
如果您編寫 GPU Kernel,您其實是在一個光譜上遊走。光譜的一端是 Triton:編寫快速,但編譯器會為您處理大部分的佈局(layout)和共享記憶體(shared memory)決策。另一端是 CUTLASS / CuTe:擁有完全掌控權,但代價是大量的模板程式碼(template machinery)。TileLang 則位於兩者之間。您使用 Python 編寫程式,但必須明確指定什麼資料存放在共享記憶體中、管線(pipeline)如何分級、以及 Warp 如何劃分工作——剩下的部分則透過「佈局推斷(layout inference)」過程自動填入。
這篇文章將涵蓋心智模型,編寫一個 GEMM,然後構建一個真正的生產環境 Kernel:DeepSeek 的 MLA(Multi-Head Latent Attention)解碼,在這裡,有趣的決策才會真正體現出來。我們的目標不是面面俱到,而是展示您應該如何思考 Tile(分塊),以及 TileLang 如何在幕後輕鬆處理棘手的部分。最後,我們將分享一個來自生產環境的典型案例——一個速度提升並非唯一優勢的 Kernel。
心智模型
核心理念可歸納為三點:
- Tile 是第一類物件(first-class object)。 一塊有形狀的資料區塊(例如 block_M × block_K)由一個執行緒區塊(thread block)、Warp 或執行緒來擁有與操作。您不必再像 Triton 那樣僅從執行緒區塊層級思考,也不必像在 CUDA 中那樣手動管理單個執行緒。
- 由您親自放置記憶體層級中的緩衝區。 您需宣告哪些內容放入共享記憶體(
T.alloc_shared)、哪些放入暫存器(T.alloc_fragment),以及哪些屬於執行緒本地。這是與 Triton 最大的區別,Triton 將共享記憶體的配置和分級隱藏在編譯器中。 - 編譯器負責推斷執行緒映射。 一旦您指定了 Tile 的位置以及要在其上執行的操作(複製、GEMM、歸約),「佈局推斷」過程會將其並行化到執行緒中,並規劃暫存器和共享記憶體的佈局。雖然您可以根據需要進行覆寫,但大多數情況下不需要。這個過程是支撐整個功能的關鍵——當我們深入 MLA 時,您就會明白為什麼。
如果您是從 Triton 轉過來的,對照表大致如下:
| Triton | TileLang | |
|---|---|---|
| 粒度 | 執行緒區塊 + 隱式向量化 | Tile(塊 / Warp / 執行緒) |
| 共享記憶體 | 由編譯器管理 | 顯式 alloc_shared + copy |
| 佈局 | 由編譯器決定 | 自動推斷,但可手動標註 |
| 管線化 | tl.range + 編譯器 | 顯式 T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm 搭配可選的 Warp 策略 |
| 後端 | NVIDIA (主要) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL,外加 Ascend 與 MUSA 分支 |
簡而言之:如果您想在不編寫 CUTLASS 的情況下,精細控制區塊劃分、管線深度和 Warp 分割,TileLang 是最佳選擇。對於簡單的逐元素運算或輕量級融合,Triton 仍然是更快捷的工具。
設定環境
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # 預先構建的 wheel,最簡單的方式
如果您打算修改編譯器流程,請改用原始碼構建(您需要本地的 LLVM/CUDA 工具鏈):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
編寫一個 GEMM
我們從每個人都熟悉的 Kernel 開始:C = ReLU(A @ B)。它雖然簡單,但涵蓋了所有重要的原語:顯式緩衝區、並行複製、軟體管線化、Tensor Core 呼叫以及 L2 swizzle。
plaintext1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # 網格維度:(沿 N 的塊數, 沿 M 的塊數);每個區塊 128 個執行緒 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # 明確指定每個 Tile 的位置 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # 共享記憶體 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # 暫存器累加器 23 24 T.use_swizzle(panel_size=4, order="col") # 選項:更好的 L2 重用 25 T.clear(C_local) # 清空累加器 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # 全局 -> 共享 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # Tile 層級 MMA 31 32 for i, j in T.Parallel(block_M, block_N): # 融合 ReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # 回寫 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
各部分的作用如下:
- 三個緩衝區,三個層級。
A_shared和B_shared存於共享記憶體;C_local存於暫存器。暫存器中的累加器,以及透過共享記憶體分級的操作數——這是 GEMM 的標準配方,唯一的區別在於這裡是由「您」親自寫下。這就是與 Triton 的核心差異。 T.copy是並行複製的語法糖。 它會展開為T.Parallel風格的移動,編譯器會從中導出向量化、合併後的「全局→共享」傳輸。當copy位於T.Pipelined內部時,它會自動變為cp.async。T.Pipelined(extent, num_stages=N)是軟體管線。num_stages=3表示三級緩衝——在計算 K-tileko的同時,ko+1和ko+2的負載已經在傳輸中。在 Triton 中,這是一個編譯參數;而在這裡,它只是迴圈的一部分,更容易理解。T.gemm(A, B, C)是 Tile 層級的矩陣乘法。 它在 NVIDIA 上會降低為 CuTe/MMA,在 AMD 上則對應到相應的指令集。它還接受transpose_A / transpose_B以及一個policy=T.GemmWarpPolicy.*參數,用來控制 Warp 如何分割輸出 Tile。請記住這個策略參數,它是我們之後提到 MLA 時的重點。T.use_swizzle會重新排列執行緒區塊的排程,使 L2 中相鄰的區塊在時間上也能連續執行,通常能帶來幾個百分點的頻寬提升。
下圖將這一切對應到硬體上。值得對照程式碼閱讀,因為標註的區域正是 TileLang 將 Triton 隱藏的控制權交還給您的地方。
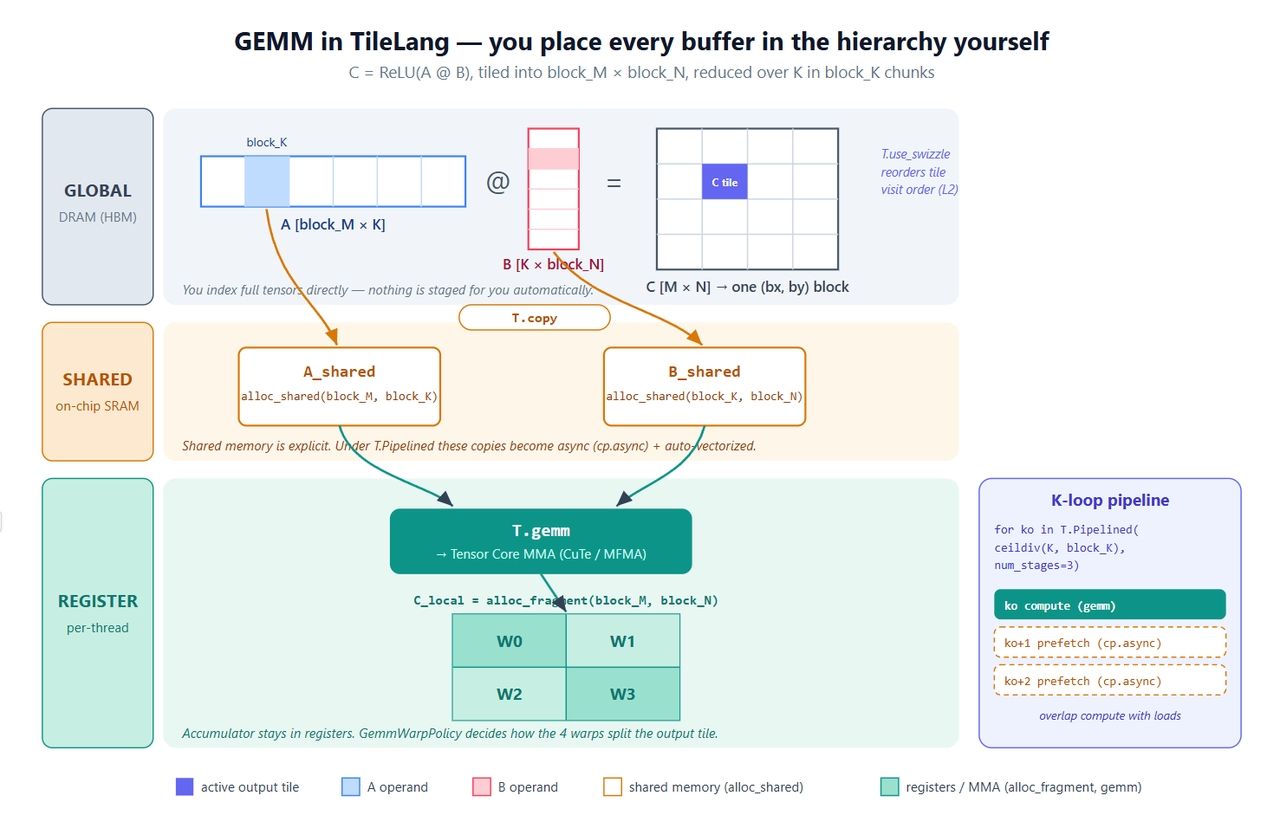
您將經常用到的幾個原語
您可以使用有限的詞彙編寫大多數 Kernel:
- 配置:
T.alloc_shared、T.alloc_fragment(暫存器)、T.alloc_local。 - 移動與初始化: 任意兩層級間的
T.copy(src, dst);T.clear、T.fill。 - 計算:
T.gemm(...);用於逐元素迴圈的T.Parallel(d0, d1, ...)(這是佈局推斷的入口點);T.reduce_max/T.reduce_sum;如T.exp、T.exp2、T.max、T.infinity等標量數學運算。 - 排程:
T.Pipelined(extent, num_stages=)、T.use_swizzle(...)、以及當您需要特定佈局時使用的T.annotate_layout(...)(用於避免 Bank Conflict、自訂 Swizzle)。 - 動態形狀:
M = T.dynamic("m"),這樣您就不需要針對每個形狀重新編譯(在某些版本中稱為T.symbolic)。
驗證結果
您通常會需要兩件事。查看編譯器實際輸出的程式碼:
plaintext1print(kernel.get_kernel_source()) # 產生的 CUDA / HIP
以及進行效能分析:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
T.print(buf) 會在 Kernel 內部列印出一個 Tile,而專案中的 examples/plot_layout 可以繪製記憶體佈局,這在追蹤 Bank Conflict 或檢查 Swizzle 時非常有用。
實際案例:MLA 解碼
GEMM 展示了機制,而下一個案例則展示了這些機制為何重要。我們將剖析 DeepSeek 的 MLA(Multi-Head Latent Attention)解碼 Kernel,因為這是 TileLang 體現其價值的最佳範例。TileLang 的參考實作在大約 80 行 Python 程式碼中,達到了與 FlashMLA 在 H100 上的相當效能(在 fp16、batch 64/128 下進行基準測試,輕鬆領先 Triton 和 FlashInfer)。有趣的問題是它是如何做到的,因為 MLA 的難點不在於數學,而在於暫存器壓力。
讓我們複習一下大家熟知的迴圈。每個 FlashAttention 系列的 Kernel 都有相同的形狀。對於每個 Query 區塊,您串流處理 Key/Value 區塊並維持一個移動的最大值和分母,這樣完整的計分矩陣就不會存入記憶體:
plaintext1# acc_s : [block_M, block_N] 此 KV 區塊的計分 2# acc_o : [block_M, dim] 輸出累加器 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # 重新調整先前的輸出 9 acc_s = exp(acc_s - scores_max) # 機率 10 acc_o += acc_s @ V[i]
acc_s 和 acc_o 都希望保留在暫存器中。對於 MHA 或 GQA,這沒問題。但對於 MLA,則不然。
難點在這裡。 MLA 的 Head 維度很大:Query 和 Key 是 576 寬(包含 512 寬的「nope」部分(無位置編碼)加上 64 寬的「rope」部分),Value 則是 512。因此 acc_o 為 [block_M, 512],並且必須在整個 KV 迴圈中駐留在暫存器中。
現在引入硬體。在 Hopper 上,快速路徑是 wgmma.mma_async,它將 4 個 Warp(128 個執行緒)綁定成一個 Warpgroup,並要求 M 至少為 64。因此一個 Warpgroup 能擁有的最小 M 為 64,這意味著一個 Warpgroup 將持有 64 × 512 的累加器。這對於單個 Warpgroup 的暫存器檔案來說太大了。它會發生溢出(spill),效能隨之崩潰。
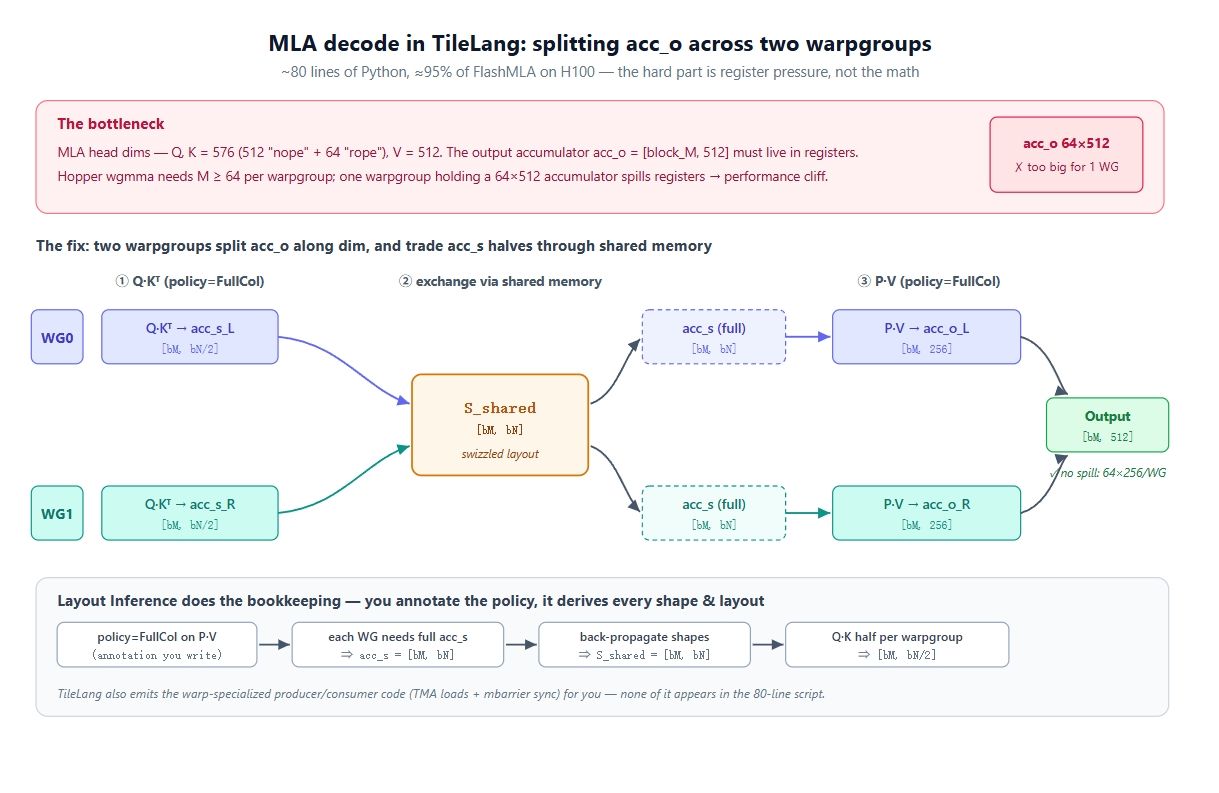
解決方案是將輸出分割到兩個 Warpgroup 上。 您不能將 M 縮小到 64 以下,所以剩下的軸只有維度(dim)。使用兩個 Warpgroup:WG0 擁有 acc_o[:, :256],WG1 擁有 acc_o[:, 256:]。現在每個 Warpgroup 持有一個 64 × 256 的累加器,這就裝得下了。然而,這帶來了第二個問題:P @ V 步驟(使用 policy=FullCol,每個 Warpgroup 產生輸出的一個列條)需要完整的 acc_s,但在 Q @ K 中,每個 Warpgroup 自然只計算了一半。解決方案是共享記憶體交換。在 Q @ K 期間,每個 Warpgroup 將其一半的 acc_s 寫入共享記憶體,並讀取另一個 Warpgroup 的另一半,這樣兩者都持有了完整的 acc_s,從而都能計算出各自的輸出條。上圖正是如此:分割計分,透過 S_shared 交換,分割輸出。
在 CuTe 中,您需要手動編寫佈局、Swizzle、Tensor Core 對齊以及生產者/消費者同步來完成此操作。在這裡能壓縮到約 80 行的原因是佈局推斷。
讓我們分解佈局推斷的作用。 您在 T.gemm 呼叫上標註意圖,它會為您在程式中傳遞約束:
- P @ V 上的
policy=FullCol意味著每個 Warpgroup 需要完整的acc_s,因此acc_s = [block_M, block_N]。 - 這會回溯到分級緩衝區,因此
T.copy(S_shared, acc_s)中的S_shared也是[block_M, block_N]。 - 並向前推導到 Q @ K:使用
FullCol時,每個 Warpgroup 的計分條為[block_M, block_N/2]。
關鍵洞察在於您從未親手撰寫任何這些形狀。您選擇 Warp 策略並編寫數學公式;形狀、Swizzle 佈局以及 Warp 專用的生產者/消費者程式碼都是推斷的結果。
Kernel 架構。 在 MLA 解碼中,Query 分割為「nope」部分(Q,維度 512)和「rope」部分(Q_pe,維度 64),壓縮後的潛在變數同時作為 K 和 V。因此計分是兩個 GEMM 的總和,輸出則是另一個。內部迴圈看起來像這樣(代表性架構,非精確程式碼 — 請參考 example_mla_decode.py):
plaintext1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# 線上 Softmax 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, 使用 scores_scale 重新調整 acc_o, 歸約到 logsum 中 ... 12 13# acc_o += P @ V (V 與潛在 KV 相同) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
一旦 FullCol 策略強迫每個 Warpgroup 擁有完整的 acc_s,兩個 Warpgroup 之間的 S_shared 交換就會由推斷自動插入。
優點:最佳化僅需一行。 這是 TileLang 的回報——整個效能工具包都是單行指令,複雜的底層轉換由系統為您處理。
- 用於 L2 重用的執行緒區塊 Swizzling:
T.use_swizzle(panel_size, order="row")。 - 用於避免 Bank Conflict 的共享記憶體 Swizzling:
T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)})— XOR 風格的位址重映射,使並發存取分散到各個 Bank,而不是序列化。 - Warp 專用化: 您編寫一個簡單的腳本,它會被降低為生產者 Warpgroup(TMA 載入)加上消費者 Warpgroup,並自動產生所有的
mbarrier同步。這些都不會出現在您的程式碼中。 - 管線化:
T.Pipelined(range, num_stages)將載入與計算重疊——級數越多,重疊越多,但共享記憶體佔用也越大,這是一個可調參數。 - Split-KV (FlashDecoding 風格): 當 Batch 很小且 SM 空閒時,將 KV 上下文分割到多個 SM 並合併。這只是一個
num_split參數加上一個合併 Kernel 的事。
因此,真正困難的推理——暫存器預算對應 M≥64 的底限、Warp 間的權責劃分、共享記憶體交換——您只需透過選擇策略和撰寫數學公式來表達。原本在 CuTe 中需要數百行脆弱程式碼才能實現的功能,這裡只需透過推斷和程式碼產生。這就是賣點,也是 MLA 案例最具說服力的地方。
我們自己的案例:AtlasCloud 的 RMSNorm 外掛
最後一個例子是我們在 AtlasCloud 自己的生產 Kernel 之一,用於 H100/H200 上的 Wan 影片生成 VAE。這是 TileLang 另一個擅長點的絕佳範例:以簡潔的外掛(drop-in)方式,覆蓋手動編寫的 Kernel 無法達到的配置。
背景。 我們已經發佈了一個手動編寫的融合 RMSNorm + SiLU Kernel。它很快,並且針對模型配置中使用的隱藏維度 D ∈ {96, 192, 384} 進行了編譯。一個較新的配置需要如 {160, 256, 320, 512, 640, 1024} 的通道寬度,因此在該配置上手動編寫的快速路徑無法執行。我們編寫了一個 TileLang 外掛來填補這個缺口。
TileLang Kernel。 一個具有相同介面(BTHWC 輸入/輸出,相同數學,相同 epsilon)且支援任何 32 倍數 C 的外掛。兩趟(two-pass)處理,完全合併,FP32 累加器:
plaintext1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W 行 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # FP32 平方和 8 # 第 1 趟:遍歷 C 的 BLOCK_C 區塊,以 FP32 累加平方和 9 # rinv = rsqrt(ss / C + 1e-5) 10 # 第 2 趟:重新載入 X,y = silu(x * gamma * rinv),回寫
BLOCK_C 根據 C 的值設為 128/64/32,以遵守 TMA boxDim ≤ 256 的限制,FP32 累加器確保平方和不會在 FP16 中溢出。調度器會在路徑可用時保留手動編寫的路徑,只有在必要時才會回退:
plaintext1_ATLAS_SUPPORTED_D = (96, 192, 384) 2 3def rms_silu_dispatch(x, gamma, out): 4 if x.shape[-1] in _ATLAS_SUPPORTED_D: 5 atlas_rms_norm_silu(x, gamma, out=out) # 保留手動編寫的路徑 6 else: 7 tilelang_rms_silu_bthwc(x, gamma, out=out) # 填補缺口
收穫。 全都是優勢,這是一個真正的外掛——相同的介面、相同的數學、相同的 epsilon,因此它可以無縫插入現有的調度邏輯中,無需更改呼叫位置。
| 內容 | 增益 |
|---|---|
| 先前不支援的配置 | 0 → 1 — 現在可以執行(關鍵突破) |
| Attention-block RMSNorm 對比取代的急切式 PyTorch Norm | 42 μs → 20 μs (~2 倍快) |
| 生產解析度下的端到端 VAE (720×1280, 21 幀) | ~1.79× 編碼, ~1.78× 解碼 |
第一行是重點所在:TileLang 讓我們能夠為先前沒有快速路徑的模型配置提供服務,且無需動到已經為其他配置優化好的手動 Kernel。只需一個用 Python 編寫的外掛,整個模型路徑就從「崩潰」變成了「生產可用」。
TileLang 的優勢
- 無需編寫 CUTLASS/CuTe,即可精細控制區塊劃分、管線級數和 Warp 分割。
- 處理結構複雜、對佈局敏感的 Kernel:GEMM 變體、FlashAttention 系列、MLA、線性注意力、反量化融合 GEMM、MoE 路由。
- 覆蓋您的手動 Kernel 無法觸及的算子或配置(隱藏維度超出定義範圍、非典型佈局)——並且在此過程中擊敗了急切式的備援。
- 跨後端(NVIDIA / AMD / 廠商分支)統一的 Kernel 實作。
- 整個最佳化工具包只需單次呼叫 —
T.use_swizzle、T.annotate_layout、T.Pipelined、Warp 專用化、Split-KV — 底層轉換由系統處理。
總結
TileLang 最酷的地方在於,困難的推理過程保留在您的腦中,而不是大量的樣板程式碼中。您決定如何劃分 Warp 間的工作、緩衝區存放在哪裡、管線跑多深——然後佈局推斷和 Warp 專用化會將其轉化為暫存器佈局、Swizzle 和生產者/消費者舞步,而這些在 CuTe 中通常需要數百行程式碼。您選擇策略並編寫數學公式。這就是它的賣點,也是為什麼一個 80 行的 MLA Kernel 能與手動編寫的 CUTLASS Kernel 並肩作戰的原因。






