DeepSeek v4:目前我們所知的一切 —— 功能、發佈日期以及如何在 Atlas Cloud 上使用
簡介:什麼是 DeepSeek v4?
Atlas Cloud 正在擴充其生成式 AI 產品陣容,即將加入 DeepSeek v4。
- 它是什麼: DeepSeek 團隊最新的旗艦模型。如果 DeepSeek v3.2 樹立了高性價比開源編碼模型的標準,那麼 v4 則透過專有的 流形約束超連結 (Manifold-Constrained Hyper-Connections, mHC) 與 記憶印跡 (Engram Memory) 技術,進一步突破了邏輯與記憶的界限。
- 主要優勢: v4 不僅能生成程式碼片段,更像一位資深架構師,能夠理解整個儲存庫 (Repository) 的結構,進行跨檔案推理與複雜的 Bug 修復。
- 狀態: 即將發佈(預計於 2026 年 2 月中旬 —— 請參閱我們關於 DeepSeek V4 期待功能 的深度報導)。
為什麼我們確信 DeepSeek v4 將改變遊戲規則?因為它解決了業界最大的痛點:AI 需要記憶並理解專案的邏輯。
📣 更新 — 2026 年 4 月 24 日: DeepSeek-V4 已正式推出。請閱讀我們關於其實際發佈內容的完整報導,包括全新的稀疏注意力架構、1M Token 上下文以及 Agent 基準測試結果 —— 請見 DeepSeek-V4 預覽版發佈。
技術深度解析:關鍵功能
為了挑戰 Claude Opus 4.5,DeepSeek 對模型進行了徹底重構。外流文件顯示,該模型在處理記憶與邏輯穩定性方面有根本性的轉變。讓我們拆解此更新的四大支柱。
架構:卓越的邏輯推理
-
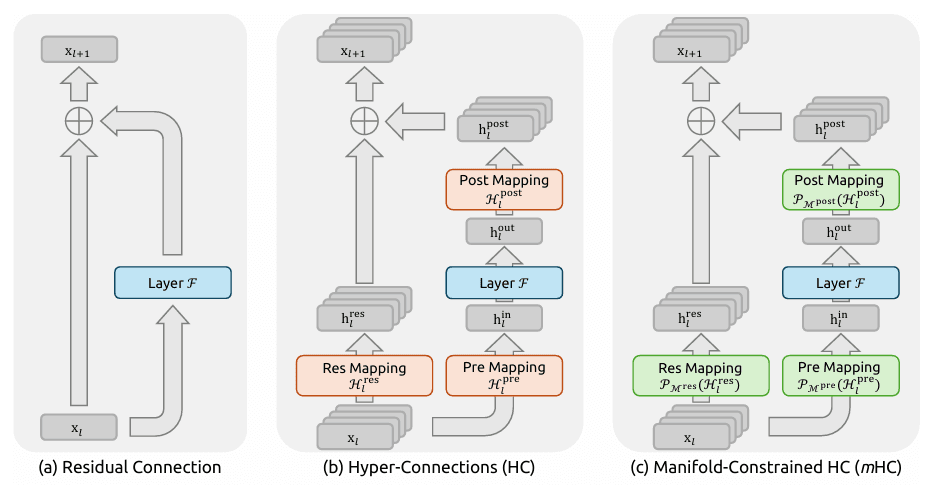
流形約束超連結 (Manifold-Constrained Hyper-Connections, mHC)
- 概念: DeepSeek v4 發明了一種新的「神經佈線」方法。傳統連接往往會在深層網路中遺失資訊,而 mHC 就像是 AI 大腦中的「邏輯高速公路」。
- 結果: 在處理海量、複雜的邏輯(例如重構數千行程式碼)時,模型能學習得更快,並更好地保留邏輯。這消除了長上下文生成中常見的「邏輯幻覺」與不一致性。
效率:降低推論成本
-
混合專家模型 (MoE) 2.0
- 概念: 雖然 v4 是一個參數巨獸(數千億參數),但它採用了優化的 MoE 架構,只為每個 Token 啟動最相關的「專家」。
- 結果: 它在 強大能力(龐大的知識庫)與 高效擴展(運行起來像較小模型一樣輕量)之間取得了完美平衡。
-
稀疏注意力 (Sparse Attention)
- 概念: 放棄了掃描所有文字的暴力法,模型現在能智慧地只聚焦於關鍵資訊。這大幅降低了運算成本並加速了長上下文的處理。
記憶:智慧化的上下文管理
-
記憶印跡 (Engram Memory)(選擇性儲存與回憶)
- 概念: AI 不再死記硬背,而是開始「理解」。它能識別專案結構、遵循命名慣例(snake_case vs. camelCase),並辨識編碼模式(模仿貴團隊特定的工程範式)。
- 結果: 它的編碼表現如同資深員工。
-
多頭潛在注意力 (Multi-Head Latent Attention, MLA)
- 概念: 將其視為「超級速記」。其他模型需要 100 個 Token 才能儲存資訊,MLA 則將其壓縮為 10 個關鍵符號。
- 結果: 當需要回憶時,模型能以數學方式重建原始意義而無損失。這在顯著降低 VRAM 使用率的同時,保持了極高的細節保留度。
應用:現實世界的工程實踐
- 儲存庫級別的理解與 Bug 修復
- 目標不只是撰寫一個函式,而是掌控整個程式碼庫。在 SWE-bench 測試中,DeepSeek v4 旨在透過理解跨檔案依賴關係,解決超過 80.9% 的現實複雜問題。
使用場景:降低成本與提升效率
DeepSeek v4 是為硬核工程而打造的,以下是它與競爭對手的比較:
重構遺留程式碼
對於無文件、混亂的遺留系統,mHC 架構是救星。它能追蹤長距離的邏輯依賴關係,確保重構的安全性。
- 對比 GPT-4o: 當上下文超過 10k Token 時,GPT-4o 常會出現「邏輯幻覺」(發明不存在的函式呼叫)。DeepSeek v4 在長上下文中保持了 100% 的邏輯一致性。
- 對比 Claude 3.5 Sonnet: 雖然 Sonnet 品質很高,但對於大規模重構任務來說,它速度慢且成本昂貴。DeepSeek v4 的 MoE 架構在 Atlas Cloud 上能以更低的成本提供約 40% 更快的推論速度。
儲存庫級別的功能開發
當在成熟專案中新增 API 時,v4 會利用「記憶印跡」瞬間掌握上下文。
- 對比傳統自動補全: 標準工具往往會忽略專案特定的規範,導致風格不一致。DeepSeek v4 模仿現有程式碼庫的效果之好,感覺就像是從您最優秀的開發人員那裡直接複製貼上。
全鏈路 Bug 追蹤
在 SWE-bench 上達到 80.9% 的成功率,意味著它能處理橫跨前端、後端與資料庫的 Bug。
- 對比 Claude Opus 4.5 (預期): Opus 4.5 可能非常強大,但價格昂貴。DeepSeek v4 以接近 SOTA 的性能與親民的價格,讓團隊能夠進行反覆的「反思與修正」迴圈,而無需耗費巨資。
📉 重點:團隊的投資回報率 (ROI)
對於新創公司與開發團隊,DeepSeek v4 + Atlas Cloud 的組合帶來了實質的投資回報:
- 生產力: 將資深開發人員的編碼時間減少 30-50%。
- 成本: 與租用雙 RTX 4090 伺服器或支付封閉原始碼 API 費用相比,Atlas Cloud 的整合 API 可為團隊節省超過 60% 的綜合運算成本。
硬體紅線:本地部署?請三思。
現在您可能很想在本地機器上運行這位「編碼之神」。但我們必須讓您認清現實:性能是有代價的。
- 最低門檻:雙 RTX 4090
- 解析: 您需要購買市面上兩張最貴的消費級 GPU 並進行連結。僅 GPU 的成本大約相當於 3 支 iPhone 17 Pro Max(或一台不錯的二手車)。
- 建議規格:單張 RTX 5090 (2026 旗艦款)
- 解析: 這是 GPU 中的「法拉利」。由於黃牛炒作,價格不僅會高得離譜,庫存也將非常稀缺。
隨著 GPU 價格居高不下,請自問:值得花費數千美元,還要處理風扇噪音、散熱問題與環境配置,只為了運行一個模型嗎?
聰明的解決方案:Atlas Cloud 第 0 天存取權
您不需要很有錢才能使用 DeepSeek v4;您只需要足夠聰明。與其購買會貶值的「電子磚頭」,不如選擇雲端。
Atlas Cloud 已為發佈做好準備:
-
我們的承諾: 享受您的假期。將部署的繁重工作交給我們。我們將 24/7 監控官方發佈管道。
-
核心優勢:
- 即時存取: 一旦開源權重釋出,我們的 API 整合便會立即上線。
- 零門檻: 無需昂貴硬體,無 CUDA 依賴地獄。只需帶上您的 Prompt。
- 無妥協體驗: 我們提供完整的上下文支援,確保「記憶印跡」機制在無量化損失的情況下,以 100% 的能力運作。
如何在 Atlas Cloud 上使用
Atlas Cloud 讓您可以 並排使用模型 —— 先在 Playground 中嘗試,再透過單一 API 整合。
方法 1:直接在 Atlas Cloud Playground 中使用
方法 2:透過 API 存取
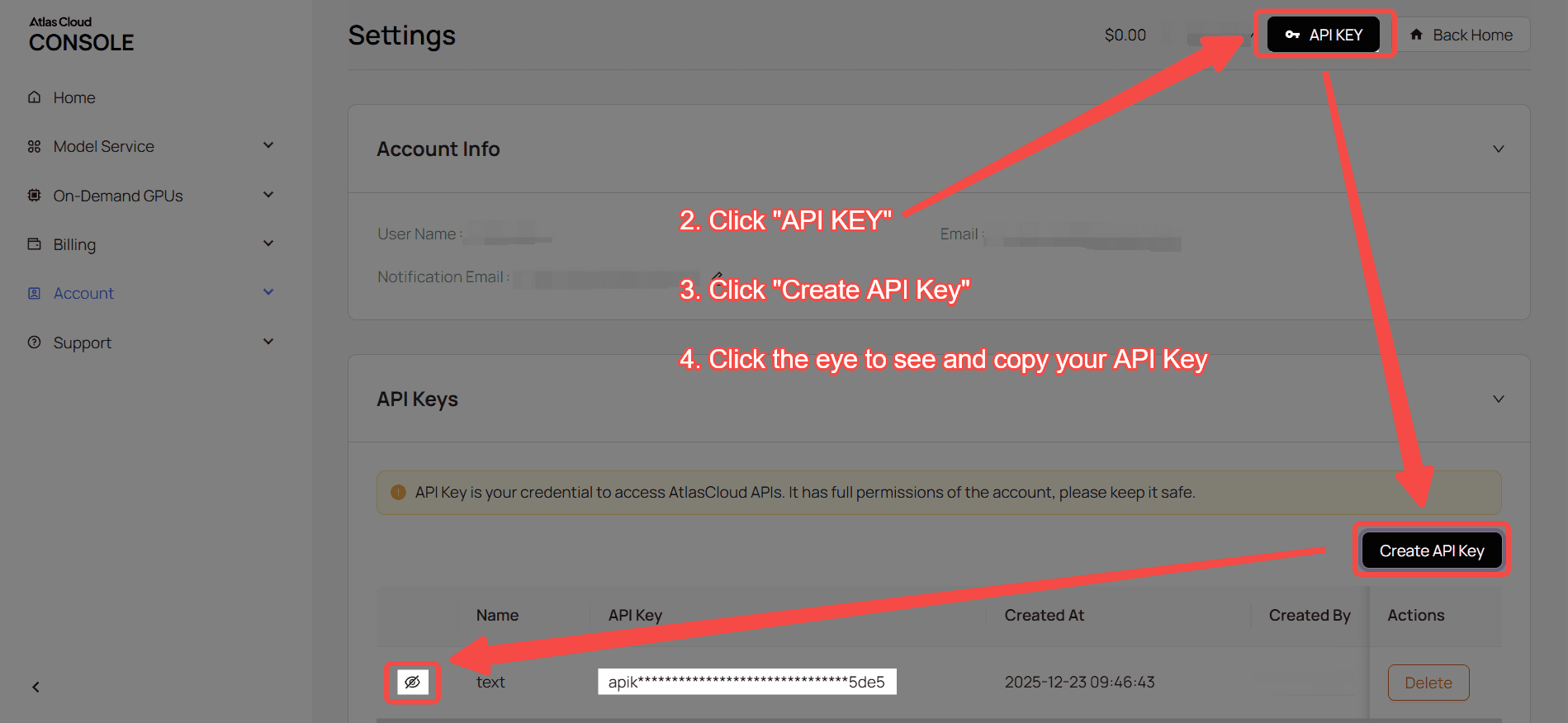
第 1 步:取得您的 API Key
在您的 控制台 (Console) 中建立 API Key,並複製以備後用。
第 2 步:查看 API 文件
在我們的 API 文件 中檢閱端點、請求參數與驗證方式。
第 3 步:發出您的第一個請求(Python 範例)
範例:使用 DeepSeek v3.2 生成內容:
plaintext1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






