
Shengshu Tech 的 Vidu Q3 為 AI 影片生成帶來了兩項大多數模型仍視為次要功能的強大能力:原生音訊生成與智慧剪輯 (Smart Cuts)。原生音訊意味著模型能在一次生成中同步產生視覺內容與對應音訊,無需額外的音訊管道或後製同步。智慧剪輯則是自動場景偵測系統,可識別生成素材中的邏輯剪輯點,為剪輯師提供預先分段、便於組合的片段。對於需要大規模構建內容管線的團隊來說,這兩項功能共同消除了生產過程中大量的繁瑣手動工作。
本指南涵蓋了您透過 Atlas Cloud API 開始使用 Vidu Q3 所需的一切:技術規格、定價分析、Python 整合範例、提示詞優化策略,以及與 Veo 3.1、Kling 3.0、Seedance 2.0 和 Hailuo 2.3 的直接對比。無論您是為了新專案評估 Vidu Q3,還是將其與當前模型進行比較,這都是一份詳盡的參考資料。
最後更新:2026 年 2 月 28 日
查看 Vidu Q3 與其他頂尖 AI 影片模型的比較:
j-qDCyXubyE
Vidu Q3 API 可透過 Atlas Cloud 以每秒生成影片 $0.07 的價格使用。
Vidu Q3 概覽
| 規格 | 詳情 |
| 開發商 | Shengshu Technology |
| API 模型 ID | shengshu/vidu-q3/text-to-video |
| 最高解析度 | 1080p |
| 最長時長 | 12 秒 |
| 原生音訊 | 是 -- 隨影片同步生成的音訊 |
| 智慧剪輯 | 是 -- 自動場景偵測與分割 |
| Atlas Cloud 定價 | $0.07/秒 |
| 最大優勢 | 原生音訊 + 智慧剪輯工作流整合 |
| 輸入模式 | 文字轉影片、圖片轉影片 |
Vidu Q3 的主要功能
原生音訊生成
Vidu Q3 在影片創作過程中會生成同步音訊。當提示詞描述包含環境音的場景時(例如:窗上的雨聲、碎石上的腳步聲、人群的細語聲),模型會在一次生成中同時產出視覺與音軌。音訊具有上下文感知能力,在時間點與強度上與視覺內容相匹配。
這是一個顯著的差異化優勢。大多數 AI 影片模型仍只輸出靜音影片,要求團隊必須尋找現成素材、透過專門模型單獨生成音訊,或在後製中手動添加聲音。使用 Vidu Q3,音影配對在生成時即已完成。對於製作社群媒體短片、產品演示或氛圍內容的創作者而言,這不僅省去了一個工作流程,更解決了後製同步的挑戰。
Vidu Q3 的音訊生成品質能有效涵蓋環境音景、環境特效與上下文相關音效。對話與音樂生成並非其主要強項——這些部分仍建議使用專業音訊模型——但對於自然的環境音來說,其輸出在許多場景下已達到可直接發佈的品質。
智慧剪輯 (Smart Cuts) -- 自動場景偵測
智慧剪輯是 Vidu Q3 的自動場景偵測與分割系統。生成影片片段後,模型會識別邏輯場景邊界,並提供關於自然剪輯點位置的詮釋資料。這對於長度接近 12 秒上限的生成內容尤為有用,因為模型產出的內容通常包含自然的視覺轉場。
對於影片剪輯管線而言,智慧剪輯的詮釋資料減少了手動瀏覽素材以確認剪輯點的時間。建構自動化內容系統的團隊可以利用這些資訊,以程式化方式分割片段、將其與其他生成的素材重組,或為不同分發管道選擇特定場景。此功能將原始的 AI 生成輸出從「需要剪輯的素材」轉變為「已預先分段、隨時可組裝的內容」。
1080p 輸出與 12 秒時長
Vidu Q3 支援 1080p 解析度,最長持續時間為 12 秒。12 秒的上限使其成為市面上時長較長的模型之一——超過了 Veo 3.1 的 8 秒與 Kling 3.0 的 10 秒,雖不及 Seedance 2.0 的 15 秒上限,但對於社群媒體廣告、產品展示、環境氛圍循環等許多使用場景而言,12 秒已提供了足夠的畫布來傳達完整的視覺敘事。
1080p 解析度是網路與社群媒體傳播的標準。輸出品質清晰,在整個生成視窗中具備良好的時間連貫性。物件保持穩定的形態,光影轉場平滑,且攝影機移動流暢,無明顯偽影。
圖片轉影片
除了文字轉影片外,Vidu Q3 還支援圖片轉影片生成。這允許團隊使用現有圖片(如產品照片、品牌素材、設計圖)作為起始影格並從中生成動態。模型會根據輸入圖片與提示詞的組合來為場景添加動作,同時維持與原始素材的視覺一致性。
對於擁有現成產品攝影圖且希望在不重新拍攝的情況下製作影片內容的電商團隊而言,圖片轉影片功能特別具有價值。靜態的產品影像可被轉化為旋轉展示、生活化場景或動態廣告。
動作與物理效果處理
Vidu Q3 的物理模擬表現處於穩健的中間地帶。流體動力學、粒子效果與基礎的物件互動皆呈現得相當自然。攝影機移動(如平移、推軌、跟拍)處理得十分流暢。模型偶爾在複雜的多物件物理互動中會出現局限:多個剛體之間的碰撞或複雜的機械運動有時會顯得稍微不自然。然而,對於大多數內容生產場景而言,其物理處理能力已綽綽有餘。
Vidu Q3 定價
Atlas Cloud API 定價
Atlas Cloud 為 Vidu Q3 提供直接的按秒計費方式,無隱藏費用、訂閱層級或點數包要求。
| 模型 | Atlas Cloud 定價 | 每 12 秒影片 |
| Vidu Q3 (文字轉影片) | $0.07/秒 | $0.84 |
生成一段完整的 12 秒 Vidu Q3 影片費用為 $0.84。對於較短的片段,成本會線性擴展——6 秒影片為 $0.42,4 秒片段則為 $0.28。
開發者為何選擇 Atlas Cloud 作為 Vidu Q3 的平台:
- 使用單一 API 金鑰即可同時呼叫 Vidu Q3 與其他 300 多種 AI 模型——包含影片、圖片、文字與多模態。一次整合,統一帳單。
- 無隊列延遲——生產級基礎設施,確保穩定的生成時間。
- 透明定價——每秒 $0.07,精確計算。無點數包、無訂閱層級、無過期代幣。
成本比較:Vidu Q3 的規模化應用
| 規模 | 每月影片數量 | 總秒數 | Atlas Cloud 費用 |
| 輕量級 | 50 部 | 600 秒 | $42.00 |
| 中量級 | 200 部 | 2,400 秒 | $168.00 |
| 重量級 | 500 部 | 6,000 秒 | $420.00 |
| 企業級 | 2,000 部 | 24,000 秒 | $1,680.00 |
以每秒 $0.07 計算,Vidu Q3 在定價格局中處於中等位置。它比 Veo 3.1 ($0.03/秒) 和 Seedance 2.0 ($0.022/秒) 貴,但大幅低於 Kling 3.0 ($0.126/秒) 和 Sora 2 ($0.15/秒)。原生音訊與智慧剪輯功能可透過省去後續音訊素材採購與手動剪輯成本,從而抵銷價格差異。
功能價格比較
| 模型 | 價格/秒 | 原生音訊 | 智慧剪輯 | 最大時長 |
| Vidu Q3 | $0.07 | 是 | 是 | 12 秒 |
| Veo 3.1 | $0.03 | 是 | 否 | 8 秒 |
| Seedance 2.0 | $0.022 | 是 | 否 | 15 秒 |
| Kling 3.0 | $0.126 | 是 | 否 | 10 秒 |
| Sora 2 | $0.15 | 是 | 否 | 12 秒 |
在評估成本時,團隊應納入原生音訊與智慧剪輯帶來的後續節省。一個原本需要單獨音訊生成(每片段 $0.02-$0.05)與手動場景分割(每片段 5-10 分鐘剪輯時間)的工作流程,可能會發現 Vidu Q3 的一體化解決方案實際上降低了總生產成本。
如何存取 Vidu Q3 API
透過 Atlas Cloud 開始使用 Vidu Q3 API 不到五分鐘。本教學將介紹一個完整的 Python 運作範例。
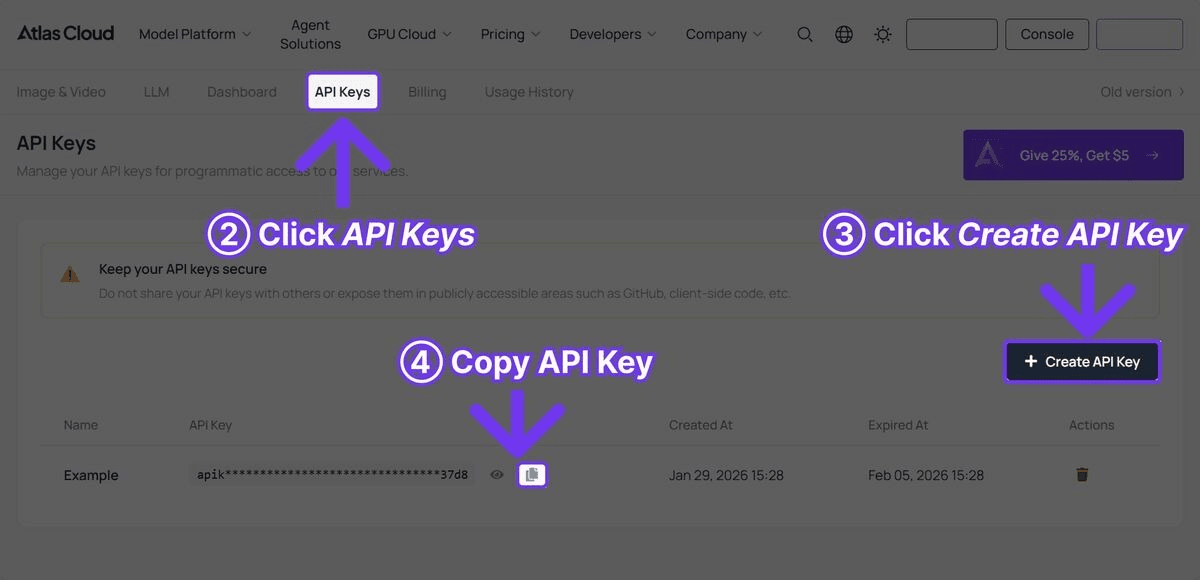
第一步:獲取您的 API 金鑰
在 Atlas Cloud 註冊帳號並前往控制台的 API 金鑰頁面。
第二步:生成帶有原生音訊的影片
python1import requests 2import time 3 4API_KEY = "your-atlas-cloud-api-key" 5BASE_URL = "https://api.atlascloud.ai/api/v1" 6 7response = requests.post( 8 f"{BASE_URL}/model/generateVideo", 9 headers={ 10 "Authorization": f"Bearer {API_KEY}", 11 "Content-Type": "application/json" 12 }, 13 json={ 14 "model": "shengshu/vidu-q3/text-to-video", 15 "prompt": "一位街頭音樂家在黃昏時分於歐洲鵝卵石巷弄內彈奏吉他,背景有溫暖的咖啡館燈光,柔和的人群氛圍音,淺景深效果", 16 "duration": 12, 17 "resolution": "1080p" 18 } 19) 20 21result = response.json() 22 23while True: 24 status = requests.get( 25 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 26 headers={"Authorization": f"Bearer {API_KEY}"} 27 ).json() 28 if status["status"] == "completed": 29 print(f"Video: {status['output']['video_url']}") 30 break 31 elif status["status"] == "failed": 32 print(f"Generation failed: {status.get('error', 'Unknown error')}") 33 break 34 time.sleep(5)
第三步:檢索與使用
回應將包含一個指向生成影片檔案的 video_url 欄位。原生音訊預設已包含在輸出檔案中——無需額外的 API 呼叫或參數。若有的話,智慧剪輯詮釋資料會作為場景邊界的時間戳記包含在回應中,可用於程式化剪輯。
Vidu Q3 提示詞技巧
Vidu Q3 的有效提示需要同時關注視覺與音訊線索。該模型對於描述豐富、環境細節清晰的場景回應良好,因為這為影片與音訊生成系統提供了強有力的背景上下文。
1. 描述音景
由於 Vidu Q3 生成原生音訊,明確描述音訊元素的提示詞將產生同步效果更好的結果。不要只描述場景看起來如何,更要描述它聽起來如何。
- 有效:「雨滴落在鄉村穀倉的鐵皮屋頂上,遠處雷聲隆隆,偶爾有風呼嘯吹動門扉」
- 較不有效:「雨中的穀倉」
2. 利用 12 秒的視窗
憑藉 12 秒的生成時間,Vidu Q3 能處理比短時長模型稍微複雜的敘事。單一提示詞可包含起點與演變——雖非完整故事,但可包含視覺上的發展。
- 「一艘紙船沿著雨水溝漂流,隨著水流增強而加速,並穿過一座石橋進入更寬的溪流」
- 「晨霧緩緩從湖面升起,露出木製碼頭,一艘繫在柱子上的獨木舟輕輕搖晃」
3. 使用環境細節作為音訊背景
您的環境描述越豐富,生成的音訊在上下文上就越準確。
- 「夜晚繁忙的東京十字路口——霓虹燈在濕漉漉的地面上反射,車輪在濕路上的滾動聲,遠處的火車鳴笛,人行道訊號燈的嗶嗶聲」
- 「安靜的圖書館閱覽室——翻書聲,輕微的低語,遠處在硬木地板上的腳步聲,時鐘滴答聲」
4. 指定攝影機移動
Vidu Q3 能很好地處理標準電影攝影機運動。明確指定攝影機運動可改善輸出的一致性。
- 「攝影機在昏暗的酒窖中緩慢向前推軌,平視視角,經過一排排陳年的木桶」
- 「俯瞰追蹤鏡頭,跟隨騎自行車的人沿著沿海公路行駛,左側為海洋,右側為懸崖」
5. 保持場景複雜度在可控範圍內
雖然 Vidu Q3 可以處理多元素場景,但最佳效果來自於聚焦於一個主要主體及輔助環境細節的提示詞,而不是試圖同時編排多個角色或動作。
表現良好的範例提示詞
環境內容:
plaintext1深夜森林空地中的營火劈啪作響,火星飄向星空,蟋蟀鳴叫,偶爾有貓頭鷹啼聲,溫暖的橘色光線照亮附近的松樹
產品展示:
plaintext1桌子旁窗邊擺著一個陶瓷馬克杯,裡面裝著冒著熱氣的黑咖啡,窗外可見清晨的雨,雨滴敲擊玻璃,熱氣在柔光中裊裊上升
旅遊內容:
plaintext1黃金時刻俯瞰梯田的緩慢空拍無人機鏡頭,遠處有農工,水面反射著夕陽天空,昆蟲嗡嗡作響,遠處傳來村莊的聲音
Vidu Q3 與競爭對手對比
2026 年的 AI 影片生成領域提供了多種強大的選擇。以下是 Vidu Q3 與其他領先模型的直接對比,這些模型皆可透過單一 Atlas Cloud API 金鑰存取。
| 功能 | Vidu Q3 | Veo 3.1 | Kling 3.0 | Seedance 2.0 | Hailuo 2.3 |
| 最高解析度 | 1080p | 電影級 | 超高畫質 (Ultra HD) | 高解析度 | 1080p |
| 最長時長 | 12s | 8s | 10s | 15s | 8s |
| API 成本 (Atlas Cloud) | $0.07/秒 | $0.03/秒 | $0.126/秒 | $0.022/秒 | $0.08/秒 |
| 原生音訊 | 是 | 是 | 是 (5 種語言) | 是 | 否 |
| 智慧剪輯 | 是 | 否 | 否 | 否 | 否 |
| 圖片轉影片 | 是 | 否 | 是 | 是 | 是 |
| 最大優勢 | 音訊 + 智慧剪輯 | 電影級質感 | 解析度 | 多模態控制 | 動漫/插畫風格 |
Vidu Q3 的勝出之處
- 智慧剪輯:在此對比中,沒有其他模型提供自動場景偵測與分割功能。對於建立自動化影片剪輯管線的團隊而言,單此功能就足以作為選擇此模型的理由。
- 音訊與時長組合:Vidu Q3 提供 12 秒的原生音/影生成。僅有 Sora 2 在具備音訊的情況下能達到此時長,但價格卻是兩倍以上 ($0.15/秒 vs $0.07/秒)。
- 帶音訊的圖片轉影片:在一次執行中為靜態圖片加入同步音訊並賦予動態,這是一個少有競爭對手能如此乾淨利落實現的工作流程。
- 平衡的定價:以 $0.07/秒的價格,Vidu Q3 處於舒適的中間地帶——顯著比頂級模型 (Kling 3.0, Sora 2) 便宜,同時提供了入門模型 (Veo 3.1, Seedance 2.0) 所缺乏的功能。
競爭對手的優勢
- 電影級品質:Veo 3.1 產出的視覺輸出更為精緻、達廣播級水準,且具備優異的調色與景深效果。對於高級品牌內容,Veo 3.1 的視覺品質更勝一籌。
- 解析度:Kling 3.0 支援超高畫質輸出。對於需要最高解析度交付物的團隊,Kling 仍是領導者。
- 時長與價格:Seedance 2.0 提供 15 秒僅需 $0.022/秒——每秒價格比 Vidu Q3 便宜近 7 倍,且時長多出 3 秒。對於預算敏感且不需要智慧剪輯的團隊,Seedance 是價值首選。
- 風格化內容:Hailuo 2.3 在動漫與插畫風格方面表現出色,這對於創意與風格化內容生產至關重要。
- 多模態輸入:Seedance 2.0 最多支援 9 張圖片、3 段影片與 3 個音訊檔案作為參考素材,為複雜專案提供了無與倫比的創意控制。
選擇合適的模型
這些模型之間的決策取決於您工作流程的優先順序:
- 當您需要原生音訊與智慧剪輯來簡化後製工作時,特別是針對社群媒體、氛圍內容或自動化影片管線,請選擇 Vidu Q3。
- 當電影級視覺品質是最高優先級且預算是關鍵限制時,請選擇 Veo 3.1。
- 當對超高畫質解析度有硬性要求時,請選擇 Kling 3.0。
- 當您需要最長片段、最低價格以及多參考素材的創意控制時,請選擇 Seedance 2.0。
- 當動漫或插畫風格內容為優先時,請選擇 Hailuo 2.3。
誰應該使用 Vidu Q3?
若符合以下情況,請選擇 Vidu Q3:
- 您正在構建自動化內容管線。智慧剪輯提供了可直接餵入剪輯流程的程式化場景分割。結合原生音訊,Vidu Q3 輸出的片段在發布前只需極少的後製處理。
- 音影同步至關重要。環境內容、帶環境音的產品演示、旅遊影片、ASMR 風格內容——任何需要聲音與影像緊密耦合的使用場景,都能從原生音訊生成中獲益。
- 您正在大規模生產社群媒體內容。12 秒的時長涵蓋了大多數社群短片格式 (Instagram Reels, TikTok, YouTube Shorts),且原生音訊消除了查找與同步額外音軌的需求。
- 您的團隊缺乏後製資源。智慧剪輯與原生音訊共同消除了兩項最耗時的後製步驟:音訊查找/同步與手動場景偵測/剪輯。
- 您需要帶聲音的圖片轉影片功能。在一個 API 呼叫中,為現有產品照片或品牌素材添加同步的環境音並使其動態化,是 Vidu Q3 特別擅長的工作流程。
若符合以下情況,請考慮其他方案:
- 預算是首要考量。Seedance 2.0 ($0.022/秒) 和 Veo 3.1 ($0.03/秒) 都便宜得多。如果智慧剪輯和高度整合的音訊並非關鍵需求,規模化生產下的節省將非常顯著。
- 您需要最高的視覺品質。Veo 3.1 的電影感與 Kling 3.0 的超高畫質在視覺精細度上皆超越 Vidu Q3。
- 您需要超過 12 秒的片段。Seedance 2.0 提供 15 秒生成,這在某些內容格式中可能是必要的。
- 需要複雜的多參考素材工作流程。Seedance 2.0 對最多 12 個參考檔案的支援提供了 Vidu Q3 無法匹敵的創意控制。
Vidu Q3 的理想使用場景
- 社群媒體內容 -- 帶有原生音訊、可立即發布的 12 秒短片
- 氛圍與 ASMR 內容 -- 帶有上下文準確音景的環境場景
- 自動化影片管線 -- 智慧剪輯詮釋資料支援程式化編輯與組裝
- 電商產品影片 -- 帶環境音的圖片轉影片,用於產品展示
- 旅遊與生活風格內容 -- 帶同步自然音效的氛圍場景
- Podcast 與部落格影片素材 -- 補充文字或音訊內容的快速氛圍片段
常見問題 (FAQ)
Vidu Q3 在 Atlas Cloud 上的費用是多少?
Vidu Q3 在 Atlas Cloud 上的定價為每秒 $0.07。生成一段 12 秒影片的成本為 $0.84。
Vidu Q3 會自動生成音訊嗎?
是的。Vidu Q3 會在影片生成過程中同步產生音訊。音訊具備上下文感知能力——它與提示詞中描述的視覺內容相匹配。環境音、背景雜音與氛圍音與影片在一次執行中共同生成,無需額外的音訊 API 呼叫。
什麼是智慧剪輯 (Smart Cuts)?
智慧剪輯是 Vidu Q3 的自動場景偵測功能。在生成影片片段後,模型會識別邏輯場景邊界,並提供關於素材中自然剪輯點的詮釋資料。此詮釋資料可用於程式化的片段分割,使得將 Vidu Q3 輸出整合到自動化剪輯管線中變得更加容易。
Vidu Q3 支援圖片轉影片嗎?
是的。Vidu Q3 接受圖片作為輸入,並生成從該初始影格開始動態化的影片。對於擁有現成產品攝影或品牌素材,且希望在不從零開始的情況下製作影片內容的團隊來說,這非常實用。文字提示詞將引導動畫的方向與風格。
Vidu Q3 與 Veo 3.1 相比如何?
兩者皆能生成原生音訊,但適用於不同的主要場景。Veo 3.1 在以更低價格 ($0.03/秒 vs $0.07/秒) 提供卓越調色與景深的電影級視覺品質上更勝一籌。Vidu Q3 則提供更長的時長 (12s vs 8s)、用於自動化剪輯的智慧剪輯功能,以及圖片轉影片能力。若預算內追求高級視覺品質,請選擇 Veo 3.1;若需要智慧剪輯、更長片段或帶音訊的圖片轉影片,請選擇 Vidu Q3。
我可以使用 Vidu Q3 進行商業專案嗎?
是的。透過 Atlas Cloud API 生成的影片可用於商業用途。與所有 AI 生成內容一樣,團隊應審閱相關的服務條款,並遵守其管轄區內關於披露 AI 生成媒體的相關法規。
結論
Vidu Q3 在 AI 影片生成領域佔據了獨特的地位。它並非最便宜的模型(Seedance 2.0 與 Veo 3.1 更實惠),解析度也不是最高的(Kling 3.0 領先),視覺精緻度亦非頂尖(Veo 3.1 在電影質感上獲勝)。它提供的是一種組合式優勢——原生音訊生成與智慧剪輯——這是目前其他模型尚未整合的特點。對於那些視後製效率與原始輸出品質同樣重要的團隊而言,這種組合極具吸引力。
透過 Atlas Cloud 的 $0.07/秒定價,使其處於合理的中間地帶。製作氛圍內容、社群媒體短片或建構自動化影片管線的團隊將會發現,省去單獨採購音訊與手動偵測場景的工作,足以抵銷相較於廉價替代品多出的成本。
使用單一 Atlas Cloud 帳號與 API 金鑰,評估 Vidu Q3 與競爭模型的表現。選擇最符合您特定工作流程與品質要求的模型(或模型組合)。
────────────────────────────────────────────────────────────






