Claude Code 每天每位開發者約需消耗 USD13 的成本,若包含高強度的自動化需求,每位工程師每月的費用甚至可能飆升至 USD500 到 USD2,000 (CloudZero, 2026)。對於一支 50 人的團隊來說,這意味著一筆憑空出現的五位數開支。如果您的 AI 編碼費用在上季度突然暴增且原因不明,您並不孤單,且解決方案通常不是「減少使用 AI」。
真正的問題在於,代理式 (Agentic) 編碼工具消耗 Token 的方式與聊天視窗截然不同,大多數團隊正以全價支付本可以用幾分之一成本取得的 Token。本指南將說明七項具體的策略來降低 AI 編碼的 Token 成本,並提供每項策略背後的數據與具體的配置變更建議。
重點摘要
- 代理式編碼工具消耗的 Token 量是聊天的 10 到 100 倍,因為每次執行工具呼叫時,系統都會重新傳送完整的上下文 (LeanOps, 2026)。
- Prompt Caching (提示詞快取) 是槓桿效應最高的調整:快取讀取成本僅約為標準輸入 Token 的 10%,有團隊僅憑此項調整就將總 LLM 開支降低了 59%。
- 將日常編碼切換至 GLM、Kimi 和 DeepSeek 等開放權重模型,相較於頂尖模型可降低 80% 以上的單一 Token 成本,且品質差距遠小於多數人的預期。
- 將所有工具透過統一閘道 (Gateway) 進行路由,能確保單一預算、單一 API 金鑰,並提供一致的定價,而不必在五家供應商間支付零售價格。
為何 AI 編碼的 Token 成本會失控
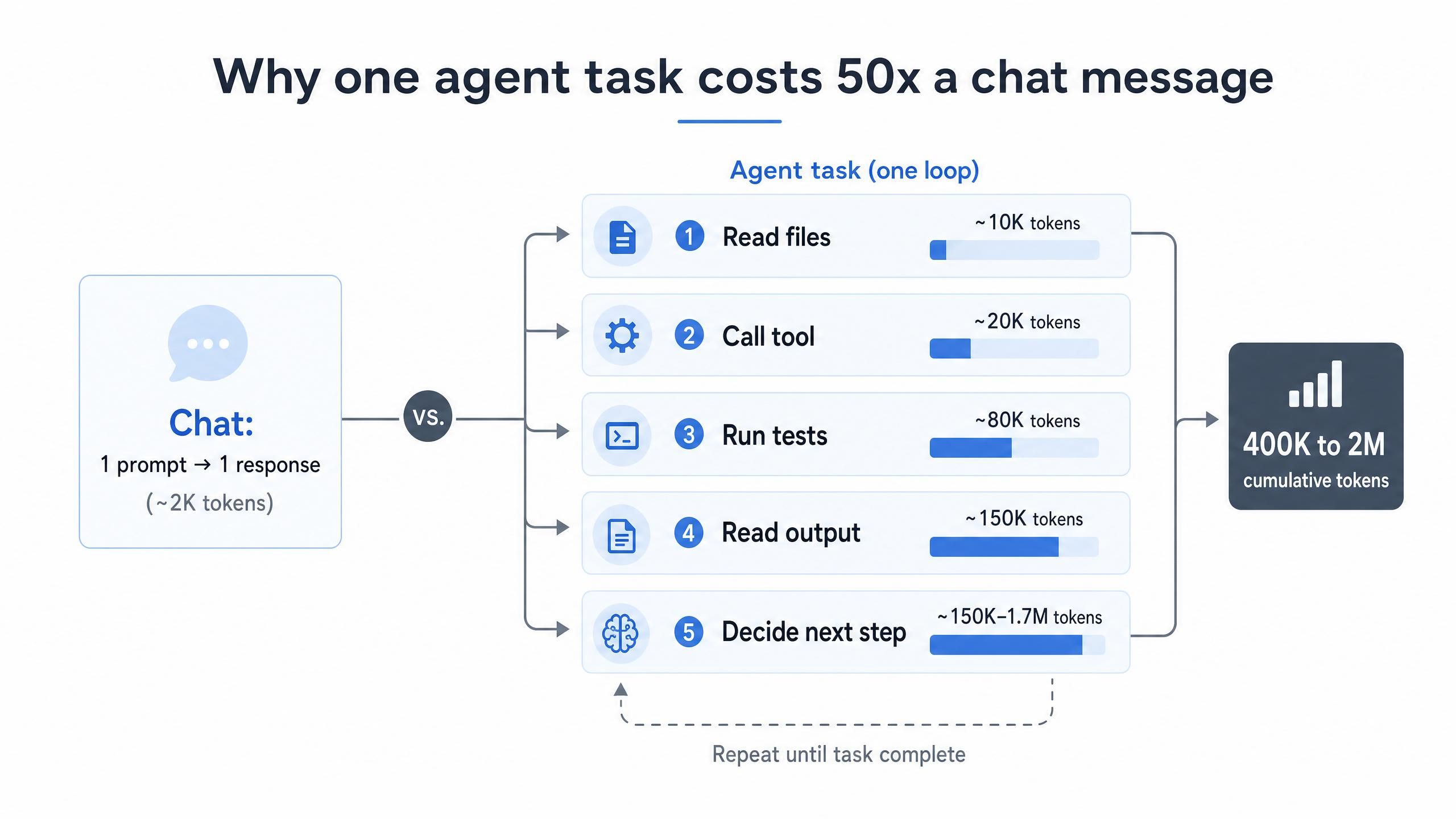
AI 編碼成本高昂的核心原因在於架構,而非使用行為。聊天互動是發送提示詞並獲得一個答案,但 AI Agent 的運作大不相同:它會讀取檔案、呼叫工具、執行測試、讀取輸出,並決定下一步動作。這些推理步驟中的每一個都會重複發送已累積的上下文,因此 Token 使用量會隨著每次循環呈指數級增長。正是基於這個原因,AI Agent 消耗 Token 的速度是聊天機器人的 10 到 100 倍 (LeanOps, 2026)。
數據成長極快。單一項非簡單的 Agent 任務,隨著上下文視窗被填滿與重新整理,透過 API 傳輸的累積輸入 Token 可能高達 40 萬到 200 萬個 (Morph, 2026)。若乘以團隊每日數十項任務,每月的發票金額就不再只是小數目。
這對大型企業而言絕非虛構的問題。根據《The Next Web》報導,微軟內部大舉撤回 Claude Code 授權的部分原因就是成本考量,每位工程師的帳單一度攀升至 USD500 到 USD2,000 (The Next Web, 2026)。當全球資源最雄厚的工程團隊之一都對此帳單感到頭痛時,在試圖削減成本之前,先了解 Token 的去向至關重要。
如何在不拖慢開發速度的情況下降低 AI 編碼成本
好消息是,這些策略幾乎都不需要減少程式碼撰寫量,也不需要人工監控 Agent。它們的運作邏輯在於消除浪費、重新定價相同的工作,並為每一項任務配對最便宜且能勝任的模型。以下是成效最顯著的七項策略,大致按投入心力與回報比排序。
策略 1:使用 Prompt Caching (提示詞快取) 來降低成本
提示詞快取是您能做出的槓桿效應最大的調整。當 Agent 在每一步驟重新發送相同的系統提示詞、工具定義和檔案上下文時,快取功能可讓模型從快取中讀取重複內容,而非重新處理。快取讀取價格約為標準輸入費率的 0.10 倍,即重複請求部分可獲得 90% 的折扣 (Finout, 2026)。
需注意:快取寫入的成本略高於一般輸入 Token,在五分鐘窗口內約為標準費率的 1.25 倍。因此,當上下文在存活時間 (TTL) 內被重複使用時,快取效益最高,這正好符合 Agent 的運作模式。其實際影響並非理論。ProjectDiscovery 團隊記錄到,在導入提示詞快取後,其整體 LLM 成本降低了 59% (ProjectDiscovery, 2026)。
如果您使用 Claude Code 或相容的 Agent,請確認已啟用快取,並將系統提示詞與大型檔案上下文放入可快取的區塊中。這項單一調整通常能帶來發票金額上最大幅度的降幅。
策略 2:根據任務配對模型以降低成本
大多數團隊將所有請求都路由至能力最強的模型,這就像開著大卡車去買雜貨一樣。更聰明的作法是:將昂貴的頂尖模型保留給真正需要它的工作,其餘則交給較便宜的模型。
一個實際的分流範例如下:
- 推理、架構、複雜除錯: 使用頂級模型,品質足以證明其價格。
- 日常程式碼生成與編輯: 使用強大的中階開放模型。
- 高流量後台作業、分類、模板程式碼: 使用最便宜但能勝任的模型。
節省效果極為顯著,因為價格差距巨大。在低價端,DeepSeek V4 Flash 每百萬輸入 Token 約為 USD0.14,而頂尖模型成本則高出數倍 (Codersera, 2026)。將 80% 的 Token 用量分配給較便宜的模型,同時將頂尖模型保留給剩下的 20% 關鍵需求,可以在不犧牲輸出品質的情況下,將總開支降低一半以上。
策略 3:保持上下文視窗輕量化
由於上下文中的每個 Token 都會在 Agent 的每一步驟中被重新傳送,臃腫的上下文視窗是您需要反覆支付的隱形稅。兩個習慣很有幫助:第一,嚴格界定每項任務的範圍,讓 Agent 只載入所需的檔案,而非整個儲存庫;第二,在切換任務時開啟新的會話,避免讓單一對話累積數十萬個陳舊的 Token。
一個有用的心智模型是:如果您不會為了回答問題而將某個檔案貼進聊天視窗,就不要讓它留在 Agent 的上下文中。將上下文視窗從 20 萬 Token 縮減至 4 萬 Token,節省的不僅僅是一次費用,而是該任務後續每次工具呼叫的開支,這是累加效應對您有利的轉變。
策略 4:切換至開放權重模型以降低成本
這是標題降幅最顯著,且往往帶有最多過時觀念的策略。2026 年推出的開放權重編碼模型已經非常優秀。在 SWE-Bench Pro 測試中,領先的頂尖模型得分約為 91,而 Kimi K2.6 為 76.8,DeepSeek V4 Pro 則接近 77 (Codersera, 2026)。雖然在最困難的基準測試中存在差距,但對於常規功能開發、重構和測試撰寫,差異遠小於價格差距。
價格差距才是關鍵所在。GLM、MiniMax、Kimi 和 DeepSeek 等開放權重模型,每個 Token 的成本僅為頂尖模型的一小部分。對於日常大部分的編碼工作,開放模型完全能夠勝任,且成本極低。過去的障礙在於門檻:必須處理不同的帳戶、金鑰,以及各供應商間不一致的定價。
這正是統一編碼閘道能改變計算方式的地方。像 Atlas Cloud 這類的平台,將主要的開放權重模型整合在單一 API 與信用額度平衡中,因此您可以今天將 Claude Code、Codex 或 OpenClaw 指向 GLM-5.1,明天改為 Kimi K2.6,而無需更動任何架構。Atlas Cloud 公布的每模型信用倍率,換算下來約比模型官方 API 定價節省 45% 到 55%,且該公司的信用費率在相同模型下甚至低於 OpenRouter。
以下是其信用倍率在熱門編碼模型中的轉換方式:
| 模型 | 上下文 | 輸入倍率 | 輸出倍率 | 相較官方約省 |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
來源:Atlas Cloud 編碼方案信用規則。信用成本 = 輸入 Token × 輸入倍率 + 輸出 Token × 輸出倍率。
策略 5:批次處理後台工作
並非所有 Token 都需要以互動式、即時定價來支付。夜間評估、大型分類作業、文件生成任務及批次重構,並不需要人類等待結果,這代表它們可以在較便宜的批次通道或最低成本的模型上執行。將這些非緊急的流量從昂貴的互動式模型中移出,等於是「撿到的錢」,因為這些工作您原本就是以全價支付,且使用高價模型對品質並無幫助。
原則很簡單:區分「我需要即時等待的」Token 與「可以隔夜完成的」Token,並採不同定價。對於多數團隊而言,總 Token 用量中驚人的一大部分其實都屬於後者。
策略 6:透過單一編碼閘道路由所有工具
工具分散會悄悄膨脹 AI 編碼成本。典型的開發者可能會在終端機使用 Claude Code、處理某些任務時用 Codex、編輯器用 Cursor,旁邊還有幾個 Agent,每個都有自己的訂閱、金鑰和不透明的帳單。您會失去查看總支出的能力,並在每個地方都支付零售價格。
整合至單一 OpenAI 相容端點可解決這兩個問題。由於 Atlas Cloud 提供一個基礎 URL 和一個橫跨 Codex、Claude Code、OpenClaw、OpenCode、Cursor 及直接 API 呼叫的信用池,您將獲得一張帳單、一個預算和一個更換模型的單一位置。其方案從每月的 USD10 入門級到適合重度團隊的高階方案不等,且隨用隨付包享有 41% 折扣,讓您可以根據實際使用量而非猜測來設定承諾。
將 Claude Code 指向該閘道只需修改一個設定檔。在 macOS 或 Linux 上,編輯
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
對於 Codex 使用者,對應的設定檔在
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.json策略 7:設定預算並監控成本
您無法減少看不見的東西。那些被巨額帳單突襲的團隊,幾乎都有一個共同點:沒有支出控制,且缺乏每位開發者的可視性。解決方法是在月初前設定消費上限,而非在收到帳單後才處理。
基於信用額度的方案並搭配每日限額可以從架構上解決此問題。與其使用無上限的計量方式,每月訂閱會在午夜刷新固定的信用額度,這能限制失控的 Agent 迴圈帶來的損害,而隨用隨付包則可吸收每日額度用盡後的零星尖峰。當需要擴展時,按比例升級代表您只需支付差價。例如,Atlas Cloud 的升級流程會將剩餘價值抵扣至新方案,因此週期中途變更可能只需幾美元,而非購買全新的計畫。
真實成本比較:跨模型的 AI 編碼 Token 成本
為了讓節省金額具體化,假設開發者在忙碌的一天中透過 Agent 傳輸了約 150 萬個輸入 Token 和 30 萬個輸出 Token(考慮到單一任務可能達到百萬級別的累積輸入,這是一個現實的數字)。若使用每百萬輸入約 USD5、每百萬輸出約 USD25 的頂尖模型,成本約為 USD7.50 輸入加 USD7.50 輸出,即每天約 USD15,這與廣泛引用的每日 USD13 成本數字相符 (CloudZero, 2026)。
若透過折扣閘道將相同的用量運行在 GLM 或 Kimi 等開放權重模型上,僅輸入部分就能降低 70% 以上,輸出部分也跟隨大幅下降。若再加上提示詞快取,主導 Agent 工作負載的重複上下文將以十分之一的費率計費。將這三種策略疊加(快取 + 便宜模型 + 精簡上下文),一個 USD15 的開發日成本有望在不改變任何人寫程式習慣的情況下,降至 USD3 到 USD5。

確切數字會依據您的工作負載而有所不同,但整體態勢不變:AI 編碼 Token 成本的大頭在於重複的上下文運行在過度昂貴的模型上,而這兩點都是可以修復的。
總結:保持低 AI 編碼成本的配置方案
如果您想從最少瑣事且獲得大部分節省的初始配置開始,建議如下:使用 GLM-5.1 或 Kimi K2.6 等開放權重模型作為預設編碼模型,保留一個頂尖模型以應付困難推理,隨處啟用提示詞快取,嚴格縮小任務範圍以保持上下文輕量,並透過具備每日預算限制的單一 OpenAI 相容端點來路由所有工具。
該組合同時解決了每個成本驅動因素:它重新定價了 Token,不再為重複的上下文付費,並限制了下行風險。希望將這些整合在一個金鑰和一個預算下的團隊,可以透過 Atlas Cloud 編碼方案控制台 進行設定,該平台開箱即支援主要的開放權重模型與常見的編碼工具。設定只需幾分鐘,但每天都能產生持續性的節省。
關於 AI 編碼 Token 成本的常見問題
為什麼我的 AI 編碼 Token 成本遠高於聊天使用量?
因為 Agent 在每個推理步驟都會重新發送完整的累積上下文,而聊天則是每次提示詞只發送一次。這種架構差異意味著 Agent 對於相同工作消耗的 Token 是聊天的 10 到 100 倍 (LeanOps, 2026),因此幾十個 Agent 任務可能遠超一個月的休閒聊天使用量。
降低 AI 編碼成本最快的方法是什麼?
啟用提示詞快取。一旦啟用,Agent 工作負載中的重複上下文僅以標準輸入費率的約 10% 計費 (Finout, 2026)。至少有一支工程團隊回報,單憑快取就讓總 LLM 成本下降了 59%。它不需要改變您的工作方式,因此是回報率最高且成本最低的調整。
便宜的開放權重模型足以應付真實的編碼工作嗎?
對大多數日常任務而言,是的。在最困難的 SWE-Bench Pro 基準測試中,頂尖開放模型得分在 70 分尾段,而頂尖模型約為 91 分 (Codersera, 2026),但日常的功能開發、重構與測試很少會觸及到這個差距。保留一個頂尖模型備用以處理真正困難的推理,其餘則交給開放模型即可。
我在 AI 編碼成本上能節省多少?
疊加提示詞快取、較便宜的預設模型以及精簡的上下文,通常能將開發者每日成本從約 USD15 降至 USD3 到 USD5 的範圍(根據公布的每 Token 費率)。這種節省會在團隊中累積,這就是為什麼每月五位數的帳單通常只要調整兩位數百分比就能變得合理。
我需要更換工具才能降低成本嗎?
不需要。大多數節省來自於 Token 的定價與重複使用方式,而非您使用的用戶端。將現有的 Claude Code、Codex 或 OpenClaw 指向折扣後的 OpenAI 相容端點只是配置變更,而非遷移,因此您的工作流程保持不變,但帳單金額會下降。
結論
在了解機制前,AI 編碼的 Token 成本感覺很神祕:Agent 不斷發送相同的上下文,而大多數團隊卻為此支付著頂尖模型的價格。透過提示詞快取、更智慧的模型路由、精簡上下文以及單一折扣閘道來修復這兩個問題,即便不改變任何一行程式碼的撰寫方式,成本也能降低一半以上。本週先從快取開始,審視哪些任務真正需要昂貴的模型,並將您的工具整合到單一預算下。設定只需一個下午,節省則是永久的。






