
MiniMax 剛剛預告了在 1M token 內容長度下,解碼速度提升 15.6 倍的技術。 如果這個數字屬實,運行百萬級 token 上下文的成本將降低近一個數量級,且在加速的同時,生成品質不會下降。
對於任何基於這些模型進行開發的團隊來說,這重新定義了成本效益的門檻。那些原本不划算的工作負載現在開始變得可行:例如將整個程式碼庫而非片段交給編碼代理 (coding agent)、處理累積了龐大歷史紀錄的長時間代理運行、針對整套文件集而非破碎片段進行檢索。每個團隊都在糾結的問題——「在費用爆炸或延遲拖垮產品之前,我能在上下文視窗裡塞多少內容?」——現在有了更高的天花板。
實現這一點的機制是稀疏注意力 (sparse attention),且 MiniMax 並非孤例。DeepSeek 已在三條模型產品線中採用該技術,Qwen 也有自己的版本,現在則是 MiniMax。技術發展方向已定。正在改變的是其影響:當每個前沿模型都能以低成本運行長上下文時,模型本身就不再是競爭壁壘——而這正是值得你關注的部分,我們將在文末回過頭來討論。
首先提出兩點誠實的警示,因為這對任何打算部署此技術的人都很重要:
- 這些是 MiniMax 自家的數據,來自一份尚未發布模型的單一預告圖,且是在他們自己的環境中測得。這是一個強烈的發展信號,但並非第三方基準測試。請將其視為「MiniMax 的聲明」,並在模型權重釋出後,針對你自己的工作負載進行重新測試。
- M3 尚未公開。我們預計將在它開放時,透過 Atlas Cloud 提供首日存取 (day-zero access)——詳情見文末。
那麼,MiniMax 是如何做到這一點的?5 月 26 日,MiniMax 研發負責人 Skyler Miao 在 X 上發布了一張圖表——色調簡約、資訊密度極高——標題為《MiniMax 稀疏注意力》,其中兩條曲線帶出了所有人關注的數據:在 1M token 下,預填充 (prefill) 速度快 9.7 倍,解碼 (decode) 速度快 15.6 倍。 社群一致認為這是 M3 的預告。我們對此進行了拆解,以了解這些數字背後的架構。
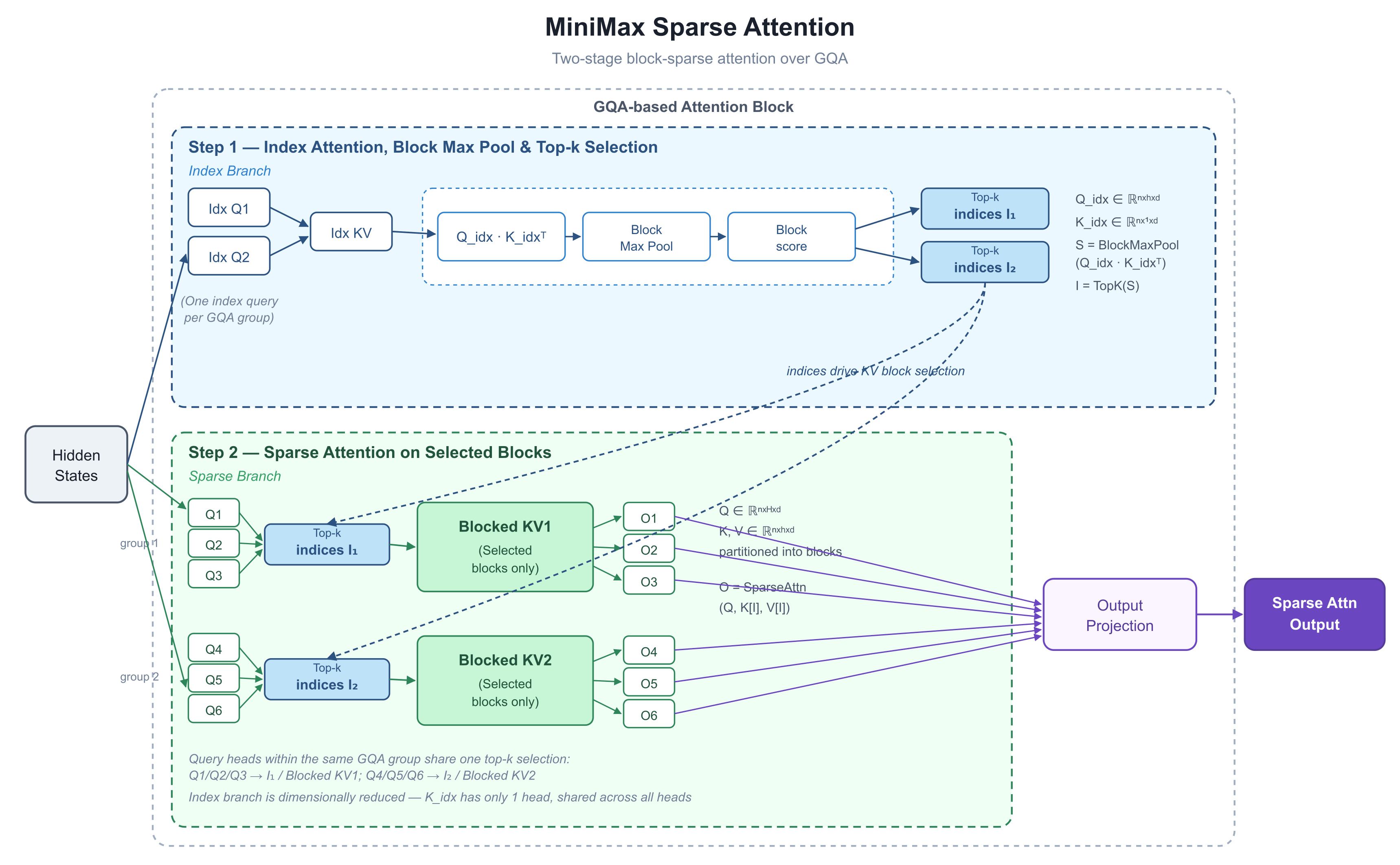
在深入解析之前,先進行一些背景說明。三個術語貫穿了整個故事:
- 預填充 (Prefill) 是模型一次性讀取輸入的過程。
- 解碼 (Decode) 是較慢的、逐個 token 進行輸出的階段——而在長上下文中,解碼階段最為棘手,因為每個新生成的 token 都必須回顧之前的所有內容。
- 稀疏注意力 (Sparse attention) 是解決方案:模型不再讓每個 token 都關注其他所有 token(預設方式,其成本隨序列長度的平方增加),而是讓模型只關注精心挑選的「子集」——在保留大部分品質的同時,僅消耗少量的運算資源。如何選擇該子集,正是各家實驗室的差異所在。
而這個預告之所以具備分量,是因為去年 10 月,MiniMax 曾發表一篇名為《為什麼 M2 最終選擇了全注意力模型?》的文章——語氣極為直接,解釋了 M2 捨棄了 M1 的高效「Lightning Attention」,因為當時高效注意力技術尚未達到生產就緒水準。六個月後,M3 帶著稀疏注意力強勢登場。潛台詞只有一句:這次,它準備好了。
1. 圖表解析:兩個階段——先篩選,再運算
該圖表展示了一個注意力區塊的內部運作。其關鍵動作是將「要查看哪些 token」與「如何對這些 token 進行注意力運算」這兩個步驟明確分開。
關於底層架構的說明:M3 是建立在 GQA (Grouped-Query Attention,分組查詢注意力) 之上的。在標準注意力層中,每個「查詢頭 (query head)」都有自己的一組鍵 (keys) 和值 (values),這雖然表現力強,但會導致 KV 快取(KV cache——儲存先前所有 token 的鍵與值,以便不必在每一步重新計算)膨脹。GQA 將查詢頭分組,每組「共享」一組鍵與值。這是目前大多數生產模型中使用的主流記憶體節約布局。記住這一點——這是整個設計的基礎。
步驟 1:索引分支 (Index Branch) —— 以低成本評分一切
上半部分是索引分支。它在主路徑之外運行,任務只有一個:告訴區塊中剩餘的部分,哪些 token 區塊值得關注。
每個 GQA 組共享一個索引查詢(圖中顯示了 6 個實際的頭與 2 個索引查詢「Idx Q」配對,每組一個)。該分支的鍵端經過了刻意的精簡:

請注意,K_idx 只有一個頭——每個頭都共享相同的索引鍵。這使得評分步驟 (Q_idx · K_idxᵀ) 的成本幾乎為零。
區塊最大池化 (Block Max Pool) 隨後將這些 token 層級的評分壓縮為區塊層級的評分(將序列切分為固定大小的區塊,並保留每個區塊中的最高評分):

最後,TopK——「保留前 K 個最高分項目」——決定了哪些 KV 區塊能存活下來以供此層和此組使用。輸出是一個短小的索引列表:I₁, I₂。
步驟 2:稀疏分支 (Sparse Branch) —— 注意力實際運行的位置
下半部分是真正的運算。查詢、鍵與值仍然保持標準的 GQA 形式。利用步驟 1 得到的 I₁ 和 I₂,該區塊只從完整的鍵與值中提取選定的子集,並僅對這些子集執行注意力運算:

最重要的設計選擇: 組中的每個查詢頭共享同一個 Top-K 選擇結果。在圖中,Q1/Q2/Q3 全都使用 I₁;Q4/Q5/Q6 全都使用 I₂。這就是 DeepSeek 的 NSA 論文所強調的硬體對齊原則——一組查詢載入一組 KV 區塊,該組資料能放入 SRAM(GPU 內部極快的小型記憶體)中進行單次處理,且標準的 FlashAttention 型核心(主流的注意力實作優化)可以原封不動地重複利用。
2. 相較於 DeepSeek 家族的三個刻意減法
社群立刻將此設計與 DeepSeek 的三種稀疏注意力設計進行了對比:
- NSA (Native Sparse Attention): 「Native」意味著稀疏性從預訓練開始就已寫入,而非後期疊加。它包含三個並行分支(壓縮 + 選擇 + 滑動視窗)加上一個學習門控 (learned gate)。
- DSA (DeepSeek Sparse Attention): DeepSeek V3.2 中採用的變體;具有極輕量索引器的 token 層級選擇。
- CSA: 社群對與 DeepSeek V4 相關的區塊層級方向的簡稱。(此標籤不如 NSA/DSA 標準,故僅作為工作代稱)。
社群對 M3 的一句總結:M3 使用 GQA 而非 MLA,採取類似 CSA 的區塊層級選擇,但它在「真實」鍵與值上進行注意力計算。
展開為表格如下:
| 維度 | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (推測) |
|---|---|---|---|---|
| KV 底層架構 | MLA (潛在向量) | GQA | MLA | GQA |
| 選擇粒度 | token 層級 | 區塊層級 | 區塊層級 | 區塊層級 |
| 並行分支 | 1 (索引器 + 選擇) | 3 (壓縮+選擇+滑動) | 1 | 1 (僅選擇) |
| 注意力運行位置 | 真實 K/V | 三路融合 | 壓縮後的 KV | 真實 K/V |
| 索引器成本 | Lightning 索引器 | 壓縮分支 | 區塊摘要 | 單頭 K + 區塊最大池化 |
| 門控 | 無 | 學習門控 | 無 | 無 |
該表隱藏了另一個值得定義的縮寫:MLA (Multi-head Latent Attention,多頭潛在注意力),這是 DeepSeek 的標誌性招式。MLA 不快取完整的鍵與值,而是將其壓縮成一個小的共享「潛在」向量進行快取,並在運行時即時解壓。KV 快取會大幅縮小,但其數學邏輯不再符合標準注意力,因此需要自訂核心。這種對比引出了 M3 的三個權衡中的第一個。
第一個減法:以 GQA 為底層,而非 MLA。 由於 M3 保持使用標準 GQA,現有的服務堆疊——vLLM 和 SGLang(兩種廣泛使用的開源推理伺服器)加上 FlashAttention——無需修改或僅需微調即可運作。無需為了繞過 MLA 的潛在 KV 而進行繁瑣的工程作業。對於目標是「生產就緒」的實驗室來說,這是風險最低的路徑。這是整個設計中最具商業邏輯的洞見:MiniMax 優化了所有人在硬體和軟體上現有的一切。
第二個減法:區塊層級選擇,但在真實鍵與值上運行注意力。 與對「壓縮後」KV 進行注意力運算的 CSA 不同,M3 保留了標準 Softmax 注意力的完整表現力。代價是:KV 快取不會隨著稀疏化而縮小——但為了保留品質而犧牲部分記憶體,是一個明智的交易。
第三個減法:NSA 的另外兩個分支消失了。 NSA 運行三條並行路徑(壓縮 + 選擇 + 滑動視窗)加上一個學習門控。M3 僅保留了選擇機制。社群的一種總結稱其為精簡版 NSA。一句話總結:工程優先。在被刪除的兩個分支中,滑動視窗很可能被 RoPE(旋轉位置嵌入——模型編碼 token 位置的標準方法)加上注意力匯點 (attention sink) 所取代,或者乾脆像 Gemma 3 和 Qwen3-Next 那樣,作為每層的密集注意力備選方案。壓縮分支則被吸收進了極簡的「單頭 K + 區塊最大池化」中。
3. 如何解讀這些數字
| 階段 | 1M 速度提升 | 含義 |
|---|---|---|
| 預填充 | 9.7× | 一次性處理 1M token 的輸入 |
| 解碼 | 15.6× | 逐個 token 生成 |
解碼速度超越預填充是合理的。在預填充期間,索引分支仍需掃描完整的輸入長度,因此節省的效果僅體現在主要注意力上。在解碼期間,每個新生成的 token 只與其選定的 KV 區塊互動,KV 快取的記憶體頻寬壓力下降了約一個數量級——這正是解碼階段成本的主要來源。
反推選擇比:假設區塊大小為 64 個 token,則 1M token 約為 16,000 個區塊。15.6 倍的解碼加速意味著每個查詢實際只接觸了約 6-7% 的區塊——有效的感受野約為 60k-70k token。該比例幾乎精確地落在 NSA 論文報告的稀疏率 (6-10%) 上。這絕非巧合——這正是此類設計在 1M 規模下的甜蜜點。
4. 推測 M3 的其餘部分
從這個注意力區塊外推到整個模型——顯然是針對推理進行了優化:
- MoE 主幹可能會保留。MoE (Mixture of Experts,混合專家模型) 是模型的主幹(區別於注意力):模型不再將每個 token 通過一個巨大的網路,而是透過路由器將每個 token 發送到少數幾個專業的「專家」子網路,從而以較小的實際運算量獲得大模型的品質。M2 發布時為 230B 總參數 / 約 10B 活躍參數 / Top-2 路由;M2.7 已將專家數量提升至 256。沒有理由讓 M3 放棄這一點——可能的變化是更深、更寬。
- 全注意力堆疊被區塊稀疏 GQA 取代。 M1 的 Lightning Attention 不太可能回歸。M3 並未重注線性注意力;它走的是「Softmax 表現力 + Top-K 區塊選擇」路線——在保持品質的同時實現亞二次方的成本。
- 極有可能是原生訓練的稀疏性。 這是 NSA 論文的核心教訓:稀疏模式必須在預訓練期間進入梯度,否則模型的檢索行為會變得混亂。MiniMax 有自己的檢索頭研究路線,因此他們不應落入該陷阱。
- 主戰場是 1M+ 的上下文。 M1 在訓練時為 1M,在推理時外推至 4M。M3 看起來準備在鎖定該能力的同時,大幅削減推理成本——這是一個非常自然的產品節奏。
5. 將 M3 置於 2026 年的設計空間
在 2025-2026 年間,稀疏注意力設計迅速分化:
- DeepSeek V3.2 DSA: MLA + token 層級 Top-K,極輕量索引器;品質最穩定,但核心工程複雜。
- DeepSeek NSA: GQA,三分支 + 門控;品質天花板最高,實作最複雜。
- Qwen3-Next: 層級化的密集與線性注意力混合;穩健但相對保守。
- MiniMax M3: GQA + 單分支區塊選擇;極簡,乘著硬體發展的順風車。
M3 設計的潛台詞是明確的:不要追求理論上最完美的注意力——要追求那些能立即執行、運行迅速,並允許重複利用現有核心的注意力技術。這與 M2 在最終選擇回歸全注意力的決策是一致的:首先用主流方法穩定品質,一旦技術真正成熟,再乾淨地進行替換。
6. 如果你正在建構下一波 AI 應用,這意味著什麼
跳出架構層面,這背後有一個更大的規律。每家嚴肅的實驗室現在都在發布自己版本的訓練內建稀疏注意力——DeepSeek 在三條產品線中採用,Qwen 有層級混合,現在是 MiniMax。技術方向已定,結論顯而易見:當每個前沿模型都能以低成本運行長上下文時,模型本身就不再是競爭壁壘。 原始推理成本正趨向商品化。差異化轉移到了更高層次——即針對特定工作負載運行「哪個」模型、如何在它們之間進行路由,以及在下一代模型六週後推出時,你更換的速度有多快。
這是一個比「找到最便宜的端點」更難的問題。一個運行生產級應用的團隊正在同時平衡四件事——品質、延遲、成本以及該功能實際驅動的業務成果——而正確答案會因工作負載而異,並隨每個發布週期而變動。M2 在 10 月是全注意力的;M3 在 5 月就變成了區塊稀疏的。你上一季所連接的模型已經落後了。
選擇最便宜的模型對開發者而言不再是制勝策略。取而代之的是,那些建立在能讓他們選擇、路由和更換模型,而無需在前沿技術每次移動時都重新整合的層級之上的開發者,以及那些將工程預算花在自有產品上,而非每幾週追逐發布說明的人,才能贏得勝利。
這正是 Atlas Cloud 運作的層級:透過單一 API 存取超過 300 種模型,涵蓋 LLM、影片、圖像和音訊,並具備智慧路由和新模型發布時的「首日存取權」。我們拆解此圖表所用的視角,正是我們決定引進哪些模型以及如何路由它們的視角。M3 尚未公開——當它開放時,我們預計將在 Atlas 上提供首日存取權,讓基於我們開發的團隊在模型發布當天,而非數月後,就能將其呈現在使用者面前。
結語
單憑一張圖表無法確認的事項還有很多:稀疏模式是否在各層之間混合、是否有密集注意力備選、索引分支是否與主網路共享嵌入、訓練時的 Top-K 是硬 (hard) 還是軟 (soft) 的、索引分支的損失函數是如何制定的。這一切都要等待官方論文或權重的公布。
但有一點已經確定:繼 DeepSeek 之後,另一家頂尖實驗室已將稀疏注意力 + 長上下文 + 開放權重組合成了有效的技術棧。在 2026 年下半年,開源環境中的 1M 上下文很可能從賣點轉變為基礎配置——而這本身,就比任何單一基準測試分數都重要得多。
參考文獻
- Skyler Miao (MiniMax 研發負責人),X 上的原始貼文:Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- 社群總結:MiniMax details its M3 sparse attention architecture — https://digg.com/ai/78gnmbpg
- MiniMax 部落格:Why Did M2 End Up as a Full Attention Model? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- DeepSeek NSA 論文:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- DeepSeek V3.2 DSA 解析:Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka:A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- MiniMax-01 技術報告:Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






