
死板的 ID3 流派標籤正在毀掉你的本地音樂收藏。透過將 AudioMuse-AI 的先進音訊分析能力與 AtlasCloud 的可擴展 API 相結合,你可以將一堆靜態的媒體檔案目錄轉化為一個極具直覺的語義發現引擎,並能將由情緒驅動的播放清單無縫匯入到你的自託管伺服器中。
![]()
重拾音樂的溫度:利用 AudioMuse-AI 建構真正直覺的本地庫
深夜,你坐在書桌前。你既不想聽節奏激昂的電子音樂播放清單,也沒心情聽那種刻板的古典音樂。你真正想要的是一種極具特定氛圍的音樂:「安靜、氛圍感強的獨立民謠,帶點細雨濛濛的木吉他底色,幫我放鬆下來。」
如果你打開自託管的 Navidrome 或 Jellyfin 實例,並在搜尋欄中輸入這句話,你將得到零結果。
幾十年來,我們這些數位音樂收藏者花費了無數時間整理 ID3 標籤、清理專輯封面,並強行將靈動的藝術形式塞進「搖滾」、「爵士」或「流行」這種僵硬的流派分類中。但老實說:流派標籤不過是 20 世紀唱片店行銷的產物。它們根本無法理解音樂聽起來到底是什麼「感覺」。
管理個人音樂庫的未來不屬於靜態元數據,而屬於語義音訊分析。大語言模型 (LLM) 遠不止是聊天介面;它們是解讀你音樂中難以量化的情感重量的終極鑰匙。透過部署開源的 AudioMuse-AI 以及像 AtlasCloud 這樣智慧的 LLM 路由,你可以讓本地檔案重煥生機,並基於純粹的氛圍、聲音質感和歌詞含義來生成播放清單。
什麼是 AudioMuse-AI?
AudioMuse-AI 是一個自託管、開源的音訊智慧引擎,旨在與你現有的媒體環境無縫協作。它充當一個由 AI 驅動的「大腦」,直接接入 Jellyfin、Navidrome、LMS/Lyrion 和 Emby 等流行的自託管音樂平台。
AudioMuse-AI 不解析文字標籤,而是處理原始音訊檔案。它執行本地化的神經網路模型來提取複雜的數學聲學向量(使用 CLAP,即對比語言-音訊預訓練),並映射 72 種支援語言的歌詞主題。
一旦初始掃描完成,你將解鎖讓商業串流演算法顯得膚淺的功能:
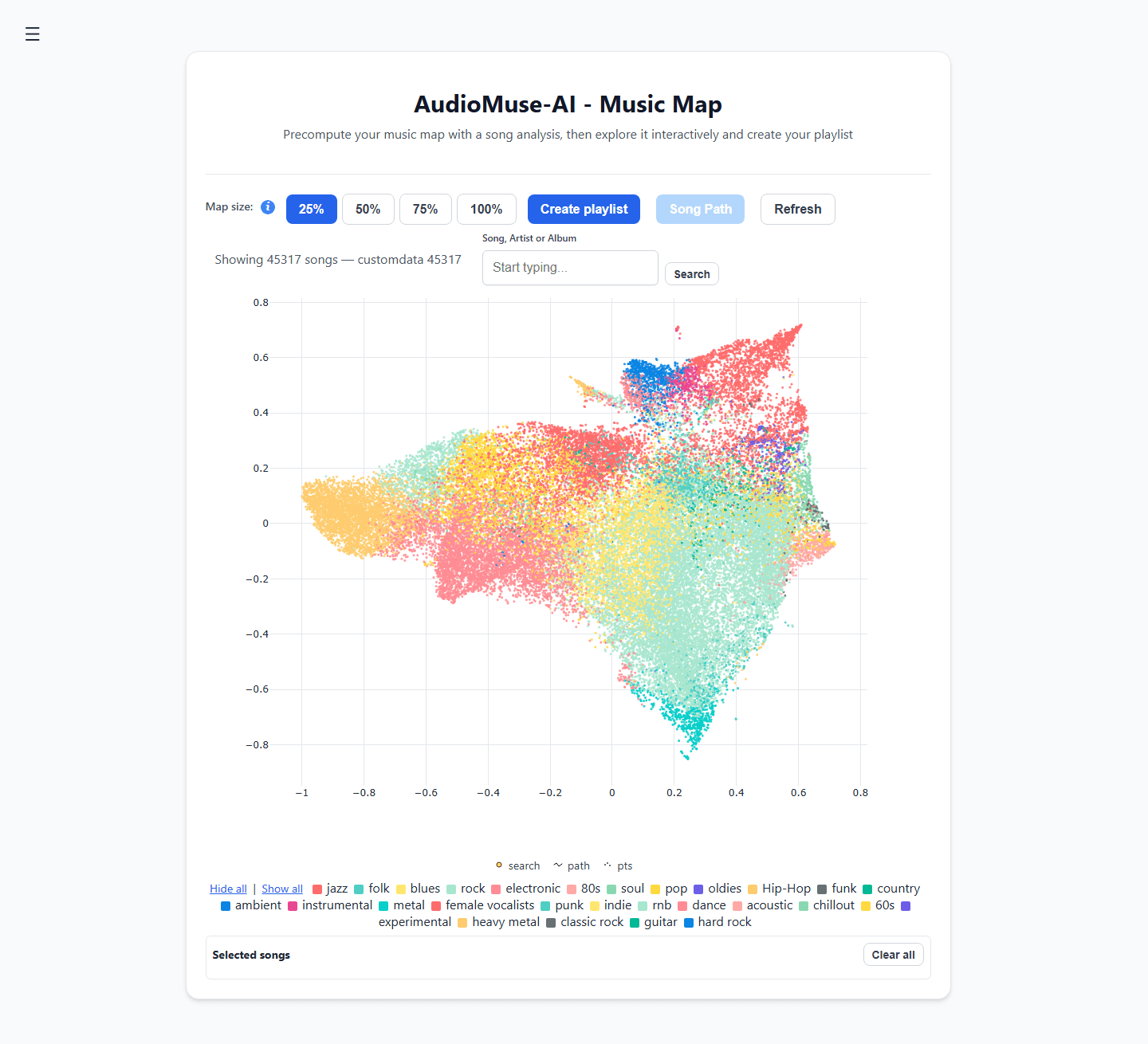
- 聲學聚類: 自動將你的音樂庫繪製成一張可視化的 2D 互動「音樂地圖」,根據音軌的原始聲波而非隨意的流派進行分組。
- 歌曲路徑: 選擇一首歡快的放克樂曲作為起點,將一段憂鬱的氛圍樂曲作為終點。引擎會自動計算兩者之間的聲學橋樑,生成一個情緒轉換平滑且完美的播放清單。
- 語義歌詞搜尋: 按敘事主題或情感概念搜尋你的音樂庫(例如:「關於在小鎮長大」的歌曲),而不僅僅是查找精確的歌詞匹配。
分步指南:建構你的語義音樂發現引擎
讓我們來一步步搭建一個完全無需元數據的語義播放清單工作流。
第一步:環境準備與部署
AudioMuse-AI 可以在 macOS、Linux 和 Windows 上原生執行,但對於標準的家用伺服器或 NAS 設定,Docker Compose 是最簡潔的方案。
在伺服器上建立一個目錄,從部署文件中取得官方的 docker-compose.yaml,並確保你的環境檔案已配置好。
YAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ 硬體注意: 底層 AI 模型非常依賴現代 CPU 指令集。如果你在 Proxmox 等虛擬化環境中執行此程式,請確保將 CPU 類型設定為 "Host",以透傳 AVX2 支援。如果你在普通的 QEMU 虛擬 CPU 上執行,容器將在啟動時立即崩潰。
透過以下指令啟動:
Bash
plaintext1docker compose up -d
第二步:執行音訊框架掃描
打開瀏覽器並訪問 http://YOUR-SERVER-IP:8000。你將看到初始化設定精靈。連接你的媒體伺服器(例如,輸入你的 Navidrome URL 和個人 API 令牌)。
連接成功後,前往 Analysis and Clustering(分析與聚類)儀表板並點擊 "Start Analysis"(開始分析)。
引擎將開始計算聲學指紋。根據你的庫大小,以及你是在英特爾 i5 迷你 PC 還是樹莓派 5 上執行,此初始解析階段可能需要幾分鐘到幾小時不等,具體取決於處理原始波形的速度。
第三步:透過 AtlasCloud 為 AI 大腦提供動力
這裡是我們遇到自託管技術瓶頸的地方。AudioMuse-AI 具有一個互動式播放清單聊天介面 (app_chat.py) 和一個深度歌詞嵌入引擎。在本地執行龐大、複雜的語言模型來處理這些語義查詢,很容易使 NAS CPU 佔用率飆升至 100%,從而導致令人痛苦的 API 超時和播放清單生成延遲。
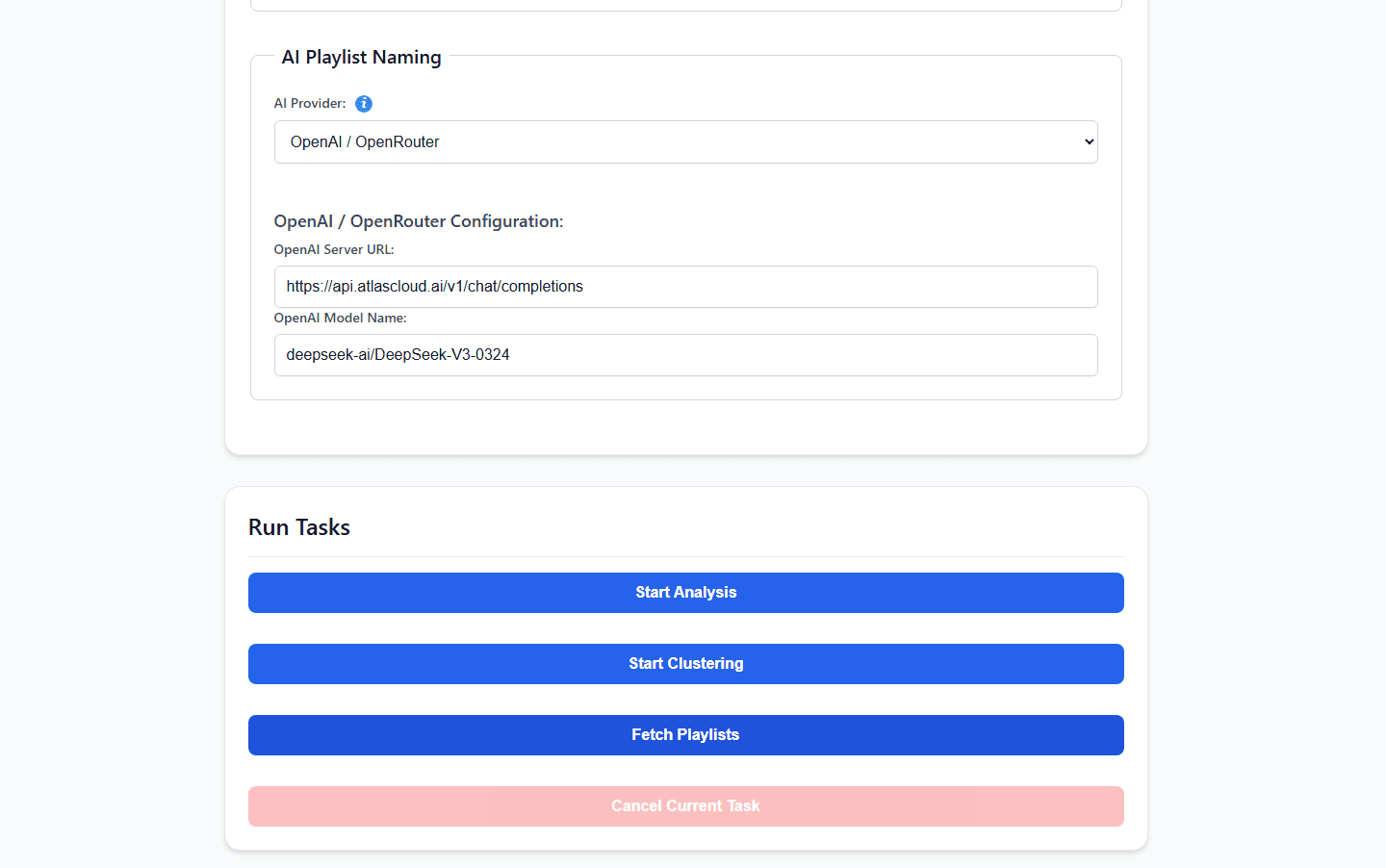
為了保持本地硬體輕量、冷靜且安靜,我們可以將沈重的語義推理卸載到外部 API。正如專案 OpenAI 相容 AI 提供商指南 中正式記錄的那樣,你可以透過使用原生的 OPENAI 核心提供者,將請求無縫路由到 AtlasCloud。
只需將這些變數新增到伺服器的部署環境設定中:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
透過利用 AtlasCloud,你無需在本地硬碟上管理龐大的多 GB 模型。只需一個 API 令牌,AudioMuse-AI 即可即時存取高效能推理模型,從而即時分析你的自然語言提示,且處理延遲極低。
第四步:生成你的第一個氛圍播放清單
在 AtlasCloud 處理語義映射的情況下,導航到 Instant Playlists(即時播放清單)選項卡。讓我們測試一下該系統跨越傳統界限的能力。輸入一個高度抽象的提示:
「給我一種深夜雨天駕駛的氛圍。開始時要原聲、緩慢,但在最後過渡到具有律動感電子脈衝的曲目。」
AtlasCloud 處理你提示中的核心情感意圖,將結構藍圖傳回 AudioMuse-AI 的本地向量索引,並立即返回精選的播放清單。點擊 "Export to Media Server",自訂播放清單就會透過 Jellyfin 或 Navidrome 即時推送到你手機上的音樂 App 中。
對比
| 功能 | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
|---|---|---|---|
| 隱私與控制 | 完全所有權。數據保持本地;LLM 查詢透過安全代理。 | 半私有。需要專有帳戶和活躍的 Plex Pass。 | 零隱私。你的收聽日誌會被貨幣化以用於廣告追蹤。 |
| 元數據依賴 | 無。直接分析原始音訊波形和歌詞主題。 | 高。分析開始前嚴重依賴準確的基礎標籤。 | 絕對依賴。完全依賴商業唱片公司的標籤和資料庫 ID。 |
| 冷啟動效能 | 完美。可以即時分析並映射冷門的本地獨立音樂。 | 較差。如果音樂未在 Plex 資料庫中匹配,則無法進行情境關聯。 | 糟糕。如果歌曲缺乏全球串流播放量,演算法會忽略它。 |
| 語義搜尋 | 高級。透過 LLM 理解複雜的自然語言提示。 | 不存在。僅限於基本過濾器(年份、流派、心情標籤)。 | 一般。文字解析能力尚可,但僅限於其目錄內的內容。 |
技術注意事項與生產故障排除
- VNNI 歌詞重分析 Bug: 如果你最近將容器堆疊更新到了最新的 AudioMuse-AI 版本,請務必注意你的 CPU 架構。較舊的 GTE 多語言嵌入模型在缺乏 VNNI 指令集(2019 年以前的硬體)的舊 CPU 上可能會產生退化的向量映射。如果你在 Linux 主機上執行 得到空結果,你應該使用 PostgreSQL CLI 刪除舊的資料庫表,並重新觸發歌詞掃描,以獲取乾淨、準確的語義搜尋結果。text
1grep -oE 'avx512_vnni|avx_vnni' /proc/cpuinfo - 媒體伺服器超時調整: 當同步包含 500 首以上曲目的龐大播放清單回 Navidrome 時,初始同步握手可能會超過預設的代理限制。如果你的日誌中出現連線握手斷開,請查閱官方參數指南來調整伺服器的超時旗標。
常見問題解答
為什麼在設定過程中我的 Jellyfin 連線測試失敗?
這通常是由不正確的 Base URL 格式或無效的 API 令牌範圍引起的。確保你使用的是包含埠的完整 HTTP/HTTPS 位址(例如 http://192.168.1.50:8096),並驗證 Jellyfin 儀表板內生成的 API 令牌是否具有播放清單的完整管理員讀寫權限。
我可以在沒有 AVX2 指令集的舊伺服器上執行 AudioMuse-AI 嗎?
可以,但你不能使用標準的 Docker 映像檔。你需要顯式拉取帶有 -noavx2 後綴的專用 Docker 映像檔(例如 neptunehub/audiomuse-ai:latest-noavx2)。這些建構版本將效能優化的線性代數後端替換為更相容的舊庫。請注意,在此備援方案下,原始音訊掃描速度會明顯變慢。
AtlasCloud API 如何提高 app_chat.py 的回應速度?
當你與對話式播放清單精靈互動時,系統必須將你的對話反饋轉換為結構化的 JSON 模式。在本地伺服器 CPU 上處理此文字每條訊息可能需要 10 到 30 秒。透過像 AtlasCloud 這樣優化的雲端合作夥伴路由這些特定請求,可以在幾毫秒內返回答案,確保你的本地伺服器記憶體保持空閒,以便在不卡頓的情況下串流傳輸高碼率 FLAC 檔案。






