
超越 n8n:為何 Rust 是實現「零崩潰」AI 工作流的唯一答案
現在是凌晨 2:00,你生產環境 n8n 中的一個非同步 JavaScript 節點發生了隱式型別轉換錯誤。第三方 Webhook 將一個整數變成了字串。由於 Node.js 是在執行階段動態評估代碼,工作流在半途斷開。執行隨之中止,數據處理到一半,而你的團隊只能手忙腳亂地修復損毀的狀態機。
對於構建關鍵任務自動化和多代理(Multi-agent)管線的開發者來說,執行階段的脆弱性就像一顆定時炸彈。解決方案是徹底拋棄這種弱型別、重解釋的編排範式。
這就是 flow-like,一個由 Rust 從零打造、企業級的開源工作流自動化引擎。透過將 Node.js 的動態鬆散性替換為嚴格的編譯期強型別生態系統,flow-like 重寫了生產管線的規則。它將不可預測的多代理行為轉化為可靠、確定性的任務,無論是在單機終端還是 Kubernetes 集群上,都不會出現任何執行階段的意外。
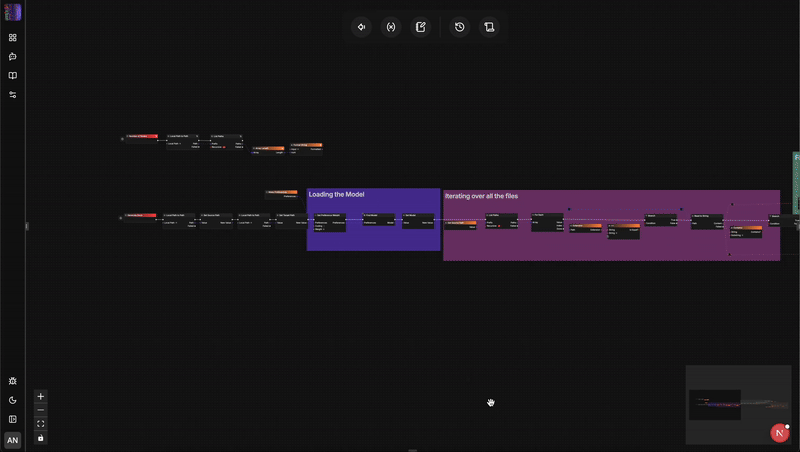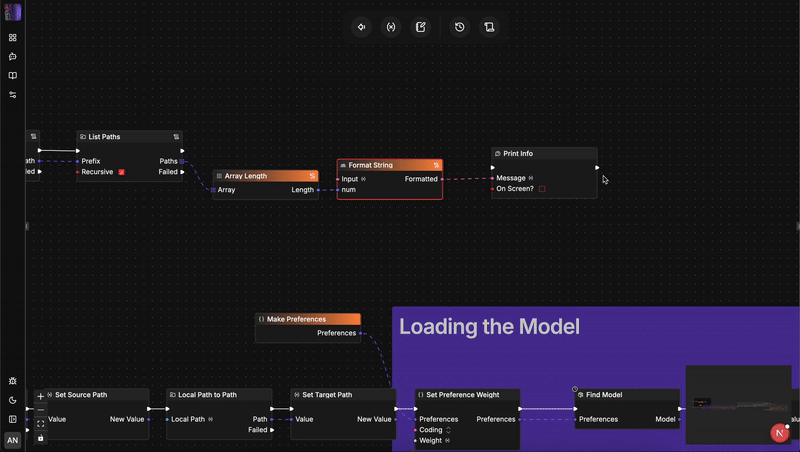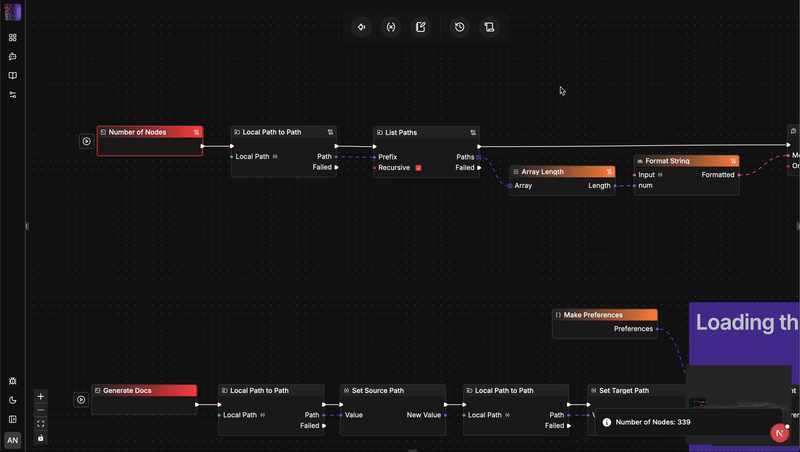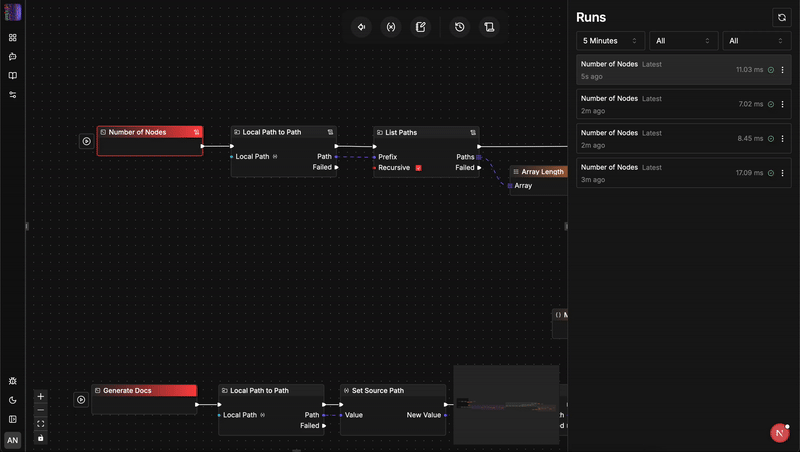
架構大比拚:flow-like vs. n8n
要理解為什麼語言轉換至關重要,我們需要深入觀察這兩個引擎如何管理狀態、安全性和擴展性。
型別安全 vs. 無型別混沌
n8n 最明顯的問題在於它完全依賴在 Node.js 模組之間盲目傳遞的鬆散 JSON 負載。如果一個節點輸出了另一個節點期望的扁平物件之外的巢狀字典,引擎只有在真實生產流量經過時才會發現這種差異。
相反,flow-like 在所有數據邊界都採用了嚴格的 「強型別合約(Strong-Type Contract)」 模型。變數使用核心建構(如 VariableType::String、VariableType::Execution 或自定義結構體)進行顯式宣告。如果輸出負載不符合消費者接腳(Consumer pin)所期望的架構合約,管線引擎會及早捕捉到錯誤。執行管線會在處理損壞或意外負載之前觸發確定性的驗證區塊。
無需垃圾回收(GC)的高效能併發
Node.js 依賴單執行緒事件迴圈來處理併發 I/O。當 n8n 容器解析大型檔案或處理高頻率 Webhook 時,V8 JavaScript 引擎會因垃圾回收(GC)暫停而產生嚴重的記憶體負擔和突然的延遲尖峰。
flow-like 利用了 Rust 的零成本抽象和手動記憶體管理。透過非同步特徵(async traits)和像 blake3 這種低開銷雜湊工具,flow-like 能輕鬆擴展至驚人的 每秒 244,000 個工作流。它處理數據陣列和複雜巢狀迴圈時,每個節點的內部執行速度平均僅需 ~0.6ms,且記憶體佔用量僅為 Node.js 執行階段的一小部分。
實戰:3 分鐘構建零洩漏、多模態 AI 處理管線
讓我們看看如何輕鬆設置並執行一個即時、型別安全的多代理工作流,透過本地參數處理輸入數據,並呼叫先進的雲端模型進行處理。
第 1 步:本地環境設置與編譯
由於 flow-like 是純原生應用,且沒有外部執行階段依賴,編譯過程非常簡單。使用 Cargo 複製專案並驗證工作區構建結構:
Bash
plaintext1git clone https://github.com/Rheosoph/flow-like.git 2cd flow-like 3cargo build --release
編譯過程會將所有內容(包括底層的 WASM 沙盒執行階段和型別定義)封裝成單一可執行二進位檔。
第 2 步:透過 Atlas Cloud 連接雲端大腦
雖然 flow-like 在本地消費級硬體上執行速度飛快,但處理非結構化數據或生成精確的 JSON 架構需要先進的推理能力。flow-like 不需要編寫自定義 API 代碼或載入數千行模型特定的封裝庫,其標準目錄中內建了原生的 BuildAtlasCloudNode 節點。
底層佈局註冊表將系統配置為對接該平台:
Rust
plaintext1let mut node = Node::new( 2 "ai_generative_build_atlascloud", 3 "Atlas Cloud Model", 4 "Builds a model served by Atlas Cloud, a full-modal AI inference platform exposing a single OpenAI-compatible API...", 5 "AI/Generative/Provider" 6);
💡 開發者註記: 這種方法消除了傳統 API 金鑰管理的繁瑣。我在該節點內使用 Atlas Cloud 提供的一個 API Token,即可動態啟動或切換深層推理模型,如 DeepSeek-V4-Pro、Qwen 或 GLM,而無需為每個模型手動註冊帳戶或初始化獨立的客戶端包。
以下是映射連接屬性的範例設置:
JSON
plaintext1{ 2 "node_id": "ai_generative_build_atlascloud", 3 "inputs": { 4 "endpoint": "https://api.atlascloud.ai/v1", 5 "api_key": "ac_prod_secure_token_7721", 6 "model_id": "deepseek-ai/deepseek-v4-pro" 7 } 8}
第 3 步:觸發管線並檢查指標
當執行訊號擊中 exec_in 接腳時,引擎會激活運行器邏輯:
Rust
plaintext1let mut hasher = blake3::Hasher::new(); 2hasher.update(b"atlascloud"); 3// System hashes parameters and returns a unique, reusable VLM Bit structure
引擎會驗證該結構,將驗證邏輯整潔地封裝在相容 OpenAI 的執行階段提供者執行個體 (custom:openai) 中,並透過 model 接腳將結構化的 Bit 物件傳遞給下游的視覺提取區塊。
生產效能指標:
- 引擎初始化佔用: ~24 MB RAM
- 內部節點接腳延遲: < 0.1ms
- 型別安全錯誤: 0(皆在配置階段捕捉)
深度比較表:引擎規格總覽
| 架構維度 | n8n 工作流引擎 | flow-like 架構 |
|---|---|---|
| 底層語言 | Node.js (TypeScript / JavaScript) | Rust (純原生核心) |
| 數據介面型別 | 鬆散 JSON (執行階段動態驗證) | 強型別合約 (Pins 強制結構) |
| 最大併發吞吐量 | ~220 任務/秒 (受限於 V8 事件迴圈) | ~244,000 工作流/秒 (零 GC 執行) |
| 執行沙盒 | VM2/Isolates (容易出現原型污染) | WebAssembly (WASM) 隔離 |
| 離線架構 | 需要重型 Docker 環境 | 本地優先原生 (可在 Raspberry Pi 上流暢執行) |
| 模型接入生態 | 針對供應商的個別社群整合 | 統一端點 (透過 Atlas Cloud 節點層) |
常見問答:關於 Rust 自動化的疑慮
基於 Rust 的引擎意味著我必須編寫原生的 Rust 代碼來構建節點嗎?
不需要。你不需要為了擴展平台而編寫 Rust。雖然引擎核心是純 Rust,但 flow-like 使用 WebAssembly (WASM) 沙盒來支援跨 15 種以上語言(包括 TypeScript、Python 和 Go)的自定義節點生成,且不會破壞引擎的執行階段安全性保證。
型別安全系統如何處理任意的、動態的 API 負載?
它在輸入節點將鬆散的輸入映射到定義良好的 Struct 容器中。透過在輸入接腳強制執行嚴格邊界,任何缺失的鍵或格式變異都會在邊界節點被立即發現並處理,確保內部邏輯步驟永遠不會遇到未定義的執行階段變數。
處理大量處理迴圈時,精確的記憶體開銷是多少?
在典型的重負載下,該平台的基礎記憶體分配平均不到 30 MB。由於 Rust 在數據超出作用域時會立即釋放資源區塊暫存器,而不是排隊等待垃圾回收,因此即使在處理寬迭代矩陣時,記憶體圖表也呈現一條平坦的直線。






