
إذا كنت تقيم النماذج مفتوحة المصدر (open-source) لأغراض البرمجة، أو الاستدلال المنطقي، أو خطوط أنابيب الوكلاء (agentic pipelines)، فستجد كلاً من Kimi K2.6 وGLM 5.1 ضمن قائمة خياراتك. كلاهما يأتي من مختبرات ذكاء اصطناعي صينية رائدة، وكلاهما يعمل مع واجهات برمجة تطبيقات متوافقة مع OpenAI، وكلاهما يتمتع بقدرات عالية في المهام المعقدة التي يهتم بها المطورون فعلياً.
المشكلة هي أنهما ليسا متطابقين؛ إذ يمتلك كل منهما نافذة سياق مختلفة، وهياكل تكلفة متفاوتة، ونقاط قوة تبرز في حالات استخدام معينة. اختيار النموذج الخاطئ لحجم عملك يعني إما إهدار الأداء أو دفع مبالغ إضافية مقابل سعة لا تحتاجها.
تستعرض هذه المقالة الفروقات الحقيقية بين النموذجين: ماذا تعني المواصفات عملياً، أين يتفوق كل نموذج وأين يعجز، وكيف تبدو الأرقام عند التشغيل على نطاق واسع.

Kimi K2.6 مقابل GLM 5.1: ملخص سريع
يعد Kimi K2.6 أحدث نموذج من شركة Moonshot AI ضمن سلسلة K2، والتي تمثل خط إنتاجهم الرئيسي حالياً. Moonshot هي الشركة المطورة لمساعد Kimi، ويراهن نموذج K2.6 على الاستدلال طويل السياق والتسعير التنافسي. وتعد نافذة السياق البالغة 262 ألف رمز (token) إحدى أبرز ميزاته.
أما GLM 5.1 فيأتي من Zhipu AI، وهي واحدة من أكثر مؤسسات أبحاث الذكاء الاصطناعي رسوخاً في الصين. تطورت سلسلة GLM (نموذج اللغة العام) عبر عدة أجيال، ويعد 5.1 العرض الأقوى حالياً لدى Zhipu. ويتمتع بسمعة قوية في مجتمع المصادر المفتوحة بفضل دقة اتباع التعليمات وجودة المخرجات المهيكلة.
يوفر كلا النموذجين واجهة برمجة تطبيقات متوافقة مع OpenAI، مما يجعل ربطهما بأدوات مثل Claude Code أو Codex أو OpenClaw أمراً بسيطاً. يتلخص الاختيار بينهما في ثلاثة عوامل حقيقية: مقدار السياق الذي تحتاجه لكل طلب، تكاليف الرموز (tokens) بناءً على حجم الاستخدام المتوقع، وما إذا كانت مهامك تميل نحو نقاط القوة النسبية لأي منهما.
النماذج خلف الأسماء
مقارنة نوافذ السياق: Kimi K2.6 مقابل GLM 5.1
تعد نافذة السياق واحدة من أوضح الفوارق الموضوعية هنا. يدعم Kimi K2.6 نافذة سياق بحجم 262 ألف رمز، بينما يدعم GLM 5.1 سعة 200 ألف رمز، وهو فارق بنسبة 31% في سعة الإدخال القصوى.
بالنسبة لمهام البرمجة العادية، لا يصل أي من النموذجين إلى هذه الحدود بشكل يومي. فمراجعة الكود القياسية، أو جلسات تصحيح الأخطاء، أو طلبات إنشاء التوثيق ستناسب كلا النافذتين براحة. يصبح هذا الفارق ذا أهمية في سيناريوهات محددة:
- تحليل قواعد الأكواد الضخمة: تمرير عشرات الآلاف من الأسطر في طلب واحد لإعادة الهيكلة أو مراجعة بنية البرنامج.
- جلسات الوكلاء الطويلة: المحادثات التي تتراكم فيها كمية كبيرة من السياق عبر عدة خطوات واستدعاءات للأدوات.
- خطوط الأنابيب المعتمدة على الوثائق: مهام البحث، أو التلخيص، أو التحليل التي تتطلب أجزاءً نصية كبيرة في استدعاء واحد.
إذا كان حجم عملك يقترب بانتظام من حدود السياق مع النماذج الأخرى، فإن نافذة Kimi K2.6 البالغة 262 ألف رمز تمنحك مساحة إضافية قبل أن تضطر إلى تنفيذ منطق لتقسيم النصوص (chunking) أو تلخيص السياق. أما إذا كانت طلباتك المعتادة أقل من 50 ألف رمز، فكلا النموذجين يوفران سعة أكثر من كافية، ويصبح الفرق في نافذة السياق عاملاً غير مؤثر.

نقاط القوة في البرمجة والاستدلال
كلا النموذجين قادران على تنفيذ مهام البرمجة، على الرغم من أن أولويات التصميم الخاصة بهما تخلق سلوكيات مختلفة في الممارسة العملية.
صُمم Kimi K2.6 من أجل فهم السياق الطويل، مما يجعله مناسباً جداً لإعادة هيكلة ملفات متعددة، وفهم كيفية تأثير التغييرات في جزء من قاعدة الكود على الأجزاء الأخرى، وسلاسل الاستدلال الممتدة حيث يحتاج النموذج إلى الاحتفاظ بالكثير من الحالة عبر خطوات عديدة. وقد ركزت Moonshot AI على نموذج K2.6 خصيصاً لهذه الاستخدامات.
بينما يحمل GLM 5.1 تركيز Zhipu AI على اتباع التعليمات بدقة وإخراج المخرجات المهيكلة. المهام مثل إنشاء كود بناءً على مواصفات تفصيلية، أو إنتاج تنسيقات مهيكلة من لغة طبيعية، أو إدارة مخططات استدعاء أدوات معقدة، كلها تبرز نقاط قوته. كما أن معدل الإخراج الأعلى قليلاً في تسعيره (7.99 مقابل 7.26) يشير إلى ميل النموذج نحو إكمال المهام بشكل أكثر شمولاً وتفصيلاً.
بالنسبة لمعظم المطورين الذين يقارنون بين هذين النموذجين، فإن فرق الأداء في مهام البرمجة العادية أصغر مما قد تتوقعه من اختلاف العلامة التجارية. الفوارق الأكثر وضوحاً تكمن في المواصفات والتكلفة، حيث تكون الأرقام ملموسة.
Kimi K2.6 مقابل GLM 5.1: تكاليف الرموز ومعدلات الرصيد
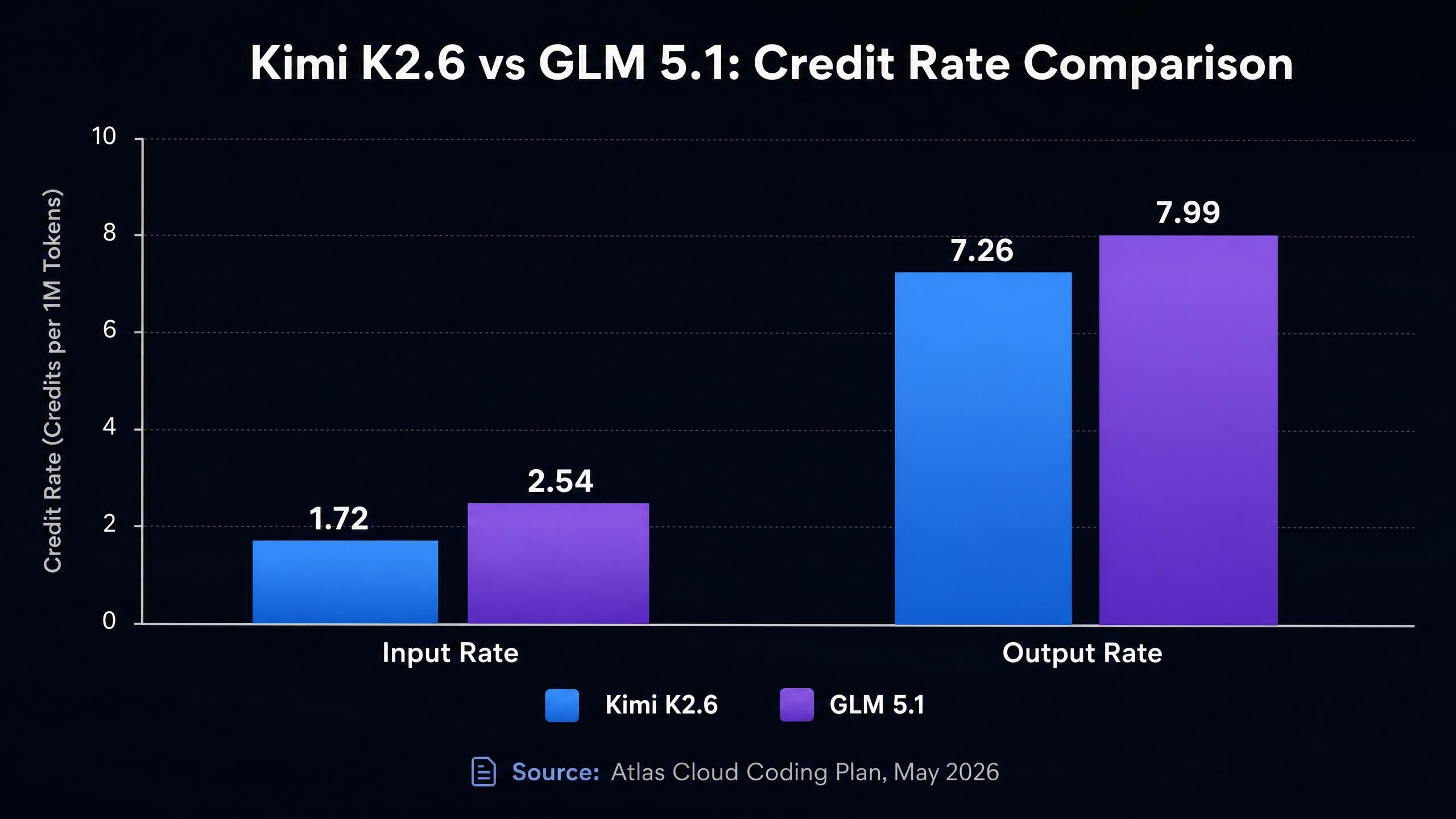
هنا يصبح للمقارنة أبعاد دقيقة. كلا النموذجين متاحان عبر باقة البرمجة من Atlas Cloud، ومعدلات الرصيد كالتالي (باقة البرمجة من Atlas Cloud، مايو 2026):
| النموذج | السياق | معدل الإدخال | معدل الإخراج | الكتابة في الذاكرة المؤقتة | مقارنة بالسعر الرسمي |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | أرخص بنسبة 45% |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | أرخص بنسبة 45% |
هناك بضعة أمور تستحق الملاحظة:
معدل إدخال GLM 5.1 (2.54) أعلى بنحو 48% من معدل Kimi K2.6 (1.72). في سياقات البرمجة حيث تمرر محتويات ملفات، أو سجلات كود ضخمة، أو محادثات طويلة، غالباً ما تشكل رموز الإدخال الجزء الأكبر من تكلفتك. خط أنابيب يقوم بـ 1000 طلب يومياً مع 10 آلاف رمز إدخال لكل طلب سيكلف حوالي 48% أكثر في الإدخال فقط مع GLM 5.1 مقارنة بـ Kimi K2.6.
أما معدلات الإخراج فهي أكثر تقارباً لكنها تظل في صالح Kimi K2.6 (7.26 مقابل 7.99، أي بفارق 10%). ومعدلات الكتابة في الذاكرة المؤقتة (cache write) تصب أيضاً في صالح Kimi K2.6 (0.290 مقابل 0.472)، وهو ما يتراكم في سير العمل الذي يستخدم ذاكرة التخزين المؤقت للمطالبات (prompt caching) للمطالبات النظامية المتكررة أو السياق الساكن.
بدمج هذه الأرقام: لطلب يحتوي على 5000 رمز إدخال و1000 رمز إخراج، ستكون تكاليف الرصيد كالتالي:
- Kimi K2.6: (5000 × 1.72) + (1000 × 7.26) = 8600 + 7260 = 15860 رصيد
- GLM 5.1: (5000 × 2.54) + (1000 × 7.99) = 12700 + 7990 = 20690 رصيد
نموذج Kimi K2.6 أرخص بحوالي 23% لكل طلب وفقاً لنسبة الإدخال/الإخراج هذه. عند التعامل بأحجام كبيرة، يتراكم هذا الفرق ليصبح فرقاً حقيقياً في الميزانية.
كلا النموذجين مسعران بأقل من 45% عن أسعار واجهة برمجة التطبيقات الرسمية الخاصة بهما عبر البوابة، وهو أمر ثابت في هذه الفئة من النماذج.
Kimi K2.6 مقابل GLM 5.1 في سير عمل البرمجة المعتمد على الوكلاء
تعمل الأدوات المعتمدة على الوكلاء (agentic tools) على تضخيم كل فرق في التكلفة والقدرة بين النماذج.
في وكيل برمجة متعدد الخطوات، يعتبر كل استدعاء للأداة طلباً منفصلاً لواجهة برمجة التطبيقات. يحمل كل طلب سياق إدخال من المحادثة المتراكمة، ويولد مخرجاً يغذي الخطوة التالية، ويضيف إلى إجمالي فاتورة الحوسبة الخاصة بك. سير العمل الذي يقوم بـ 40 استدعاء لواجهة برمجة التطبيقات في جلسة واحدة لا يكلف فقط 40 ضعف سعر الطلب الفردي؛ بل إنه يراكم السياق بسرعة، مما يدفع الطلبات نحو أعداد أكبر من رموز الإدخال مع تقدم الجلسة.
أين يميل Kimi K2.6 إلى التفوق في عمل الوكلاء: الجلسات الطويلة حيث ينمو السياق المتراكم بشكل كبير، المهام التي تتضمن قراءة وتعديل ملفات كود كبيرة، وخطوط الأنابيب التي تهم فيها المحافظة على تكاليف معقولة عبر العديد من الاستدعاءات. كما أن نافذة السياق الأكبر تعني عدداً أقل من عمليات إعادة ضبط الجلسة، مما يقلل من تشويش ذاكرة العمل الخاصة بالوكيل.
أين يميل GLM 5.1 إلى الأداء الأفضل: خطوط الأنابيب التي تتطلب فيها كل خطوة مخرجات دقيقة ومهيكلة بشكل جيد، وحيث تكون دقة التعليمات في كل استدعاء فردي أكثر أهمية من عمق السياق عبر الجلسة. إذا كان وكيلك يحتاج إلى إنشاء كود بناءً على مخططات أنواع صارمة (type schemas)، أو إدارة توقيعات دوال معقدة، أو إنتاج مخرجات مهيكلة متسقة في كل مرة، فإن نقاط قوة GLM 5.1 في اتباع التعليمات تكون أكثر صلة مباشرة.
يعمل كلا النموذجين بسلاسة مع Claude Code وCodex وOpenClaw وCursor من خلال إعدادات قياسية متوافقة مع OpenAI. التكامل متطابق بينهما، ولا يتغير سوى معرف النموذج (model ID).
كيف تشغل النموذجين وتختار ما يعمل فعلياً لأجلك
Kimi K2.6 مقابل GLM 5.1: اختيار النموذج المناسب دون تخمين
الطريقة الأكثر موثوقية للقرار بين هذين النموذجين ليست قراءة مقالات المقارنة (بما في ذلك هذه المقالة)، بل تشغيل كليهما على مهامك الفعلية ومقارنة جودة المخرجات بنفسك. الخبر السار هو أن هذا سهل التنفيذ عندما يجلس كلا النموذجين خلف نفس مفتاح واجهة برمجة التطبيقات وعنوان URL الأساسي.
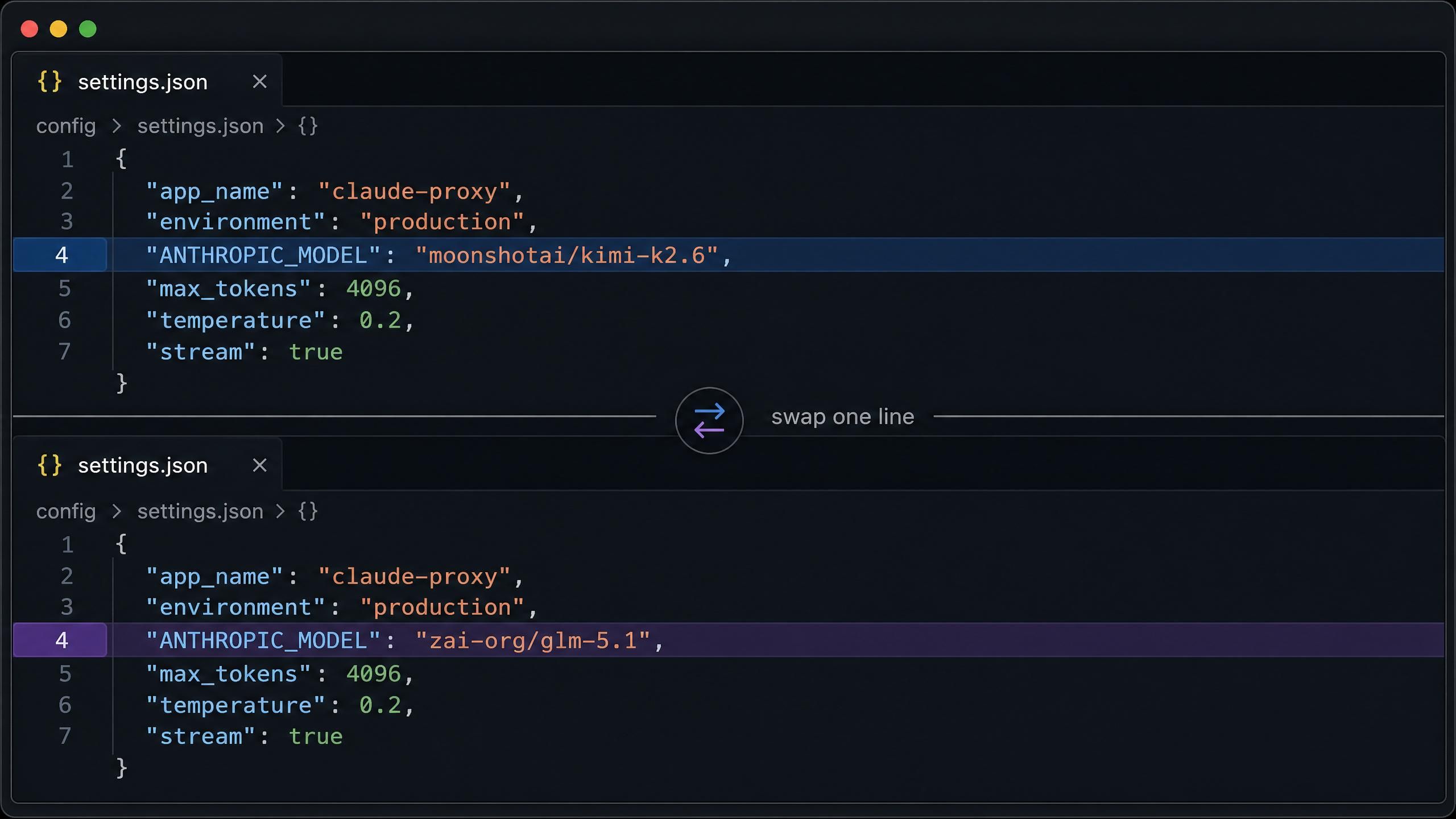
باقة البرمجة من Atlas Cloud تضع Kimi K2.6 وGLM 5.1 على نفس نقطة النهاية (endpoint) تحت مفتاح API واحد. التبديل بينهما هو مجرد تغيير سطر واحد في الإعدادات، مما يعني أنه يمكنك تشغيل سير عملك الحقيقي على كلا النموذجين واحداً تلو الآخر دون إعادة بناء أي تكامل.
بالنسبة لـ Claude Code على macOS أو Linux، يتم وضع الإعداد الكامل في ~/.claude/settings.json. اضبطه على Kimi K2.6 أولاً:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
للتبديل إلى GLM 5.1، قم بتغيير moonshotai/kimi-k2.6 إلى zai-org/glm-5.1 في حقول النموذج الثلاثة. كل شيء آخر يبقى كما هو. لاحظ أن عنوان URL الأساسي لـ Claude Code هو https://api.atlascloud.ai بدون لاحقة /v1.
بالنسبة لـ Codex، ينقسم الإعداد إلى ملفين. ~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
بالنسبة لـ OpenClaw، قم بتشغيل openclaw onboard واختر QuickStart ثم Custom Provider. أدخل https://api.atlascloud.ai/v1 كعنوان URL أساسي، والصق مفتاح Atlas الخاص بك، وحدد معرف النموذج الذي تريد اختباره.
تأتي باقة Atlas Cloud في شكلين: اشتراك شهري مع تحديث يومي للرصيد (الأفضل للاستخدام اليومي الثابت) وباقة الدفع حسب الاستخدام مع نافذة صلاحية لمدة 90 يوماً (أفضل لأحجام العمل المتغيرة أو التجريبية). بما أنك على الأرجح ستختبر كلا النموذجين، فإن خيار الدفع حسب الاستخدام يمنحك المرونة دون الالتزام بحجم شهري.
Kimi K2.6 مقابل GLM 5.1: الإجابة على الأسئلة الشائعة
أي نموذج يكلف أقل عند التشغيل على نطاق واسع؟ نموذج Kimi K2.6 أرخص لكل رمز في كل من الإدخال والإخراج. الفارق أكبر في الإدخال (معدل إدخال GLM 5.1 أعلى بنحو 48%)، وهو ما يهم أكثر في سير عمل البرمجة الذي يرسل كميات كبيرة من السياق. عند أحجام الطلبات الكبيرة، يتراكم هذا ليصبح فرقاً ملموساً في الميزانية.
أي نموذج يتعامل مع مهام اللغة الصينية بشكل أفضل؟ كلا النموذجين يتمتعان بقدرات قوية في اللغة الصينية، وهو أمر متوقع بالنظر إلى أصولهما. يتمتع GLM 5.1 من Zhipu AI بسجل حافل بشكل خاص في مهام اللغة الصينية، تم بناؤه عبر أجيال متعددة من سلسلة GLM. كما يتعامل Kimi K2.6 مع الصينية بشكل جيد بالنظر إلى تركيز Moonshot AI على المستخدمين الصينيين. بالنسبة للمهام ذات الأولوية الصينية، كلاهما قوي، مع تفوق طفيف لـ GLM 5.1 بناءً على سجله.
هل يمكنني خلط كلا النموذجين في نفس خط الأنابيب؟ نعم. من خلال بوابة موحدة، يمكنك توجيه خطوات مختلفة في نفس خط الأنابيب إلى نماذج مختلفة عن طريق تغيير معلمة النموذج فقط لكل طلب. قد تستخدم Kimi K2.6 لخطوات التحليل كثيفة السياق (تكلفة إدخال أقل، نافذة أكبر) وGLM 5.1 لخطوات إنشاء المخرجات المهيكلة (اتباع تعليمات أقوى)، كل ذلك باستخدام مفتاح API واحد.
هل فارق السياق 262K مقابل 200K يستحق الاهتمام؟ لمعظم مهام البرمجة اليومية، لا. كلتا النافذتين كبيرتان بما يكفي للطلبات النموذجية. يهم الفرق إذا كانت جلساتك تتراكم بانتظام بين 150-200 ألف رمز، أو إذا كنت تمرر ملفات كود كبيرة للتحليل، أو إذا كنت تدير جلسات وكلاء طويلة دون إعادة ضبط. إذا كنت نادراً ما تصل إلى 50 ألف رمز لكل طلب، فإنه ليس عاملاً حاسماً.
هل تحتاج هذه النماذج إلى إعداد خاص للعمل مع Claude Code؟ لا يوجد إعداد خاص يتجاوز ما هو موضح أعلاه. يقرأ Claude Code إعدادات النموذج الخاصة به من ~/.claude/settings.json وطالما قمت بتوجيهه إلى بوابة توفر هذه النماذج بتنسيق متوافق مع OpenAI، فإنه يتصل بوضوح. الشيء الوحيد الذي يجب مراقبته هو تنسيق عنوان URL الأساسي لـ Claude Code تحديداً: فهو يستخدم https://api.atlascloud.ai بدون /v1 على عكس معظم الأدوات الأخرى.
الحكم النهائي: Kimi K2.6 مقابل GLM 5.1
الاختيار بين هذين النموذجين يتعلق بمدى ملاءمة حجم العمل أكثر من كونه انتصاراً ساحقاً لأحدهما.
يعد Kimi K2.6 الخيار الافتراضي الأكثر فعالية من حيث التكلفة. إنه أرخص لكل رمز، ويتعامل مع سياق أكثر لكل طلب، ومناسب جداً لأنواع المهام ذات المدخلات الكبيرة والسياق الطويل التي تولدها وكلاء البرمجة. إذا كنت تحسن التكلفة على نطاق واسع أو تعمل بانتظام مع قواعد كود كبيرة، فهو الخيار الأقوى بناءً على الأرقام.
يكسب GLM 5.1 سعره الأعلى قليلاً في المهام التي تتطلب اتباع تعليمات دقيقة ومخرجات مهيكلة متسقة. إذا كان خط أنابيبك أقل كثافة في السياق ولكنه يتطلب دقة عالية في كل خطوة إنشاء فردية، فإنه يستحق الاختبار مقابل نوع مهمتك المحدد.
النهج العملي: ابدأ بـ Kimi K2.6 لميزة التكلفة ونافذة السياق الأكبر، وقم بتشغيل سير عملك الحقيقي من خلاله، ثم قارن أداء GLM 5.1 على نفس المهام إذا كانت لديك أسئلة حول جودة المخرجات المهيكلة. مع وجود كلا النموذجين خلف نفس مفتاح API على باقة البرمجة من Atlas Cloud بخصم 45% عن الأسعار الرسمية، فإن تكلفة المقارنة منخفضة بما يكفي للسماح للأداء الفعلي بتوجيه القرار.
مواصفات النماذج ومعدلات الرصيد تستند إلى وثائق باقة البرمجة من Atlas Cloud اعتباراً من مايو 2026. تعكس قدرات النماذج المعلومات المتاحة للجمهور من Moonshot AI وZhipu AI. الأسعار قابلة للتغيير؛ يرجى التحقق من الأرقام الحالية مباشرة مع كل مزود.






