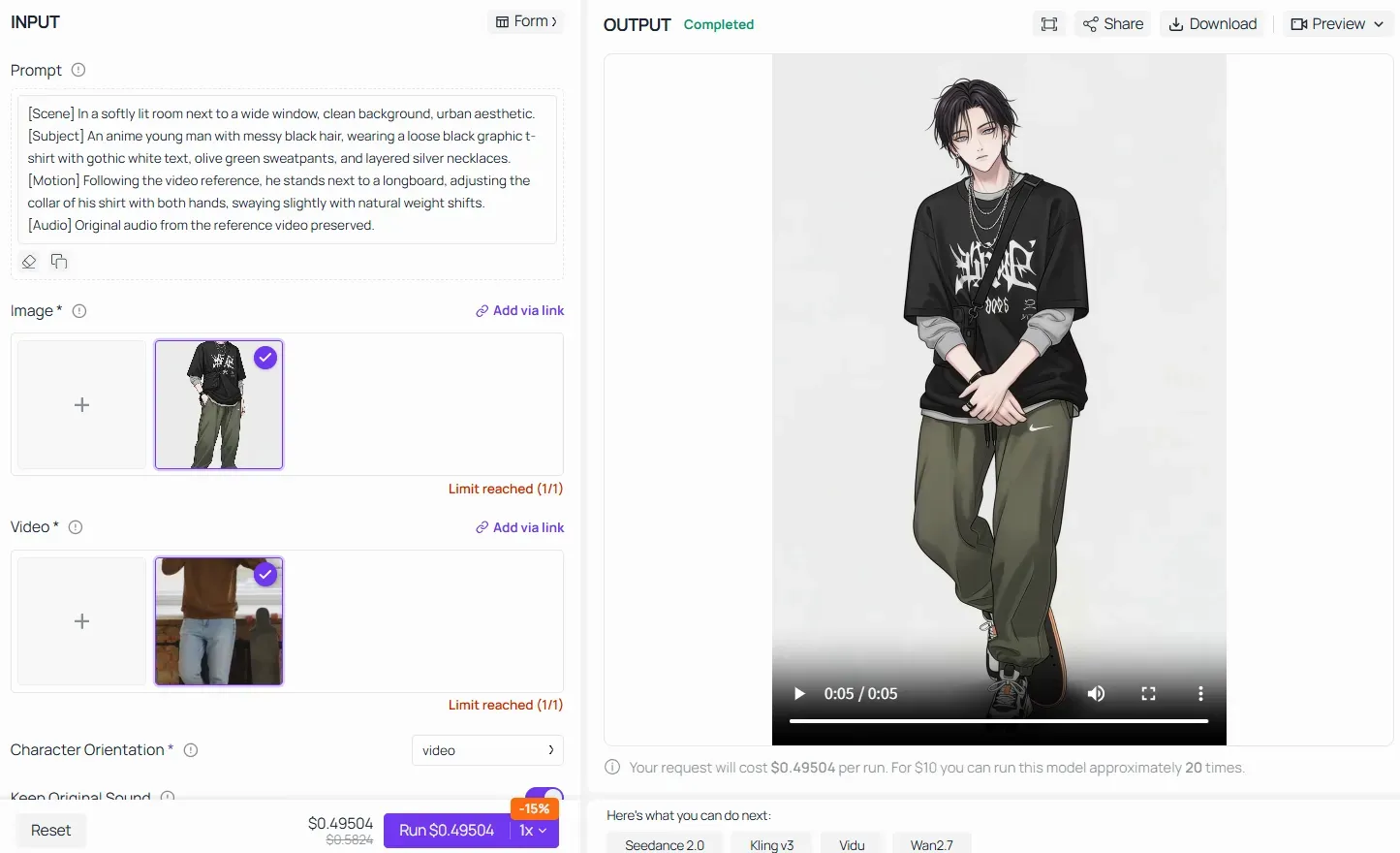
當在 Atlas Cloud 等平台上利用「影片參考 / 動作傳輸」等進階功能時,核心公式依然具有絕對的權威性。與其給 AI 模糊的指令如「讓動漫角色跳一樣的舞」,您必須透過分解場景、凍結上傳的主體特徵並鎖定動作映射來建構提示詞:
透過填滿管道中的每個區塊,您能確保 AI 模型將真實影片中沈重的骨骼力學無縫傳輸到上傳的動漫角色資產上,同時不破壞其視覺身份。
Kling 2.6 運動控制經驗法則: 您的文字提示詞無需糾結於微小的力學細節(例如「手臂上舉 45 度」)。將這些繁重的工作交給影片參考。相反地,使用您的 [Subject] 與 [Scene] 區塊來嚴格鎖定視覺風格、材質與色彩配置,確保 AI 在傳輸表演時不會扭曲原始圖片的身份。
圖片品質與實務限制
請記住一個重要原則:最終影片的品質取決於您上傳的圖片。
務必使用高解析度圖片。低解析度圖片會導致影片成品出現顆粒感與模糊,AI 無法在事後修復這些雜訊,這個問題在臉部特寫鏡頭中尤其明顯。
使用更高解析度的來源圖片,您的角色一致性就能在 5 秒與 10 秒的輸出窗口中維持穩定,不會衰減。
技術故障排除:解決生成瓶頸與音訊漂移
即使是經驗豐富的創作者,在使用 Kling 2.6 時也會遇到摩擦。最常見的兩個問題是生成在中途停滯,以及對話在片段後半段失去同步。兩者都有明確的起因與實用的解決方案。
為何 Kling 會卡在 99%
如果影片卡在 99%,通常有兩個原因。首先,伺服器可能過於繁忙;其次,您的提示詞可能對系統而言過於複雜。AI 嘗試同時構建所有聲音與畫面,如果提示詞中堆疊太多內容,指令就會產生衝突。這種混亂會拖慢系統或導致完全凍結。
嘗試順序解決方案:
- 稍後再試。重新整理頁面並在離峰時段提交提示詞(清晨通常效果最佳)。
- 簡化提示詞。將複雜的提示詞拆分為兩個較小的部分,作為獨立的影片生成處理。
- 移除堆疊的環境描述,每個片段保留一個主要音效層。
- 若單次生成中包含三名以上角色,請減少角色數量。
如何修正對話漂移
修正對話漂移的方法在於解決其根本原因:當語音指令過多競爭時,模型的多說話者處理能力會在 5-6 秒後下降。在涉及三名以上角色的場景中,效能可能會受影響。
| 場景 | 建議修正方案 |
|---|---|
| 10 秒以上的雙人對話 | 使用 10 秒時長並加入清晰的說話者切換提示 |
| 三人以上角色 | 拆分為每組說話者對應的獨立片段 |
| 長獨白漂移 | 縮短劇本,使其舒適地容納在 10 秒窗口內 |
| 歌唱中斷 | 音樂內容務必使用 10 秒參數 |
減少偽影與優化點數消耗
若要 減少生成偽影,請保持圖生影的來源檔案為高解析度,並避免場景描述不匹配。在 點數消耗優化 方面,請注意「專業模式」中啟用原生音訊每秒消耗 10 點,而禁用時每秒消耗 5 點。建議先以禁用音訊進行草稿製作,確認後再啟用以進行最終渲染,進一步延長您的 平台限制 預算。
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1:全面對比
不要期待單一 AI 影片工具能包辦所有事情。當您需要內建音訊時,「最佳」選擇取決於您的預算、工作流以及影片片段的實際需求。
功能比較概覽
| 功能 | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
|---|---|---|---|---|
| 原生音訊 | 完整 (對話/音效/環境) | 完整 (單次同步) | 完整 (含唇形同步) | 完整 (3D 空間音訊) |
| 最大片段長度 | 10 秒 | 15 秒 | 15 秒 | 8 秒 |
| 最大解析度 | 1080p | 原生 4K | 1080p | 原生 4K |
| 運動控制 | 強 (骨骼/影片參考) | 強 (完整身份鎖定) | 中 (風格/動作傳輸) | 中 (流體力學物理) |
| 多鏡頭 | 無 | 有 (單次最高 6 鏡) | 有 (支援多場景長文字) | 無 |
| 語音控制 | 有 | 有 | 無 (依賴提示詞) | 無 (依賴提示詞) |
| 定價 | $0.048 - $0.095/s | $0.071 - $0.357/s | $0.018 - $0.7/s | $0.05 - $0.2/s |
註:定價參考 Atlas Cloud。
Kling 2.6 的優勢所在
Kling 2.6 與 Wan 2.6 的音訊對比並非勢均力敵。Wan 2.6 僅具備部分音訊支援,而 Kling 2.6 能在一次生成中提供完整的原生對話、音效與環境音層。對於需要無需後製、直接可用的音訊片段的創作者來說,Kling 2.6 是更簡潔的工作流。
Kling 2.6 的成本比 Veo 3.1 低 50% 以上。如果您不需要好萊塢級的影片畫質,Kling 是更明智的選擇,它能讓您以預算內創造大量內容。
Veo 3.1 的強項所在
Veo 3.1 與 Kling 影片 的選擇取決於真實感與音訊空間化。Veo 3.1 能生成三維音訊環境,音訊來源可在立體聲場中移動,輸出為 48kHz 的立體聲 AAC 編碼 (192kbps)。截至 2026 年 3 月,沒有其他主流 AI 影片模型提供此等級的空間音訊。對於廣播級的對話與文字渲染,Veo 3.1 依然是更強的選擇。
AI 影片物理表現比較
在 AI 影片物理 方面,各模型分歧明顯。Kling 2.6 以優秀的運動流暢度與符合人體工學的物理模擬見長,而 Veo 3.1 雖偶有物理不一致,但在光影與紋理表現上極為卓越。
決策框架
- 選擇 Kling 2.6:用於語音控制角色、預算導向製作、社交媒體內容、一次生成完成的視聽成品。
- 選擇 Kling 3.0:用於長篇電影鏡頭、多場景腳本、4K 輸出。
- 選擇 Wan 2.6:用於開源、零成本迭代與草稿測試。
- 選擇 Veo 3.1:用於空間音訊、文字渲染、照片級真實感產品廣告。
結論:AI 電影製作的新節奏
傳統影片製作流程——匯出視覺畫面、獨立生成配音、疊加音效、再進行後製混音——在使用 Kling 2.6 時已不再適用。整個過程現在已簡化為一次提示詞提交。
進步最快的創作者,是那些將提示詞撰寫視為導演技藝而非搜尋查詢的人。邁向專業級影片的真正訣竅很簡單:只需將場景、主體、動作與聲音計畫打包進一個清晰的提示詞中。
目前,Kling 2.6 是市面上最強大的工具之一,非常適合大型內容團隊、個人創作者以及追求快速、高品質影視的行銷工作室。技術門檻將持續升高,現在精通提示詞結構,就是為未來發展打下創意基礎。






