
مقطع فيديو سينمائي تم إنشاؤه بواسطة الذكاء الاصطناعي — إضاءة رائعة، شخص يمشي في طوكيو ليلاً — وفجأة، في منتصف المقطع، تمر قدمه عبر الرصيف. أو يتوقف المطر فجأة في منتصف المشهد. أو يبدأ كوب قهوة في احتواء نفسه بشكل غريب.
كان الوهم مثالياً لمدة ست ثوانٍ بالضبط، حتى تدخلت قوانين الفيزياء.
على مدى ثلاث سنوات، كان هذا هو الخطأ غير القابل للإصلاح في قلب تقنية الفيديو التوليدي. كانت النماذج قادرة على محاكاة المظهر، لكنها لم تكن قادرة على محاكاة العالم.
في 19 مايو، خلال مؤتمر I/O 2026، قدم نموذج Gemini Omni من Google الحجة بأن هذا الخطأ أصبح أخيراً قابلاً للإصلاح، وقدم للجمهور بهدوء عرضاً تجريبياً واحداً أثبت وجهة نظره بشكل أفضل من أي معيار قياسي.
عرض الرخامة الذي أحدث ضجة في عالم الذكاء الاصطناعي على تويتر
العرض التجريبي: كرة رخامية زجاجية واحدة تتدحرج عبر مسار معقد من التفاعلات المتسلسلة. ترتد عن الأطباق، وتقرع الأجراس، وتنزلق على المنحدرات، وتسقط أحجار الدومينو التي تطيح بأشياء أخرى. كل تلامس له قوة رد فعل منطقية، وكل هبوط له صوت متوافق.
لم تخفِ تغطية 9to5Google دهشتها: "فيديو الكرة الرخامية المتدحرجة هو مثال رائع، مع فيزياء منطقية للكرة وتأثيرات صوتية مقنعة لكل ارتداد ورنين جرس."
قد تبدو هذه الجملة عادية، لكنها في الواقع علامة فارقة في الصناعة.
انتشر العرض التجريبي في غضون ساعات. حتى عمالقة الذكاء الاصطناعي لم يتمكنوا من البقاء صامتين؛ فقد غرد خبير المناعة والمعلق في مجال الذكاء الاصطناعي د. ديريا أونوتماز بعد دقائق فقط من الكلمة الرئيسية: "واو! لقد أطلقت Google DeepMind للتو نموذجاً جديداً ومذهلاً متعدد الوسائط يسمى Gemini Omni. الفيديوهات تبدو جيدة جداً! يجب تجربته في أسرع وقت ممكن!"
لماذا كان "مجرد دحرجة رخامة" أمراً مستحيلاً لثلاث سنوات؟
لفهم سبب استحقاق عرض الرخامة لوصف "علامة فارقة في الصناعة"، يجب أن تنظر إلى ما فشل فيه فيديو الذكاء الاصطناعي منذ عام 2023.
في عصر Sora، كانت الجودة البصرية موجودة بالفعل. كان بإمكان النموذج تقديم مقطع سينمائي بدقة 4K لشخص يمشي في طوكيو ليلاً. ولكن:
- كان الماء في النوافير يتدفق للأعلى.
- كانت الملعقة تمر عبر وعاء الحبوب.
- كانت ساق الشخصية تصبح شفافة لفترة وجيزة في منتصف الخطوة.
- كانت الجاذبية تعمل... في معظم الأوقات.
كانت العناصر البصرية مكتملة بنسبة 90%، لكن نموذج العالم كان مكتملاً بنسبة 50%. وبمجرد أن يلاحظ المشاهد خطأ في الفيزياء، لا يمكنه تجاهله، وينهار الوهم بالكامل.
بالنسبة للمبدعين المحترفين، لم تكن هذه مشكلة تجميلية، بل كانت عقبة أمام الاستخدام العملي. لم يكن بإمكانك تسليم فيديو الذكاء الاصطناعي للعملاء دون فحص إطارات الفيديو يدوياً بحثاً عن أي أخطاء فيزيائية، مما يعني أن معظم فرق المؤسسات تجاهلت هذه الوسيلة تماماً.
تستهدف Google من خلال Omni هذه الفجوة مباشرة. تضع صفحة الإطلاق الرسمية الأمر في جملة واحدة: "يتمتع Omni بفهم بديهي ومحسن لقوى مثل الجاذبية، والطاقة الحركية، وديناميكا الموائع، مما يسمح لك بإنشاء مشاهد أكثر واقعية."
حسبيس يطلق التصريح الجريء
لم يأتِ أكثر الأسطر كشفاً للحقيقة في مؤتمر I/O 2026 من شريحة تسويقية، بل جاء على لسان الرئيس التنفيذي لشركة DeepMind، ديميس حسبيس، على المسرح: حيث وصف Omni بأنه "خطوة نحو الذكاء الاصطناعي العام (AGI)."
وكما أفاد موقع Decrypt، ربط حسبيس صراحةً محاكاة الفيزياء بطموح الذكاء الاصطناعي العام الأوسع، واصفاً Gemini بأنه "ذكاء اصطناعي بنموذج عالمي يمكنه فهم ومحاكاة العالم."
هذا هو الإطار الذي يجب أن يدفع الناس للانتباه. حسبيس لا يدعي أن Omni هو مجرد لعبة فيديو أفضل، بل يقول: إن النموذج الذي يفهم الفيزياء حقاً هو نموذج يمكنه في النهاية التصرف في العالم المادي. وهو بالضبط ما تحتاجه الروبوتات.
زاوية الروبوتات التي لم يلحظها أحد خارج الصين
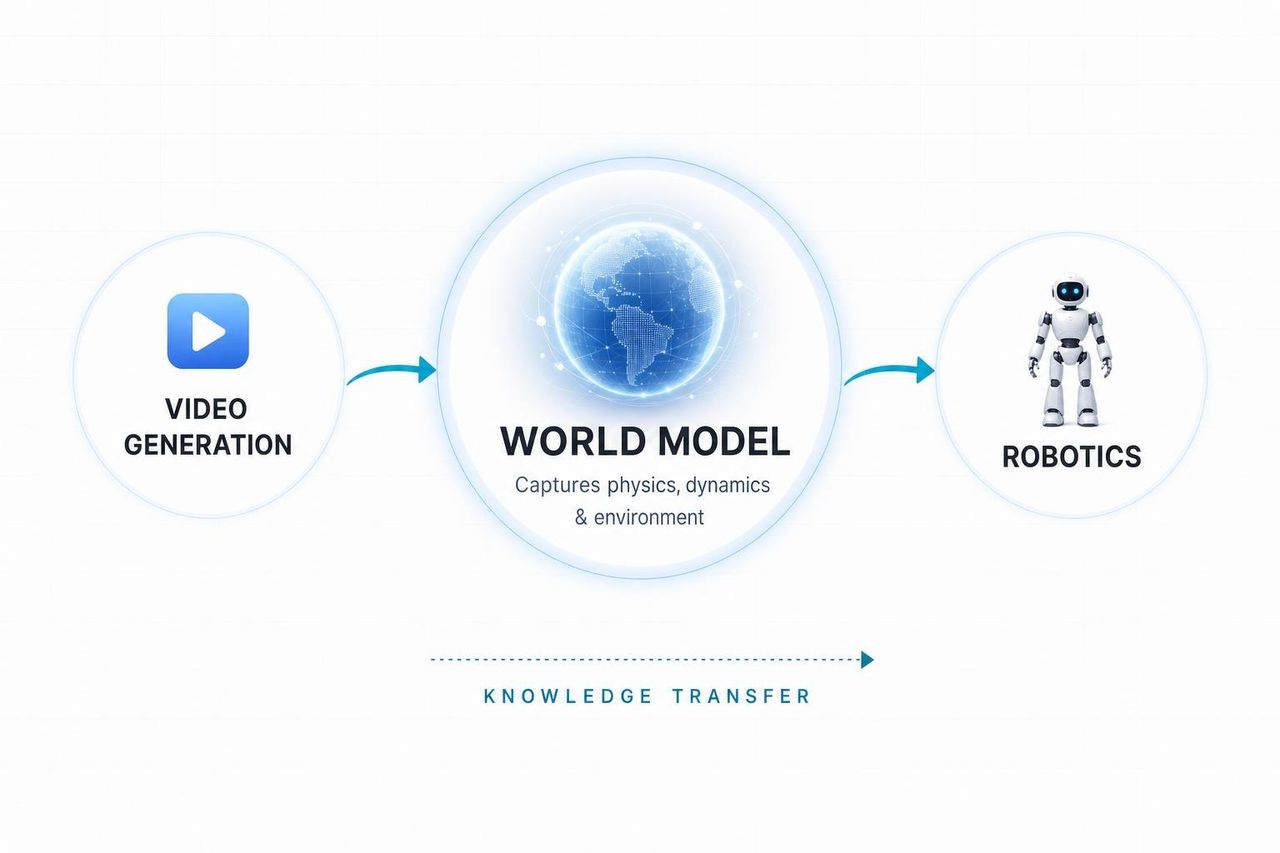
هنا زاوية غفلت عنها معظم التغطيات باللغة الإنجليزية تماماً، لكن الصحافة التقنية الصينية التقطتها أولاً.
وفقاً لـ تقرير Sina Finance نقلاً عن كبير مسؤولي التكنولوجيا في DeepMind كوراي كافوك أوغلو، فإن فهم Omni للفيزياء "تم تطبيقه مباشرة على تدريب الروبوتات المتطورة."
وقد التقط موقع Technobezz نفس الإطار: حيث يحمل Omni "معرفة بالعالم أكثر بكثير من Veo" لأنه يرث بيانات التدريب الأساسية لـ Gemini، والتي تتضمن الآن كميات هائلة من بيانات المحاكاة الفيزيائية.
الترجمة: عرض الرخامة ليس مجرد خدعة للمبدعين، بل هو معاينة عامة للمحاكي الذي تستخدمه Google لتعليم الروبوتات كيفية الإمساك بالأشياء، والرمي، والتوازن، ورد الفعل. نموذج الفيديو هو الجزء المرئي من جبل جليدي أكبر بكثير من "نمذجة العالم" — جبل جليدي يمتد من توليد الفيديو ← إلى الفهم الفيزيائي ← إلى الذكاء الاصطناعي المتجسد.
فجأة، يبدو الرخام المتدحرج مختلفاً. ليس "لقد صنعت Google عرضاً فيزيائياً رائعاً"، بل "لقد أظهرت Google للعالم بهدوء أن خط أنابيب تدريب الروبوتات الخاص بها جاهز للعمل."
الدليل المخفي الذي فات الجميع: عرض السبورة
إليك دليلاً ثانياً على الفيزياء يتم تداوله بهدوء في المنتديات التقنية الصينية.
قبل أيام من مؤتمر I/O 2026، بدأ تداول عرض تجريبي مسرب لـ Omni: أستاذ جامعي يقف أمام سبورة، يكتب إثباتاً كاملاً لهوية مثلثية. وكما ورد في تغطية 36Kr، كانت المعادلة صحيحة رياضياً، والخطوات مرتبة بشكل مترابط، وخط اليد طبيعياً — كل ذلك تم إنشاؤه من مطالبة نصية واحدة باللغة الإنجليزية.
يبدو هذا إنجازاً في عرض النصوص، لكنه في الواقع إنجاز فيزيائي مقنّع.
يتطلب خط اليد الصحيح من الذكاء الاصطناعي نمذجة:
- ميكانيكا حركة اليد لتشكيل كل حرف.
- التسلسل الذي تُكتب به البراهين عادةً.
- الضغط المادي للطبشور على السبورة.
- المنطق الزمني لخطوات الاشتقاق.
في المقابل، أنتج Sora نصاً على السبورة، وبكلمات مقال 36Kr، "بدا كأنه كتابة، ولكن عند الفحص الدقيق كان مجرد هلوسات لا معنى لها."
نفس القدرة الأساسية — الاتساق الفيزيائي والزمني — تم تطبيقها على مجال مختلف. الرخامة ترتد بشكل صحيح، والطبشور يلمس السبورة بشكل صحيح. كلاهما يمثل نفس نموذج العالم الذي يظهر في اختبارات سطحية مختلفة.
لكن دعونا لا نتسرع في التتويج
سيكون من غير المسؤول كتابة رسالة حب دون إضافة ملاحظات.
وقد رصدت المراجعة العملية لـ DataCamp نموذج Omni وهو يرتكب أخطاء فيزيائية. طلب المراجع إطلاق "منجنيق" — فطار المقذوف للخلف. كان الخطأ حقيقياً، لكنه كان مضحكاً أكثر منه مأساوياً لأن المراجع اختار نمطاً بصرياً يشبه المنسوجات، فبدت العيوب وكأنها فن من العصور الوسطى.
وقد انتقد موقع Engadget التغطية المتحمسة: "المشكلة الرئيسية في Veo 3.1 وتطبيقات توليد الفيديو الأخرى هي أن الفيديو يبدو وكأنه من 'وادي الغرابة'، وغالباً ما يكرهه المستخدمون النهائيون. سيكون من المثير للاهتمام معرفة ما إذا كانت جودة المخرجات تطابق ادعاءات Google المتحمسة."
ثلاث حقائق إضافية:
- لم يتم نشر أي معايير قياسية. لم تُصدر Google تقييمات رقمية مع الإطلاق. لن تظهر معايير الطرف الثالث المستقلة قبل عدة أسابيع.
- حد 10 ثوانٍ للمقطع. وفقاً لمقابلة TechCrunch مع DeepMind، يقتصر Omni Flash حالياً على مخرجات مدتها 10 ثوانٍ. القادم سيكون بمدد أطول، ولكن حالياً، هذا النطاق مخصص للفيديوهات القصيرة.
- تحرير الصوت/الكلام مؤجل.اعترفت Google نفسها بأن الشركة "لا تزال تعمل على اختبار هذا وفهم كيفية تقديم هذه القدرة للمستخدمين بمسؤولية" — أي أن خطر التزييف العميق في تحرير الصوت حقيقي، ولا تقوم Google بطرح هذه القدرة حالياً.
يأتي كل مقطع من Omni مزوداً بـ علامة SynthID المائية الخفية من Google بالإضافة إلى بيانات اعتماد المحتوى C2PA، والتي يمكن التحقق منها في تطبيق Gemini وChrome وSearch. وتجدر الإشارة إلى أنه مع زيادة واقعية الفيزياء، تزداد الحاجة إلى المصدر الموثق (Provenance) تشفيرياً، لا تنقص. فكلما بدا التزييف أفضل، زادت حاجتنا لمعرفة أنه تزييف.
مقارنة Omni بـ Sora وVeo وSeedance في الفيزياء
إليك كيف تقف نماذج الفيديو الرائدة في الذكاء الاصطناعي من حيث الفيزياء وفهم العالم اعتباراً من مايو 2026:
| النموذج | واقعية الفيزياء | المعرفة بالعالم | التحرير الحواري | الحالة |
|---|---|---|---|---|
| Gemini Omni Flash | الرائد الجديد (ادعاء) | الأفضل — يرث تدريب Gemini | نعم، متعدد الجولات | متاح منذ |






