
Google Nano Banana 2 Lite(即 gemini-3.1-flash-lite-image API 端點)是一款專為快速應用設置而打造的輕量級、高速 AI 工具。它是目前市面上最實惠的 Google 圖像 API。它能在短短 4 秒內將文字轉化為圖像,非常適合需要快速生成大量圖像的各類大型商務應用。

對於開發高併發應用程式的工程師而言,等待數百個自動化圖像生成隊列完成是一項令人筋疲力盡的瓶頸。當您的平台需要動態渲染數以千計的在地化廣告變體、用戶頭像或快速網頁原型時,依賴高階創意模型會迅速拉高生產成本並拖累用戶體驗。高延遲和昂貴的單圖費用,常迫使開發團隊必須在應用程式速度與每月營運預算之間做出取捨。
Google 透過其創意模型系列的最新成員解決了這一難題。藉由根據明確的工作負載需求區分效能層級,開發人員現在可以優化高頻率的資產管線,而無需為不必要的渲染能力支付額外溢價。這項解決方案的核心在於一款專為快速程式化部署而設計的輕量級圖像生成模型。
滿足對「最便宜 Google 圖像 API」的需求
對於運行高流量視覺工作流的工程團隊來說,傳統的圖像生成 API 帶來了重大的財政挑戰。當擴展到數百萬次自動化 API 調用時,每張圖片支付數美分的成本將變得難以持續。這種經濟門檻推升了市場對一種真正能夠處理大量請求,且不會帶來巨大基礎設施開銷的最便宜 Google 圖像 API 的需求。
gemini-3.1-flash-lite-image 模型的推出,透過改變經濟門檻,重新定義了程式化圖像生成的架構。它不再將每個視覺請求視為高價值的藝術資產,而是將高頻率圖像生成視為基礎公用資源。這使得軟體工程師能夠將流暢的即時圖像創作直接嵌入多租戶應用程式及互動式社群軟體中,並將成本效益作為首要的營運指標。
Nano Banana 2 Lite 效能基準深度解析
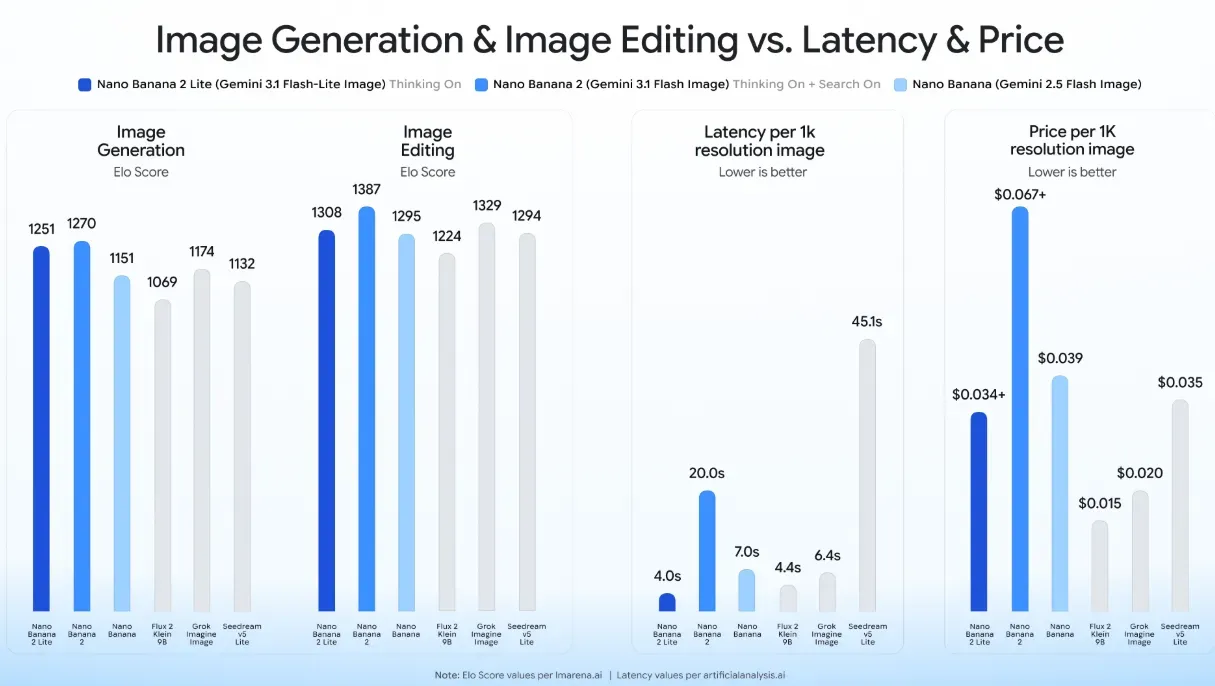
這款以效能為優先的模型層級商業名稱為 Nano Banana 2 Lite。該模型在設計上嚴格聚焦於最大化處理吞吐量並最小化回應開銷。實際測試和官方規格證實,該模型的文字轉圖像生成延遲可低至 4 秒。這一快速的回應速度比標準模型層級快了約 5 倍,將開發流程從非同步的隊列式操作轉變為同步、近乎即時的用戶體驗。
Nano Banana 2 Lite 效能指標
| 參數維度 | 官方規格 / 指標 | 註釋與營運模式 |
| 支援模態 | 輸入:文字、圖像、影片;輸出:文字、圖像 | 不支援音訊;影片僅供輸入。 |
| 上下文視窗限制 | 最大輸入:65,536 tokens;最大輸出:4,096 tokens | 針對高頻率、快速應用的邏輯進行了優化。 |
| 核心能力 | 圖像生成、交錯式圖像/文字、編輯圖像、多輪圖像編輯 | 不支援透過影片輸入生成圖像。 |
| 輸出解析度 | 嚴格為 1K(約 1 百萬像素) | 每生成 1K 圖像消耗 1,120 個輸出圖像 tokens。 |
| 支援的長寬比 | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | 完美涵蓋標準電子商務、社群媒體及橫幅廣告版面。 |
| 單一提示詞限制 | 最大輸入圖像:每個提示詞 14 張;最大輸出圖像:受限於 32,768 個輸出 tokens | 檔案數量最終受限於 65,536 個 tokens 的上下文視窗。 |
| 多模態 Token 成本 | 輸入圖像:1,120 tokens/張;輸入影片:70 tokens/秒(以 1 fps 採樣) | 文字輸入與輸出模態需額外收費。 |
| 併發安全機制 | 支援配置吞吐量 (Provisioned Throughput) | 對於企業級平台在峰值負載下確保 4 秒延遲至關重要。 |
Nano Banana 2 Lite 相較於舊型模型的效能提升,源於架構上的實質改進。與舊版的 gemini-2.5-flash-image 模型相比,新的 Lite 版本具備以下技術優勢:
- 世界知識整合: 該模型對地理位置、物理結構和抽象空間佈局具備高度精確的上下文理解能力,非常適合快速進行 UI/UX 線框圖設計。
- 角色一致性: 在連續生成過程中能維持穩定的角色特徵和結構物件細節,讓工程師能夠為電商平台構建迭代式的分鏡腳本軟體或程式化虛擬試穿功能。
- 內嵌排版與在地化: 系統能直接在生成的圖表中呈現清晰易讀的文字。這讓開發人員能夠即時構建針對不同地區市場的自動化廣告變體。
解讀 Nano Banana 2 Lite API 定價與 Token 機制
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | 標準價格 (每 1M tokens / <= 200K 輸入 tokens) |
| 輸入 (文字、圖像、影片) | USD0.25 |
| 文字輸出 (回應與推理) | USD1.50 |
| 圖像輸出 | USD30 |
要了解您的營運成本,必須深入查看底層的 token 結構,而非僅依賴廣泛的行銷平均值。雖然業界標準推廣通常列出每 1,000 張圖像約 USD0.034 的統一費率,但 Google 的實際帳單結構依賴於精確的多模態 token 基礎設施。Nano Banana 2 Lite API 定價的具體付費層級開發人員費率分為不同的交易機制。
透過 Google AI Studio 或 Gemini Enterprise Agent Platform 使用標準付費層級時,文字、圖像或影片輸入的費用為每 100 萬 tokens USD0.25。文字輸出與結構推理 tokens 的費用為每 100 萬 tokens USD1.50。當生成標準 1K 解析度圖像(約 1 百萬像素)時,系統處理的固定輸出負載相當於每 100 萬圖像輸出 tokens USD30.00。這直接對應到每張圖像 USD0.0336 的精確成本。
此外,工程師可以透過非同步批量執行來實現巨大的預算優化。Google 為 24 小時內處理的非緊急批量請求提供 50% 的折扣。這將 1K 解析度圖像的成本降至令人驚豔的 USD0.0168,使其成為後台資產生成的首選。
架構對比:Google 創意模型系列
為了在生產環境中選擇最有效率的模型,對照 Google 創意圖像系列的效能與成本結構非常有幫助。每個模型變體針對不同的營運門檻,開發人員需根據具體的應用需求匹配適當的 API 端點。
| 指標 / 特性 | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
|---|---|---|---|
| API 模型 ID | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| 輸入 Token 價格 | USD0.25 / 1M tokens | USD0.50 / 1M tokens | USD2.00 / 1M tokens |
| 輸出圖像 Token 價格 | USD30.00 / 1M tokens | USD60.00 / 1M tokens | USD120.00 / 1M tokens |
| 標準 1K 圖像成本 | USD0.03 | USD0.07 | USD0.13 |
| 批量 1K 圖像成本 | USD0.02 | 不提供 | 不提供 |
| 平均延遲 | ~4 秒 | ~6–8 秒 | ~10–12 秒 |
| 最大缺點 | 硬性 1K 解析度上限;在處理高度複雜、密集的文字段落時較吃力。 | 缺乏針對繁重後台操作的批量定價折扣。 | 交易延遲高,輸出成本高,限制了其在超高併發迴圈中的使用。 |
| 最佳生產用途 | 高流量管線、即時應用互動、在地化橫幅廣告。 | 需要深度對話式圖像編輯的中階應用程式。 | 電影級資產創作、複雜圖形設計、極致文字精準度。 |
gemini-3.1-flash-lite-image 的 SDK 快速整合腳本
將 Google AI Studio 圖像生成整合到現有的應用程式管線中,可直接透過原生的 Google GenAI SDK 完成。下方的程式碼區塊展示了如何初始化客戶端、配置程式化參數,並安全地執行指向 gemini-3.1-flash-lite-image 端點的非同步文字轉圖像請求。
Python
plaintext1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str):""" 6 初始化 Google GenAI 客戶端,並使用具成本效益的 gemini-3.1-flash-lite-image 模型, 7 執行低延遲的文字轉圖像生成請求。 8 """# 初始化客戶端;需預先設定 GEMINI_API_KEY 環境變數 9 client = genai.Client() 10 11 print(f"正在發送模型生成請求:gemini-3.1-flash-lite-image") 12 13 try: 14 response = client.models.generate_images( 15 model='gemini-3.1-flash-lite-image', 16 prompt=prompt_text, 17 config=types.GenerateImagesConfig( 18 number_of_images=1, 19 output_mime_type="image/jpeg", 20 aspect_ratio="1:1", # 支援標準長寬比,如 1:1, 16:9, 4:3 21 person_generation="ALLOW_ADULT" 22 ) 23 ) 24 25 # 處理並儲存生成的圖像負載for i, generated_image in enumerate(response.generated_images): 26 image_bytes = generated_image.image.image_bytes 27 full_path = f"{output_path}_asset_{i}.jpg"with open(full_path, "wb") as f: 28 f.write(image_bytes) 29 print(f"已成功將 1K 圖像資產儲存至 {full_path}") 30 31 except Exception as e: 32 print(f"API 執行失敗:{str(e)}") 33 34if __name__ == "__main__": 35 prompt = "A professional product mockup of a sleek desktop companion robot on an office desk, clean lighting" 36 generate_bulk_asset(prompt, "output_production")
在大規模部署此腳本時,基礎設施會自動處理安全與合規層級。Google 預設會在每個輸出圖像的中繼資料中,嵌入無法察覺的 SynthID 水印和結構化的 C2PA 內容憑證。這確保了透過您的管線生成的所有程式化資產都能保持完全可追溯且符合企業合規性,而無需任何額外的自定義後處理腳本。
透過統一 API 層保護您的生產環境
雖然呼叫 Google 原生 SDK 在孤立環境下運作良好,但要將此文字轉圖像工作流擴展到多租戶企業級應用程式,通常需要一個統一的 API 管理層。
像 Atlas Cloud 這樣的基礎設施與協作平台,透過為此特定模型變體提供生產就緒的整合路徑,已正式將此管線去中心化。透過專屬的 Atlas Cloud Nano Banana 2 Lite 文字轉圖像/編輯模型 中心,開發人員現在可以將高頻視覺工作流直接路由至統一的 API 基礎設施中。
透過 Atlas Cloud 這樣的中心連接,您的開發團隊不僅能結合此模型 4 秒完成的快速影像處理工具與其他模型的備援選項,還能獲得單一集中的使用數據統計和簡易計費。這意味著您無需在主伺服器中添加額外繁雜的程式碼。
常見 API 錯誤代碼與速率限制疑難排解
如果您將應用程式擴展至同時處理數萬次圖像請求,肯定會遇到伺服器或客戶端限制。平穩地處理這些流量擁塞,可以防止應用程式崩潰,並確保用戶體驗始終快速流暢。
處理 429 Too Many Requests(請求過多)
在繁忙的應用程式運行過程中,最常見的錯誤是 429 Too Many Requests 訊息。這表示您的應用程式超出了授予一般 Google AI Studio 開發帳戶的共享速度限制。為了解決此問題,開發人員應在請求迴圈中加入帶有抖動 (Jitter) 的指數退避演算法,當捕獲到 429 狀態碼時,延遲後續的 API 調用。對於需要保證產能的企業級運作,工程師可以轉向 Gemini Enterprise Agent Platform 內的配置吞吐量 (PT) 方案,該方案會預留專用硬體分配,以確保在峰值負載下提供穩定的吞吐量。
解決 400 Invalid Argument 與 403 Forbidden 錯誤
400 Invalid Argument 錯誤通常代表您的影片設定中包含錯誤的尺寸或不當的長寬比。Lite 方案非常嚴格,僅允許 1K 影片輸出。請確保您的長寬比符合標準尺寸(例如 1:1 或 16:9)。
相對地,403 Forbidden 錯誤則表示 API 金鑰問題或安全阻擋。Google 使用自動過濾器檢查所有文字。如果您的提示詞違反這些安全規則,系統將阻止圖像生成。您將需要重寫文字以符合平台規範。
開發者現實:原生整合預算型圖像工作流
部署一款針對預算進行優化的模型,意味著必須承認其現實侷限性。由於該模型的架構旨在實現極致的速度與低成本,它必然存在明確的取捨:
- 硬性的 1K 解析度上限意味著它無法產生原生 4K 可直接印刷的圖形。
- **此外,**當任務涉及包含密集結構層的高度複雜提示詞時,模型在跨越截然不同的場景轉換時,偶爾會出現角色一致性不穩定的情況。
為了在不增加營運成本的情況下減輕這些缺點,您可以將生成管線串聯成多輪編輯工作流。
與其嘗試在第一次就生成完美、極其複雜的場景,不如將應用程式邏輯設計為先生成一個 4 秒的快速基礎草圖。隨後,再使用對話式圖像編輯請求,以程式化方式修改、重置光影或替換資產中的特定物件。
對於進階多媒體應用,此 1K 圖像輸出可以直接饋入影片生成管線,例如 Gemini Omni Flash,該工具以每秒 USD0.10 的實惠費率處理影片編輯任務。
Nano Banana 2 Lite 適合您的技術堆疊嗎?
為了簡化您的架構評估,以下分析了哪些開發團隊能從 Nano Banana 2 Lite (gemini-3.1-flash-lite-image) 獲得最高的投資報酬率,以及誰應該考慮標準高階層級。
此模型適合誰?
- 高併發應用程式開發者: 如果您的軟體每分鐘處理數千次自動化 API 請求(例如即時用戶頭像生成器、即時動態廣告產生器或大量電子商務產品展示系統),此模型正是為您的負載需求而建。
- 對成本敏感的軟體工程師: 針對微型預算工作流,且將營運支出維持在低水平作為首要生存指標的團隊。利用其 USD0.0168 的批量層級,能有效消除標準的高溢價財政瓶頸。
- 互動式應用架構師: 需要嚴格同步迴圈、且用戶要求近乎即時反饋的產品,將能從其低於 4 秒的生成速度中獲益匪淺。
誰應該避免使用此模型?
- 高保真平面設計師: 如果您的應用程式依賴渲染大規模印刷圖形、原生 4K 解析度橫幅或複雜的電影級行銷素材,硬性的 1K 解析度上限將限制您的創作產出。
- 文字密集的視覺行銷人員: 雖然該模型支援內嵌排版,但對於需要將複雜的佈局文字原生內嵌在圖像中的應用,建議使用 Gemini 3 Pro Image 層級,以保持絕對的文字精準度。
- 音訊中心化多媒體開發者: 對於嚴重依賴音訊同步或直接從連續即時音訊串流生成圖像的進階多模態迴圈,此模型並不支援音訊,因此不建議使用。
常見問題 (FAQ)
與標準層級相比,gemini-3.1-flash-lite-image 如何降低開發者成本?
該模型相較於標準的 gemini-3.1-flash-image 模型,直接降低了 50% 的開發者標準成本。透過將 token 足跡優化至每 100 萬輸入 tokens USD0.25 與每 100 萬輸出 tokens USD30.00,在標準付費層級下,標準 1K 解析度圖像的價格降至 USD0.0336。對於非緊急的後台任務,利用批量 API 可將此費率降至每張圖像 USD0.0168。
Nano Banana 2 Lite 能處理高併發的企業級應用負載嗎?
可以,該模型專為處理高併發的企業需求而建。雖然標準開發層級共享公共基礎設施池,但企業團隊可以透過 Gemini Enterprise Agent Platform 部署配置吞吐量 (Provisioned Throughput) 來確保專屬、高度可靠的效能。這完全避開了標準的共享速率限制,並在尖峰流量時段確保穩定的 4 秒生成速度。
最便宜的 Google 圖像 API 是否在安全性或內容追蹤上做出妥協?
成本優化並不代表刪減企業級安全功能或合規機制。由該模型生成的每張圖像都會自動包含嵌入在像素陣列中的原生 SynthID 水印,以及標準的 C2PA 內容憑證。這些中繼資料允許企業平台在將 AI 生成資產應用於公開場景前,維持透明追蹤並全面驗證其真實性。






