تُعد Gemini Omni تحولاً جوهرياً عن أنظمة الذكاء الاصطناعي التقليدية؛ فهي تعمل كنموذج ذكاء اصطناعي شامل (All-in-one) يعالج المعلومات بشكل طبيعي منذ اللحظة الأولى. فبدلاً من ربط أدوات مختلفة لمعالجة أنواع متعددة من الوسائط، يعمل النموذج بالكامل عبر "محرك عصبي عالمي" موحد. ومن خلال معالجة النصوص، والصور، والصوت، والفيديو ضمن مساحة متجهة (vector space) متعددة الوسائط، فإنه يقضي تماماً على صوامع البيانات القديمة واختناقات الاتصال.
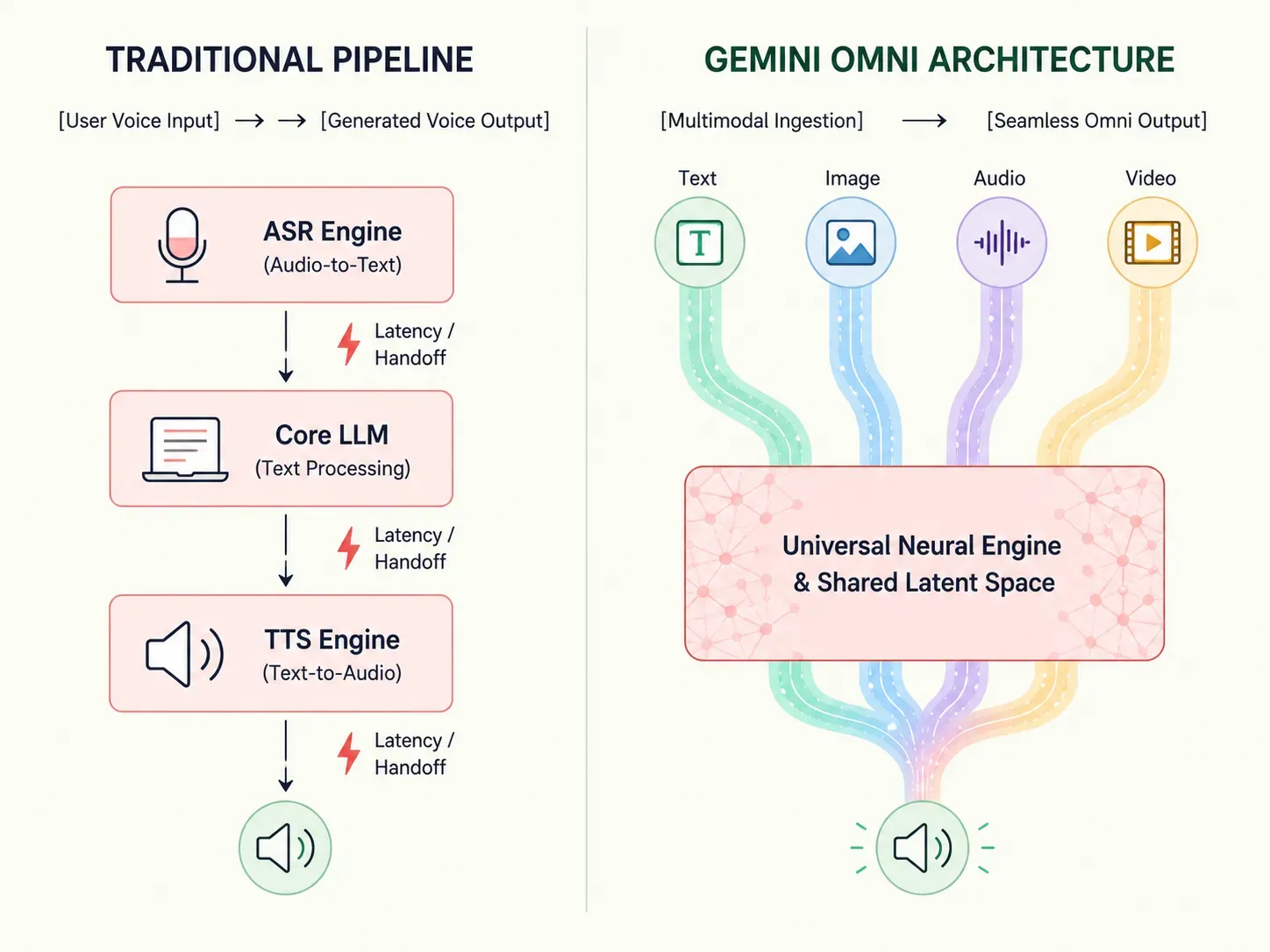
يعتمد الذكاء الاصطناعي التقليدي على خطوط معالجة متسلسلة—مثل تحويل الصوت إلى نص قبل أن يبدأ النموذج اللغوي في صياغة الإجابة. بينما تُعيد Gemini Omni تعريف سير العمل هذا بشكل جذري:
- الاستيعاب الأصلي (Native Ingestion): يعالج النظام رموز النصوص، وبكسلات الصور، وترددات الصوت، وإطارات الفيديو في الوقت ذاته تماماً.
- الحفاظ على السياق: تضمن معالجة البيانات من البداية للنهاية عدم فقدان المشاعر الدقيقة، أو الإشارات البصرية، أو التفاصيل الصغيرة بين الطبقات المختلفة.
يعزز هذا التحول الهيكلي من كفاءة المعالجة ويقلص التأخير إلى مستويات استجابة تقترب من استجابة البشر. وبذلك، يمكن للمطورين والشركات الاستغناء عن إعدادات النماذج المتعددة والمعقدة والاعتماد على نظام واحد قوي مصمم للحوسبة متعددة الحواس الحقيقية.
كيف يعالج نموذج واحد أربعة وسائط في وقت واحد؟
لفهم كيفية معالجة ميزات Gemini Omni للنصوص والصور والصوت والفيديو في الوقت نفسه، يجب النظر مباشرة إلى طبقة البيانات الأساسية. فبينما توجه الأنظمة التقليدية أنواع الملفات المختلفة عبر نماذج فرعية منفصلة ومعزولة، تتخطى Gemini Omni هذا النهج المجزأ تماماً، وتطبق إطار عمل موحد للترميز (Unified Tokenization) يترجم جميع المدخلات أصلاً إلى لغة واحدة يفهمها جوهر الذكاء الاصطناعي.
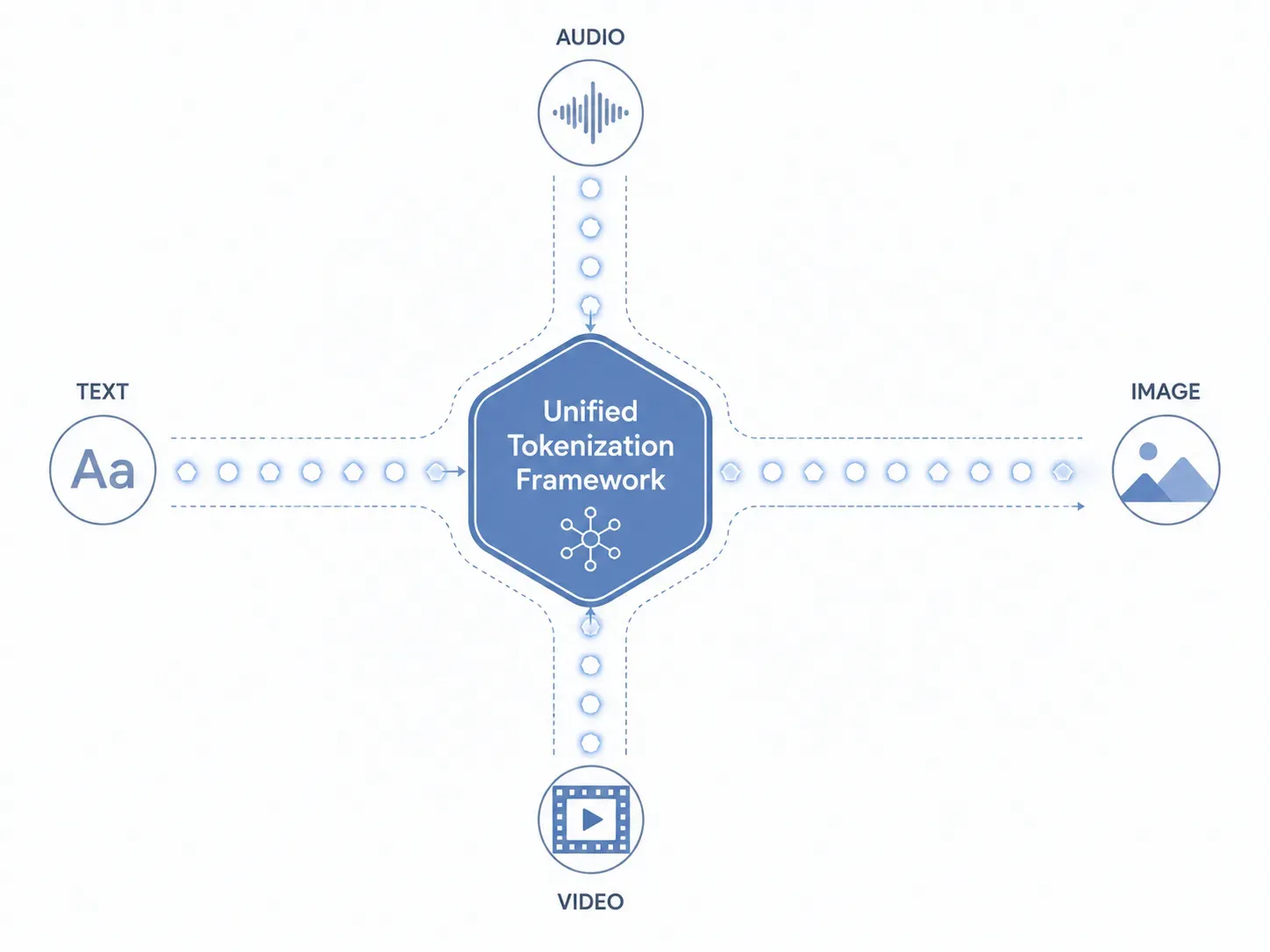
آليات الترميز الموحد
كيف تتعامل Gemini Omni مع أنواع ملفات مختلفة دون نماذج فرعية منفصلة؟ تكمن الإجابة في كيفية استيعاب البيانات وتفكيكها قبل بدء الاستنتاج:
- النصوص: تُحول الحروف الأبجدية الرقمية إلى رموز نصية دلالية قياسية.
- الصور: تُقطع العناصر البصرية إلى رقع صغيرة من البكسلات وتُخطط كرموز بصرية.
- الصوت: تُؤخذ عينات من موجات الصوت المستمرة، مع التقاط التردد والنبرة، وتحويلها إلى رموز صوتية.
- الفيديو: تُعامل الصور المتحركة كسلسلة مستمرة من الإطارات الزمنية، مما ينشئ رموزاً مكانية-زمانية.
الأوزان المشتركة ومعالجة الموترات الأصلية
بمجرد اكتمال استيعاب البيانات متعددة الوسائط، تدخل جميع أنواع البيانات في بنية أوزان مشتركة. وبدلاً من استخدام مُشفرات متخصصة فردية تمرر البيانات ذهاباً وإياباً عبر جسور مسببة للتأخير، تقوم شبكة عصبية واحدة بمعالجة جميع الرموز بشكل موحد.
ومن خلال معالجة الموترات (Tensors) الأصلية، ينفذ النموذج عمليات حسابية على رموز النصوص، والصوت، والصور ضمن نفس طبقات المصفوفة. ولأن كل شيء يتشارك نفس المساحة الحسابية، تفهم الشبكة مباشرة العلاقة بين كلمة منطوقة، وجملة مكتوبة، وبكسل صورة، وإطار فيديو دون الحاجة إلى خطوة ترجمة واحدة.
لمشاهدة تطبيق هذه المبادئ الهندسية والترميز الأصلي على نطاق واسع في سيناريوهات واقعية، شاهد عرض "رؤية أبحاث مختبر MIT الإعلامي". يحدد هذا العرض التحول طويل الأمد في الصناعة نحو ربط نماذج الذكاء الاصطناعي مباشرة بطيف غني من الإشارات المادية ومتعددة الحواس:
الركائز الأساسية للوسائط: خريطة معالجة الوسائط المتعددة
لفهم قوة Gemini Omni حقاً، يجب تجاوز مجرد استيعاب البيانات. يستخدم النموذج بنية موحدة تتواجد فيها النصوص والصور والصوت والفيديو ضمن خريطة مساحة كامنة (Latent space mapping) مشتركة. فعندما يتغير مدخل في وسيط واحد، فإنه لا يؤدي فقط إلى رد فعل معزول، بل يغير ديناميكياً المعايير الرياضية للوسائط الثلاثة الأخرى في نفس اللحظة تماماً.
مصفوفة الترابط متعدد الوسائط
يعتمد الاستنتاج عبر الوسائط (Cross-media inference) في الوقت الفعلي على تدفقات بيانات مترابطة. فبدلاً من معالجة البيانات في كتل متسلسلة، يقوم النموذج بمزامنة الركائز الأربع بشكل مستمر لتحقيق محاذاة مثالية للوسائط المتعددة.
توضح خريطة المعالجة أدناه كيف تؤثر هذه المدخلات الحية على بعضها البعض داخل الشبكة العصبية العالمية:
| المدخل الرئيسي | الوسائط المعالجة معاً | عملية النظام | الهدف التقني العميق |
| موجات الصوت | النص + إطارات الفيديو | تتبع إيقاع الصوت لفهرسة تسلسلات الفيديو الزمنية | محاذاة حسية في الوقت الفعلي |
| الصور الثابتة | الصوت الخام + النص | تترجم أطياف ألوان الصورة إلى أصوات سياقية مطابقة | توليف عبر الوسائط |
| الكود البرمجي | مصفوفات الفيديو + النص | تعدل متغيرات الفيديو الهيكلية مباشرة عبر منطق البرمجة | تنفيذ الكود التوليدي |
| تسلسلات الفيديو | مسارات الصوت + الكود | تحسب التحديثات المكانية والزمانية عبر مسارات البيانات المتعددة | تحليل موحد للصوت والفيديو |
مزامنة المعايير في الوقت الفعلي
عندما تعالج Gemini Omni بث فيديو مباشراً، فإنها لا تفصل المرئيات عن مسار الصوت الخلفي. وإذا سجل مدخل الصوت ارتفاعاً مفاجئاً في التردد—مثل صراخ شخص ما—يقوم النموذج بتحديث توقعاته للرموز البصرية فوراً. إنه يتوقع حركة مادية سريعة أو تغيراً في إطارات الفيديو قبل حدوثها حتى.
يمنع هذا التأثير المتبادل العميق انحراف السياق. ولأن الشبكة بأكملها توازن بين هذه المتغيرات في وقت واحد، تظل المخرجات متماسكة تماماً، سواء كان النموذج يولد ملخص فيديو متزامناً أو يترجم بثاً حسياً مباشراً أثناء التنقل.
القضاء على التأخير وانحراف السياق: ميزة الأوزان الموحدة
لتقدير سرعة Gemini Omni، من المفيد النظر إلى عدم الكفاءة الرياضية لخطوط أنابيب الذكاء الاصطناعي "المخيطة". تاريخياً، كان بناء مساعد يدعم الصوت أو الفيديو يتطلب ربط طبقات برمجية منفصلة ذات غرض واحد.
plaintext1[إدخال صوت المستخدم] 2 │ 3 ▼ 4 1. محرك ASR (تحويل الصوت إلى نص) 5 │ 6 ▼ 7 2. طبقة LLM الأساسية (معالجة توليد النصوص) 8 │ 9 ▼ 10 3. محرك TTS (توليف النص إلى صوت) 11 │ 12 ▼ 13[مخرج صوتي مولد]
يجبر هذا التنسيق متعدد الخطوات البيانات على الانتقال عبر جسور برمجية متصلة، مما يضاعف تأخير التنفيذ. ولا يمكن لمحرك تحويل النص إلى كلام المنفصل "سماع" التسجيل الصوتي الأصلي، مما يؤدي إلى خسارة فادحة في البيانات عبر أنواع الوسائط المختلفة؛ فالتلميحات الصوتية المهمة، مثل النبرة الساخرة للمستخدم، أو التردد، أو الضيق العاطفي، تختفي تماماً عندما يتم تسطيح كل شيء إلى نص عادي.
تحقيق خفض حقيقي في تأخير المسار
تتخطى Gemini Omni هذه الحدود من خلال العمل على أوزان عصبية موحدة. ولأن شبكة عصبية واحدة تقيم النصوص، والصوت، والبكسلات أصلاً تحت سقف رياضي واحد، فإنها تزيد سرعات التنفيذ بشكل كبير. هذا التصميم يؤدي إلى خفض عميق في تأخير المسار.
وفقاً لتقارير قياس الأداء من Google DeepMind، فإن البنى الأصلية متعددة الوسائط التي تشغل تدفقات صوتية حية تقلل أوقات الاستجابة من البداية للنهاية إلى أقل من 150 مللي ثانية. وهذا التحول يطابق فعلياً الإيقاع الطبيعي للمحادثة البشرية في الوقت الفعلي.
تحسين الاحتفاظ بالسياق
إلى جانب السرعة الفائقة، يضمن التنفيذ الموحد مستوى عالياً من تحسين الاحتفاظ بالسياق. فعندما تتحدث إلى النموذج، تعالج الأوزان ترددات صوتك إلى جانب تعريفاتك النصية في وقت واحد.
- معالجة التنغيم: تلتقط الشبكة التعديلات الصوتية مباشرة، وتستجيب بالتعاطف أو الاستعجال المناسب.
- المزامنة البصرية: تترجم التعبيرات الدقيقة للوجه أو الحركات المكانية داخل إطار الفيديو مباشرة إلى مخرج المحادثة دون أخطاء تحليل.
من خلال إزالة خطوات الترجمة الوسيطة، تحافظ Gemini Omni على التفاصيل الصغيرة من التلاشي. وهذا يبني أساساً قوياً لتفاعلات سلسة وطبيعية عبر حواس مختلفة بين البشر والآلات.
بناء سير عمل المؤسسات باستخدام أنظمة الذكاء الاصطناعي الشاملة
يغير هذا التحول نحو تعدد الوسائط الأصلي كيفية بناء الشركات للأدوات الرقمية وتوسيع نطاقها. فمن خلال استخدام إعداد ذكاء اصطناعي واحد وشامل، يمكن للشركات استبدال القطع البرمجية المنفصلة وغير المتناغمة بسير عمل موحد، مما يسمح لها بتشغيل أنظمة وسائط مختلطة وتفاعلية بسهولة على نطاق واسع.
بنية واجهة برمجة التطبيقات (API) الواحدة
لم يعد المطورون بحاجة إلى تنسيق وظائف سحابية متباينة للتعرف على الكلام، وتحليل النصوص، ومعالجة الصور. بدلاً من ذلك، تربط تكامل واجهة برمجة تطبيقات موحد طبقة التطبيق مباشرة بالشبكة الأساسية، مثل واجهة برمجة تطبيقات نموذج Atlas Cloud AI. يسمح هذا المسار المبسط للفرق ببناء خطوط أنابيب متقدمة عبر الوسائط باستخدام إطار عمل طلب واحد.
plaintext1 ┌─────────────────────────────────┐ 2 │ Unified Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Real-Time Code │ │ Mixed-Media Data │ │ Multi-Sensory Ed │ 9│ & Asset Sync │ │ Automation Layer │ │ Dashboards │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
على سبيل المثال، يمكن لمنصة تدريب مؤسسية معالجة بث فيديو مباشر، وتتبع إيقاع صوت المتحدث، وترجمة الحوار، وتحديث لوحة معلومات البيانات المرئية ديناميكياً في وقت واحد—وكل ذلك مدعوم بنظام خلفي واحد.
المزايا الاستراتيجية للنشر
ما هي مزايا النشر للانتقال إلى بنية نموذج شامل؟
يوفر الانتقال من إعدادات النماذج المتعددة القديمة إلى شبكة عصبية واحدة فوائد فورية وقوية لأنظمة تكنولوجيا المعلومات في الشركات:
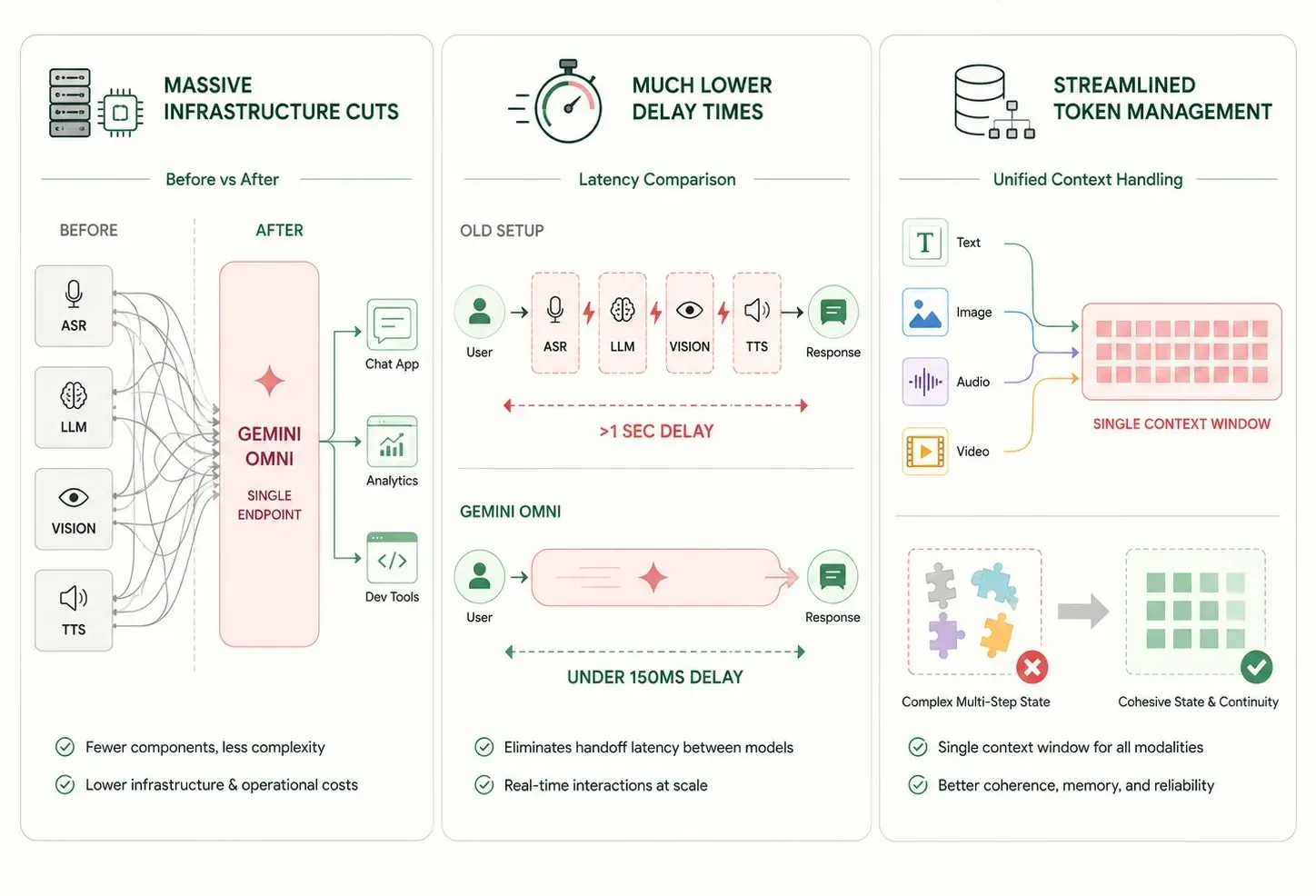
- خفض هائل في البنية التحتية: تجميع مهام النصوص والرؤية والصوت في نموذج واحد يقلل من عدد نقاط النهاية البرمجية المنفصلة، مما يجعل الصيانة طويلة الأمد أسهل بكثير.
- أوقات تأخير أقل بكثير: تخطي خطوات الشبكة الإضافية بين الأدوات الصغيرة والمتخصصة يقلل أوقات الاستجابة إلى أقل من ثانية، مما يسمح بتجارب مستخدم حقيقية في الوقت الفعلي.
- إدارة رموز مبسطة: نافذة سياق واحدة تتبع جميع الوسائط بشكل موحد تقلل من مشكلات إدارة الحالة المعقدة عبر العمليات متعددة الخطوات.
تحقيق النشر القابل للتوسيع للوسائط المتعددة
من خلال العمل عبر إطارات عمل مثل Gemini Enterprise Agent Platform، يمكن للشركات تنسيق شبكات من الوكلاء الفرعيين المستقلين بسلاسة. يجعل هذا النظام الواحد من السهل تشغيل مشاريع الوسائط المتعددة واسعة النطاق، حيث يستخدم إعدادات مُدارة تتابع سياق الخلفية وهوية المستخدم عبر سير عمل يستمر لأيام. ومن خلال إبقاء المدخلات المختلفة في مساحة آمنة واحدة، يمكن للشركات أتمتة المهام عبر وسائط مختلفة من البداية إلى النهاية دون فقدان البيانات أو فقدان مسار الموضوع الرئيسي.
القيود الحسابية وتحسين الأجهزة لاستنتاج الذكاء الاصطناعي العالمي
بينما يفتح معالجة أربعة تدفقات بيانات منفصلة تحت بنية شبكة موحدة سير عمل سلس عبر الوسائط، فإنه يقدم أيضاً مطالب غير مسبوقة على البنية التحتية للأجهزة الحديثة. يتطلب التنقل في هذه البيئة إدارة دقيقة للموارد الحسابية للتغلب على العقوبات المادية القصوى المرتبطة بالمعالجة الحسية المتعددة والمتزامنة على نطاق عالمي.
عبء الترميز متعدد الوسائط
ينبع التحدي الهندسي الأول من عبء رموز الوسائط المتعددة. فبخلاف مجموعات بيانات النصوص الأبجدية الرقمية القياسية، تولد الصور عالية الدقة، وترددات الصوت الخام، وملفات الفيديو المتسلسلة كميات هائلة من البيانات الرقمية.
- معالجة النصوص: تتحول صفحة واحدة من الكتابة إلى حوالي 1,000 رمز دلالي كثيف.
- المعالجة البصرية: دقيقة واحدة من لقطات الفيديو الخام، عند تقطيعها إلى خطوات إطار ثابتة وكتل بكسل، تتفكك إلى مئات الآلاف من الرموز البصرية.
عندما يعالج جوهر نموذج واحد أنواع الوسائط هذه معاً، فإنه يسبب طفرة أسية في كثافة نافذة السياق. يجب على آلية "الانتباه" (Attention) في النظام تقييم كيفية ارتباط كل رمز بكل رمز آخر، مما يهدد بإغراق ذاكرة النطاق الترددي العالي (HBM) الموجودة على الرقاقة وتشبيع طبقات المعالجة.
تسريع أعباء العمل عبر توسيع مجموعات TPU
لمواجهة هذا الاختناق، تعتمد بنيات المؤسسات على منصات أجهزة متخصصة مصممة خصيصاً للحوسبة متعددة الحواس. تستخدم بنية جوجل الأحدث توسيع مجموعات TPU لتوزيع أعباء عمل الرموز الموحدة المكثفة هذه عبر بيئات مراكز البيانات متعددة الطبقات.
plaintext1 ┌─────────────────────────┐ 2 │ Unified Gemini Tokens │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore Array │ │ TensorCore Array │ 9│ (Parallel Matrix Arithmetic) │ │ (Parallel Matrix Arithmetic) │ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Optical Interconnect │ 16 │ (Ultra-Low Latency ICI) │ 17 └─────────────────────────┘
توفر إعدادات الأجهزة مثل منصة Trillium TPU v6e زيادة مذهلة بمقدار 4.7 ضعف في ذروة الأداء الحسابي لكل رقاقة مقارنة بأجيال الأجهزة القديمة. تعالج هذه البنية المتخصصة هذه المطالب الهائلة من خلال الجمع بين وحدات تنفيذ المصفوفات المحسنة وتخطيطات البنية التحتية المادية العميقة:
| طبقة محرك الأجهزة | المواصفات المعمارية | وظيفة النظام الأساسي |
| مصفوفات TensorCore الموسعة | مضاعفة مساحة وحدة ضرب المصفوفة (MXU) | تنفذ عمليات حسابية موازية مكثفة على موترات الفيديو الكثيفة. |
| ذاكرة HBM عالية النطاق الترددي | تصل إلى 32 جيجابايت HBM لكل رقاقة | تضم مصفوفات رموز ضخمة بالكامل على السيليكون لمنع اختناقات الذاكرة. |
| الجيل التالي من الربط بين الرقائق | 800 جيجابايت/ثانية نطاق ترددي ثنائي الاتجاه | تزامن متغيرات المعايير عبر عشرات الآلاف من الرقائق بدون تأخير. |
من خلال استخدام نسيج شبكات ضوئي مخصص جنباً إلى جنب مع تكوينات الذاكرة العميقة هذه، يمكن للبنى التحتية السحابية التوسع ديناميكياً للتعامل مع معايير مدخلات بملايين الرموز. وهذا يسمح للمؤسسات بنشر وكلاء ذكاء اصطناعي متقدمين في الوقت الفعلي عالمياً دون المخاطرة بتوقف الذاكرة أو فشل وقت تشغيل النظام.
واجهة برمجة تطبيقات موحدة لإنتاج الفيديو
بينما تطلق جوجل Gemini Omni Flash داخل تطبيق Gemini وGoogle Flow للمستخدمين النهائيين، يحتاج المطورون وفرق الإنتاج الذين يرغبون في تضمين نفس محرك الفيديو متعدد الوسائط في سير عملهم الخاص إلى طبقة API مستقرة وقابلة للتنبؤ.
تقدم Atlas Cloud خدمة Gemini Omni Flash عبر واجهة برمجة تطبيقات موحدة متوافقة مع OpenAI، إلى جانب أكثر من 300 نموذج آخر للصور والفيديو والنماذج اللغوية الكبيرة — بحيث يمكنك دمج نموذج جوجل متعدد الوسائط الأصلي دون التلاعب بحسابات بائعين منفصلة أو بوابات دفع أو حزم تطوير برمجية (SDKs).
كلا إصداري Gemini Omni Flash متاحان على Atlas Cloud:
| Variant | Best For | Inputs | Resolution | Duration | Starting Price |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video | توليد سينمائي مدفوع بالأوامر النصية | نص (حتى 20,000 حرف) | 720p / 1080p / 4K | 4, 6, 8, 10 ثانية | $0.2 + $0.1/ثانية |
| Gemini Omni Flash Image-to-Video | فيديو متسق الموضوع من مراجع حقيقية | نص + حتى 7 صور مرجعية | 720p / 1080p / 4K | 4, 6, 8, 10 ثانية | $0.2 + $0.1/ثانية |
بداية سريعة — قم بتوليد فيديو Gemini Omni Flash في 5 أسطر:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "غابة ضبابية في ساعة الغروب، لقطة سينمائية", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
تعيد واجهة برمجة التطبيقات معرف تنبؤ (prediction ID) على الفور — قم بعمل استطلاع لـ /api/v1/model/prediction/{id} للحصول على رابط MP4 المُعالج. المخطط الكامل، ونماذج الأكواد بـ 7 لغات، ومساحة تجريبية بدون كود (no-code) متاحة على صفحات النماذج المرتبطة أعلاه.
الخاتمة: الاستعداد للمستقبل من خلال الذكاء الآلي الموحد
يغير وصول Gemini Omni نماذج تصميم المطورين بشكل جذري، حيث يحول الصناعة من ربط أدوات منفصلة إلى نشر حلول موحدة من طبقة واحدة. وبدلاً من إدارة جسور تكامل معقدة بين واجهات برمجة تطبيقات معزولة، يمكن للمهندسين الآن الاعتماد على إطارات عمل تعلم آلي من الجيل التالي تعالج بشكل طبيعي تدفقات البيانات المترابطة تحت سقف رياضي واحد.
plaintext1[خط أنابيب البرمجيات القديم] 2واجهة نصية منفصلة ──┐ 3واجهة صوتية منفصلة ─┼──► لبنات خط أنابيب يدوية ──► إنتاج هش 4واجهة فيديو منفصلة ──┘ 5 6[بنية Omni الموحدة] 7رموز عالمية ──► نموذج أصلي أحادي الطبقة ──► أتمتة سلسة
يتطلب هذا التحول الهيكلي إصلاحاً كاملاً لكيفية بناء المنتجات الرقمية. وللبقاء في المنافسة، يجب على الفرق التقنية الابتعاد عن صوامع البيانات الساكنة وإعداد الأنظمة البرمجية القياسية لـ أنظمة حسية متعددة أصلية.
بالعمل مباشرة على بنية تحتية سحابية محسنة للغاية مثل Google Cloud AI infrastructure، يمكن للمؤسسات توسيع نطاق أعباء عمل الرموز المكثفة هذه دون المخاطرة بانحراف السياق النظامي أو عقوبات التأخير. في النهاية، يعني تأمين خط أنابيب التطوير الخاص بك للمستقبل تصميم حلول حول محرك واحد متماسك مبني لفهم العالم المادي بشكل شامل.






