يُعد Google Gemini Omni نموذج ذكاء اصطناعي شامل (all-in-one) من تطوير Google DeepMind، تم الكشف عنه في مؤتمر Google I/O بتاريخ 19 مايو 2026. وأهم إنجازاته هو تعدد الوسائط الأصلي (native multimodality)، مما يعني قدرته على معالجة وإنشاء النصوص والصور والأصوات ومقاطع الفيديو ضمن نظام واحد، بدلاً من الربط بين أدوات منفصلة. صُمم هذا النموذج لصناع المحتوى والمطورين والشركات التي ترغب في إنشاء وتحرير الفيديوهات عبر محادثات بسيطة دون الحاجة لتبديل التطبيقات.
تبدأ نظرة عامة على ميزات Gemini Omni بفكرة واحدة: أنشئ أي شيء من أي مدخلات. وعلى عكس أدوات تحويل النص إلى فيديو (text-to-video AI) المستقلة، يجمع Gemini Omni بين قدرات الاستنتاج في Gemini وتقنيات معالجة الوسائط المتقدمة في تمريرة واحدة.
لمحة سريعة على القدرات الرئيسية
| الميزة | التفاصيل |
|---|---|
| المدخلات المقبولة | نصوص، صور، صوت، فيديو |
| المخرجات الأساسية | فيديو (قريباً ستتوفر الصور والصوت) |
| أسلوب التحرير | محادثي، مطالبات (prompts) متعددة الجولات |
| النموذج الأول | Gemini Omni Flash |
| التوفر | مشتركو Google AI Plus وPro وUltra |
طرق الوصول إليه
- تطبيق Gemini — متاح لمشتركي AI Plus/Pro/Ultra عالمياً
- Google Flow — لسير عمل الأفلام القصيرة المتكامل
- YouTube Shorts / YouTube Create — لإنشاء المحتوى القصير
- Developer API — سيتم إطلاقه خلال أسابيع
ما هو Google Gemini Omni وكيف يعمل؟
يُعد Google Gemini Omni قفزة نوعية كبرى؛ فهو النموذج الإبداعي الرئيسي والشامل من Google DeepMind. تم الكشف عنه في مؤتمر Google I/O 2026، حيث يستقبل النصوص والصور والأصوات والفيديوهات في آن واحد لإنتاج محتوى فيديو عالي الجودة. وهو يحل رسمياً محل Veo داخل منظومة Gemini.
المحرك الأساسي: شرح تعدد الوسائط الأصلي
اعتمدت معظم أدوات الذكاء الاصطناعي للفيديو السابقة على مسار تسلسلي: تحويل المدخلات إلى أوصاف نصية، ثم تمرير تلك الأوصاف إلى محرك عرض فيديو منفصل. لكن Gemini Omni يعمل بشكل مختلف؛ فهو مبني على نموذج متعدد الوسائط أصلي يعالج جميع أنواع الوسائط في وقت واحد ضمن محرك أساسي واحد بدلاً من توجيهها عبر خطوات معزولة.
تكمن أهمية ذلك في أن تجاوز طبقات التحويل يتيح للنموذج الاحتفاظ بسياق أكثر ثراءً. فعند تزويده بصورة مرجعية مع مطالبة نصية، يقوم Omni بالاستنتاج من كليهما معاً، مما يحافظ على التفاصيل البصرية التي عادةً ما تضيع في خطوة التحويل النصي.
كيف تبدو مدخلات Gemini Omni متعددة الوسائط في الواقع؟
يدعم Gemini Omni هذه التوليفات في مطالبة واحدة:
| نوع المدخلات | مثال على الاستخدام |
|---|---|
| نص فقط | وصف مشهد من الصفر |
| صورة + نص | تحريك صورة ثابتة بناءً على توجيه مكتوب |
| فيديو + نص | تحرير مقطع موجود بشكل محادثي |
| صوت + نص | توجيه النبرة بجانب مطالبة بصرية |
| مختلط (الكل) | دمج مقاطع مرجعية، صور نمطية، وتعليق صوتي |
المعالجة الفورية والتحكم عبر المحادثة
بما أن الاستنتاج يحدث داخل نموذج واحد، تصبح المعالجة الفورية (real-time processing) لتعليمات التحرير عملية وفعالة. يقوم Omni بتحسين المخرجات عبر محادثة متعددة الجولات؛ حيث يمكنك تبديل الخلفية، أو ضبط الإضاءة، أو تثبيت لقطة بمجرد وصف التغيير، دون الحاجة لإعادة كتابة المطالبة من الصفر.
وصفت نيكول بريتشوفا من Google DeepMind هذا النموذج بأنه "أكثر من مجرد تحديث لـ Veo"، حيث تم دمج قدرات الاستنتاج في Gemini مع عرض الوسائط في نظام واحد متماسك.
تحرير الفيديو بالذكاء الاصطناعي عبر المحادثة: كيفية استخدام Gemini Omni لتعديل الأصول المتقدمة
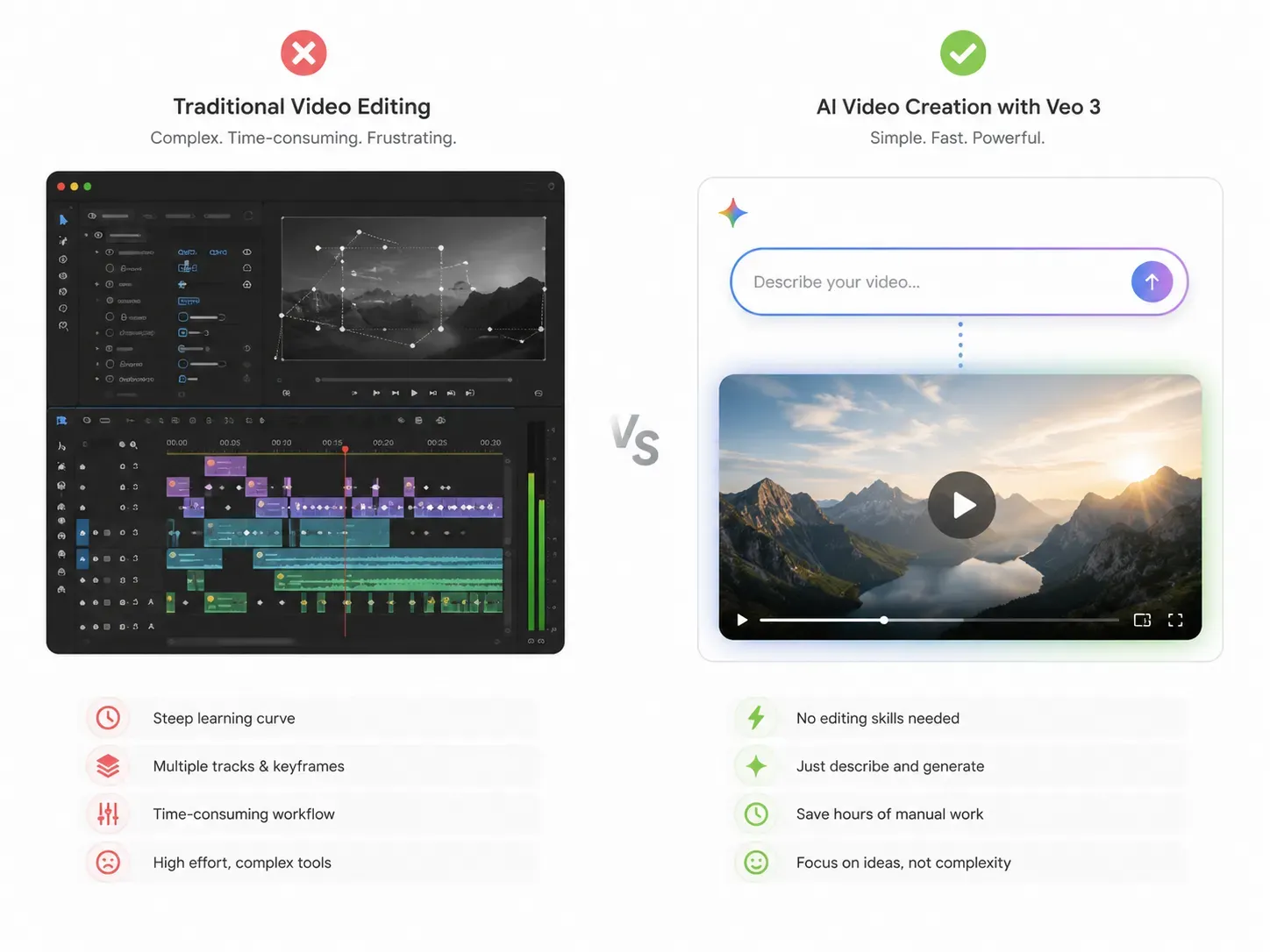
فهم البنية شيء، ووضعها قيد التنفيذ شيء آخر. وهنا تبرز قدرة Gemini Omni على تحرير الفيديو عبر المحادثة لتميزه عن الأدوات التقليدية.
تتطلب برامج تحرير الفيديو التقليدية جداول زمنية (timelines) وطبقات وتحريكاً يدوياً (keyframing). بينما يستبدل Gemini Omni ذلك المسار بالكامل؛ قم برفع لقطاتك، واكتب أو انطق ما تريد تغييره، وسيقوم النموذج بإعادة عرض المقطع. لا إضافات ولا برامج خارجية.
هل يمكن لـ Gemini Omni التعامل مع استبدال عناصر الفيديو المعقدة؟
نعم، وهذه إحدى أكثر ميزاته عمليةً. وفقاً للوثائق الرسمية لـ Google، تتضمن مهام تعديل أصول الفيديو المدعومة:
- تبديل الخلفيات: استبدل البيئة خلف الشخصية مع الحفاظ على الشخصية ذاتها.
- تغييرات الملابس والأسلوب: تعديل الملابس أو نقل نمط بصري عبر المقطع.
- استبدال الكائنات: تبديل عنصر معين في المشهد أثناء اللقطة.
- ضبط الإضاءة: تغيير الحالة المزاجية أو شدة إضاءة المشهد عبر تعليمات بسيطة.
- تثبيت الفيديو: تنعيم اللقطات المهتزة من خلال مطالبة لغوية بسيطة.
- تبديل الشخصيات: استبدال شخص بآخر باستخدام صورة مرجعية.
تحرير الفيديو التفاعلي عبر المحادثات متعددة الجولات
ما يجعل هذا التحرير "تفاعلياً" بدلاً من كونه توليداً لمرة واحدة هو حلقة المحادثة متعددة الجولات. تبني كل تعليمة تحرير على سابقتها، مما يحافظ على تماسك المشهد (نفس الخلفية، ومنطق الإضاءة، وهوية الشخصية) عبر جولات التحسين المتتالية.
على سبيل المثال، يمكن لصانع المحتوى أن يطلب: "استبدل الخلفية بشارع في المدينة"، ثم يتبعها بـ "اجعل الإضاءة أكثر دفئاً"، وأخيراً "ثبّت اللقطة" — كل ذلك دون إعادة بدء التوليد.
استبدال عناصر الفيديو بالذكاء الاصطناعي: ماذا تتوقع الآن؟
يستهدف استبدال عناصر الفيديو في نموذج Gemini Omni Flash الحالي مقاطع مدتها 10 ثوانٍ. ومن المخطط إطلاق تعديلات أكثر تعقيداً عبر تنسيقات أطول، بالإضافة إلى أنواع مخرجات إضافية كصور مستقلة وملفات صوتية في إصدارات مستقبلية.
أتقن حلقة المحادثة متعددة الجولات: دليل مطالبة عملي لـ Gemini Omni
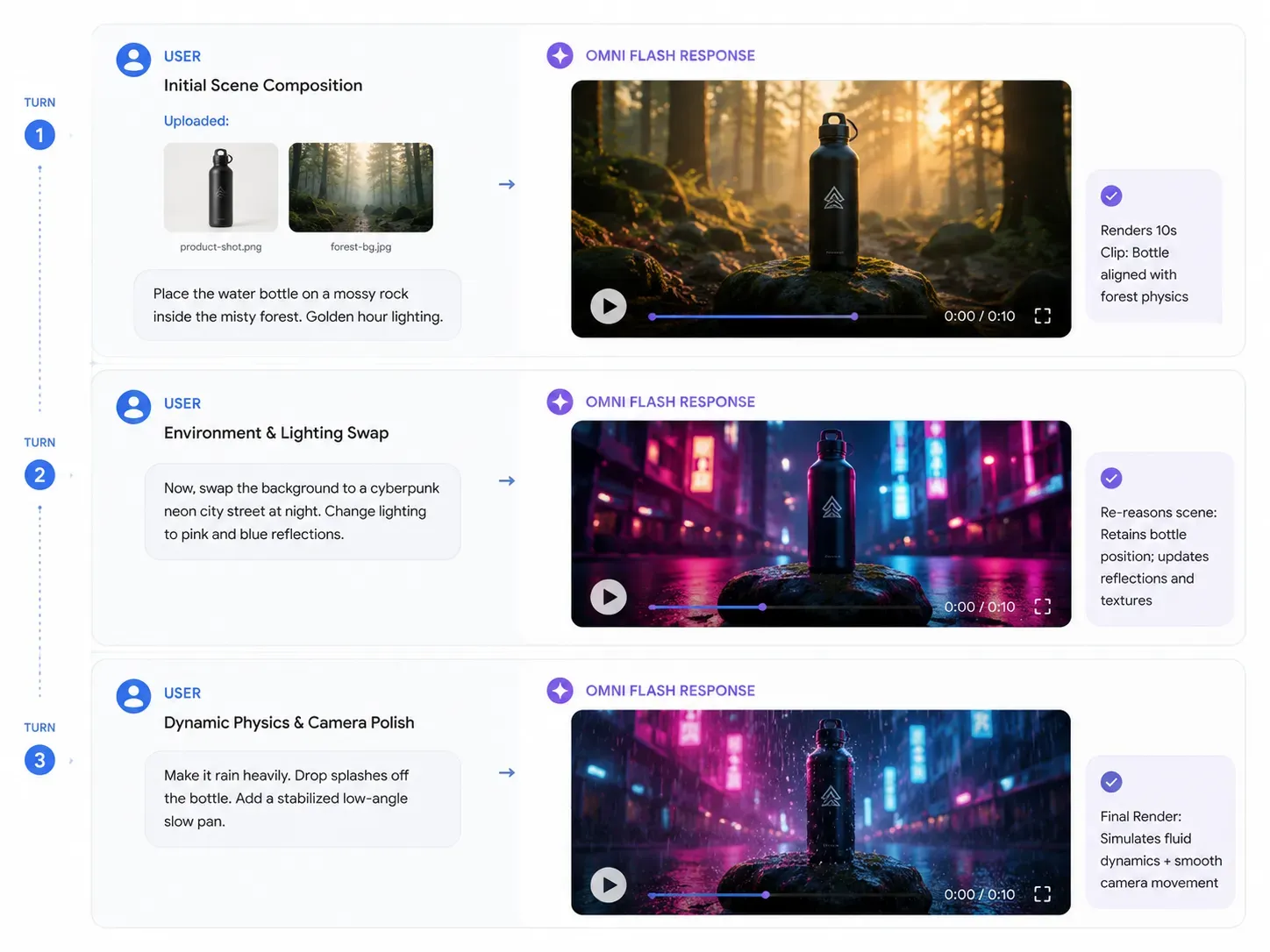
لإطلاق العنان للإمكانات الكاملة لتعدد الوسائط الأصلي في Gemini Omni، يجب أن تتحول استراتيجية المطالبة من التوليد لمرة واحدة إلى محادثة مستمرة. ولأن محرك فيزياء "نموذج العالم" يحتفظ بمنطق البيئة، يمكنك إضافة التعليمات خطوة بخطوة.
إليك مخطط عملي جاهز لصناع المحتوى التجاري:
الجولة 1: المدخلات المرجعية الأولية
الأصول المدخلة: رفع brand-product-shot.png (زجاجة مياه معدنية) و background-reference.jpg (غابة ضبابية).
المطالبة: "أنشئ عرضاً سينمائياً للمنتج مدته 10 ثوانٍ. ضع زجاجة المياه المعدنية من الصورة على صخرة مغطاة بالطحالب داخل الغابة الضبابية. اجعل الإضاءة في وقت الصباح الباكر (الساعة الذهبية)."
المخرجات المتوقعة: يستنتج Omni من الصورتين معاً، ويضع الزجاجة بواقعية على الصخرة مع مراعاة الوزن القائم على الفيزياء وظلالها الأولية.
الجولة 2: تعديل الأصول الديناميكي
سياق المدخلات: محادثة مستمرة داخل نفس الجلسة (لا حاجة لإعادة الرفع).
المطالبة: "الآن، استبدل الخلفية. ضع بدلاً من الغابة الضبابية شارعاً في مدينة مستقبلية (سايبربانك) مليئاً بأضواء النيون ليلاً. غيّر الإضاءة لتنعكس انعكاسات النيون الزرقاء والوردية على السطح المعدني للزجاجة."
المخرجات المتوقعة: تتغير الخلفية فوراً، والأهم من ذلك أن موقع الزجاجة يظل ثابتاً، بينما تتغير انعكاسات سطحها ديناميكياً لتعكس مصادر ضوء النيون الجديدة.
الجولة 3: اللمسة الفيزيائية النهائية
| إجراء المطالبة | الأمر المستهدف |
|---|---|
| إضافة فيزياء البيئة | "اجعل المطر يبدأ بالهطول بغزارة في المشهد. تأكد من تطاير قطرات الماء بواقعية عند اصطدامها بالزجاجة وتشكل تموجات على الأرض." |
| تطبيق تحكم الكاميرا | "قم بعمل زووم بطيء للكاميرا من زاوية منخفضة إلى أعلى، وطبق تثبيت فيديو بلغة بسيطة لجعل الانتقال سلساً." |
بينما يساهم إتقان حلقة المحادثة في Google Flow في تحسين مسار عملك، يحتاج المطورون الذين يديرون سير عمل متعدد النماذج إلى مرونة أكبر. يتيح تنفيذ واجهات برمجة تطبيقات (APIs) متعددة الوسائط لمنصات مثل Atlas Cloud تقديم أكثر من 300 نموذج — بما في ذلك محركات متقدمة للفيديو والصور والاستنتاج اللغوي — تحت طبقة تنسيق واحدة.
محاكاة الواقع: قوة محرك فيزياء "نموذج العالم" في Gemini Omni
لا ينتج التحرير عبر المحادثة نتائج رائعة إلا عندما يفهم النموذج لماذا يبدو المشهد على حالته الحالية. وهنا تصبح طبقة فيزياء نموذج العالم (world model physics) في Gemini Omni حاسمة.
في مؤتمر Google I/O 2026، وصف ديميس هاسابيس، الرئيس التنفيذي لـ Google DeepMind، نموذج Gemini Omni ليس كمولد فيديو فحسب، بل كـ نموذج عالم (world model) — وهو نظام يبني فهماً داخلياً للواقع ويستنتج ما يجب أن يحدث تالياً داخل أي مشهد.
ماذا يعني "نموذج العالم" في الواقع؟

تنبأت معظم أدوات الذكاء الاصطناعي السابقة للفيديو بالإطار التالي عبر مطابقة البكسلات على نطاق واسع. أنتجت لقطات تبدو حقيقية ولكنها لا تتصرف بمنطق ثابت؛ حيث كانت الشخصيات تتشوه بين اللقطات، والظلال تتجاهل مصادر الضوء، والسوائل تتحرك كأنها نسيج لا مادة.
أما Gemini Omni فقد تدرب بشكل مختلف. وفقاً لـ Google، يدمج النموذج فهماً واقعياً للفيزياء والحركة والذكاء الاصطناعي للوعي المكاني لترسيخ مخرجاته في كيفية عمل العالم المادي فعلياً.
الخصائص الفيزيائية التي تدرب Gemini Omni على محاكاتها
تقول Google إن النموذج لديه فهم حدسي للخصائص التالية، بناءً على منصة Genie التابعة لـ DeepMind:
| الخاصية الفيزيائية | التأثير العملي في الفيديو |
|---|---|
| الجاذبية | تسقط الكائنات وتهبط بوزن دقيق |
| الطاقة الحركية | الحفاظ على الزخم عبر التصادمات |
| ديناميكيات السوائل | الماء والدخان والسوائل تتصرف بطريقة طبيعية |
| اتساق الإضاءة | تتحول الظلال بشكل صحيح عند تعديل المشاهد |
| التشريح المكاني | تحافظ نسب الشخصيات على ثباتها عبر اللقطات |
لماذا هذا مهم لإنشاء فيديو متسق؟
خلال العرض التقديمي في مؤتمر I/O 2026، تم اختبار هذه الطبقة من خلال إنشاء شرح دقيق جداً بطريقة الصلصال (claymation) حول طي البروتين — مما أثبت أن النموذج يتجاوز مطابقة البكسلات ليفهم الواقع العلمي والمكاني الفعلي.
هذا الأساس القائم على "نموذج العالم" هو ما يسمح بإنشاء فيديو متسق عبر التعديلات متعددة الجولات. فعندما يستبدل المستخدم خلفية أو يعدل الإضاءة، لا يقوم النموذج بتركيب طبقة جديدة فحسب، بل يعيد استنتاج العلاقة الفيزيائية بين الشخصية والبيئة الجديدة ومصدر الضوء. والنتيجة هي محاكاة الواقع المادي على مستوى المشهد بدلاً من ترقيع البكسلات.
التحول الجذري: مطابقة البكسلات مقابل محاكاة العالم
| أدوات الذكاء الاصطناعي القديمة | Google Gemini Omni (نموذج العالم) |
| ❌ تفتقر للمنطق؛ تتنبأ فقط بالاحتمالية الإحصائية لتجمع البكسلات التالي. | 🧠 تفهم كتلة الكائنات، والزخم الحركي، وحفظ طاقة السوائل. |
| ❌ تتشوه الظلال وتتمزق الأنسجة ديناميكياً بمجرد تغير زاوية الكاميرا. | 🧠 تحاكي الإضاءة العالمية، مما يضمن انكسار أشعة الضوء والانعكاسات بشكل طبيعي. |
| ❌ يتشوه تشريح الشخصية وهياكل الخلفية بعد 3-5 ثوانٍ. | 🧠 تحتفظ ببيئة موحدة، ومنطق إضاءة، وهوية ثابتة عبر التعديلات. |
الصور الرمزية الرقمية المخصصة: هل يمكن لـ Gemini Omni إنشاء "أفاتار" لصناع المحتوى؟
فيزياء "نموذج العالم" تجعل اللقطات المولدة تبدو حقيقية، بينما ميزة الصور الرمزية (الأفاتار) تجعلها تبدو كأنها أنت.
هل يمكن لـ Gemini Omni إنشاء أفاتار ذكاء اصطناعي؟ نعم. يتضمن Gemini Omni Flash أداة مخصصة تتيح للصناع بناء شبيه رقمي لأنفسهم — باستخدام مظهرهم وصوتهم الخاص — واستخدامه مباشرة داخل الفيديوهات المولدة دون الحاجة لإعادة رفع مواد مرجعية في كل مرة.
![]()
كيف تعمل عملية إنشاء الأفاتار؟
لمنع إساءة الاستخدام، أضافت Google خطوة تحقق منظمة قبل إنشاء الأفاتار. ووفقاً لـ TechCrunch، يكمل المستخدمون عملية تهيئة تتضمن تسجيل أنفسهم وهم يقرؤون سلسلة من الأرقام، ثم يتم تخزين المظهر المسجل وإعادة استخدامه في الجلسات المستقبلية.
أما التحرير الصوتي الكامل للمقاطع الخارجية فيخضع للمراجعة، بينما تعمل Google على ضمان النشر المسؤول. تحمل جميع الصور الرمزية الرقمية المخصصة والفيديوهات المولدة علامة Google SynthID المائية الرقمية، والتي يمكن التحقق منها عبر تطبيق Gemini وGemini في Chrome وGoogle Search.
كيف يتكامل Gemini Omni مع YouTube Shorts وGoogle Flow؟
يوضح الجدول التالي الوصول الحالي حسب المنصة:
| المنصة | مستوى الوصول | ملاحظات |
|---|---|---|
| تطبيق Gemini | مشتركو AI Plus, Pro & Ultra | ميزات Omni Flash الكاملة بما فيها الأفاتار |
| منصة Google Flow | مشتركو AI | تشمل Flow Agent، والتحرير الجماعي، وFlow Music |
| أدوات صناع YouTube Shorts | مجاني، لا يتطلب اشتراك | تم الإطلاق في أسبوع Google I/O 2026 |
| تطبيق YouTube Create | مجاني | نفس جدول إطلاق Shorts |
| Developer API | قادم خلال أسابيع | وصول للمؤسسات وGoogle AI Studio |
تلقّت منصة Google Flow تحديثات إضافية بجانب Omni Flash: وكيل "Flow Agent" للعصف الذهني والتوليد الجماعي، وميزة الأدوات المخصصة (Custom Tools) لسير العمل القابل للمشاركة بدون برمجة، ودعم Flow Music لإنشاء فيديوهات موسيقية كاملة وتحويل الأنماط.
أمن المحتوى والمنشأ: كيف تحمي العلامة المائية Google SynthID الفيديو؟
تثير أدوات إنشاء الأفاتار وتحرير الفيديو القوية سؤالاً بديهياً: ما الذي يمنع استخدامها لإنشاء محتوى مضلل؟ إجابة Google هي علامة مائية لا يمكن إزالتها، وغير مرئية، ومدمجة في كل مقطع ينتجه Gemini Omni.
ما هي العلامة المائية Google SynthID للفيديو؟
العلامة المائية Google SynthID ليست شعاراً مرئياً أو علامة وصفية قابلة للحذف، بل هي إشارة مدمجة مباشرة في بكسلات الفيديو لحظة توليده — غير مرئية للعين البشرية ولكنها قابلة للقراءة بواسطة أدوات الكشف الخاصة بـ Google. ووفقاً لمؤتمر I/O 2026، فقد ميزت SynthID أكثر من 100 مليار صورة وفيديو مولد بالذكاء الاصطناعي منذ إطلاقها.
والأهم من ذلك، أن الإشارة مصممة للبقاء حتى بعد عمليات المعالجة الشائعة التي قد تمحو العلامات السطحية، مثل:
- الضغط وإعادة الترميز
- تغيير الحجم والقص
- تحويل التنسيق
بالنسبة لـ Gemini Omni، يتم تفعيل SynthID افتراضياً ولا يمكن تعطيله.
كيف يعمل التحقق من منشأ وسائط الذكاء الاصطناعي؟
يمكن التحقق من منشأ وسائط الذكاء الاصطناعي (AI media provenance) عبر ثلاث منصات من Google: تطبيق Gemini، وGemini في Chrome، وGoogle Search. يقوم المستخدمون برفع المقطع ويحدد الكاشف الطوابع الزمنية التي توجد فيها إشارة العلامة المائية، مما يوفر تحققاً سياقياً بدلاً من مجرد نتيجة "نعم/لا".
SynthID كاستراتيجية لتخفيف مخاطر التزييف العميق (Deepfake)
| طبقة الأمان | ماذا تفعل؟ |
|---|---|
| علامة مائية على مستوى البكسل | تصمد أمام الضغط والقص وإعادة الترميز |
| تضمين إلزامي | لا يمكن للمستخدم إيقاف تشغيلها |
| تبني عابر للمنصات | OpenAI وElevenLabs تتبنيان معيار C2PA |
| بوابة التحقق من الأفاتار | تتطلب تحققاً صوتياً قبل تخزين الهوية |
| حجب التحرير الصوتي | التحرير الصوتي الكامل مؤجل بانتظار نشر مسؤول |
أشار سوندار بيتشاي إلى السياق بوضوح في مؤتمر I/O 2026: تشير الدراسات إلى أن الأشخاص يحددون فيديوهات التزييف العميق عالية الجودة بشكل صحيح بنسبة ربع الوقت فقط. وتشكل SynthID، إلى جانب حجب قدرات التحرير الصوتي، نهج Gemini Omni متعدد الطبقات لـ تخفيف مخاطر التزييف العميق وأمن المحتوى.
Gemini Omni Flash مقابل Pro: مستويات الاشتراك، وتسعير الرموز، والوصول إلى API
بعد اتضاح ميزات النموذج، السؤال التالي هو عملي: كم تكلفته، وأي مستوى يناسب سير عملك؟
كيف تحصل على وصول إلى Gemini Omni Flash الآن؟

بدأ طرح Gemini Omni Flash في 19 مايو 2026. وتعتمد مسارات الوصول على كيفية استخدامك له:
| مستوى الخطة | السعر الشهري | التخزين السحابي | تطبيق Gemini والميزات الأساسية |
|---|---|---|---|
| Google AI Plus | 7.99 دولار | 200 جيجابايت | حدود استخدام أعلى بمرتين، وصول لنموذج Flash Thinking |
| Google AI Pro | 19.99 دولار | 5 تيرابايت | حدود استخدام أعلى بـ 4 مرات، وصول لنموذج Pro، وDeep Research |
| Google AI Ultra | 99.99 دولار | 20 تيرابايت | حدود استخدام أعلى بـ 5 مرات من Pro، وصول للميزات الأكثر تقدماً مثل Deep Think |
يعتمد الوصول إلى Gemini Omni داخل Google Flow على رصيد Google Flow Omni المخصص للخطة: من الوصول الأساسي في AI Plus، إلى مسارات عمل صناعة الأفلام متعددة الجولات في AI Pro، وصولاً إلى سعات حوسبة الاستوديو عالية الحدود في AI Ultra.
بالنسبة لتطبيقات المطورين، يوفر نموذج Vertex AI للدفع لكل رمز (token) تكاليف قابلة للتنبؤ. ومع ذلك، بالنسبة لخطوط إنتاج العرض التي تتطلب معدلات API صارمة، يوفر الانتقال إلى نماذج تسعير GPU المرنة عند الطلب مخططاً أكثر فعالية من حيث التكلفة، مما يمنح الفرق تحكماً خاماً في الأجهزة دون التزامات بحد أدنى.
Gemini Omni Flash مقابل Pro: ما الفرق؟
في مقارنة Gemini Omni Flash مقابل Pro، تم تأكيد إصدار Flash بينما لم يتوفر Pro بعد. يولد Flash مقاطع مدتها 10 ثوانٍ — وهو حد متعمد لإدارة طلب الحوسبة عند الإطلاق، وليس حداً تقنياً للنموذج، وفقاً لنيكول بريتشوفا من Google DeepMind.
تم الإعلان عن Omni Pro ولكن دون موعد إطلاق. تقول Google إنها ستطلقه عندما يرى الفريق "تطوراً نوعياً يتجاوز Flash". حتى ذلك الحين، Flash هو نموذج Omni الوحيد المتاح للجمهور.
Gemini Omni مقابل Google Veo: ما الذي تغير؟
تعد المقارنة بين Gemini Omni مقابل Google Veo تحولاً معمارياً وليس مجرد تحديث إصدار. يظل Veo 3.1 متاحاً مع وصول API للجمهور لتوليد النصوص إلى فيديو. بينما يضيف Omni طبقة استنتاج، ويقبل أنواع المدخلات الأربعة في وقت واحد، ويقدم تحريراً محادثياً متعدد الجولات — وهي ميزات لم يُصمم Veo لدعمها.
واجهة برمجة تطبيقات (API) موحدة لإنتاج الفيديو
بينما تطرح Google نموذج Gemini Omni Flash داخل تطبيق Gemini وGoogle Flow للمستخدمين النهائيين، يحتاج المطورون وفرق الإنتاج الذين يرغبون في دمج نفس محرك الفيديو متعدد الوسائط في سير عملهم إلى طبقة API مستقرة وقابلة للتنبؤ.
توفر Atlas Cloud نموذج Gemini Omni Flash عبر واجهة برمجة تطبيقات موحدة ومتوافقة مع OpenAI، إلى جانب أكثر من 300 نموذج آخر للصور والفيديو والنماذج اللغوية — بحيث يمكنك دمج نموذج Google متعدد الوسائط دون الحاجة لإدارة حسابات بائعين منفصلة أو بوابات دفع أو أدوات تطوير (SDKs) مختلفة.
كلا نسختي Gemini Omni Flash متاحتان الآن على Atlas Cloud:
| النسخة | الأفضل لـ | المدخلات | الدقة | المدة | السعر الابتدائي |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video | التوليد السينمائي المعتمد على المطالبة | نص (حتى 20,000 حرف) | 720p / 1080p / 4K | 4, 6, 8, 10 ثوانٍ | 0.2 دولار + 0.1 دولار/ثانية |
| Gemini Omni Flash Image-to-Video | فيديو متسق الموضوع من مراجع حقيقية | نص + حتى 7 صور مرجعية | 720p / 1080p / 4K | 4, 6, 8, 10 ثوانٍ | 0.2 دولار + 0.1 دولار/ثانية |
بداية سريعة — أنشئ فيديو Gemini Omni Flash في 5 أسطر:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
تُرجع الـ API معرّف التوقع فوراً — استخدم /api/v1/model/prediction/{id} للحصول على رابط ملف MP4 المعروض. المخطط الكامل، ونماذج الكود بـ 7 لغات، وساحة تجربة (Playground) بدون برمجة متاحة على صفحات النماذج المذكورة أعلاه.
الخاتمة: مستقبل المحتوى متعدد الوسائط
يمثل Gemini Omni شيئاً أكبر من مجرد مولد فيديو أفضل. فمن خلال دمج محرك الاستنتاج في Gemini مع التوليد متعدد الوسائط الأصلي، ألغت Google ما كان يتطلب سابقاً أربع أدوات منفصلة — المطالبة النصية، ومرجعية الصور، وعرض الفيديو، والتحرير ما بعد الإنتاج — في سير عمل محادثي واحد.
تتضاعف الآثار بسرعة؛ ففيزياء "نموذج العالم" تعني أن التعديلات تبدو قابلة للتصديق دون تركيب يدوي، وعلامة SynthID تعني أن المساءلة جزء أصيل وليس إضافياً، والقدرة على إنشاء الأفاتار تعني أن الصناع يمكنهم الإنتاج على نطاق واسع دون الحاجة للوقوف أمام الكاميرا في كل مرة. ومع وجود Omni Flash بالفعل عبر تطبيق Gemini وGoogle Flow وYouTube Shorts، فإن عتبة الدخول منخفضة بما يكفي لصناع المحتوى الأفراد وفرق المؤسسات على حد سواء.
ما سيأتي لاحقاً — من Omni Pro، وتوسيع الوصول للـ API، وتعدد أنماط المخرجات — سيحدد مدى عمق هذا التحول.
الآن نريد أن نسمع منك. أي ميزة من ميزات Gemini Omni من المرجح أن تجربها أولاً في سير عملك — التعديلات المحادثية للخلفية، أم إنشاء الأفاتار، أم توليد المشاهد القائمة على الفيزياء؟ شاركنا رأيك في التعليقات أدناه.






