أطلقت Google نموذج Gemini Omni في مؤتمر I/O 2026 — وهو نموذج متعدد الوسائط يقوم بتعديل الفيديو من خلال محادثة باللغة الإنجليزية البسيطة، بعيدًا عن الجداول الزمنية (Timelines) أو الإطارات الرئيسية (Keyframes). وتُثبت العروض التوضيحية الرائجة (نحت الفقاعات، المرآة السائلة، عازف الكمان) التحول الحقيقي: الأمر لا يتعلق فقط بتحويل النص إلى فيديو، بل بـ تحويل النص إلى تعديل على الفيديو الذي تمتلكه بالفعل. هذه هي "لحظة كاميرا iPhone" في عالم صناعة الفيديو. وتجدر الإشارة إلى غياب ميزات الخطاب، وتعديل الصوت، والاشتراك الاحترافي — وهذا مقصود تمامًا.
إنها الساعة الواحدة صباحًا. لقد أمضيت أربع ساعات في تعديل مقطع مدته 30 ثانية. يحتوي ملف مشروعك على 47 طبقة. سحبت الإطارات الرئيسية حتى بدأ معصمك يؤلمك. وفجأة، أرسل العميل رسالة: "هل يمكننا تجربة إضاءة أكثر دفئًا؟" وأنت، كمحترف، على وشك البدء من جديد.
كانت هذه هي المهمة. كانت هذه هي المهمة.
في 19 مايو 2026، أوقفت Google هذه الممارسة بهدوء.
ففي مؤتمر I/O 2026، أعلنت الشركة عن Gemini Omni — وهو نموذج متعدد الوسائط يحول تعديل الفيديو إلى شيء اعتقد معظمنا أنه لا يزال بعيدًا بعقد من الزمن: محادثة طبيعية.
الوعد الجوهري: توقف عن "تشغيل" الفيديو. ابدأ بالتحدث إليه.
إليك الفكرة بأكملها في جملة واحدة: أنت لا تُشغل الفيديو بعد الآن — بل تخبره بما تريده.
إعلان Google يوضح الأمر دون تجميل: "كل تعليمية تبني على ما قبلها. تظل شخصياتك ثابتة، وتحافظ الفيزياء على تماسكها، ويتذكر المشهد ما حدث من قبل."
هذا ليس تحديثًا لـ Veo. تقدم صفحة منتج Google DeepMind صياغة أكثر دقة: "فكر في Gemini Omni كأنه Nano Banana، ولكن للفيديو." في العام الماضي، جعلت Nano Banana تعديل الصور سهلاً مثل كتابة ما تريده. والآن، يقوم Omni بالأمر نفسه للصور المتحركة.
النموذج الأول في هذه العائلة — Gemini Omni Flash — متاح بالفعل الآن في تطبيق Gemini وGoogle Flow وYouTube Shorts.
وهذه هي الجملة التي يجب أن تعيد تشكيل نظرتك لهذه الفئة بأكملها: في مقابلة TechCrunch مع فريق DeepMind، وصف مهندس الأبحاث غابي بارث-مارون ما يصنعه الناس باستخدام Omni بأنه "ميكسات مخصصة" (personalized memes).
هذه هي الأطروحة. لقد انتقلت صناعة الفيديو من كونها حرفة إلى مجرد تعبير — وهو نفس التحول الذي شهدته التصوير الفوتوغرافي عندما قضت هواتف iPhone على هيمنة كاميرات DSLR.
العروض التوضيحية التي تجتاح تويتر
يمكنك قراءة مواد التسويق طوال اليوم، لكن ما باع هذا الإطلاق حقًا هي العروض التوضيحية. هناك ثلاثة منها تنتشر في كل مكان الآن:
- نحت الفقاعات: زود Omni بمقطع لمنحوتة حجرية، واكتب "اجعل المنحوتة من الفقاعات"، وسيحافظ العرض التالي على نفس التكوين، ونفس الإضاءة، ونفس الظلال — لكن المنحوتة أصبحت الآن صابونًا شفافًا يعكس الضوء المحيط.
- المرآة السائلة: تلمس يد مرآة؛ ويطلب التلقين من Omni "اجعل المرآة تتموج بجمال كأنها سائلة، وحوّل ذراع الشخص إلى مادة مرآة عاكسة."كما وثق موقع Windows Report، تنتشر التموجات فيزيائيًا إلى الخارج، ويعكس كروم الذراع الغرفة الفعلية.
- التعديلات المتسلسلة: يُظهر عرض عازف الكمان من Google موضوعًا واحدًا عبر ثلاث جولات: مسرح ← بيئة منقولة ← زاوية كاميرا من فوق الكتف. ثلاث تعديلات. شخص واحد. الوجه، والوضعية، وطريقة الإمساك بالآلة — كلها متسقة.

هذا ليس تحويل نص إلى فيديو. إنه تحويل النص إلى تعديل للفيديو الذي تمتلكه بالفعل. قد يبدو الفرق بسيطًا، لكنه يغير كل شيء.
لماذا يفقد صناع المحتوى صوابهم
السبب في أن هذا الإطلاق له صدى أقوى من إطلاقات النماذج الأخرى بسيط: Omni يقضي على أسوأ حلقة مفرغة في توليد الفيديو بالذكاء الاصطناعي.
الحلقة القديمة: توليد ← كره النتيجة ← إعادة كتابة التلقين بالكامل ← انتظار 90 ثانية ← النتيجة لا تزال سيئة ← التكرار.
الحلقة الجديدة: توليد ← "غيّر الإضاءة إلى وقت الغروب" ← تم ← "الآن أبطئ حركة الكاميرا" ← تم.
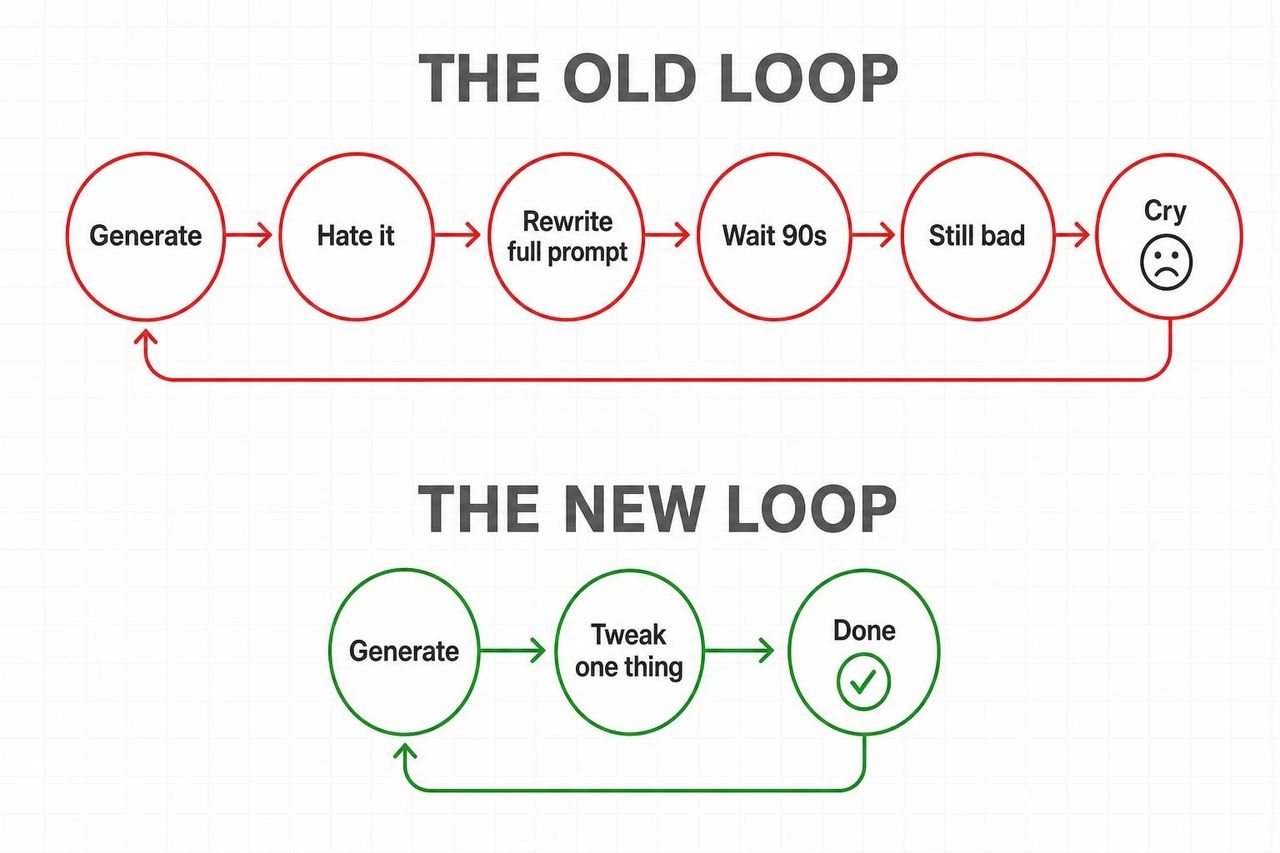
موقع Android Central لم يخفف من حدة الحكم: "يمكن لـ Gemini Omni أن يجعل تطبيقات تعديل الفيديو التقليدية تبدو قديمة." وطرح موقع TechRadar وجهة النظر نفسها بلمسة أكثر دقة، مشيرًا إلى أن الحركة تظل متماسكة عبر التعديلات بدلاً من إعادة التعيين مع كل تلقين جديد.
لقد بدأ المطورون بالفعل في التحرك. ففي منتدى المطورين V2EX، قام مطور صيني باختباره في يوم الإطلاق وكتب: "التعديل القائم على الدردشة للأجسام داخل الفيديو — هذا النوع من التفاعل هو بوضوح الاتجاه المستقبلي. السرعة والاتساق تجاوزا توقعاتي." وعلى منصة X، غرد عالم المناعة ومعلق الذكاء الاصطناعي د. ديريا أونوماز بعد دقائق من العرض الرئيسي: "واو! أطلقت Google DeepMind للتو نموذجًا مذهلاً جديدًا للذكاء الاصطناعي متعدد الوسائط يسمى Gemini Omni. الفيديوهات تبدو جيدة للغاية! يجب تجربته في أسرع وقت ممكن!"
عندما يتفق خبراء الذكاء الاصطناعي على تويتر ومنتديات المطورين الصينية على نفس النقطة في غضون ساعات، فأنت أمام نقطة تحول حقيقية.
حيث تتوخى Google الحذر بهدوء
سيكون من غير المسؤول كتابة رسالة إعجاب دون ذكر التحذيرات.

أشار موقع Engadget إلى المشكلة الكبيرة: "المشكلة الرئيسية في Veo 3.1 وتطبيقات توليد الفيديو الأخرى هي أن الفيديو يتمتع بمظهر 'وادي الغرابة' (Uncanny Valley)، وغالبًا ما يكرهه المستخدمون النهائيون. سيكون من المثير للاهتمام معرفة ما إذا كانت جودة المخرجات ستطابق ادعاءات Google الحماسية."
وقد كشفت اختبارات موقع DataCamp بالفعل عن خلل فيزيائي حقيقي — آلة منجنيق تطلق حمولتها للخلف. وأشار المراجع أيضًا إلى أن النموذج لا يزال يفتقر إلى نتائج معيارية منشورة، لذا فإن التحقق المستقل سيستغرق أسابيع.
هناك أيضًا حذف متعمد: تعديل الخطاب والصوت داخل الفيديوهات الموجودة. وكما اعترفت Google نفسها، فإن الشركة "لا تزال تعمل على اختبار هذا وفهم كيفية تقديم هذه القدرة للمستخدمين بمسؤولية." الترجمة: خطر التزييف العميق حقيقي، وهم يحتفظون بالقدرة الأكثر خطورة خلف الكواليس.
يأتي كل مقطع من Omni مزودًا بعلامة مائية غير مرئية من Google، SynthID، بالإضافة إلى بيانات الاعتماد للمحتوى C2PA — وهي بيانات يمكن التحقق من مصدرها داخل تطبيق Gemini وChrome وSearch. هذا ليس اختياريًا؛ لقد أصبح هذا هو المعيار الأساسي الآن.
ماذا يعني هذا حقًا لسير عملك
إذا جردت الضجيج، فستبقى مع شيء جديد حقًا:
- الأداة هي المحادثة. لا جداول زمنية، لا طبقات، لا إطارات رئيسية. فقط كلمات.
- حلقة التغذية الراجعة تتقلص. ما كان يتطلب 90 ثانية لإعادة التوليد، أصبح يتطلب 10 ثوانٍ من التعديلات.
- الخنادق الاحترافية تضيق. عندما يستطيع أي شخص لديه ذوق فني التكرار على الفيديو بالسرعة التي يكرر بها رسالة على Slack، ينتقل الاختناق من التنفيذ إلى الأفكار.
بالنسبة لفرق التسويق، وصناع المحتوى المستقلين، والمعلمين، وأي شخص سبق له أن احتاج إلى "مجرد مقطع سريع مدته 10 ثوانٍ" — هذه هي نقطة التحول. ليس لأن النموذج مثالي، بل لأن نمط التفاعل أصبح أخيرًا هو الصحيح.
تعديل الفيديو في المستقبل لن يحتاج إلى برمجيات، بل سيحتاج إلى مفردات.
واجهة برمجة تطبيقات موحدة واحدة لإنتاج الفيديو
بينما تطرح Google نموذج Gemini Omni Flash داخل تطبيق Gemini وGoogle Flow للمستخدمين النهائيين، يحتاج المطورون وفرق العمل الذين يرغبون في دمج نفس محرك الفيديو متعدد الوسائط في سير عملهم إلى طبقة واجهة برمجة تطبيقات (API) مستقرة وموثوقة.
توفر Atlas Cloud نموذج Gemini Omni Flash عبر واجهة برمجة تطبيقات موحدة متوافقة مع OpenAI، إلى جانب أكثر من 300 نموذج آخر للصور والفيديو والنماذج اللغوية الكبيرة (LLM) — حتى تتمكن من دمج نموذج Google متعدد الوسائط دون الحاجة إلى التوفيق بين حسابات بائعين متعددين، أو بوابات دفع، أو حزم تطوير برمجية (SDKs) مختلفة.
كلا نسختي Gemini Omni Flash متاحتان الآن على Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| النسخة | الأفضل لـ | المدخلات | الدقة | المدة | السعر الابتدائي |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | التوليد السينمائي المعتمد على التلقين فقط | نص (حتى 20,000 حرف) | 720p / 1080p / 4K | 4، 6، 8، 10 ثوانٍ | $0.2 + $0.1/ثانية |
| Gemini Omni Flash Image-to-Video (Developer) | فيديو متسق الموضوع من مراجع حقيقية | نص + حتى 7 صور مرجعية | 720p / 1080p / 4K | 4، 6، 8، 10 ثوانٍ | $0.2 + $0.1/ثانية |
بداية سريعة — توليد فيديو بواسطة Gemini Omni Flash في 5 أسطر:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
تُرجع واجهة برمجة التطبيقات معرف تنبؤ (prediction ID) على الفور — قم بعمل استطلاع (poll) لـ /api/v1/model/prediction/{id} للحصول على رابط MP4 المنتج. يتوفر المخطط الكامل، ونماذج الأكواد بـ 7 لغات، وملعب (Playground) بدون برمجة في صفحات النماذج المرتبطة أعلاه.
شيء أخير — لأي شخص يبني فعليًا باستخدام هذه الأدوات
إليك الواقع المحرج خلف كل إطلاق نموذج مثل هذا: بحلول الربع القادم، ستصل ثلاثة إعلانات أخرى عن "أفضل نموذج فيديو في العالم". سيكون لكل منها حزمة تطوير (SDK) مختلفة، ومسار مصادقة مختلف، وقواعد مختلفة لمعدلات الاستخدام، ونموذج تسعير مختلف. سيضيع فريقك أسبوعًا في تعلم كل واحد منها، ثم أسبوعًا في إلغاء السابق.
هذه هي المشكلة التي تحلها Atlas Cloud بالضبط.
نحن نمنح المطورين نقطة نهاية واحدة مع إمكانية الوصول إلى أكثر من 300 نموذج — كل نموذج أساسي رئيسي، والإصدارات مفتوحة المصدر الرائدة، والمتخصصون سريعو التطور في مجالات الصور، والفيديو، والاستنتاج. بدّل النماذج بسطر واحد من الكود. قم بإجراء اختبارات المقارنة جنبًا إلى جنب دون الحاجة إلى إعادة دمج حزم SDK. أطلق النموذج الرائج اليوم، وانتقل إلى أي شيء قد يصبح رائجًا في الشهر المقبل — دون إعادة كتابة أي شيء.
لأن الشيء الوحيد المؤكد بشأن الذكاء الاصطناعي الآن هو أن لوحة الصدارة تتغير كل ثلاثاء. ابْنِ على هذا الأساس.






