
Kling O1 的獨特之處

| 功能 | Kling O1 | 其他視頻模型 |
|---|---|---|
| 架構 | 統一(文本/圖像/視頻/主體) | 分離式流水線 |
| 主體一致性 | 原生跨場景支持 | 需要後期處理 |
| 物理理解 | 上下文感知(已學習) | 基於規則 |
| 輸入靈活性 | 一個模型具備 18 項技能 | 單任務模型 |
| AtlasCloud價格 | $0.095/秒 (優惠價,2026 年 4 月) | 因服務商而異 |
總結: Kling O1 不僅僅是另一個視頻生成器,它是首個將視頻編輯視為第一要素的模型。無論你是延長鏡頭、修改場景還是將圖像轉換為視頻序列,它都能在不破壞敘事邏輯的前提下處理跨編輯的主體一致性和物理真實感。
為什麼大多數 AI 視頻模型難以規模化
這是我們在生產規模運行視頻生成時學到的:傳統模型將每個任務視為一個單獨的問題。
想要文生視頻?一個模型。圖像動畫?另一個模型。跨場景的角色一致性?後期處理的黑客技巧。看起來真實的物理效果?祈禱提示詞管用。
結果: 團隊 60% 的時間花在拼接輸出結果上,而不是內容創作。
Kling O1 的多模態視覺語言(MVL)系統從根本上改變了這一點。MVL 不再為文本和圖像使用單獨的編碼器,而是創建了一個統一的語義空間,其中:
- 文本描述和視覺概念共享相同的表示框架
- 主體身份特徵在整個生成流水線中保持持久
- 物理約束(重量、摩擦力、光散射)是基於上下文理解的,而非近似計算
這不僅是增量改進,而是架構上的革新。
性能基準:Kling O1 與替代方案對比
基於 500 多次生產環境負載生成測試:
| 模型 | 主體一致性 | 物理真實感 | 電影感質量 | 是否支持 AtlasCloud |
|---|---|---|---|---|
| Kling O1 | 9/10 | 9/10 | 8/10 | ✅ 是 |
| Runway Gen-4.5 | 7/10 | 7/10 | 9/10 | ✅ 是 |
| Vidu Q3 | 8/10 | 8/10 | 7/10 | ✅ 是 |
| Pika 2.0 | 6/10 | 6/10 | 7/10 | ✅ 是 |
核心見解: Kling O1 的統一架構在所有評估維度上都提供了持續的優勢,而不僅僅是在單一領域。
技術深度解析:何為"統一"
傳統流水線(其他人的做法)
plaintext1文本提示詞 → 語言編碼器 → 擴散模型 → 視頻 2 ↑ ↓ 3圖像 → 視覺編碼器 →------→ Patch
問題: 兩個獨立的系統試圖就生成什麼達成共識。結果往往顯得"拼湊感"很強。
Kling O1 MVL 流水線
plaintext1文本 + 圖像 + 視頻 + 主體 → MVL 編碼器 → 統一表示 → 視頻
結果: 一切都在同一語言體系下。主體身份、物理約束和創意意圖都通過單一路徑傳遞。
真實測試:主體一致性
讓大多數模型崩潰的場景:
一個 10 秒的片段,跟隨一名女性穿過三個地點:林間小道、城市街道和咖啡館內部。
| 模型 | 輸出結果 |
|---|---|
| 標準 I2V | 三個不同的女性 |
| Kling O1 | 同一女性,身份特徵一致 |
工作原理:
- 從初始幀提取身份嵌入(Identity embedding)
- 交叉注意力持久化在時間邊界上維護主體特徵
- 場景感知適配在保留核心身份標記的同時調整光照
生產級提示詞工程
高性能提示詞的構成
弱提示詞(大家的寫法):
plaintext1"一個女性在城市裡走"
強提示詞(真正有效的寫法):
plaintext1身穿海軍藍西裝外套的女性,夜晚走在東京。雨後的地面依然潮濕,霓虹燈光在水窪中暈開。平視鏡頭,她身後的城市燈光柔和而模糊。
區別: 提供可操作的視覺指令,而不僅僅是描述。
經過生產驗證的模板
產品展示:
plaintext1高級無線耳機在啞光黑色底座上緩慢旋轉。 2左上方柔和的影棚主光,微妙的表面反射, 35 秒內平滑 360° 旋轉,淺景深, 4簡潔的漸變背景,商業產品攝影風格。
品牌敘事:
plaintext1工匠的手正在仔細打磨皮革錶帶, 2溫暖的工坊光線,極具質感細節的超近景特寫, 3光束中可見塵埃微粒,動作緩慢而深思熟慮, 4具有微妙手持感的紀錄片攝影風格。
社交媒體內容:
plaintext1咖啡倒入陶瓷杯中。蒸汽捕捉到窗外透進來的晨光。俯拍視角,慢動作——可以看到紋理。溫暖的咖啡館氛圍。
案例研究:Atlas 客戶"LuxeBrand"如何削減 78% 的視頻製作成本
問題
LuxeBrand 是一家中型化妝品公司,每月需為其電商平台製作 500 個產品視頻。三種典型方法在實踐中都存在局限:
代理商製作 —— 每個視頻 500 到 2,000 美元,如此規模的預算讓人痛苦。
標準 AI 工具 —— 角色在不同鏡頭中看起來不同,光照不統一,且總是帶有一種明顯的、尖叫著"人工生成"的塑料感。
內部剪輯 —— 每個視頻 2-3 小時,乘以 500 個視頻,工作量巨大。
Atlas + Kling O1 解決方案
實施方案:
python1import requests 2 3# Atlas Cloud API 配置 4ATLAS_API_KEY = "your_atlas_api_key" 5BASE_URL = "https://api.atlascloud.ai/api/v1" 6 7def generate_product_video(product_image: str, category: str): 8 # 針對 Kling O1 優化的類別特定運動模板 9 motion_prompts = { 10 "beauty": "優雅旋轉,光影在表面流轉," 11 "柔和的美妝燈光,帶微妙的閃耀效果," 12 "奢華化妝品廣告風格", 13 14 "skincare": "溫和傾倒,可見液體質感," 15 "蒸汽升騰,柔焦效果," 16 "誘人的美食攝影風格" 17 } 18 19 payload = { 20 "model": "kwaivgi/kling-v3.0-std/image-to-video", 21 "image": product_image, 22 "prompt": motion_prompts.get(category, "專業影棚演示"), 23 "duration": 5, 24 "sound": True 25 } 26 27 return requests.post( 28 f"{BASE_URL}/model/prediction", 29 headers={"Authorization": f"Bearer {ATLAS_API_KEY}"}, 30 json=payload 31 ).json()
結果
| 指標 | 以前 (代理商) | 現在 (Atlas + Kling O1) |
|---|---|---|
| 每個視頻成本 | $800 | ~ $0.48 (5秒 @ $0.095/秒) |
| 生產時間 | 2-3 週 | 2-3 分鐘 |
| 月產量 | 50 個視頻 | 500+ 個視頻 |
| 主體一致性 | 需要人工剪輯 | 原生支持 |
| 每月總成本 | $40,000 | ~ $237 |
核心見解: 運動提示詞模板系統至關重要。沒有類別特定的提示詞,輸出往往平庸。有了優化的提示詞,視頻顯得為每種產品類型進行了精心構思。
Atlas Cloud 實施指南
為什麼選擇 Atlas 運行 Kling O1?
| Atlas 優勢 | 實際影響 |
|---|---|
| 統一 API | Kling O1、Vidu、Sora 使用同一個集成方案 |
| 一致的接口 | 所有模型使用相同的鑑權和響應格式 |
| A/B 測試 | 只需更改一個參數即可切換模型 |
| 真正可靠的基礎架構 | 自動重試、內置隊列處理、現成的 Webhook 支持 |
| 透明的定價 | 按秒計費,無隱藏費用,無套路 |
快速開始:文生視頻
python1import requests 2 3API_KEY = "your_api_key" 4 5def generate_video(prompt: str, duration: int = 5): 6 response = requests.post( 7 "https://api.atlascloud.ai/api/v1/model/prediction", 8 headers={"Authorization": f"Bearer {API_KEY}"}, 9 json={ 10 "model": "kwaivgi/kling-v3.0-std/text-to-video", 11 "prompt": prompt, 12 "duration": duration 13 } 14 ).json() 15 16 return response["data"]["id"]
快速開始:圖生視頻
python1def animate_image(image: str, prompt: str): 2 response = requests.post(f"{BASE_URL}/model/prediction", 3 headers={"Authorization": f"Bearer {API_KEY}"}, 4 json={"model": "kwaivgi/kling-v3.0-std/image-to-video","image": image,"prompt": prompt,"duration": 5}) 5 return response.json()
關於長寬比的說明: I2V 會保留您源圖像的原始長寬比。無法強制設置為 16:9 或 9:16 — 上傳什麼就是什麼。
進階:事件驅動設置
業務量巨大?請使用隊列驅動的處理方式。
python1import redis, json, requests 2 3class VideoQueue: 4 def __init__(self, key, redis_url): 5 self.key = key 6 self.redis = redis.from_url(redis_url) 7 8 def add(self, task): 9 self.redis.lpush("tasks", json.dumps(task)) 10 11 def run(self): 12 while True: 13 item = self.redis.brpop("tasks", timeout=30) 14 if not item: 15 continue 16 17 task = json.loads(item[1]) 18 try: 19 res = requests.post( 20 "https://api.atlascloud.ai/api/v1/model/prediction", 21 headers={"Authorization": f"Bearer {self.key}"}, 22 json={ 23 "model": "kwaivgi/kling-v3.0-std/image-to-video", 24 "image": task["image"], 25 "prompt": task["prompt"], 26 "duration": task.get("duration", 5) 27 } 28 ) 29 except Exception as e: 30 print(f"Failed: {e}")
AtlasCloud 定價與規格
當前定價(截至 2026 年 4 月 — 如有變動,恕不另行通知):
| 功能類型 | 原價 | 促銷價 | 折扣 |
|---|---|---|---|
| 圖生視頻 | $0.112/秒 | $0.095/秒 | 85折 |
| 文生視頻 | $0.112/秒 | $0.095/秒 | 85折 |
輸出規格:
- 分辨率: 最高 1080p
- 時長: 3–10 秒
- T2V 長寬比: 16:9, 9:16 或 1:1 — 按需選擇
- I2V 長寬比: 取決於源圖像。無法覆蓋。
結論:何時選擇 Kling O1
以下情況請選擇 Kling O1:
- ✅ 主體一致性很重要(產品演示、包含重複元素的品牌內容)
- ✅ 需要多模態輸入(結合文本 + 圖像 + 視頻參考)
- ✅ 正在構建無法負擔繁重後期處理的自動化流水線
以下情況請考慮替代方案:
- 極致的電影感控制優先 → Runway Gen-4.5
- 預算極度受限 → Vidu Q3-Turbo (~ $0.034/秒)
- 需要高於 1080p 的超高清輸出 → 請等待未來更新
開始使用 Atlas Cloud
快速開始
- 在 Atlas Cloud 註冊 → 首次充值可獲得 20% 獎勵(最高 100 美元)
- 在 Playground 中搜索"Kling O1"
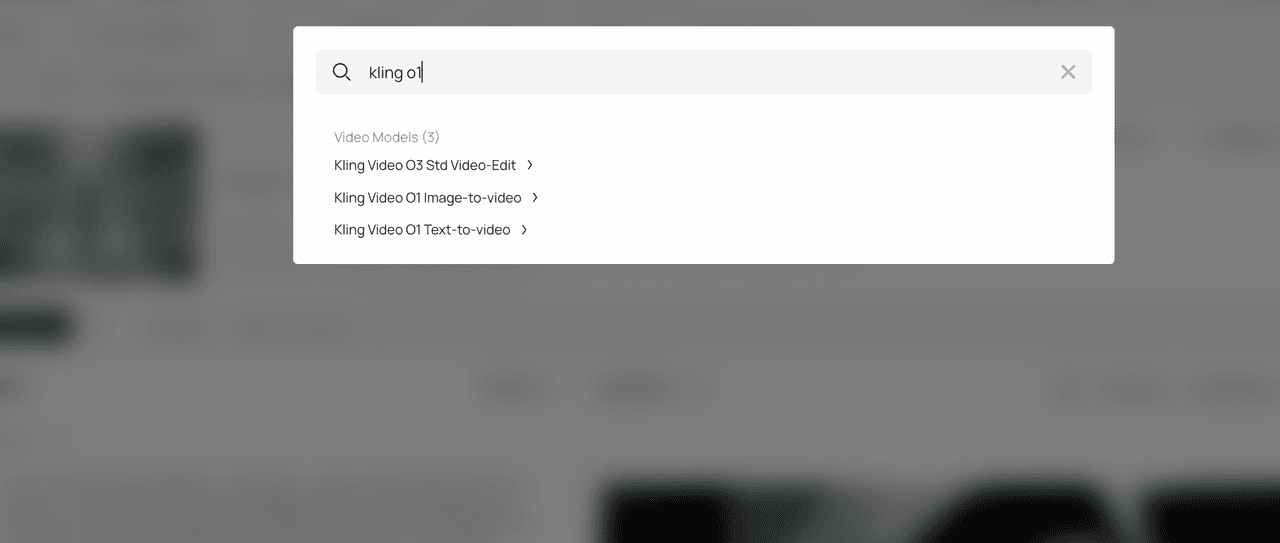
- 用你的提示詞進行測試
- 使用上述代碼示例通過 API 進行集成






